Файл: Анализ многоуровневой обработки речевых сигналов при наличии шумов.docx
Добавлен: 22.11.2023
Просмотров: 52
Скачиваний: 2
СОДЕРЖАНИЕ
1.4 Распознавание речевых сигналов
Точность распознавания зависит от модели распознавания. Также на точность распознавания влияют:
2. Качество кодирования аудио;
Предварительная обработка речевого сигнала
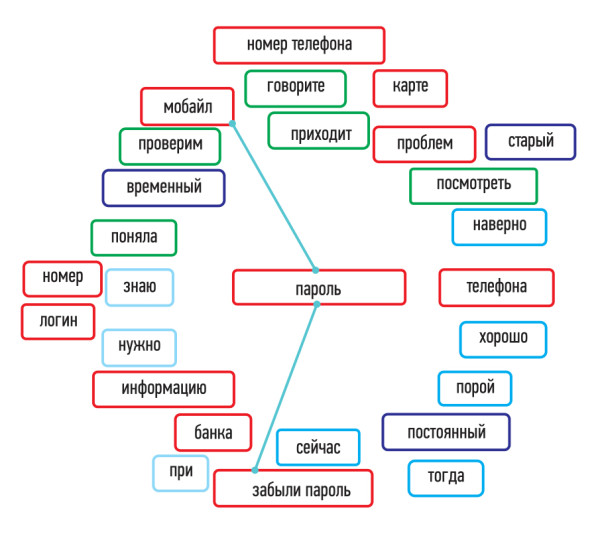
Рис. 1. Пример семантического облака темы «Восстановление пароля»
2.1 Методы, основанные на оценке спектральных характеристик шума
2.2 Динамическое шумоподавление
2.3 Определения эффективности очистки речевых сигналов разработанным алгоритмом
2.4 Разработка схемы работы программы
2.1 Методы, основанные на оценке спектральных характеристик шума
3. "Вычитание" амплитудного спектра шума из амплитудного спектра сигнала.
4. Обратное преобразование - синтез результирующего сигнала.
2.2 Динамическое шумоподавление
2.3 Определения эффективности очистки речевых сигналов разработанным алгоритмом
Предварительная обработка речевого сигнала
Преобразование речевого аудио в формат данных, используемый системой ML, является начальным этапом процесса распознавания говорящего. Начните с записи речи с помощью микрофона и преобразования аудиосигнала в цифровые данные с помощью аналого-цифрового преобразователя. Дальнейшая обработка сигнала обычно включает в себя такие процессы, как обнаружение голосовой активности (VAD), подавление шума и выделение признаков. Мы рассмотрим каждый из этих процессов позже. Во-первых, давайте рассмотрим некоторые ключевые методы предварительной обработки речевого сигнала: масштабирование функций и преобразование стерео в моно. Поскольку диапазон значений сигнала сильно варьируется, некоторые алгоритмы машинного обучения не могут должным образом распознавать звук без нормализации. Масштабирование объектов - это метод, используемый для нормализации диапазона независимых переменных или признаков данных. Масштабирование данных устраняет разреженность, приводя все ваши значения к одному масштабу, следуя той же концепции, что и нормализация и стандартизация. Например, вы можете стандартизировать свои аудиоданные с помощью sk. Количество каналов в аудиофайле также может влиять на производительность вашей системы распознавания громкоговорителей. Аудиофайлы могут быть записаны в моно- или стереоформате: моно-аудио имеет только один канал, в то время как стереозвук имеет два или более каналов. Преобразование стереозаписей в моно помогает повысить точность и производительность системы распознавания громкоговорителей. Python предоставляет модуль pydub, который позволяет воспроизводить, разделять, объединять и редактировать аудиофайлы WAV. Вот как вы можете использовать его для преобразования стереофонического WAV-файла в монофонический файл.Анализ и обработка речи
К технологиям анализа и обработки речи относят быстрый поиск ключевых слов в аудиозаписях, автоматический анализ и оценку телефонных переговоров, интеллектуальный анализ речевой информации. Даннная технология отличается простотой использования и точностью поиска в фонограммах, которая определяется поисковым словарем. Так, для словаря из пяти слов надежность поиска составляет не менее 95%, для словаря из 100 слов — 81%. Интеллектуальный анализ речевой информации позволяет автоматически определять тематику телефонных переговоров. В основе анализа лежат технологии распознавания слитной речи. В результате автоматического распознавания речь дикторов преобразуется в текстовый индексированный файл, пригодный для автоматического лексико-семантического анализа. Решение о принадлежности аудиозаписи к абстрактному тематическому кластеру проводится с учетомчастотности и связности слов и словосочетаний, употребляемых дикторами в ходе телефонной беседы (рис. 1).