Файл: Лабораторная работа на тему Выявление и подбор тренда для временного ряда.docx
ВУЗ: Смоленский областной казачий институт промышленных технологий и бизнеса
Категория: Задание
Дисциплина: Моделирование систем
Добавлен: 19.11.2018
Просмотров: 673
Скачиваний: 5
Лабораторная работа
Тема: Построение трендовых моделей на основе кривых роста. Оценка адекватности и точности трендовых моделей. Прогнозирование экономических процессов на основе трендовых моделей.
Цель: Изучить методы предварительного выбора вида кривой для трендовой модели:
-
метод конечных разностей (метод Тинтера);
-
метод характеристик прироста, а также методы проверки адекватности и точности трендовых моделей:
-
проверки случайности колебаний уровней остаточной последовательности,
-
критерий пиков,
-
проверки соответствия распределения случайной компоненты нормальному закону распределения,
-
проверки равенства математического ожидания случайной компоненты нулю.
Применить полученные знания для решения следующей задачи (данные к задаче необходимо взять из таблицы в соответствии с вариантом, совпадающим с номером компьютера, на котором студент работает в компьютерном классе).
Задание: имеются исходные данные об объёмах перевозок различных грузов морским транспортом за некоторый период. Проверить имеет ли место тренд в исходных данных (применить метод Фостера – Стьюарта или метод проверки разностей средних уровней), если тренд имеется, то применить необходимые эконометрические методы и выполнить предварительный выбор вида трендовой кривой (из списка: полиномиальные кривые, простая и модифицированная экспонента, кривая Гомперца, логистическая кривая). С помощью метода наименьших квадратов определить параметры тренда. Оценить адекватность и точность полученной трендовой модели. Построить график тренда и исходных эмпирических значений в одной координатной плоскости.
Если в исходном ряду нет тренда, имеются ярко выраженные аномальные уровни, то каждый аномальный уровень необходимо сгладить, т.е. заменить его средним арифметическим уровней, находящихся от него слева и справа. После этого выполнить повторную проверку наличия тренда в исходных данных, если тренд имеется, то найти его математическое выражение, если тренда по-прежнему нет, то выполнить его предварительное сглаживание или построить график и исключить те значения, которые нарушают трендовые тенденции в данных.
Вариант 1
|
t |
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
9 |
10 |
11 |
12 |
13 |
|
yt |
7,62 |
6,80 |
9,02 |
9,34 |
9,67 |
9,55 |
10,76 |
11,48 |
11,43 |
11,48 |
11,68 |
12,24 |
12,89 |
Вариант 2
|
t |
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
9 |
10 |
11 |
12 |
|
yt |
8,50 |
8,11 |
9,93 |
10,70 |
10,97 |
10,63 |
11,24 |
11,98 |
11,84 |
12,19 |
12,38 |
12,73 |
Вариант 3
|
t |
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
9 |
10 |
11 |
12 |
|
yt |
9,40 |
9,00 |
10,45 |
10,68 |
11,44 |
11,73 |
12,41 |
12,69 |
13,05 |
13,09 |
13,74 |
13,74 |
Вариант 4
|
t |
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
9 |
10 |
11 |
12 |
|
yt |
8,84 |
10,18 |
10,75 |
11,64 |
12,01 |
12,96 |
13,28 |
13,11 |
13,63 |
13,82 |
13,88 |
14,04 |
Вариант 5
|
t |
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
9 |
10 |
11 |
12 |
|
yt |
9,15 |
8,02 |
10,87 |
12,01 |
12,40 |
12,05 |
13,56 |
13,39 |
13,96 |
14,41 |
14,39 |
14,75 |
Вариант 6
|
t |
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
9 |
10 |
11 |
12 |
|
yt |
10,8 |
10,24 |
12,63 |
12,35 |
13,09 |
13,50 |
14,12 |
14,51 |
15,03 |
15,24 |
15,02 |
15,33 |
Вариант 7
|
t |
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
9 |
10 |
11 |
12 |
|
yt |
11,86 |
11,47 |
12,81 |
13,93 |
14,00 |
14,83 |
14,34 |
15,54 |
15,22 |
15,83 |
15,46 |
15,61 |
Вариант 8
|
t |
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
9 |
10 |
11 |
12 |
|
yt |
10,84 |
11,55 |
13,31 |
14,67 |
14,75 |
14,78 |
15,68 |
16,08 |
16,41 |
16,60 |
16,72 |
16,65 |
Вариант 9
|
t |
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
9 |
10 |
11 |
12 |
|
yt |
12,19 |
12,48 |
14,17 |
14,84 |
15,19 |
15,65 |
16,37 |
16,39 |
16,85 |
17,32 |
17,62 |
17,79 |
Вариант 10
|
t |
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
9 |
10 |
11 |
12 |
|
yt |
13,21 |
12,46 |
15,33 |
14,86 |
15,78 |
16,40 |
16,85 |
16,97 |
17,26 |
17,44 |
17,76 |
17,89 |
Вариант 11
|
t |
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
9 |
10 |
11 |
12 |
|
yt |
14,08 |
13,19 |
15,26 |
15,87 |
16,30 |
16,47 |
17,70 |
17,78 |
18,07 |
18,25 |
18,31 |
18,71 |
Вариант 12
|
t |
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
9 |
10 |
11 |
12 |
|
yt |
14,73 |
13,66 |
16,87 |
17,41 |
17,59 |
17,74 |
18,23 |
19,28 |
19,44 |
19,58 |
19,95 |
19,97 |
Вариант 13
|
t |
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
9 |
10 |
11 |
12 |
|
yt |
14,29 |
14,32 |
16,87 |
17,50 |
17,85 |
18,10 |
18,52 |
19,31 |
19,71 |
19,82 |
19,91 |
20,94 |
Краткие теоретические сведения.
Метод конечных разностей (метод Тинтера): данный метод может быть использован, если уровни ряда состоят из двух компонент (тренда и случайной компоненты) и тренд является гладким (непрерывно дифференцируемым). Этапы:
-
вычисляются приросты до k-го порядка включительно (k=4)
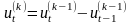
-
для исходного и разностного ряда k-го порядка вычисляются дисперсии. Для исходного ряда
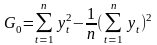 и для полученного ряда
и для полученного ряда
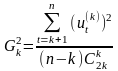
-
вычисляется величина равная разности дисперсии:
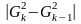
-
производится сравнение полученных величин. Если все разности примерно одного порядка, то степень аппроксимирующего полинома (k-1).
Метод характеристик
прироста: в этом методе предварительно
ряд сглаживается методом простой
скользящей средней. Интервал сглаживания
равен 3 (m=3). Вычисляется
среднее значение yt
(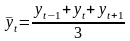 ).
Чтобы не потерять первый и последний
уровни первый уровень сглаживается по
следующей формуле
).
Чтобы не потерять первый и последний
уровни первый уровень сглаживается по
следующей формуле
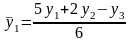 (1)
(1)
а последний сглаживается по формуле
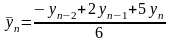 (2)
(2)Вычисляем
первые и вторые средние приросты по
формулам:
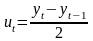
и
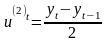 .
Вычисляется ряд производных величин:
.
Вычисляется ряд производных величин:
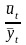 ;
;
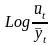 ;
;
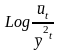 ;
;
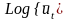 .
Затем по вычисленным показателям
определяют вид кривой.
.
Затем по вычисленным показателям
определяют вид кривой.
Оценка адекватности и точности трендовых моделей
Независимо от вида и способа построения экономико-математической модели вопрос о возможности ее применения в целях анализа и прогнозирования экономического явления может быть решен только после установления адекватности, т.е. соответствия модели исследуемому процессу или объекту. Так как полного соответствия модели реальному процессу или объекту быть не может, адекватность — в какой-то мере условное понятие. При моделировании имеется в виду адекватность не вообще, а по тем свойствам модели, которые считаются существенными для исследования.
