Файл: Лекция 9. Системы распознавания образов (идентификации). Нейронные сети.doc
ВУЗ: Смоленский областной казачий институт промышленных технологий и бизнеса
Категория: Лекция
Дисциплина: Системы искусственного интеллекта
Добавлен: 29.10.2018
Просмотров: 2879
Скачиваний: 14
СОДЕРЖАНИЕ
Лекция 6. Системы распознавания образов (идентификации). Нейронные сети
Проблема обучения распознаванию образов (ОРО)
Геометрический и структурный подходы.
Обучение и самообучение. Адаптация и обучение
История исследований в области нейронных сетей
Модель нейронной сети с обратным распространением ошибки (back propagation)
Нейронные сети: обучение без учителя
Нейронные сети Хопфилда и Хэмминга
Метод группового учета аргументов МГУА
Общая схема построения алгоритмов метода группового учета аргументов (МГУА).
Алгоритм с ковариациями и с квадратичными описаниями.
Метод предельных упрощений (МПУ)
![]()
Расстояние центров тяжести равно расстоянию между центральными точками кластеров:
![]()
Обобщенное (по Колмогорову) расстояние между классами, или обобщенное K-расстояние, вычисляется по формуле
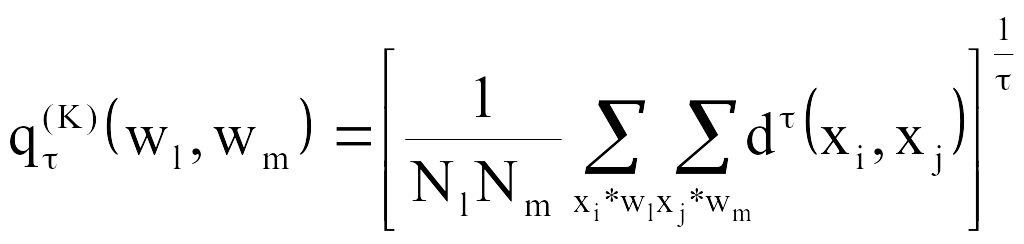
В частности, при и при - имеем
![]()
![]()
Выбор той или иной меры расстояния между кластерами влияет, главным образом, на вид выделяемых алгоритмами кластерного анализа геометрических группировок объектов в пространстве признаков. Так, алгоритмы, основанные на расстоянии ближайшего соседа, хорошо работают в случае группировок, имеющих сложную, в частности, цепочечную структуру. Расстояние дальнего соседа применяется, когда искомые группировки образуют в пространстве признаков шаровидные облака. И промежуточное место занимают алгоритмы, использующие расстояния центров тяжести и средней связи, которые лучше всего работают в случае группировок эллипсоидной формы.
Нацеленность алгоритмов кластерного анализа на определенную структуру группировок объектов в пространстве признаков может приводить к неоптимальным или даже неправильным результатам, если гипотеза о типе группировок неверна. В случае отличия реальных распределений от гипотетических указанные алгоритмы часто «навязывают» данным не присущую им структуру и дезориентируют исследователя. Поэтому экспериментатор, учитывающий данный факт, в условиях априорной неопределенности прибегает к применению батареи алгоритмов кластерного анализа и отдает предпочтение какому-либо выводу на основании комплексной оценки совокупности результатов работы этих алгоритмов.
Алгоритмы кластерного анализа отличаются большим разнообразием. Это могут быть, например, алгоритмы, реализующие полный перебор сочетаний объектов или осуществляющие случайные разбиения множества объектов. В то же время большинство таких алгоритмов состоит из двух этапов. На первом этапе задается начальное (возможно, искусственное или даже произвольное) разбиение множества объектов на классы и определяется некоторый математический критерий качества автоматической классификации. Затем, на втором этапе, объекты переносятся из класса в класс до тех пор, пока значение критерия не перестанет улучшаться.
Многообразие алгоритмов кластерного анализа обусловлено также множеством различных критериев, выражающих те или иные аспекты качества автоматического группирования. Простейший критерий качества непосредственно базируется на величине расстояния между кластерами. Однако такой критерий не учитывает «населенность» кластеров — относительную плотность распределения объектов внутри выделяемых группировок. Поэтому другие критерии основываются на вычислении средних расстояний между объектами внутри кластеров. Но наиболее часто применяются критерии в виде отношений показателей «населенности» кластеров к расстоянию между ними. Это, например, может быть отношение суммы межклассовых расстояний к сумме внутриклассовых (между объектами) расстояний или отношение общей дисперсии данных к сумме внутриклассовых дисперсий и дисперсии центров кластеров.
Функционалы качества и конкретные алгоритмы автоматической классификации достаточно полно и подробно рассмотрены в специальной литературе. Эти функционалы и алгоритмы характеризуются различной трудоемкостью и подчас требуют ресурсов высокопроизводительных компьютеров. Разнообразные процедуры кластерного анализа входят в состав практически всех современных пакетов прикладных программ для статистической обработки многомерных данных.
Иерархическое группирование
Рис. 12. Результаты работы иерархической агломеративной процедуры группирования объектов, представленные в виде дендрограммы.

Классификационные процедуры иерархического типа предназначены для получения наглядного представления о стратификационной структуре всей исследуемой совокупности объектов. Эти процедуры основаны на последовательном объединении кластеров (агломеративные процедуры) и на последовательном разбиении (дивизимные процедуры). Наибольшее распространение получили агломеративные процедуры. Рассмотрим последовательность операций в таких процедурах.
На первом шаге все объекты считаются отдельными кластерами. Затем на каждом последующем шаге два ближайших кластера объединяются в один. Каждое объединение уменьшает число кластеров на один так, что в конце концов все объекты объединяются в один кластер. Наиболее подходящее разбиение выбирает чаще всего сам исследователь, которому предоставляется дендрограмма, отображающая результаты группирования объектов на всех шагах алгоритма (Рис. 12). Могут одновременно также использоваться и математические критерии качества группирования.
Различные варианты определения расстояния между кластерами дают различные варианты иерархических агломеративных процедур. Учитывая специфику подобных процедур, для задания расстояния между классами оказывается достаточным указать порядок пересчета расстояний между классом wl и классом w(m, n) являющимся объединением двух других классов wm и wn по расстояниям qmn = q(wm, wn) и qln = q(wl, wn) между этими классами. В литературе предлагается следующая общая формула для вычисления расстояния между некоторым классом wl и классом w(m, n):
ql(m, n) = q (wl, w(m, n)) = qlm + qln + qmn + | qlm - qln |
где , , и — числовые коэффициенты, определяющие нацеленность агломеративной процедуры на решение той или иной экстремальной задачи. В частности, полагая = = - = ½ и = 0, приходим к расстоянию, измеряемому по принципу ближайшего соседа. Если положить = = = ½ и = 0, то расстояние между двумя классами определится как расстояние между двумя самыми далекими объектами этих классов, то есть это будет расстояние дальнего соседа. И, наконец, выбор коэффициентов соотношения по формулам
![]()
приводит к расстоянию qcp между классами, вычисленному как среднее расстояние между всеми парами объектов, один из которых берется из одного класса, а другой из другого.
Использование следующей модификации формулы
![]()
дает агломеративный алгоритм, приводящий к минимальному увеличению общей суммы квадратов расстояний между объектами внутри классов на каждом шаге объединения этих классов. В отличие от оптимизационных кластерных алгоритмов предоставляющих исследователю конечный результат группирования объектов, иерархические процедуры позволяют проследить процесс выделения группировок и иллюстрируют соподчиненность кластеров, образующихся на разных шагах какого-либо агломеративного или дивизимного алгоритма. Это стимулирует воображение исследователя и помогает ему привлекать для оценки структуры данных дополнительные формальные и неформальные представления.