Файл: Курсовая работа по дисциплине (учебному курсу) Теоретические основы информатики.docx
Добавлен: 26.10.2023
Просмотров: 165
Скачиваний: 12
ВНИМАНИЕ! Если данный файл нарушает Ваши авторские права, то обязательно сообщите нам.
МИНИСТЕРСТВО НАУКИ И ВЫСШЕГО ОБРАЗОВАНИЯ РОССИЙСКОЙ ФЕДЕРАЦИИ
федеральное государственное бюджетное образовательное учреждение высшего образования
«Тольяттинский государственный университет»
Институт математики, физики и информационных технологий
(наименование института полностью)
Кафедра «Прикладная математика и информатика»
(наименование кафедры полностью)
02.03.03 Математическое обеспечение и администрирование информационных систем
(код и наименование направления подготовки, специальности)
Мобильные и сетевые технологии
(направленность (профиль))
курсовая работа
по дисциплине (учебному курсу)
«Теоретические основы информатики»
(наименование дисциплины (учебного курса))
на тему «Разработка и реализация простейшего компилятора по варианту исходных данных № 2»
Группа МОб-2102а
Студент А.Н. Гнатюк
Руководитель
| Оценка: | |
| Дата: | |
| | |
| | (подпись руководителя) |
Тольятти 2022
МИНИСТЕРСТВО НАУКИ И ВЫСШЕГО ОБРАЗОВАНИЯ РОССИЙСКОЙ ФЕДЕРАЦИИ
федеральное государственное бюджетное образовательное учреждение высшего образования
«Тольяттинский государственный университет»
Институт математики, физики и информационных технологий
(наименование института полностью)
Кафедра «Прикладная математика и информатика»
(наименование кафедры полностью)
ЗАДАНИЕ
на выполнение курсовой работы
Студент Гнатюк Артём Николаевич
1. Тема «Разработка и реализация простейшего компилятора по варианту исходных данных № 2».
2. Срок сдачи студентом законченной курсовой работы декабрь 2022 г.
3. Исходные данные к курсовой работе: тип констант – тип констант – двоичные, оператор условия – у2, тип данных – Char.
4. Содержание курсовой работы (перечень подлежащих разработке вопросов, разделов): Исходные данные для выполнения курсовой работы, Разработка лексического анализатора, Разработка синтаксического разборщика, Разработка генератора результирующего кода.
5. Ориентировочный перечень графического и иллюстративного материала: блок-схемы, скриншоты экранных форм, таблицы, графы.
6. Рекомендуемые учебно-методические материалы: Баумгертнер С.В., Кузьмичев А.Б., Теоретические основы информатики. Выполнение курсовой работы. Учебно-методическое пособие для студентов направлений подготовки 01.03.02 Прикладная математика и информатика, 02.03.03 Математическое обеспечение и администрирование информационных систем. – Тольятти: ТГУ, 2018.
7. Дата выдачи задания «24» сентября 2022 г.
| Руководитель курсовой работы | (подпись) | (И.О. Фамилия) |
СОДЕРЖАНИЕ
СОДЕРЖАНИЕ 3
ВВЕДЕНИЕ 4
1.Исходные данные для выполнения курсовой работы 6
1.1Задание по курсовой работе 6
1.2Описание грамматики входного языка 7
2.РАЗРАБОТКА ЛЕКСИЧЕСКОГО АНАЛИЗАТОРА 8
2.1Описание выбранного способа организации таблицы идентификаторов с обоснованием сделанного выбора 8
2.2Разработка конечного автомата 9
2.3Разработка лексического анализатора 10
2.4Выбор метода взаимодействия лексического анализатора с синтаксическим разборщиком 11
3.РАЗРАБОТКА СИНТАКСИЧЕСКОГО АНАЛИЗАТОРА 12
3.1Разработка матрицы предшествования 12
3.2Разработка синтаксического разборщика 14
4.РАЗРАБОТКА ГЕНЕРАТОРА РЕЗУЛЬТИРУЮЩЕГО КОДА 15
4.1Выбор и описание форм внутреннего представления программы, используемых в компиляторе с обоснованием сделанного выбора 15
4.2Разработка алгоритма порождения результирующего кода 16
4.3Интеграция разработанных компонент в компилятор 16
4.4Описание разработанного компилятора 17
ЗАКЛЮЧЕНИЕ 18
БИБЛИОГРАФИЧЕСКИЙ СПИСОК 19
ВВЕДЕНИЕ
Цель данной курсовой работы – углубление теоретических и практических знаний при разработке и реализации простейших компиляторов, овладение основными принципами и методами построения и функционирования компиляторов, освоение навыков их реализации.
Задачи, решаемые в процессе выполнения курсовой работы:
-
разработка генератора таблицы идентификаторов; -
разработка лексического анализатора; -
разработка синтаксического анализатора; -
разработка генератора результирующего кода; -
изучение основных принципов и методов построения и функционирования компиляторов; -
применение теоретических знаний на практике; -
подготовка к будущей профессиональной деятельности; -
формирование культуры написания выпускной квалификационной работы.
Объектом исследования является системное программное обеспечение.
Предметом исследования курсовой работы является процесс разработки и реализации простейшего компилятора.
Выполнение курсовой работы заключается в создании простейшего компилятора на выбранном языке программирования по заданной грамматике. В результате выполнения курсовой работы должна быть представлена программная реализация компилятора, пояснительная записка, которая соответствует требованиям стандартов и заданию на курсовую работу.
В пояснительную записку будут включены следующие разделы:
-
Исходные данные для выполнения курсовой работы.
Данный раздел будет содержать описание всех исходных данных по данной курсовой работе, требования к входному языку компилятора, а также построенную в форме Бэкуса-Наура грамматику входного языка в соответствии с предоставленным вариантом задания.
-
Разработка лексического анализатора.
Во втором разделе пояснительной записки будет представлено описание выбранного способа организации таблицы идентификаторов с обоснованием сделанного выбора, граф переходов конечного автомата лексического анализатора с описанием выбранных состояний и обозначений, описание и разработка самого лексического анализатора, пример его работы и выбранный метод взаимодействия лексического анализатора с синтаксическим разборщиком.
-
Разработка синтаксического разборщика.
В данный раздел будут включены разработка матрицы предшествования и синтаксический разборщик, основанный на разработанной матрице простого предшествования с тестовыми примерами.
-
Разработка генератора результирующего кода.
Четвертый раздел будет содержать такие вопросы, как: выбор и описание форм внутреннего представления программы, описание разработанного алгоритма порождения результирующего кода, интеграция разработанных компонент в компилятор, а также описание уже разработанного компилятора.
В заключении будут сформулированы краткие выводы по каждому разделу, которые получены в процессе выполнения данной курсовой работы.
-
Исходные данные для выполнения курсовой работы
-
Задание по курсовой работе
Вариант: 2
Тип констант: 2 (двоичные)
Тип данных: Char
Оператор цикла: if <выражение> then <оператор> else <оператор>;
В процессе выполнения данной курсовой работы должен быть создан компилятор, запуск которого осуществляется с помощью командной строки с именем входного файла в качестве первого и единственного входного параметра.
Требования к входному языку компилятора:
-
Входная программа может быть разбита на строки произвольным образом, причем все пробелы и переводы строки должны игнорироваться компилятором. -
Текст входной программы может содержать комментарии любой длины, которые должны игнорироваться компилятором. -
Должны быть предусмотрены следующие варианты операторов входной программы:
– оператор присваивания вида <переменная> := <выражение>;
– составной оператор вида {…};
– оператор цикла, предусмотренный вариантом задания.
-
Выражения в операторах должны содержать:
– арифметические операции: сложение (+), вычитание (–), умножение (*), деление (/);
– операции сравнения: «меньше» (<), «больше» (>), «равно» (=);
-
Операндами в выражениях могут выступать идентификаторы (переменные) и константы. -
Все идентификаторы, встречающиеся в исходной программе, должны восприниматься как переменные, имеющие определенный тип. -
Для изменения приоритета операций должны использоваться круглые скобки.
В качестве выходного (результирующего) языка используются триады.
-
Описание грамматики входного языка
Входной язык может быть построен с помощью КС-грамматики. Описание грамматики, построенной в форме Бэкуса-Наура:
< ELSE_BLOCK> ::= {
< ELSE_BLOCK> ::=
В данном описании нетерминалы грамматики показаны в угловых скобках. Остальные символы являются терминалами грамматики.
-
РАЗРАБОТКА ЛЕКСИЧЕСКОГО АНАЛИЗАТОРА
-
Описание выбранного способа организации таблицы идентификаторов с обоснованием сделанного выбора
В качестве способа организации таблицы идентификаторов использовалась хеш-адресация. Хеш-адресация использует значения, возвращаемые некоторой хеш-функцией, как адреса ячеек из некоторого массива данных. Формула хеш-функции:
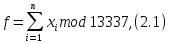
где
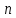 – количество символов в имени данного идентификатора,
– количество символов в имени данного идентификатора, 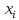 – ASCII-код одного символа имени идентификатора.
– ASCII-код одного символа имени идентификатора.Данная хеш-функция считает сумму ASCII-кода всех символов имени идентификатора и находит остаток от деления данной суммы на простой модуль.
Метод цепочек заключается в использовании промежуточной хеш-таблицы, в каждой ячейке которой хранится указатель на область памяти из основной таблицы идентификаторов. Это позволяет сделать саму таблицу идентификаторов динамической и расширять ее при обнаружении нового идентификатора. При использовании данного метода для каждого идентификатора добавляется еще одно поле, указатель на следующий элемент. Таким образом, при возникновении коллизии, алгоритм связывает идентификаторы друг с другом последовательно, образуя цепочки связанных элементов. Среднее время на размещение и поиск элемента в таблице зависит от среднего количества коллизий, а объем используемой памяти не так велик за счет динамически расширяемой таблицы и зависит от количества идентификаторов.
-
Разработка конечного автомата
Лексемы входного языка представлены в таблице 2.2.
Таблица 2.2 – Лексемы входного языка
| Код лексемы | Лексема | Тип |
| 1 | if | Ключевое слово |
| 2 | ( | Разделитель |
| 3 | ) | Разделитель |
| 4 | { | Разделитель |
| 5 | } | Разделитель |
| 6 | Последовательность, начинающаяся с «_» или буквы, продолжающаяся «_», буквой или цифрой | Идентификатор |
| 7 | = | Разделитель |
| 8 | ; | Разделитель |
| 9 | Последовательность «0» и «1», начинающаяся с «0b» | Константа |
| 10 | + - == || >= <= > < | Разделитель |
| 11 | * / && | Разделитель |
| 12 | else | Ключевое слово |
| 1000 | |- | Маркер конца цепочки |
Границами лексем служат пробел, знак табуляции, знак перевода строки и возврата каретки, другие служебные символы. Эти символы при лексическом анализе игнорируются.
Комментарием в программе считается последовательность символов любой длины, начинающаяся с «//» и продолжающаяся до конца строки.
В качестве способа описания конечного автомата была выбрана таблица переходов (таблица 2.3).
Начальное состояние автомата – 1, конечное состояние – 0. В конечное состояние автомат попадает, если распознана лексема. В случае отсутствия перехода из данного состояния по очередному символу цепочки, автомат возвращает ошибку.
Таблица 2.2 – Таблица переходов конечного автомата
| | if | else | ( | ) | { | } | b | _A-Z a-z | 0 | 1 | 2-9 | + - == || >= <= > < | * / && | Прочие символы |
| 1 | 0 | 0 | 0 | 0 | 0 | 0 | 2 | 2 | 3 | ERR | ERR | 0 | 0 | ERR |
| 2 | 0 | 0 | 0 | 0 | 0 | 0 | 2 | 2 | 2 | 2 | 2 | 0 | 0 | 0 |
| 3 | ERR | ERR | ERR | ERR | ERR | ERR | 4 | ERR | ERR | ERR | ERR | ERR | ERR | ERR |
| 4 | ERR | ERR | ERR | ERR | ERR | ERR | ERR | ERR | 5 | 5 | ERR | ERR | ERR | ERR |
| 5 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 5 | 5 | 0 | 0 | 0 | 0 |
Таким образом, конечный автомат представлен в виде таблицы переходов, с помощью которой можно распознать любую лексему из входной цепочки.
-
Разработка лексического анализатора
Лексический анализатор – часть компилятора, которая отвечает за выделение лексем в исходном тексте программы. Получая на вход исходный текст программы, анализатор разбивает его на отдельные слова (лексемы). В результате работы анализатора должен получиться список всех обнаруженных в исходном тексте программы лексем.
Лексический анализатор разрабатывался с помощью автоматного программирования.
На рисунке 2.1 изображен пример работы лексического анализатора. Исходный текст программы был разбит на лексемы. Для каждой лексемы указан ее код и строка, в которой данная лексема была обнаружена. Если на входе неправильная лексема, лексический анализатор сообщит об ошибке.
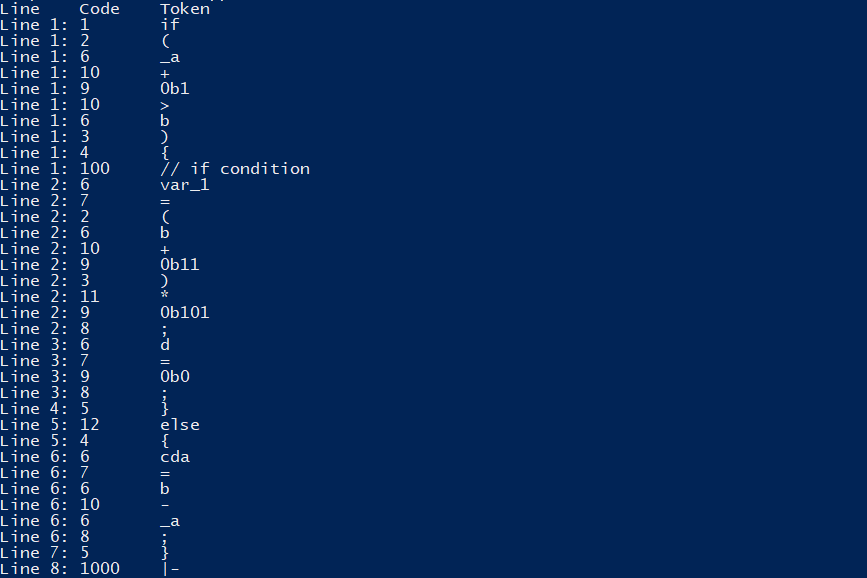
Рисунок 2.1 – Пример работы лексического анализатора
-
Выбор метода взаимодействия лексического анализатора
с синтаксическим разборщиком
При реализации программы использован смешанный подход. При этом код очередной распознанной лексемы передается блоку синтаксического анализатора для выбора очередной команды автомата.
Также результатом анализа является таблица идентификаторов. Пример представлен на рисунке 2.2.

Рисунок 2.2 – Пример таблицы идентификаторов
-
РАЗРАБОТКА СИНТАКСИЧЕСКОГО АНАЛИЗАТОРА
-
Разработка матрицы предшествования
Синтаксический анализатор – часть компилятора, которая выявляет и проверяет синтаксические конструкции входного языка. Разборщик находит и выделяет синтаксические конструкции в тексте исходной программы, проверяет правильность и устанавливает тип каждой такой конструкции, представляет эти конструкции в виде, удобном для дальнейшей генерации текста результирующей программы. Синтаксический анализатор – основная часть компилятора на этапе анализа. Перед разработкой синтаксического анализатора нужно построить матрицу операторного предшествования.
Исходная КС-грамматика в форме Бэкуса-Наура выглядит следующим образом:
< ELSE_BLOCK> ::= {
< ELSE_BLOCK> ::=
В таблице 3.1 показаны множества крайних левых и правых терминальных символов.
Таблица 3.1 – Множество крайних левых и правых терминальных символов. Результат
| Символ | Lt(U) | Rt(U) |
| CONDITION_BLOCK | ;,if,{,a | ;,},:=,-,+,*,/,) |
| THEN_BLOCK | if,{,a | },:=,-,+,*,/,) |
| OPERATOR_LIST | ;,b | :=,;,-,+,*,/,) |
| OPERATOR | b | :=,-,+,*,/,) |
| EXPRESSION | <,=,>,-,+,*,/,( | <,=,>,-,+,*,/,) |
| EXPR_EXT_R | -,+,*,/,( | -,+,*,/,) |
| EXPR_EXT_F | ( | ) |
Используя таблицу 3.2 с множеством крайних левых и правых терминальных символов и правила грамматики G можно заполнить матрицу операторного предшествования, которая нужна для разработки синтаксического разборщика.
Матрица операторного предшествования представлена в таблице 3.2.
Таблица 3.2 – Матрица операторного предшествования
| | ; | if | ( | ) | { | } | 0-9 | _A-Za-z | + - > < == | * / && |
| ; | =. | <. | <. | .> | <. | .> | <. | <. | <. | <. |
| if | | | <. | | | | | | | |
| ( | <. | | <. | =. | | | <. | <. | <. | <. |
| ) | .> | .> | | .> | <. | .> | <. | | .> | .> |
| { | <. | <. | | | <. | =. | <. | | | |
| } | .> | | | | | .> | | | | |
| 0-9 | .> | | | .> | | .> | | | .> | .> |
| _A-Za-z | .> | | | .> | | .> | | | .> | .> |
| + - > < == | .> | | <. | .> | | .> | <. | <. | .> | <. |
| * / && | .> | | <. | .> | | .> | <. | <. | .> | .> |
-
Разработка синтаксического разборщика
Главной задачей синтаксического разбора является построение дерева синтаксического разбора по таблице лексем. Для этого необходимо наличие таблицы лексем, указателя на первую лексему в списке и стек символов.
На рисунке 3.1 изображен алгоритм работы синтаксического анализатора в виде схемы.
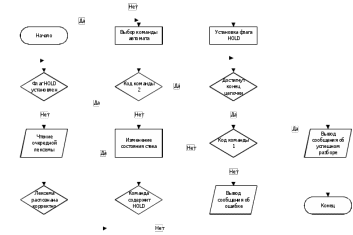
Рисунок 3.1 – Блок-схема алгоритма синтаксического разборщика
Таким образом, в пункте 3.2 данной курсовой работы был разработан синтаксический анализатор, который принимает на входе цепочку лексем, полученных лексическим анализатором, затем производит проверку на корректность введенных синтаксических конструкций. В результате также было получено дерево разбора для дальнейшей генерации результирующего кода.
-
РАЗРАБОТКА ГЕНЕРАТОРА РЕЗУЛЬТИРУЮЩЕГО КОДА
-
Выбор и описание форм внутреннего представления программы, используемых в компиляторе с обоснованием сделанного выбора
В качестве формы внутреннего представления программы были выбраны триады. Триады очень четко демонстрируют взаимосвязь операций, а также это очень простой и понятный способ формирования выходного кода. Каждая триада имеет следующую структуру:
<операция> (<операнд1>, <операнд2>).
Итоговым (результирующим) кодом является список триад, которые выполняются друг за другом.
Триады являются универсальной, машинно-независимой формой внутреннего представления в компиляторе результирующей объектной программы, апотому не требуют оговорки дополнительных условий при генерации кода.
Триады взаимосвязаны между собой, поэтому для установки корректной взаимосвязи процедура генерации кода должна получать также текущий номер очередной триады.
В алгоритме последовательные номера триад (а, следовательно, и ссылки на них) устанавливаются не сразу. Это не имеет значения при рекурсивной организации процедуры, но при другом способе обхода дерева вывода в программе генерации кода лучше увязывать триады между собойименно по ссылке (указателю), а не по порядковому номеру.
Для триад разработаны универсальные (машинно-независимые) алгоритмы оптимизации кода. После их выполнения (оптимизации внутреннего представления) триады могут быть преобразованы в команды на языке ассемблера.
-
Разработка алгоритма порождения результирующего кода
Для построения результирующего кода следует использовать метод, называемый синтаксически управляемым переводом. Его суть заключается в том, что каждому правилу входного языка сопоставляется правило выходного языка. СУ-перевод строит для каждой вершины дерева операций блок кода.
Итоговый код строится сверху вниз, сначала запускается функция построения блока кода для вершины дерева, которая начнет выполнение функции построения кода для потомков вершины, это будет продолжаться до тех пор, пока не будет исследовано всё дерево.
Ниже приведен пример списка полученных триад.
| =(mem_11650, _a) =(mem_651, 0b1) =(mem_2712, b) =(mem_2712, b) =(mem_3871, 0b11) +(mem_2712, mem_3871) =(mem_10515, 0b101) *(mem_2712, mem_10515) =(var_1, mem_2712) =(mem_324, 0b0) =(d, mem_324) +(mem_11650, mem_651) >(mem_11650, mem_2712) =(mem_2712, b) =(mem_11650, _a) =(cda, mem_2712) |
Используя дерево операции, СУ-перевод заменяет все узлы дерева на выходной (результирующий) код. Итогом являются сгенерированные и записанные в файл триады.
После генерации списка триад можно приступать к интеграции всех компонент в компилятор.
-
Интеграция разработанных компонент в компилятор
Для интеграции разработанных программ (создание таблицы идентификаторов, разработка лексического анализатора, синтаксического разборщика и синтаксически управляемого перевода) в единую программу-компилятор было выбрано создание проекта в среде программирования и объединение всех компонент через заголовочные файлы.
Алгоритм работы компилятора:
-
Лексический анализатор разбивает весь исходный текст на лексемы. Формируется таблица лексем. -
Все найденные идентификаторы заносятся в таблицу идентификаторов. -
Полученная таблица лексем разбивается синтаксическим анализатором на синтаксические конструкции по правилам грамматики. В результате получается дерево разбора. -
Полученное на прошлом шаге дерево разбора преобразуется в дерево операций. С помощью этого дерева генерируются триады (результирующий код), что и является результатом работы компилятора. Триады записываются в файл с именем «out_result.txt».
-
Описание разработанного компилятора
Для запуска компилятора следует открыть командную строку и перейти в каталог с исполняемым файлом компилятора (имя исполняемого файла – «Compiler.exe»), вызвать компилятор, передав название файла с исходным текстом или путь к нему. Если файл с исходным текстом не будет найден, компилятор сообщит об этом и завершит работу. Если ошибок не возникнет, компилятор сообщит об успешном завершении компиляции и завершит свою работу.
ЗАКЛЮЧЕНИЕ
В процессе выполнения данной курсовой работы были подробно изучены теоретические сведения по разработке простейших компиляторов, на основе этих знаний получены новые практические умения и навыки по их реализации, были изучены основные методы и принципы функционирования компиляторов. Таким образом, цель данной курсовой работы достигнута.
Все задачи, поставленные для достижения цели курсовой работы, были решены.
В первом разделе данной курсовой работы были описаны все исходные данные, требования к входному языку компилятора, была разработана грамматика входного языка в форме Бэкуса-Наура.
Во втором разделе данной работы был выбран метод организации таблицы идентификаторов итогового компилятора. Затем был разработан лексический анализатор, который разбивает весь исходный текст на лексемы.
Третий раздел включает описание разработанного синтаксического анализатора на основе ранее полученной матрицы операторного предшествования. Синтаксический анализатор является основной частью компилятора на стадии анализа и разбивает весь исходный текст на синтаксические конструкции. В результате было сформировано дерево разбора для дальнейшей генерации результирующего кода.
В четвертом разделе был разработан алгоритм порождения результирующего кода (триад) из дерева операций, которое было получено из дерева разбора, сформированного в третьем разделе работы.
В результате выполнения данной курсовой работы был разработан простейший компилятор по заданной грамматике на языке программирования C++, что позволило применить на практике все теоретические знания, полученные при изучении дисциплины.
БИБЛИОГРАФИЧЕСКИЙ СПИСОК
-
Баумгертнер, С. В., Кузьмичев, А. Б. Теоретические основы информатики. Выполнение курсовой работы [Текст] : учебно-методическое пособие для студентов направлений подготовки 01.03.02 Прикладная математика и информатика, 02.03.03 Математическое обеспечение и администрирование информационных систем. – Тольятти: ТГУ, 2018. -
Белов, В. В. Алгоритмы и структуры данных [Электронный ресурс] : учеб. для вузов по направлению подгот. 09.03.04 "Програм. инженерия" (квалификация – Бакалавр) / В. В. Белов, В. И. Чистякова. – Документ Bookread2. – М. : Курс [и др.], 2016. – 238 с. – Режим доступа: http://znanium.com/bookread2.php?book=766771. -
Гагарина, Л. Г. Технология разработки программного обеспечения [Электронный ресурс] : учеб. пособие для вузов по направлениям подгот. 09.04.01 и 09.03.03 "Информатика и вычисл. техника" / Л. Г. Гагарина, Е. В. Кокорева, Б. Д. Сидорова-Виснадулпод ред. Л. Г. Гагариной. – Документ Bookread2. – М. : Форум [и др.], 2018. – 400 с. : ил. – Режим доступа: http://znanium.com/bookread2.php?book=924760. -
Гордеев, А. В., Молчанов, А. Ю. Системное программное обеспечение [Текст] : учеб. для вузов / А. В. Гордеев, А. Ю. Молчанов. – М.: Питер, 2017. – 736 c. -
Молчанов, А. Ю. Системное программное обеспечение Лабораторный Практикум. [Электронный ресурс] : URL: https://docplayer.ru/30301704-Aleksey-yurevich-molchanov-sistemnoe-programmnoe-obespechenie-laboratornyy-praktikum.html. -
Синицын, С. В. Основы разработки программного обеспечения на примере языка С [Электронный ресурс] / С. В. Синицын, О. И. Хлытчиев – Электрон. текстовые данные. – Москва: Интернет-Университет Информационных Технологий (ИНТУИТ), 2016. – 211 c. – Режим доступа: http://www.iprbookshop.ru/73700.html.