Трендовая
модель
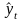 конкретного временного ряда
считается
адекватной, если правильно отражает
систематические
компоненты временного ряда. Это требование
эквивалентно
требованию, чтобы остаточная компонента
конкретного временного ряда
считается
адекватной, если правильно отражает
систематические
компоненты временного ряда. Это требование
эквивалентно
требованию, чтобы остаточная компонента
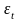 = yt
-
(t=
1,
2, ..., n)
удовлетворяла свойствам случайной
компоненты временного
ряда: случайность колебаний
уровней остаточной последовательности,
соответствие распределения случайной
компоненты нормальному закону
распределения, равенство математического
ожидания случайной
компоненты нулю, независимость значений
уровней случайной
компоненты. Рассмотрим, каким образом
осуществляется
проверка этих свойств остаточной
последовательности.
= yt
-
(t=
1,
2, ..., n)
удовлетворяла свойствам случайной
компоненты временного
ряда: случайность колебаний
уровней остаточной последовательности,
соответствие распределения случайной
компоненты нормальному закону
распределения, равенство математического
ожидания случайной
компоненты нулю, независимость значений
уровней случайной
компоненты. Рассмотрим, каким образом
осуществляется
проверка этих свойств остаточной
последовательности.
Проверка случайности колебаний уровней остаточной последовательности означает проверку гипотезы о правильности выбора вида тренда. Для исследования случайности отклонений от тренда мы располагаем набором разностей
![]()
Характер
этих отклонений изучается с помощью
ряда непараметрических критериев. Одним
из таких критериев является
критерий серий,
основанный на медиане
выборки. Ряд
из величин
располагают
в порядке возрастания их значений
и находят медиану
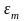 полученного вариационного ряда, т.е.
срединное значение при нечетном п
или
среднюю арифметическую
из двух срединных значений при п
четном.
Возвращаясь
к исходной последовательности
и
сравнивая
значения этой последовательности с
,
будем ставить знак
«плюс», если значение
превосходит
медиану, и знак «минус»,
если оно меньше медианы; в случае
равенства сравниваемых
величин соответствующее значение
опускается.
Таким образом, получается последовательность,
состоящая
из плюсов и минусов, общее число которых
не превосходит п.
Последовательность
подряд идущих плюсов или
минусов называется серией.
Для
того чтобы последовательность
была случайной выборкой, протяженность
самой длинной
серии не должна быть слишком большой,
а общее число
серий — слишком малым.
полученного вариационного ряда, т.е.
срединное значение при нечетном п
или
среднюю арифметическую
из двух срединных значений при п
четном.
Возвращаясь
к исходной последовательности
и
сравнивая
значения этой последовательности с
,
будем ставить знак
«плюс», если значение
превосходит
медиану, и знак «минус»,
если оно меньше медианы; в случае
равенства сравниваемых
величин соответствующее значение
опускается.
Таким образом, получается последовательность,
состоящая
из плюсов и минусов, общее число которых
не превосходит п.
Последовательность
подряд идущих плюсов или
минусов называется серией.
Для
того чтобы последовательность
была случайной выборкой, протяженность
самой длинной
серии не должна быть слишком большой,
а общее число
серий — слишком малым.
Обозначим
протяженность самой длинной серии через
Ктах,
а
общее число серий — через
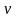 .
Выборка признается случайной,
если выполняются следующие неравенства
для 5%-ного
уровня значимости:
.
Выборка признается случайной,
если выполняются следующие неравенства
для 5%-ного
уровня значимости:
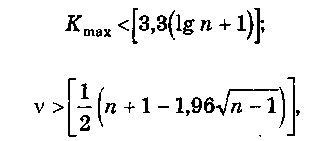
где квадратные скобки, как обычно, означают целую часть числа.
Если хотя бы одно из этих неравенств нарушается, то гипотеза о случайном характере отклонений уровней временного ряда от тренда отвергается и, следовательно, трендовая модель признается неадекватной.
Другим
критерием для данной проверки может
служить критерий пиков
(поворотных точек). Уровень
последовательности
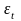 считается максимумом, если он больше
двух рядом
стоящих уровней, т.е.
считается максимумом, если он больше
двух рядом
стоящих уровней, т.е.
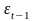 <
>
<
>
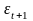 ,
и минимумом, если
он меньше обоих соседних уровней, т.е.
<
>
.
В обоих случаях
считается поворотной
точкой; общее число
поворотных точек для остаточной
последовательности
обозначим
через р.
,
и минимумом, если
он меньше обоих соседних уровней, т.е.
<
>
.
В обоих случаях
считается поворотной
точкой; общее число
поворотных точек для остаточной
последовательности
обозначим
через р.
В
случайной выборке математическое
ожидание числа точек
поворота
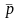 и
дисперсия
и
дисперсия
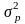 выражаются формулами:
выражаются формулами:
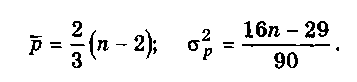
Критерием случайности с 5%-ным уровнем значимости, т.е. с доверительной вероятностью 95%, является выполнение неравенства
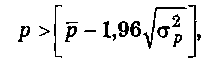
где квадратные скобки, как и ранее, означают целую часть числа. Если это неравенство не выполняется, трендовая модель считается неадекватной.
Проверка
соответствия распределения случайной
компоненты
нормальному закону распределения может
быть произведена
лишь приближенно с помощью исследования
показателей
асимметрии
(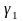 )
и
эксцесса
(
)
и
эксцесса
(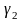 ),
так как временные ряды,
как правило, не очень велики. При
нормальном распределении показатели
асимметрии и эксцесса некоторой
генеральной
совокупности равны нулю. Мы предполагаем,
что отклонения
от тренда представляют собой выборку
из генеральной
совокупности, поэтому можно определить
только выборочные
характеристики асимметрии и эксцесса
и их ошибки:
),
так как временные ряды,
как правило, не очень велики. При
нормальном распределении показатели
асимметрии и эксцесса некоторой
генеральной
совокупности равны нулю. Мы предполагаем,
что отклонения
от тренда представляют собой выборку
из генеральной
совокупности, поэтому можно определить
только выборочные
характеристики асимметрии и эксцесса
и их ошибки:
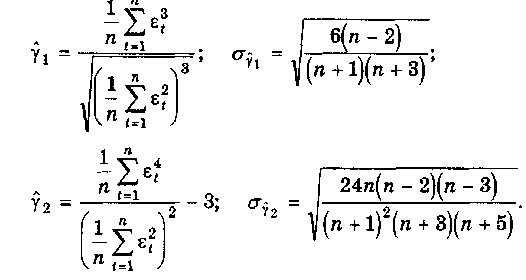
В
этих формулах
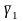 — выборочная характеристика асимметрии;
— выборочная характеристика асимметрии;
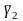 — выборочная характеристика эксцесса;
— выборочная характеристика эксцесса;
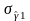 и
и
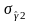 — соответствующие среднеквадратические
ошибки.
— соответствующие среднеквадратические
ошибки.
Если одновременно выполняются следующие неравенства:
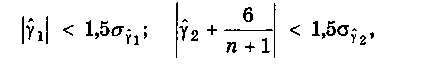
то гипотеза о нормальном характере распределения случайной компоненты принимается.
Если выполняется хотя бы одно из неравенств
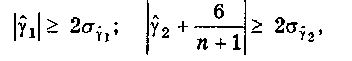
то гипотеза о нормальном характере распределения отвергается, трендовая модель признается неадекватной. Другие случаи требуют дополнительной проверки с помощью более сложных критериев.
Кроме рассмотренного метода известен ряд других методов проверки нормальности закона распределения случайной величины: метод Вестергарда, RS-критерий и т. д. Рассмотрим наиболее простой из них, основанный на RS-критерии. Этот критерий численно равен отношению размаха вариации случайной величины R к стандартному отклонению S.
В
нашем случае R
=
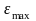 -
-
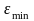 ,a
S
=
,a
S
=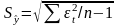 .
Вычисленное
значение RS-критерия
сравнивается с табличными (критическими)
нижней и верхней границами данного
отношения,
и если это значение не попадает в интервал
между критическими границами, то с
заданным уровнем значимости гипотеза
о нормальности распределения отвергается;
в противном
случае эта гипотеза принимается. Для
иллюстрации приведем
несколько пар значений критических
границ RS-критерия
для
уровня значимости
.
Вычисленное
значение RS-критерия
сравнивается с табличными (критическими)
нижней и верхней границами данного
отношения,
и если это значение не попадает в интервал
между критическими границами, то с
заданным уровнем значимости гипотеза
о нормальности распределения отвергается;
в противном
случае эта гипотеза принимается. Для
иллюстрации приведем
несколько пар значений критических
границ RS-критерия
для
уровня значимости
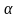 = 0,05: при п
= 10
нижняя
граница равна 2,67, а верхняя равна 3,685;
при п
= 20
эти числа составляют соответственно
3,18 и 4,49; при п
= 30
они равны
3,47 и 4,89.
= 0,05: при п
= 10
нижняя
граница равна 2,67, а верхняя равна 3,685;
при п
= 20
эти числа составляют соответственно
3,18 и 4,49; при п
= 30
они равны
3,47 и 4,89.
Проверка равенства математического ожидания случайной компоненты нулю, если она распределена по нормальному закону, осуществляется на основе t-критерия Стьюдента. Расчетное значение этого критерия задается формулой
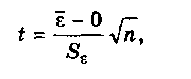
где
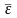 — среднее арифметическое значение
уровней остаточной
последовательности
— среднее арифметическое значение
уровней остаточной
последовательности
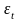 ;
;
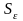 — стандартное
(среднеквадратическое) отклонение для
этой
последовательности.
— стандартное
(среднеквадратическое) отклонение для
этой
последовательности.
Если расчетное значение t меньше табличного значения ta статистики Стьюдента с заданным уровнем значимости а и числом степеней свободы п-1, то гипотеза о равенстве нулю математического ожидания случайной последовательности принимается; в противном случае эта гипотеза отвергается и модель считается неадекватной.
Проверка независимости значений уровней случайной компоненты, т.е. проверка отсутствия существенной автокорреляции в остаточной последовательности может осуществляться по ряду критериев, наиболее распространенным из которых является d-критерий Дарбина—Уотсона. Расчетное значение этого критерия определяется по формуле
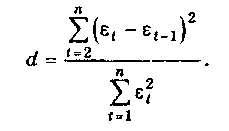
Заметим, что расчетное значение критерия Дарбина-Уотсона в интервале от 2 до 4 свидетельствует об отрицательной связи; в этом случае его надо преобразовать по формуле d' = 4 - d и в дальнейшем использовать значение d'.
Расчетное значение критерия d (или d') сравнивается с верхним d2 и нижним d1 критическими значениями статистики Дарбина—Уотсона, фрагмент табличных значений которых для различного числа уровней ряда п и числа определяемых параметров модели k представлен для наглядности в таблице (уровень значимости 5%).
|
n |
k=1 |
k=2 |
k=3 |
|||
|
d1 |
d2 |
d1 |
d2 |
d1 |
d2 |
|
|
15 |
1,08 |
1,36 |
0,95 |
1,54 |
0,82 |
1,75 |
|
20 |
1,20 |
1,41 |
1,10 |
1,54 |
1,00 |
1,68 |
|
30 |
1,35 |
1,49 |
1,28 |
1,57 |
1,21 |
1,65 |
Если расчетное значение критерия d больше верхнего табличного значения d2, то гипотеза о независимости уровней остаточной последовательности, т.е. об отсутствии в ней автокорреляции, принимается. Если значение d меньше нижнего табличного значения d1, то эта гипотеза отвергается и модель неадекватна. Если значение d находится между значениями d1 и d2, включая сами эти значения, то считается, что нет достаточных оснований сделать тот или иной вывод и необходимы дальнейшие исследования, например, по большему числу наблюдений.
Вывод об адекватности трендовой модели делается, если все указанные выше четыре проверки свойств остаточной последовательности дают положительный результат. Для адекватных моделей имеет смысл ставить задачу оценки их точности. Точность модели характеризуется величиной отклонения выхода модели от реального значения моделируемой переменной (экономического показателя). Для показателя, представленного временным рядом, точность определяется как разность между значением фактического уровня временного ряда и его оценкой, полученной расчетным путем с использованием модели, при этом в качестве статистических показателей точности применяются следующие: