Файл: Анализ многоуровневой обработки речевых сигналов при наличии шумов.docx
Добавлен: 22.11.2023
Просмотров: 55
Скачиваний: 2
СОДЕРЖАНИЕ
1.4 Распознавание речевых сигналов
Точность распознавания зависит от модели распознавания. Также на точность распознавания влияют:
2. Качество кодирования аудио;
Предварительная обработка речевого сигнала
Рис. 1. Пример семантического облака темы «Восстановление пароля»
2.1 Методы, основанные на оценке спектральных характеристик шума
2.2 Динамическое шумоподавление
2.3 Определения эффективности очистки речевых сигналов разработанным алгоритмом
2.4 Разработка схемы работы программы
2.1 Методы, основанные на оценке спектральных характеристик шума
3. "Вычитание" амплитудного спектра шума из амплитудного спектра сигнала.
4. Обратное преобразование - синтез результирующего сигнала.
2.2 Динамическое шумоподавление
2.3 Определения эффективности очистки речевых сигналов разработанным алгоритмом

Министерство образования и науки Республики Казахстан
Академия логистики и транспорта
Кафедра «Информационно-коммуникационные технологии»
Отчет по преддипломной практике
на тему: «Анализ многоуровневой обработки речевых сигналов при наличии шумов»
| |
Выполнила
студентка гр. РЭТ-19-2 А.А.Сакенова
Научный руководитель,
PhD, ассоц.проф.АЛТ А.М.Достиярова
 Алматы, 2023
Алматы, 2023Министерство образования и науки Республики Казахстан
Академия логистики и транспорта
Сакенова Алия Алтаевна
Анализ многоуровневой обработки речевых сигналов при наличии шумов
ДИПЛОМНАЯ РАБОТА
Образовательная программа: 6В06209-Радиотехника, электроника и телекоммуникации
Алматы, 2023СОДЕРЖАНИЕ
ВВЕДЕНИЕ 4
ВВЕДЕНИЕ
Речевой сигнал можно рассматривать с помощью модели, в которой речевой сигнал является откликом системы с медленно изменяющимися параметрами на периодическое или шумовое возбуждающее колебание. По существу речеобразующий механизм (голосовой тракт) является акустической трубкой, возбуждаемой соответствующим источником при создании желаемого звука. Для звонких звуков источнику возбуждения соответствует квазипериодическая последовательность импульсов, представляющая поток воздуха, протекающий через колеблющиеся голосовые связки. Речевой сигнал можно промоделировать откликом линейной системы с переменными параметрами (голосового тракта) на соответствующий возбуждающий сигнал. При неизменной форме голосового тракта выходной сигнал равен свертке возбуждающего сигнала и импульсного отклика голосового тракта. Однако все разнообразие звуков получается путем изменения формы голосового тракта. Частотная характеристика голосового тракта является гладкой функцией частоты; поскольку голосовой тракт представляет собой полость, то в первую очередь он характеризуется акустическими резонансами, соответствующими резонансным частотам этой полости, которые обычно называются формантными частотами. Спектр речевого сигнала образуется перемножением линейчатого спектра возбуждающего сигнала и спектра, соответствующего голосовому тракту, и, следовательно, тоже является линейчатым, а его огибающая характеризует передаточную функцию голосового тракта. Поскольку при создании различных звуков форма голосового тракта изменяется, огибающая спектра речевого сигнала будет конечно тоже изменяться с течением времени. Аналогично при изменении периода сигнала, возбуждающего звонкие звуки.
Способы представления речевых сигналов: от простейшей периодической дискретизации речевого сигнала до оценок параметров модели. Выбор того или иного способа представления речевого сигнала определяется решаемой задачей, которые разделяются на три класса. К первому классу относят задачи, связанные с анализом речи. Анализ речи является неотъемлемой частью систем распознавания речевых сигналов, а также систем идентификации дикторов по голосу. Ко второму классу относят задачи, связанные с синтезом речи по тексту. Задачи такого типа возникают в многочисленных информационно-справочных системах. В задачах, относящихся к третьему классу, выполняется как анализ системы сжатия речевых сигналов с целью передачи речи по компьютерным сетям или по традиционным линиям связи. Одним из перспективных направлений применения обработки речевых сигналов являются системы распознавания речи в сети Интернет. В этом случае пользователь сети, используя телефон, может соединиться с программой распознавания речи, находящейся на сервере и транслирующей диалог в команды Веб-сервера. Это позволяет получить доступ к распределенным информационным ресурсам сети по телефону.
.
1. Классификация существующих методов обработки применяемых в системах распознавания речи
В настоящее время существуют многочисленные технические средства, могущие воспринимать (распознавать) произносимые речевые сообщения: компьютеры, медицинское электронное оборудование, автомобили, мобильные телефоны и др. Что такое распознавание речи? На первый взгляд, все кажется очень просто: человек произносит слово (фразу), а техническая система адекватно реагирует на него: либо выполняет команду, содержащуюся в слове (фразе), либо набирает диктуемый текст, либо как-то иначе “распоряжается” извлеченной из фразы информацией. Бурное развитие распознавания речи с помощью персонального компьютера началось с 1993 г. Две ключевых задачи распознавания речи – достижение 100 % распознавания на ограниченном наборе команд хотя бы для одного диктора и независимое от диктора распознавание непрерывного речевого потока в реальном масштабе времени произвольного языка с приемлемым качеством – не решены, несмотря на многочисленные попытки решения этих задач в течение последних 50-ти лет. Современные системы распознавания речи уже дают возможность пользователям диктовать слова (фразы) в обычной разговорной манере. Однако процесс непрерывного распознавания речи, дающий до 95 % качества распознавания при оптимальных условиях, все-таки дает на 100 знаков 5 ошибок. Около 200 ошибок на странице формата A4 – слишком много для профессиональной работы. При рассмотрении классификации систем распознавания речи следует отметить, что классификация может осуществляться по различным параметрам. Системы распознавания речи можно классифицировать следующим образом: в зависимости от размера словаря: системы распознавания речи с ограниченным набором слов; системы со словарем большого размера; в зависимости от привязки к диктору: системы, являющиеся дикторо-зависимыми и дикторо-независимыми; в зависимости от типа распознаваемой речи: системы, работающие со слитной речью или раздельной речью.
Рисунок 2.1 - Схема ввода речевых сообщений в ЭВМ
Речевой сигнал формируется и передается в пространстве в виде звуковых волн. Источником речевого сигнала служит речеобразующий тракт, который возбуждает звуковые волны в упругой воздушной среде. Приемником сигнала является датчик звуковых колебаний, микрофон - устройство для пре-образования звуковых колебаний в электрические. Существует большое количество типов микрофонов (угольные, электродинамические, электрос-татические, пьезоэлектрические и др.) описанных в специальной литературе. Чувствительным элементом микрофона любого типа является упругая мембрана, которая вовлекается в колебательный процесс под воздействием звуковых волн.
1.1 Детектирование голосовой активности
Детектор голосовой активности - это критически важный компонент системы распознавания речи, который значительно влияет на её точность и производительность. При правильном выделении участков звука, в которых присутствует целевой голосовой сигнал, детектор наличия голоса значительно уменьшает объём данных для обработки системой распознавания речи, что в итоге ускоряет её работу и уменьшает вероятность ложных распознаваний. Особенно это свойство важно при работе систем распознавания речи на персональных устройствах пользователей – смартфонах, ноутбуках, смарт-телевизорах, у которых в отличии от специализированных серверов ограничена процессорная мощность. На базе раннее разработанного авторами линейного 8-ми канального массива MEMS микрофонов с PDM интерфейсом [15] был спроектирован в SolidWorks и изготовлен прототип устройства для аудиовизуального детектирования голосовой активности, представленный на рис. 1. Прототип состоит из трёх печатных плат:

Рис.1. Версия массива микрофонов со встроенной видеокамерой
Прототип по USB шине подключается к компьютеру с видеокартой с поддержкой технологии CUDA, на котором производятся все вычисления. Метод детектирования голосовой активности показал высокое качество разметки голосового сигнала, которое при соблюдении нахождения говорящего человека в поле видимости видеокамеры превышает результаты, показываемые детекторами голоса, использующими только звуковую информацию.
1.2 Оценка качества и разборчивости речи
Применение современных методов компьютерной оценки разборчивости речи является очень полезным при работе звукорежиссера в студиях и театрально-концертных залах (особенно если в них установлена система звукоусиления), а также при оценке качества речевых сигналов при передаче по каналам радиовещания, телефонии, в системах перевода речей и пр. опыт проектирования залов различного назначения (аудиторий, лекционных залов, кинозалов, театральных залов и др.) и результаты многочисленных исследований показали, что разборчивость речи в помещении определяют следующие акустические характеристики:
Уровень прямого речевого сигнала во всех точках зала;
Уровень внешних и внутренних шумов;
Время реверберации;
Структура, уровень и направление прихода отраженных сигналов.
Влияние реверберационного процесса на структуру речевого сигнала можно отчетливо увидеть на примере осциллограмм, записанных в заглушенной камере и в помещении с большим значением реверберации (рис.1). Естественно, что при таком существенном изменении временной структуры речевого сигнала процесс его распознавания существенно ухудшается.
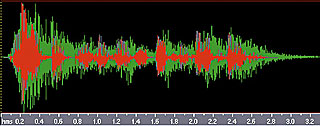
Рис.1 Осциллограмма речевого сигнала в заглушенной камере и в помещении
1.3 Подавление шума
Подавление шума – это то, что подразумевает конструкция и материалы наушников и гарнитур. По сути, это уровень изоляции от внешнего шума, который может обеспечить устройство само по себе, без учета электронных компонентов и алгоритмов. Проще говоря, это то, насколько хорошо наушники справляются с функцией берушей. Шумоподавление достигается путем использования аналоговых или цифровых фильтров и различается по типам реализации — шумоподавление с обратной связью, без обратной связи, а также гибридное. Качественная технология активного подавления шума значительно улучшает акустические характеристики наушников и гарнитур с хорошим пассивным шумоподавлением.

Типичный пример гарнитуры с активным шумоподавлением