Файл: Применение точечного и интервального оценивания в экономике. Примеры применения. Погрешность оценки.docx
Добавлен: 12.12.2023
Просмотров: 65
Скачиваний: 4
ВНИМАНИЕ! Если данный файл нарушает Ваши авторские права, то обязательно сообщите нам.
Следует отметить, что несмещенность и состоятельность являются желательными свойствами оценок, но не всегда разумно требовать наличия этих свойств у оценки. Например, может оказаться предпочтительней оценка хотя и обладающая небольшим смещением, но имеющая значительно меньший разброс значений, нежели несмещенная оценка. Более того, есть характеристики, для которых нет одновременно несмещенных и состоятельных оценок.
Оценки для математического ожидания и дисперсии
Пусть случайная величина имеет неизвестные математическое ожидание и дисперсию, причем
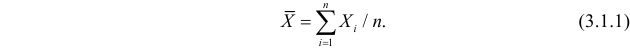
Несмещенность такой оценки следует из равенств
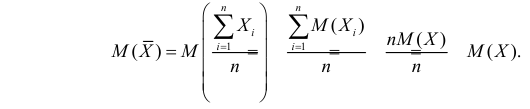
В силу независимости наблюдений
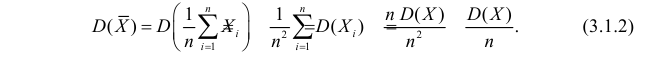
При условии
Доказано, что для математического ожидания нормально распределенной случайной величины оценка
Оценка математического ожидания посредством среднего арифметического наблюдаемых значений наводит на мысль предложить в качестве оценки для дисперсии величину

Преобразуем величину
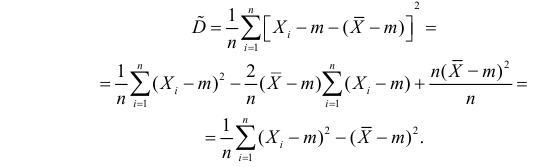
В силу (3.1.2) имеем
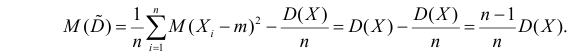
Последняя запись означает, что оценка
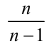 и полученную оценку обозначим через
и полученную оценку обозначим через 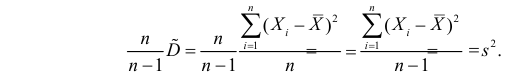
Величина
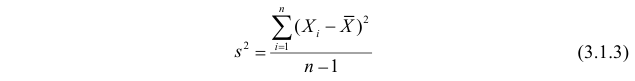
является несмещенной и состоятельной оценкой дисперсии.
Пример:
Оценить математическое ожидание и дисперсию случайной величины Х по результатам ее независимых наблюдений: 7, 3, 4, 8, 4, 6, 3.
Решение. По формулам и имеем
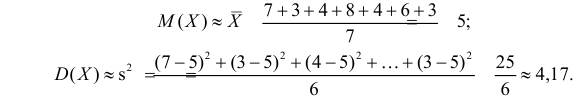
Ответ.
2 Интервальное оценивание
Мы рассмотрели оценки неизвестных параметров закона распределения случайной величины Х по данным выборки. Получаемые при этом точечные оценки гi не совпадают (за исключение редких случаев) с истинным значением неизвестных параметров аi. Следовательно, всегда имеется некоторая погрешность при замене неизвестного параметра его оценкой, т.е. |г - а|<:
(1.1)
И если эта вероятность близка к единице, т.е. если,то диапазон практически возможных значений ошибки, возникающей при замене а на, равен . Причем большие про абсолютной величине ошибки появляются с вероятностью , >0.
Чем меньше для данного >0 будет >0, тем точнее оценка г. Из соотношения (1.1) видно, что вероятность тог, что интервал г - ; г+ со случайными концами накроет неизвестный параметр, равна 1 - . Эта вероятность называется доверительной вероятностью.
Случайный интервал, определяемый результатами наблюдений, который с заданной вероятностью а = 1 - накрывает неизвестный параметр а, называемый доверительным интервалом для параметра а, соответствующим доверительной вероятности а = 1 - .
Граничные точки доверительного интервала называются соответственно нижним и верхним доверительным пределами.
Заданному а = 1 - соответствует неединственный доверительный интервал. Доверительные интервалы могут изменяться от выборки к выборке. Более тог, для данной выборки различные методы построения доверительных интервалов могут привести к различным интервалам. Поэтому выработаны определенные правила. Используя их и эффективные оценки неизвестных параметров, получают кратчайшие интервалы для заданной доверительной вероятности а = 1 - .
Рассмотрим общие принципы построения доверительных интервалов. Предположим, что доверительный интервал находим для некоторого параметра а совокупности и в качестве точечной оценки этого параметра возьмем выборочную несмещенную М(г) = а и эффективную оценку г = г(Х1; Х2;… Хn), имеющую среднее квадратическое отклонение г.
Если бы закон распределения оценки г был известен, то для нахождения доверительного интервала нужно было бы найти такое значение , для которого . Но закон распределения оценки г зависит от закона распределения случайной величины Х и, следовательно, от его неизвестного параметра а. Для того чтобы не применять закон распределения случайной величины Х, поступают следующим образом.
Так как мы считаем значение выборки х1, х2, х3,…,хn, имеющими те же законы распределения, что и исследуемая случайная величина Х, то, согласно центральной предельной теореме (теоретическое выборочное распределение средних при большом n может быт хорошо аппроксимировано соответствующим нормальным распределением параметрами М() = М() и , большинство числовых характеристик выборки имеют нормальное или близкое значение к нормальному выборочное распределение.
Поэтому с помощью вероятностей, которые находим из таблиц нормального распределения, где , для заданного можно найти такое интервал г - ; г+ , в котором лежит значение г, вычисленное по данной выборке можно решить и обратную задачу: по данной вероятности найти значение
, такое что .
Неравенства а - ? г ?а + эквивалентны неравенствам г - ? а ? г + (вычтем г - из каждой части и умножим на -1). Тем самым указаны методы построения доверительных интервалов г - ; г + для параметра а.
Таким образом, при построении доверительных интервалов составляется случайная величина Y (например, , связанная с неизвестным параметром а, его оценкой и имеющая известную плотность распределения вероятностей p(y). Используя эту плотность, определим доверительный интервал по формуле .
В качестве доверительно вероятности (иначе - уровня доверия) обычно полагают
а =0,95 (0,99). Это значит, что при извлечении n выборок из одной и той же генеральной совокупности доверительный интервал примерно в 95% (99%) случаев будет накрывать неизвестный параметр (относительно неизвестного параметра вероятные события не допускаются). При увеличении же доверительной вероятности строится более широкий доверительный интервал, который малопригоден для практики. Еще раз подчеркнем, что чем меньше длина доверительного интервала, тем точнее оценка.
Отметим, что для точного нахождения доверительных интервалов необходимо знать закон распределения случайной величины Х, тогда как для применения приближенных методов это не обязательно.
Заключение
Итак, сформулированы правила непараметрического оценивания обычно используемых характеристик распределения случайной величины. Эти правила основаны на асимптотических результатах теории вероятностей и математической статистики. Использование методов, разработанных в предположении нормальности распределения, может привести к заметно искаженным выводам в ситуации, когда гипотеза нормальности не выполнена. Практические рекомендации таковы: при анализе реальных данных следует использовать непараметрические доверительные границы.
Новая парадигма математических методов исследования требует перехода от параметрических статистических методов к непараметрическим. Непараметрическая статистика - одна из точек роста современной прикладной статистики. Непараметрические статистические методы являются важной составной частью перспективных математических и инструментальных методов контроллинга
Список используемых источников
1. Орлов А.И. Вероятность и прикладная статистика: основные факты: справочник. – М.: КноРус, 2020. – 192 с.
2. Орлов А.И. Современное состояние непараметрической статистики // Политематический сетевой электронный научный журнал Кубанского государственного аграрного университета. 2015. № 106. С. 239–269.
3. Орлов А.И. Часто ли распределение результатов наблюдений является нормальным? // Заводская лаборатория. Диагностика материалов. 2021. Т.57. №7.С.64-66.
4. Орлов А.И. Организационно-экономическое моделирование : учебник : в 3 ч. Ч.3. Статистические методы анализа данных. - М.: Изд-во МГТУ им. Н.Э. Баумана, 2021. - 624 с.