Файл: Научнообразовательный журнал для студентов и преподавателей.docx
ВУЗ: Не указан
Категория: Не указан
Дисциплина: Не указана
Добавлен: 03.02.2024
Просмотров: 72
Скачиваний: 1
ВНИМАНИЕ! Если данный файл нарушает Ваши авторские права, то обязательно сообщите нам.
Большинство аналитических методов, используемые в технологии Data Mining
– это известные математические алгоритмы и методы.
Важно понимать, что информация, полученная в процессе применения методов сбора данных, должна быть нетривиальной и ранее неизвестной, например, средние продажи не являются таковыми. Знания должны описывать новые отношения между свойствами, предсказывать значения одних признаков на основе других и т.д. Найденные знания должны быть применимы и на новых данных с некоторой степенью достоверности. Полезность заключается в том, что эти знания могут приносить определенную выгоду при их применении. Знания должны быть в форме, понятной пользователю, а не в математическом виде.
Задачи, решаемые методами Data Mining:
-
Классификация – это отнесение объектов (наблюдений, событий) к одному из заранее известных классов. -
Регрессия, в том числе задачи прогнозирования. Установление зависимости непрерывных выходных от входных переменных. -
Кластеризация – это группировка объектов (наблюдений, событий) на основе данных (свойств), описывающих сущность этих объектов. Объекты в кластере должны быть "похожими" друг на друга и отличаться от объектов, включенных в другие кластеры. Чем больше похожих
объектов внутри кластера и чем больше различных кластеров, тем точнее кластеризация.
-
Ассоциация – определение закономерности между связанными событиями. Примером такого шаблона является правило, указывающее, что событие X следует за событием Y. Такие правила называются ассоциативными правилами. Изначально эта задача была разработана для поиска типичных моделей покупок, сделанных в супермаркетах, поэтому ее иногда также называют анализом рыночной корзины (market basket analysis). -
Последовательные шаблоны – определение закономерностей между связанными во времени событиями, т.е. обнаружение такой зависимости, что если произойдет событие X, то спустя заданное время произойдет событие Y. -
Анализ отклонений – выявление наиболее нехарактерных шаблонов.
6. Практическая часть.
Бывает, что для выполнения конкретной задачи нужно найти сотни и тысячи номеров, адресов страниц в социальных сетях на сотнях сайтов при определенных условиях и запросах, но управлять таким объемом информации вручную невозможно. Некоторая информация также может быть скрыта от глаз пользователя, но она содержится в коде веб-сайта. Тогда к нам на помощь и приходят парсеры.
Специальные программы анализируют код страницы с помощью различных алгоритмов от совсем простых до сложнейших статистических моделей с использованием теории хаоса и нейронных сетей.
Мы разработаем парсер сайтов на языке Python, который будет обрабатывать информацию с сайтов, продающих автомобили. Получив, обработанные данные, проверим их на адекватность, удалим ошибочные записи (при наличии таковых), при необходимости декодируем. Затем сможем оценить эффективность работы парсера путем оценки качества, полученных данных. Если полученные данные
будут в удобоваримом виде, будем считать, что парсеры – простой и современный способ обработки больших данных.
Код парсера можно посмотреть в репозитории GitHub по ссылке: https://github.com/mistergahan/BigData
Для примера попробуем работать с относительно небольшими объемами данных. Пропарсим сайт Auto.ru, а точнее соберем все автомобили марки Opel на рынке.
Получим датасет (.csv файл) со следующими данными (см. Рис.1).
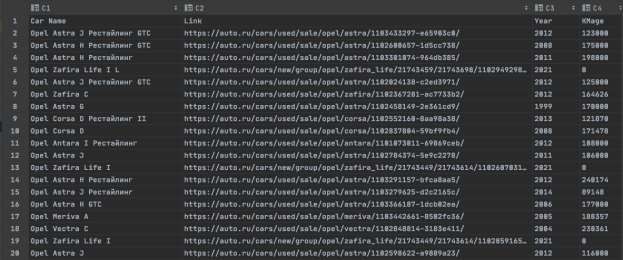
Рис.1.Первые20
строкполученногофайла
Данные читаемы, пропусков нет, можем перейти непосредственно к анализу полученного датастета.
Для анализа полученных данных будем использовать Anaconda Jupiter Notebook. Посмотрим, как коррелируют между собой и распределяются год выпуска и пробег автомобиля.
Выведем первые 5 строк датасета (см. Рис. 2).
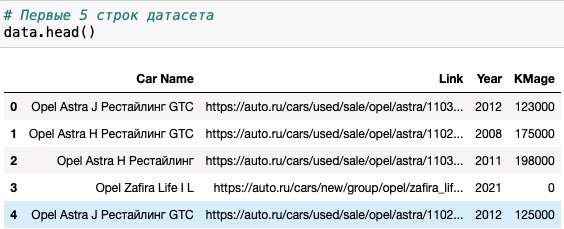
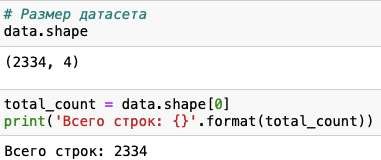 Рис. 2. Первые 5 строк полученного файла в Jupiter NotebookМожем убедиться, что все поля отображаются корректно и без пропусков. Выведем размер датасета и типы данных в колонках (см. Рис.3).
Рис. 2. Первые 5 строк полученного файла в Jupiter NotebookМожем убедиться, что все поля отображаются корректно и без пропусков. Выведем размер датасета и типы данных в колонках (см. Рис.3).Рис.3.Размерполученногофайла
Просмотрим типы данных чтобы понимать, как их анализировать (см. Рис.4).
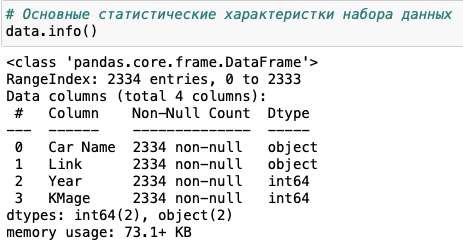
Рис.4.Списокколонокитипыпредставленныхданных
Используем метод seaborn, чтобы оценить плотность распределения пробега автомобилей марки Opel (см. Рис.5).
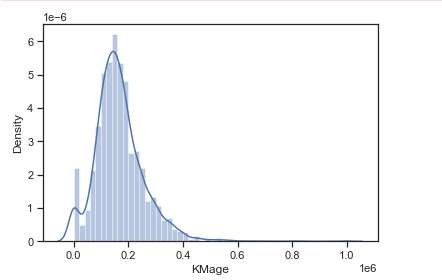
Рис.5.РаспределениепробегаавтомобилеймаркиOpel
Теперь построим обычную гистограмму, показывающую частотное распределение Года выпуска и Пробега авто (см. Рис. 6).
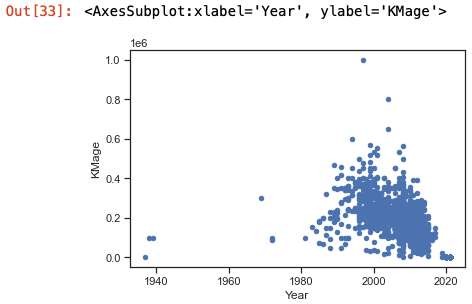
Рис.6.ЧастотноераспределениеГодавыпускаипробегаавтомобилей
маркиOpel
Добавим линию линейной регрессии, чтобы наглядно увидеть отклонение от моды (см. Рис. 7).
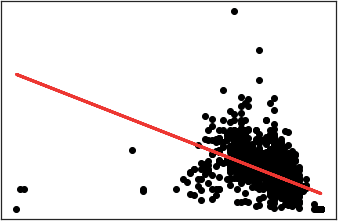
Рис. 7. Частотное распределение Года выпуска и пробега автомобилеймаркиOpelсЛинейнойрегрессией (выделена красным)
Из полученного графика мы видим, что распределение Года выпуска и Пробега авто далеко не линейно, как мы могли предполагать заранее. В то время как у части автомобилей на рынке распределение действительно происходит линейно, у большой доли соотношение год/пробег значительно выбивается из моды.
Из последнего графика явно видно, что присутствуют даже явно заметные аномалии, когда у автомобиля с возрастом сохраняется малое число пройденных километров. Если посмотреть, спаршенный нами ранее датасет, то мы можем без труда выявить подобные примеры (см Рис. 8 - 11).
Рис. 8. Запись в датасете с аномально низким значением пробега для годавыпуска авто.
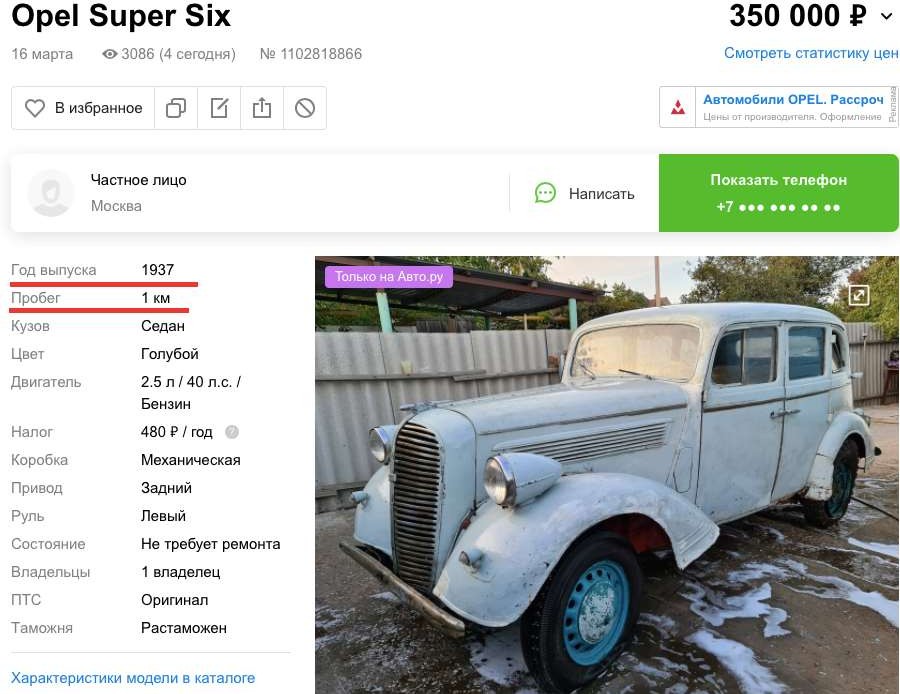
Рис. 9. Карточка автомобиля с аномально низким значением пробега длягода выпусканасайтеauto.ru.
Рис.10.Записьвдатасетесаномальновысокимзначениемпробегадлягода
выпускаавто

Рис. 11. Карточка автомобиля с аномально высоким значением пробега длягода выпусканасайтеauto.ru.
Заключение
В данной статье автор работы рассмотрел понятие Big Data и убедился в актуальности данной тематики. В частности, был затронут метод Data Mining и разработан свой скрипт,
который позволил оперативно добывать данные с сайта Auto.ru в удобном для анализа формате. Проанализировав полученную выборку при использовании методов машинного обучения, было обнаружено, что распределение пробега автомобилей относительно года их выпуска происходит не по линейному закону и нашли обоснование данному феномену.
Дальнейшими шагами по развитию данной тематики может быть расширение функциональности скрипта с целью его унивесификации.
Литература
-
Хабрахабр. Аналитический обзор рынка Big Data // Электронный ресурс
-
https://habrahabr.ru/company/moex/blog/256747/
Шаньгин В. Ф. Защита информации в компьютерных системах и сетях. // ДМК Пресс. 2017 г.
Егоров А.А., Чернышова А.В., Губенко Н.Е. Анализ средств защиты больших данных в распределенных системах // Первая международная научно-практическая конференция Программная инженерия: методы и технологии разработки информационно-вычислительных систем (ПИИВС- 2016). Донецк, 2016 г. – Сборник научных трудов. – ДонНТУ, Том 2, с. 28- 33.
Егоров А.А., Чернышова А.В. Исследование инструментов распределенной системы Hadoop // Конференция Современные информационные технологии в образовании и научных исследованиях (СИТОНИ-2017). Донецк, 2017 г.
Хабр. Big Data от А до Я. Часть 1: Принципы работы с большими данными, парадигма MapReduce // Электронный ресурс – https://habr.com/ru/company/dca/blog/267361/
Михаил Цымблер. Какие методы и технологии используются для обработки Больших Данных //Электронный ресурс - https://mzym.susu.ru/papers/Zymbler_Supercomputers-14b.pdf