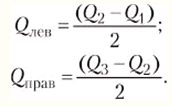Файл: Профильспециализация Качественные и количественные методы психологических и педагогических исследований.docx
ВУЗ: Не указан
Категория: Не указан
Дисциплина: Не указана
Добавлен: 26.10.2023
Просмотров: 12
Скачиваний: 1
ВНИМАНИЕ! Если данный файл нарушает Ваши авторские права, то обязательно сообщите нам.
НЕГОСУДАРСТВЕННОЕ ОБРАЗОВАТЕЛЬНОЕ ЧАСТНОЕ УЧРЕЖДЕНИЕ ВЫСШЕГО ОБРАЗОВАНИЯ
«МОСКОВСКИЙ ФИНАНСОВО-ПРОМЫШЛЕННЫЙ УНИВЕРСИТЕТ «СИНЕРГИЯ»
Факультет (Институт) _Педагогики___
(наименование факультета/ института)
Направление подготовки /специальность: 44.03.01 Педагогическое образование .
(код и наименование направления подготовки /специальности)
Профиль/специализация: Качественные и количественные методы психологических и педагогических исследований
(наименование профиля/специализации)Форма обучения: заочная .
(очная, очно-заочная, заочная)
Первичная статистическая обработка данных
Все методы количественной обработки принято подразделять на первичные и вторичные.
Первичная статистическая обработка нацелена на упорядочивание информации об объекте и предмете изучения. На этой стадии "сырые" сведения группируются по тем или иным критериям, заносятся в сводные таблицы. Первично обработанные данные, представленные в удобной форме, дают исследователю в первом приближении понятие о характере всей совокупности данных в целом: об их однородности - неоднородности, компактности - разбросанности, четкости - размытости и т. д. Эта информация хорошо считывается с наглядных форм представления данных и дает сведения об их распределении.
В ходе применения первичных методов статистической обработки получаются показатели, непосредственно связанные с производимыми в исследовании измерениями.
К основным методам первичной статистической обработки относятся: вычисление мер центральной тенденции и мер разброса (изменчивости) данных.
Первичный статистический анализ всей совокупности полученных в исследовании данных дает возможность охарактеризовать ее в предельно сжатом виде и ответить на два главных вопроса: 1) какое значение наиболее характерно для выборки; 2) велик ли разброс данных относительно этого характерного значения, т. е. какова "размытость" данных. Для решения первого вопроса вычисляются меры центральной тенденции, для решения второго - меры изменчивости (или разброса). Эти статистические показатели используются в отношении количественных данных, представленных в порядковой, интервальной или пропорциональной шкале.
Меры центральной тенденции - это величины, вокруг которых группируются остальные данные. Данные величины являются как бы обобщающими всю выборку показателями, что, во-первых, позволяет судить по ним обо всей выборке, а во-вторых, дает возможность сравнивать разные выборки, разные серии между собой. К мерам центральной тенденции в обработке результатов психологических исследований относятся: выборочное среднее, медиана, мода.
Выборочное среднее (М) - это результат деления суммы всех значений (X) на их количество (N).
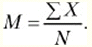
Медиана (Me) - это значение, выше и ниже которого количество отличающихся значений одинаково, т. е. это центральное значение в последовательном ряду данных. Медиана не обязательно должна совпадать с конкретным значением. Совпадение происходит в случае нечетного числа значений (ответов), несовпадение - при четном их числе. В последнем случае медиана вычисляется как среднее арифметическое двух центральных значений в упорядоченном ряду.
Мода (Мо) - это значение, наиболее часто встречающееся в выборке, т. е. значение с наибольшей частотой. Если все значения в группе встречаются одинаково часто, то считается, что моды нет. Если два соседних значения имеют одинаковую частоту и больше частоты любого другого значения, мода есть среднее этих двух значений. Если то же самое относится к двум несмежным значениям, то существует две моды, а группа оценок является бимодальной.
Обычно выборочное среднее применяется при стремлении к наибольшей точности в определении центральной тенденции. Медиана вычисляется в том случае, когда в серии есть "нетипичные" данные, резко влияющие на среднее. Мода используется в ситуациях, когда не нужна высокая точность, но важна быстрота определения меры центральной тенденции.
Вычисление всех трех показателей производится также для оценки распределения данных. При нормальном распределении значения выборочного среднего, медианы и моды одинаковы или очень близки.
Меры разброса (изменчивости) - это статистические показатели, характеризующие различия между отдельными значениями выборки. Они позволяют судить о степени однородности полученного множества, его компактности, а косвенно и о надежности полученных данных и вытекающих из них результатов. Наиболее используемые в психологических исследованиях показатели:
среднее отклонение, дисперсия, стандартное отклонение.
Размах (Р) - это интервал между максимальным и минимальным значениями признака. Определяется легко и быстро, но чувствителен к случайностям, особенно при малом числе данных.
Среднее отклонение (МД) - это среднеарифметическое разницы (по абсолютной величине) между каждым значением в выборке и ее средним.
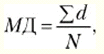
где d = |Х - М |, М - среднее выборки, X - конкретное значение, N - число значений.
Множество всех конкретных отклонений от среднего характеризует изменчивость данных, но если не взять их по абсолютной величине, то их сумма будет равна нулю и мы не получим информации об их изменчивости. Среднее отклонение показывает степень скученности данных вокруг выборочного среднего. Кстати, иногда при определении этой характеристики выборки вместо среднего (М) берут иные меры центральной тенденции - моду или медиану.
Дисперсия (D) характеризует отклонения от средней величины в данной выборке. Вычисление дисперсии позляет избежать нулевой суммы конкретных разниц (d = Х - М) не через их абсолютные величины, а через их возведение в квадрат:

где d = |Х - М|, М - среднее выборки, X - конкретное значение, N - число значений.
Стандартное отклонение (б). Из-за возведения в квадрат отдельных отклонений d при вычислении дисперсии полученная величина оказывается далекой от первоначальных отклонений и потому не дает о них наглядного представления. Чтобы этого избежать и получить характеристику, сопоставимую со средним отклонением, проделывают обратную математическую операцию - из дисперсии извлекают квадратный корень. Его положительное значение и принимается за меру изменчивости, именуемую среднеквадратическим, или стандартным, отклонением:

где d = |Х- М|, М - среднее выборки, X- конкретное значение, N - число значений.
МД, D и ? применимы для интервальных и пропорционных данных. Для порядковых данных в качестве меры изменчивости обычно берут полуквартильное отклонение (Q), именуемое еще полуквартильным коэффициентом. Вычисляется этот показатель следующим образом. Вся область распределения данных делится на четыре равные части. Если отсчитывать наблюдения начиная от минимальной величины на измерительной шкале, то первая четверть шкалы называется первым квартилем, а точка, отделяющая его от остальной части шкалы, обозначается символом Qv Вторые 25 % распределения - второй квартиль, а соответствующая точка на шкале - Q2. Между третьей и четвертой четвертями распределения расположена точка Q3. Полуквартильный коэффициент определяется как половина интервала между первым и третьим квартилями:

При симметричном распределении точка Q2 совпадет с медианой (а следовательно, и со средним), и тогда можно вычислить коэффициент Q для характеристики разброса данных относительно середины распределения. При несимметричном распределении этого недостаточно. Тогда дополнительно вычисляют коэффициенты для левого и правого участков: