Файл: Федеральное государственное автономное образовательное учреждение высшего образования казанский (приволжский) федеральный университет высшая школа информационных технологий и информационных систем.docx
Добавлен: 08.11.2023
Просмотров: 100
Скачиваний: 2
ВНИМАНИЕ! Если данный файл нарушает Ваши авторские права, то обязательно сообщите нам.
СОДЕРЖАНИЕ
Федеральное государственное автономное образовательное учреждение
высшего образования
КАЗАНСКИЙ (ПРИВОЛЖСКИЙ) ФЕДЕРАЛЬНЫЙ УНИВЕРСИТЕТ
ВЫСШАЯ ШКОЛА ИНФОРМАЦИОННЫХ ТЕХНОЛОГИЙ И
ИНФОРМАЦИОННЫХ СИСТЕМ
Направление подготовки: 09.03.03 – Прикладная информатика
ВЫПУСКНАЯ КВАЛИФИКАЦИОННАЯ РАБОТА
Кластеры.
Построение отказоустойчивого решения на базе открытого ПО.
Работа завершена:
«___»_____________2017 г.
Студент группы ______ ____________________ Т.А.Светликова
Работа допущена к защите:
Научный руководитель
Старший системный администратор, GDC
«___»_____________201 г. ____________________ А.А. Иванов
Директор Высшей школы ИТИС
«___»_____________201 г. __________________ А.Ф. Хасьянов
Казань – 2017 г.
Содержание
Введение. 3
1.Обзорная часть 5
1.1 История. 5
1.2 О кластере. 7
1.2.1 Высокая доступность. 10
1.2.1Непрерывная доступность (Fault tolerant) 13
1.2.3 Вычислительные кластеры 16
1.3 Рынок 18
1.3.1 PowerHA 19
1.3.2 Windows 22
1.3.3 HP Serviceguard 30
1.3.4. Red Hat Enterprise Linux Cluster 32
1.3.5 Solaris Cluster 36
2.Реализация 38
2.1 Демон 40
2.2 Сервисное приложение 47
2.3 Клиентское приложение. 49
Вывод. 51
Список литературы. 52
Приложение 54
Введение.
Компьютерные технологии не стоят на месте, а все больше и больше развиваются, и они имеют все большее влияние в бизнес-процессе предприятий, поэтому необходимо, чтобы вычислительные ресурсы были доступны максимально долгое время. Для успешного проведения бизнеса компаниям с развитой сетевой инфраструктурой необходимы надежные сервера. Примерами таких компаний являются интернет магазины; предприятия, в которых есть специальный системы, работающие в режиме реального времени; банки, с огромной сетью филиалов. Серверы в таких компаниях должны работать и предоставлять услуги двадцать четыре часа в сутки ежедневно.
Каждый год фирмы теряют все большие суммы при выходе оборудования из строя или его простое. В эту сумму входят прибыль, которую предприятие могло бы получить, стоимость информации, которая была утеряна, стоимость технического обслуживания оборудования, себестоимость самого оборудования, количество клиентов, которое фирма может потерять и т.д.
Есть большое количество вариантов создания относительно надежной системы. К таким относятся дисковые массивы RAID, которые объединяют несколько физических дисков в логический; это позволяет не прекращать обработку обращений к хранящейся информации, если из строя выйдет один или несколько физических дисков. Также используются резервирование блоков питания, чтобы при отказе одного из них, оборудование продолжало работать. Если произойдет отключение электричества, поддержку работоспособности могут обеспечить бесперебойные блоки питания. Для того, чтобы избежать отказ оборудования, при поломке одного процессора используются многопроцессорные системы. Но ни один из способов не поможет, если откажут все оборудования. Именно для таких случаев были разработаны кластеры.
Первой реализацией кластеров можно считать системы «горячего резерва», которые были популярны во времена, когда стали популярны мини-компьютеры. Некоторое количество таких систем, входят в состав сети серверов, находятся в резерве и простаивают, но, как только сломается какая-либо из основных систем, они включаются в работу и выполняют необходимые функции. Получается, что некоторые сервера полностью имеют полную копию других и могут заменить их, в случае поломки или отказа последних. Но это не выгодно, так как часть оборудования просто дублирует другую и не выполняет никакую другую полезную функцию, и нагрузка распределяется неравномерно. Для того, чтобы оборудование не простаивало, а выполняло какие-либо полезные действия были придуманы кластеры.
Таким образом, в нашей жизни невозможно обойти без кластерных технологий. Исходя из всего вышеизложенного определилась проблема, для решения которой была поставлена цель: реализовать HA-кластера. В связи с эти определились задачи:
-
Дать описание кластеров -
Дать общую характеристику кластеров -
Изучить виды кластеров -
Проанализировать наиболее популярные на современном рынке кластерные высокой доступности -
Реализовать свой кластер
- 1 2 3 4 5 6
Обзорная часть
В обзорно-аналитической главе будет проведен обзор предметной области, рассмотрены аналоги системы, их преимущества и недостатки.
1.1 История.
Изначально кластерные технологии использовались при развертывании компьютерных сетей. Немалую роль в появлении высокоскоростной передачи между компьютерами имела возможность объединения вычислительных ресурсов. Лаборатория Xerox PARC вместе с группой разработчиков протокола TCP/IP разработали и закрепили стандарты сетевого взаимодействия уже в начале 1970-ых годов. Была разработана операционная система Hydra («Гидра»), которая работала на компьютерах PDP-11, которые выпускала компания DEC. На базе это ОС был разработан кластер, который был назван C.mpp в 1971 году в Америке в городе Питтсбург, который находится штате Пенсильвания. Однако, только в 1983 году научились распределять задачи и распространять файлы с помощью компьютерных сетей, огромный вклад в разработку этого внесла компания Sun Microsystems, которая предоставила операционную систему на основе BSD, которая имела название SunOS.
Первым коммерческим проектом кластера стал ARCNet, созданный компанией Datapoint в 1977 году, однако этот продукт не принес прибыль компании, поэтому разработка кластеров была заморожена до 1984 года. В этом году компанией DEC был создан кластер VAXcluster, который был построен для ОС VAX/VMS. Каждый из этих кластеров мог не только производить совместные вычисления, но и предоставлял возможность совместного использования файловой системы и других составляющих, при этом не теряя целостность файлов и неизменность данных. На данный момент VAXCluster (называемый теперь VMSCluster) входит в сотав операционной системы HP OpenVMS, которая использует процессоры Alpha и Itanium.
Также есть еще несколько первых разработок кластера, которые преобрели популярность. Такими продуктами являются класера Himalaya, который разработан компанией Tandem в 1994 году, а также Parallel Sysplex, который был разаботан компанией IBM также в 1994 году.
Большей часть разработкой кластеров, которые состояли из персональных компьютеров, занимался проект Parallel Virtual Machine. Первый релиз данной программы произошёл в 1989 году. Это программное обеспечение предоставляло возможность из нескольких обычных компьютеров собрать один виртуальный суперкомпьютер. Появилась возможность очень быстро и просто создавать кластера. Данные дешевые кластера были даже лучше по производительности, чем производительность мощностей коммерческих систем.
Разработку кластеров, состоящих из ПК в данной области продолжило Американское аэрокосмическое агентство NASA в 1993г. И уже в 1995 году появился кластер Beowulf. Это также поспособствовало развитию grip-сетей, который были созданы вместе с системами UNIX.
1.2 О кластере.
Термин «кластер» имеет множество определений. Для некоторых главной составляющей является отказоустойчивость, для других — масштабируемость, для третьих — управляемость. Классическое определение кластера звучит примерно так: «кластер — параллельная или распределенная система, состоящая из нескольких связанных между собой компьютеров и при этом используемая как единый, унифицированный компьютерный ресурс». Следовательно, кластер – это некоторое количество серверов или компьютеров, которые объединены в одну сеть, которой можно управлять, и работают как неразделимый механизм. Для работы кластера необходимо, чтобы на любой узле (ноде, компьютере, сервере) была запущена своя копия ОС.
Грегори Пристер как-то дал определение кластерным технологиям: «Кластер представляет собой одну из разновидностей распределенной или параллельной системы». Этот человек сыграл немалую роль на начальном этапе создания кластеров. Именно он был одним из ранних архитекторов кластерных решений.
Однако эксперты Aberdeen Group дали более глобальное определение кластеру. По их мнению, кластер - это система, которая может работать как единый целый механизм, обеспечивает высокую отказоустойчивость, имеет централизованное управление всеми ресурсами и общую файловую систему и, кроме того, обеспечивает гибкость конфигурации и легкость в наращивании ресурсов.
Все узлы кластера объединены в единую сеть, с помощью коммутационных каналов, через которые сервера могут обмениваться информацией. Каждый узел следит за состоянием других узлов, а также отправляет необходимую информацию, которая может включать в себя конфигурационные данные, данные об общих системах хранения и их работоспособности. Процедура обмена данной информацией называется heartbeat («сердцебиение», или «пульс»), и если кластер получил этот сигнал, следовательно сервер-адресант работает исправно. Если в какой-то момент один из узлов перестает посылать heartbeat-сигналы, то остальные узлы начинают считать его неисправным и кластер начинает перенастраиваться. Сигналы «сердцебиения» могут передаваться по одному каналу с какими-либо данным, но при создании крупных систем, лучше выделить для этого другой канал, чтобы не происходила потеря сигнала. С помощью таких сигналов также можно определить узел, который будет контролировать работу остальных узлов.
Бывает ситуация, когда приложение перестает быть доступным для пользователя, этот период называется время простоя (или отключения). Есть классификация простоев, которая состоит из двух категорий:
-
запланированные:
-
замена оборудования;
-
обслуживание;
-
обновление программного обеспечения;
-
резервное копирование (автономное резервное копирование);
-
тестирование (периодическое тестирование необходимо для проверки кластеров);
-
разработка;
-
незапланированные:
-
ошибки администратора;
-
отказы приложений;
-
отказы оборудования;
-
ошибки операционной системы;
-
стихийные бедствия.
Таким образом, кластерные технологии должны обеспечивать доступность сервиса при любых простоях, как запланированных, так и незапланированных..
Наиболее популярными приложениями, которые лучше запускать в кластерах, являются:
-
базы данных;
-
системы управления ресурсами предприятия (ERP);
-
средства обработки сообщений и почтовые системы;
-
средства обработки транзакций через Web и Web-серверы;
-
системы взаимодействия с клиентами (CRM);
-
системы разделения файлов и печати.
Также есть у кластеров есть своя классификация. Обычно различают следующие основные виды кластеров:
-
отказоустойчивые кластеры (High-availability clusters, HA, кластеры высокой доступности)
-
кластеры непрерывной доступности (Fault tolerant)
-
вычислительные кластеры
1.2.1 Высокая доступность.
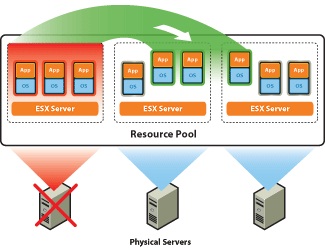
Высокодоступные кластера обозначаются аббревиатурой HA (англ. High Availability — высокая доступность). Данные кластеры позволяют предоставить высокую доступность сервиса. Количество узлов в HA кластере всегда избыточное, чтобы при отказе одного или нескольких, можно было бы запустить сервис на других. Минимальное количество узлов в данном кластере составляет два. В противном случае повысить доступность не получиться. Существует большое количество программ, которое предоставляют решение для HA-кластера.
Существует три варианта построение высокодоступного кластера:
-
с холодным резервом или активный/пассивный. В этом случае активный узел обрабатывает все запросы, а пассивный включается в работу только лишь при отказе активного. Пример — резервные сетевые соединения, в частности, Алгоритм связующего дерева. Например связка DRBD и HeartBeat.
-
с горячим резервом или активный/активный. Все ноды принимают и обрабатывают запросы, и при отказе одного из них, нагрузка распределяется по оставшимся нодам. Следовательно, при отказе одного узла кластер переконфигурируется. Примеры — практически все кластерные технологии, например, Microsoft Cluster Server. OpenSource проект OpenMosix.
-
с модульной избыточностью. Данный вариант самый трудозатратый. Его используют только в случаях, когда простой системы невозможен. В это конфигурации один и тот же запрос может выполняться несколькими узлами и выдается результат любого узла. Следовательно, очень важно, чтобы результаты всех узлов были идентичными (либо различия незначительны). Примеры — RAID и Triple modular redundancy.
Некоторые решения кластеров могут сочетать несколько вариантов построения кластеров. Так, например, Linux-HA может обслуживать очень рискованные запросы всеми узлами, это называется режим обоюдной поглощающей конфигурации, а другие запросы могут равномерно распределяться между узлами.
Высокая доступность кластеризация является метод, используемый для минимизации времени простоя и обеспечить непрерывное обслуживание, когда некоторые компоненты системы терпят неудачу. Kластеры HA состоит из множества узлов, которые взаимодействуют и обмениваются информацией через общие сетках памяти данных и являются отличным способом, чтобы обеспечить высокую доступность системы, надежность и масштабируемость.
Учитывая эти разнообразные элементы высоко-доступность требует:
-
Тщательное и полное планирование физических и логических процедур доступа и эксплуатации ресурсов, от которых зависит приложение. Эти процедуры помогают избежать сбоев в первую очередь.
-
Пакет мониторинга и восстановления, что позволяет автоматизировать обнаружение и восстановление после ошибок.
-
Хорошо контролируемый процесс для поддержания аппаратных и программных аспектов конфигурации кластера, сохраняя при этом доступны приложения.
Отказоустойчивый кластеры предоставляют решение задач, таких как:
-
24 часа в сутки 7 дней недели любые приложения готовы к запуску, независимо от отказов в работе операционной системы, устройств хранения, приложения или инфраструктуры;
-
держать очень высокий показатель SLA (перевыполнение обязательств);
-
при предоставляемом оборудовании (базе, инфраструктуре) гарантировать максимальную высокую доступность;
-
обеспечение целостности и доступности приложения в кластере, а также ПО;
-
быстрое восстановление данных при поломках;
-
уменьшение количество сбоев, чтобы не происходило простоев ОС, а также увеличение скорости развертывания нового оборудования;
-
тщательный контроль за доступностью очень важных приложениями, таких как базы данных;
-
гарантирование высокой доступности в виртуальных, реальных и смешанных средах.
Преимущества высокой доступности:
-
все компоненты стандартизированы и могут быть запущенные на существующих серверах и машинах;
-
могут кластеризовать большую часть существующих приложений
-
могут работать с очень большим вариантом
-
работают практически со всеми приложениями (зависит только от умения того, кто осуществляет внедрение);
-
работают с большинством существующих типов дисков и сетей;
-
стоимость таких приложений относительно невысока.
-
Непрерывная доступность (Fault tolerant)
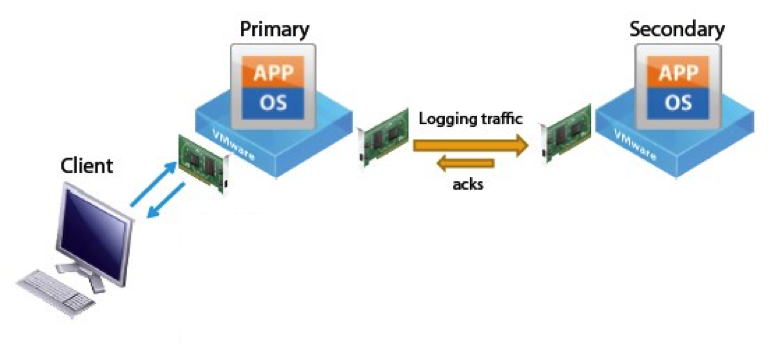
Для того, чтобы можно было предоставить полностью отказоустойчивый сервис, нужно, чтобы постоянно была точная копия узла, на котором запущен необходимый сервис. При создании копии после поломки оборудования придется потратить некоторое время на копирования или может случиться ситуация, при которой невозможно будет достать необходимую информацию из проблемного узла и это приведет к утере информации.
Именно для таких ситуаций существует способ создания непрерывно доступного кластера. Существует два способа реализации такого решения: аппаратный и программный.
Аппаратный способ
При этом способе создаются два сервера, один из которых выполняет запросы, а другой полностью его копирует. При этом они оба независимо производят вычисления. Также есть узел, который проверяет и сверяет получившиеся результаты и выполняет поиск ошибок. Если невозможно исправить получившуюся ошибку, то сервер, который считается неисправным, отключается.
В этом случае оборудование будет простаивать не более 32 секунд в год. Чтобы получить такие результаты необходимо пожертвовать большими деньгами на приобретение данного оборудования. По подсчетам одной российской компании на данный кластер придется потратить порядка $1 600 000
Программный способ.
Самым известным программным продуктом для реализации непрерывно доступного кластера в настоящее время является vSphere от VMware.
Но данный способ реализации имеет свои ограничения, такие как:
-
Определенный процессор на физической машине
-
Intel архитектуры Sandy Bridge (или новее). Avoton не поддерживается.
-
AMD Bulldozer (или новее).
-
Сетка, с пропускной способностью в 10-гигабит, через которую общаются виртуальные машины
-
Количество виртуальных машин на физической не должно превышать 8
-
Количество виртуальных процессов виртуальной машины не более 4
-
Количество виртуальных процессов на хосте не более 8
-
Не поддерживаются снэпшоты
-
ISO-образы должны быть находиться в общем хранилище, чтобы все машины имели к ним доступ.
Было проведено несколько экспериментов, результатами которых стал вывод, что при использовании FT от VMware виртуальные машины начинали работать значительно медленнее, производительность упала на
47%.
запланированные:
-
замена оборудования; -
обслуживание; -
обновление программного обеспечения; -
резервное копирование (автономное резервное копирование); -
тестирование (периодическое тестирование необходимо для проверки кластеров); -
разработка;
незапланированные:
-
ошибки администратора; -
отказы приложений; -
отказы оборудования; -
ошибки операционной системы; -
стихийные бедствия.
базы данных;
системы управления ресурсами предприятия (ERP);
средства обработки сообщений и почтовые системы;
средства обработки транзакций через Web и Web-серверы;
системы взаимодействия с клиентами (CRM);
системы разделения файлов и печати.
отказоустойчивые кластеры (High-availability clusters, HA, кластеры высокой доступности)
кластеры непрерывной доступности (Fault tolerant)
вычислительные кластеры
с холодным резервом или активный/пассивный. В этом случае активный узел обрабатывает все запросы, а пассивный включается в работу только лишь при отказе активного. Пример — резервные сетевые соединения, в частности, Алгоритм связующего дерева. Например связка DRBD и HeartBeat.
с горячим резервом или активный/активный. Все ноды принимают и обрабатывают запросы, и при отказе одного из них, нагрузка распределяется по оставшимся нодам. Следовательно, при отказе одного узла кластер переконфигурируется. Примеры — практически все кластерные технологии, например, Microsoft Cluster Server. OpenSource проект OpenMosix.
с модульной избыточностью. Данный вариант самый трудозатратый. Его используют только в случаях, когда простой системы невозможен. В это конфигурации один и тот же запрос может выполняться несколькими узлами и выдается результат любого узла. Следовательно, очень важно, чтобы результаты всех узлов были идентичными (либо различия незначительны). Примеры — RAID и Triple modular redundancy.
Тщательное и полное планирование физических и логических процедур доступа и эксплуатации ресурсов, от которых зависит приложение. Эти процедуры помогают избежать сбоев в первую очередь.
Пакет мониторинга и восстановления, что позволяет автоматизировать обнаружение и восстановление после ошибок.
Хорошо контролируемый процесс для поддержания аппаратных и программных аспектов конфигурации кластера, сохраняя при этом доступны приложения.
24 часа в сутки 7 дней недели любые приложения готовы к запуску, независимо от отказов в работе операционной системы, устройств хранения, приложения или инфраструктуры;
держать очень высокий показатель SLA (перевыполнение обязательств);
при предоставляемом оборудовании (базе, инфраструктуре) гарантировать максимальную высокую доступность;
обеспечение целостности и доступности приложения в кластере, а также ПО;
быстрое восстановление данных при поломках;
уменьшение количество сбоев, чтобы не происходило простоев ОС, а также увеличение скорости развертывания нового оборудования;
тщательный контроль за доступностью очень важных приложениями, таких как базы данных;
гарантирование высокой доступности в виртуальных, реальных и смешанных средах.
все компоненты стандартизированы и могут быть запущенные на существующих серверах и машинах;
могут кластеризовать большую часть существующих приложений
могут работать с очень большим вариантом
работают практически со всеми приложениями (зависит только от умения того, кто осуществляет внедрение);
работают с большинством существующих типов дисков и сетей;
стоимость таких приложений относительно невысока.
-
Непрерывная доступность (Fault tolerant)
Определенный процессор на физической машине
-
Intel архитектуры Sandy Bridge (или новее). Avoton не поддерживается. -
AMD Bulldozer (или новее).
Сетка, с пропускной способностью в 10-гигабит, через которую общаются виртуальные машины
Количество виртуальных машин на физической не должно превышать 8
Количество виртуальных процессов виртуальной машины не более 4
Количество виртуальных процессов на хосте не более 8
Не поддерживаются снэпшоты
ISO-образы должны быть находиться в общем хранилище, чтобы все машины имели к ним доступ.
Для каждой физической машины необходимо приобретать свою лицензию. Тем самым необходимо потратить минимум $1750 на одну лицензию, а также приобрести годовую подписку на техподдержку за + $550. Стоимость такого кластера может составлять $100 000
Поэтому кластеры непрерывной доступность лучше использовать только в крайних случаях. Только если от приложения требуется постоянная доступность, или сервера используют очень часто или же, если сервера действительно очень важны.
Таким образом, несмотря на преимущества систем непрерывной доступности, есть немало трудностей при внедрении и эксплуатации таких решений.
1.2.3 Вычислительные кластеры
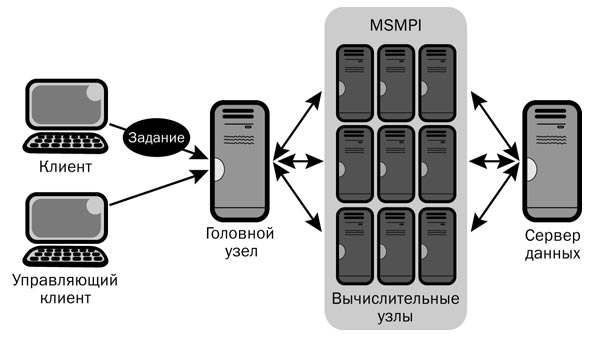
Этот вид кластеров необходим, когда нужно в очень быстрый срок произвести большое количество вычислений, в частности, когда производятся научные исследования. Для таких серверов более важна скорость и качество проведения вычислений, и не очень важно скорость операций ввода-вывода. Вычислительные кластера разделяют вычисления на параллельные ветки. Для того, чтобы эти ветки могли обмениваться данными, есть специальные сетевые каналы.
В каждой конфигураций кластера существует головная машина, которая регулирует работу остальных нод кластера. Сами вычислительные процессы происходят на вычислительных узлах, при этом количество вычислительных процессов не превышает количества процессоров на узле.. На головном узле не происходит никаких вычислений.
Пользователь обращается только к головному узлу. Доступа к вычислительным узлам у него не должно быть. Программа и пользователь не взаимодействуют друг с другом, нет нужды вводить что-либо с клавиатуры или ждать вывода на экран. Пользователь не следит за тем, как происходят вычисления.
На вычислительных серверах устанавливается операционная ситсема семейства ОС Unix, так как эта ОС поддерживает многопользовательский и многозадачный режимы.
Для всех узлов существует общая файловая система, к которой может обратиться любой вычислительный узел. Для этой файловой системы выделен специальный файл-сервер. Но при этом несколько узлов не могут одновременно записывать данные в один файл, но могут записывать в разные. Также возможно создать локальный диск на каждом вычислительном узле кластера. В них можно хранить какие-нибудь временные файлы, которые удаляются при завершении работы программы.
Типовые задачи для расчетных кластеров:
-
решение задач механики жидкости и газа, теплопередачи и теплообмена, электродинамики, акустики; -
моделирование аэрогазодинамических процессов; -
моделирование физико-химических процессов и реакций; -
моделирование сложного динамического поведения различных механических систем; -
решение задач цифровой обработки сигналов, финансового анализа, разнообразных математических задач, визуализации и представления данных -
анализ и расчет статической и динамической прочности; -
газодинамика, термодинамика, теплопроводность и радиочастотный анализ; -
моделирование задач любой степени геометрической сложности; -
рендеринг анимации и фотореалистичных VFX эффектов