ВУЗ: Не указан
Категория: Не указан
Дисциплина: Не указана
Добавлен: 29.10.2023
Просмотров: 312
Скачиваний: 6
ВНИМАНИЕ! Если данный файл нарушает Ваши авторские права, то обязательно сообщите нам.
Принципы транзакционности (ACID)….
В транзакции может быть неограниченное количество операций, и заканчиваться может быть Commit или Rollback. Причем Commit возможен только если все операции написаны без ошибок (причем все равно какая ошибка: синтаксис, рестарт сервера, сетевая ошибка и тд и в этому случае только Rollback).
3 принцип транзакции изолированы друг от друга и не влияют друг на друга пока они не выполнены
SAVEPOINT new_name; – точка транзакции в которой транзакции не завершается но она вносит данные в базу данных
ROLLBACK TO name – откат к сейфпоинту с именем
Уровни изоляции

1 режим не примениvв некоторых субд, например postgres sql
SET IZOLUTION … это такая же команда как begin rollback и тд и причем стоит сразу же после begin
2 режим все операции в транзакциях работают на основе данных одной базы данных
3 режим для каждой транзакции создаются копии базы данных
-
Управление блокировками
-
Работа планировщика запросов -
План исполнения
Пользователь (передает запрос) -> Query parser (разбор запросов синтактически, если все верно, то разбирает запрос семантически и строит дерево запроса) -> Query optimizer (формирует план исполнения запроса) -> Query Plan (документ, в котором перечислены этапы операций, которые нужно выполнить для получения результату, который нужен пользователю) -> Query executer (по шагам выполняет каждый пункт запроса) -> передача результата выполнения запроса пользователю.
Transaction manager следит за выполнением плана запроса в QE
План исполнения — это последовательность операций, которые нужно сделать внутри базы данных, чтобы получить результат для пользователя.
Один и тот же результат можно достигнуть, выполняя различные планы, и тогда QO генерирует несколько планов исполнения и потом выбирает из них тот план, который быстро выдаст результат.
QO определяет быстроту выполнения плана с помощью цены плана (cost (не в чем не измеряется)). Цена плана формируется из цены каждой операции. Самый быстрый план имеет наименьшую стоимость.
Show random_page_cost; покажет стоимость случайного чтения
---4
Show seq_page_cost; цена последовательного чтения
---1
EXPLAIN – показ наилучшего плана исполнения запроса
, при этом исполнение начинаться не будет.
Explain select * from …
План исполнения надо читать снизу вверх
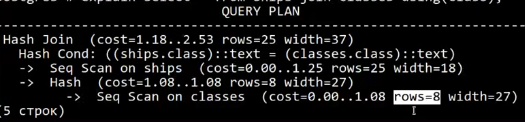
Cost = 1.18 (первая выдача) … 2.53 (полная выдача)
EXPLAIN ANYLZE - показ плана исполнения, обогащенный реальной статистикой, запрос выполняется и в план добавляется время исполнения всего запроса и времени планирования, а также затраченная память. Фактическое и реальное время (actual time) выполнение плана исполнения.
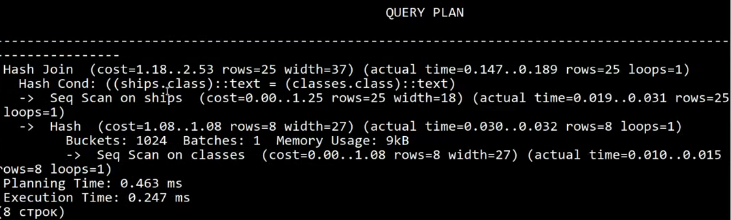
План исполнения позволит нам понять, что происходит при запросе, чтобы не тратить лишнее время на получение не верного результата.
Информацию о таблицах планировщик берет из системной таблицы pg_statisc. Хранит информацию: кол-во записей в таблице, длинна записей и тд.
Чтобы собрать статистику мы используем ANALYZE
Analyze; - по всей базе данных
Analyze name_tab;
Explain analyze (не собирает статистику) не имеет ничего общего с analyze
На основе статистики планировщики планирует свою работу. Статистика не сразу обновляется (может быть, она только вручную собирается), поэтому explain может показывать не точную информацию, а оптимизатор может выдавать не верные планы.
-
Составные запросы
INSERT INTO name_tab SELECT …; (вставка данных из запроса)
У DELETE и UPDATE можно использовать подзапрос в WHERE. Также это возможно и у INSERT INTO
Доп инфа вопрос 24
-
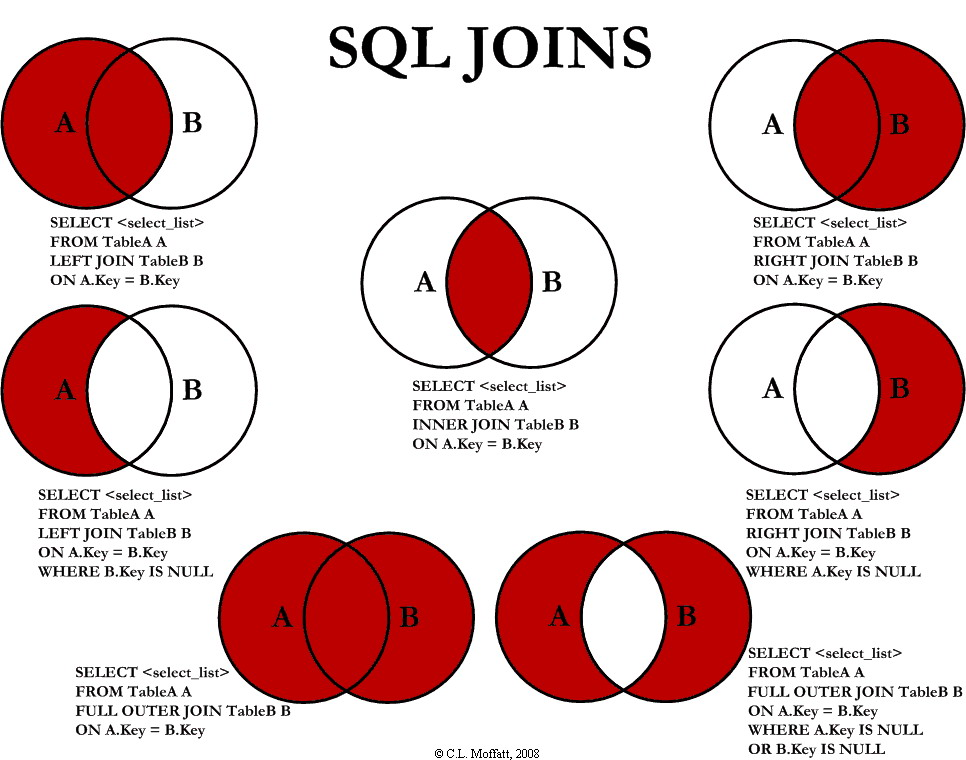
Виды join
[INNER] JOIN – таблицу образуют записи, которые удовлетворяют условию соединения
Альтернативная форма записи:
FROM name_tab1 JOIN name_tab2 ON … == FROM name_tab1, name_tab2 WHERE … (но второй случай очень затратный так как сначала происходит cross join а потом отбор данных, поэтому лучше всегда JOIN)
LEFT JOIN - таблицу образуют все записи из перовой таблицы, причем записи, которые не удовлетворяют условию соединения выставляют NULL в присоединённых столбцах
RIGHT JOIN – тоже самое что и LEFT JOIN, но только уже все записи из 2 таблицы
FULL JOIN – все записи с двух таблиц, но не связные записи будут иметь NULL в новых (присоединённых) столбцах
Альтернативна форма записи:
LEFT JOIN
UNION
RIGHT JOIN
CROSS JOIN - Перекрёстное соединение. Соединённую таблицу образуют все возможные сочетания строк из T1 и T2 (т. е. их декартово произведение). Если таблицы содержат N и M строк, соединённая таблица будет содержать N * M строк
Альтернативная форма записи:
FROM name_tab2 CROSS JOIN name_tab2 == FROM name_tab1, name_tab2
Исключающие соедините (не является командой) (exclusive join)
OUTER JOIN (исключающие соединение) (нельзя одной командой в psql) все записи с двух таблиц, но не берем записи которые есть в каждой таблице
(еще есть левосторонний и правосторонний исключающий join)
Соединение 3 и больше таблиц
FROM (name_tab1 JOIN name_tab2 ON… ) JOIN name_tab3 ON …
FROM name_tab1, name_tab2, name_tab3 where … and …
Эти операции соединения могут выполняться разными способами
NLJ (nested loop join (О(n^2))– самый тяжелый для выполнения (цикл в цикле), используется для CROSS JOIN или для запроса вида: … table1 JOIN table2 ON name_pol1 < name_pol2 (для этих запросов другие способы невозможны), также используется если хотя бы одна таблица очень маленькая (помещается в 1 page))
HJ (hash join (O(2n)) – самый быстрый, выбирается меньшая таблица по которой строиться хэш таблица)
MJ (merge join – работает если поля, по которым происходит соединение, имеют индекс)
-
Соответствие операций реляционной алгебры и операций SQL
Объединение (UNION)
Объединение отношений R1 и R2 выражается формулой
Объединением отношений R1 и R2 является отношение того же типа со строками, которые взяты из всех кортежей, присутствующих в R1 или в R2, или в обоих отношениях. При этом кортежи-дубликаты устраняются.
Отношения R1 и R2 должны принадлежать к одному типу. Они должны быть совместимыми по объединению (union compatible), т. е. иметь одинаковые заголовки и их количество.
Разность (EXCEPT)
Разность отношений R1 и R2 выражается формулой R = R1\ R2. Разностью R1\ R2 называется множество кортежей, принадлежащих R1, но не принадлежащих R2.
Пересечение (INTERSECT)
Пересечение отношений R1 и R2 возвращает отношение, содержащее все кортежи, которые принадлежат одновременно двум заданным отношениям, и выражается формулой
Произведение (CROSS JOIN, FROM A, B)
Декартово произведение – операция, заключающаяся в построении нового отношения на основе двух других путем попарной комбинации всех возможных записей из первого отношения и второго отношения.
Если отношение R1 имеет I записей и арность k1 , а R2 – J записей и арность k2 , то декартовым произведением отношений R1 и R2 является множество I*J кортежей арности (k1 + k2)
Проекция (SELECT)
Операция проекции заключается в том, что из отношения R1 выбираются указанные столбцы и компонуются в указанном порядке, т.е проекция — это операция, заключающаяся в удалении некоторых столбцов в отношении.
Смысл операции проекции заключается в выделении из отношения той информации, которая нам нужна. Эта операция используется в операторе SELECT языка SQL при выборке значений требуемых полей.
Выборка (WHERE)
Операция, которая определяет отношение, содержащие только те кортежи (строки) исходного отношения R, которые удовлетворяют заданному условию (предикату). Условие определяется как логическое выражение, включающее значения атрибутов.
Например, селекция отношения R1 по формуле F: R = F (R1), где F – формула, образованная:
– операндами, являющимися номерами столбцов;
– логическими операторами И , ИЛИ , НЕ ;
– арифметическими операторами сравнения <, =, >, <=, !=, >=
Соединение (JOIN)
Операция над двумя отношениями, имеющими общие атрибуты (по которым будет производится соединение), в результате которой получается новое отношение, состоящее из всех атрибутов исходных отношений и объединяющее только те кортежи исходных отношений, в которых значения общих атрибутов совпадают.
-
Запросы с подзапросами
Подзапрос в select должен давать одну запись, а не табличное выражение
Подзапрос в from – табличное выражение
Подзапрос в where если это IN или EXISTS то табличное выражение, иначе одну запись.
Кросс-коррелированные подзапросы — это подзапросы, которые связаны с основным запросом (то есть подзапрос должен быть связан со своей таблицы и с таблицей основного запроса в WHERE) (Таблицы могут быть одинаковыми, но тогда нужно обозначить разные имена таблицы через as)).
С помощью подзапроса можно реализовать что-то на подобия цикл в цикле. Например вычислить для группы записей, у которых одно и то же значение в каком нибудь поле, максимальное, средние значение и тд (что то наподобие оконных функций)
-
Запросы с группировкой
В 12 вопросе
-
Работа с индексами
CREATE [INIQUE] [ASC or DESC] INDEX [IF NOT EXISTS (проверка на существование такого индекса)] new_name ON name_table [USING метод] (name_pol1, name_pol2, …)
Методы: btree (методы по умолчанию), hash
– UNIQUE − требует создания уникального индекса; (система должна контролировать повторяющиеся значения в таблице при создании индекса (если в таблице уже есть данные) и при каждом добавлении данных. Попытки вставить или изменить данные, при которых будет нарушена уникальность индекса, будут завершаться ошибкой.)
– ASC − указывает на необходимость сортировки значений индексных полей по возрастанию (по умолчанию);
– DESC− указывает на необходимость сортировки значений индексных полей по убыванию;
DROP INDEX [IF EXISTS] name [CASCADE // RESTRICT]
ALTER INDEX [ IF EXISTS ] имя
RENAME TO новое_имя
SET TABLESPACE табл_пространство
Чтобы использовать индекс в базе данных, нужно произвести выборку по полу, у которого есть индекс, отсортировать по этому полю.
-
Представления в SQL
Представление (VEIW) — это логическая (виртуальная) таблица (относится к объектам базы данных), записи в которую отобраны с помощью оператора SELECT. Представлением называется запрос на выборку, которому присвоили имя, а затем сохранили в базе данных.
Представление можно использовать в режиме обычной таблицы, то есть оно может являться источником данных для запроса или другого представления, в этом случае представление является подзапросом.
Представление, основанное на двух и более таблиц, или использована группировка, выделение уникальных значений (DISTINCT), INTERSECT или UNUION, агрегирующие функции нельзя изменять (UPDATE, INSERT) (можно обойти тригером) (возможно только считывания), на одной таблице изменения разрешены.
Представление позволяет пользователю увидеть результаты сохраненного запроса, а SQL обеспечивает доступ к этим результатам таким образом, как если бы они были простой таблицей. Но представление не хранит в себе данные, каждый раз создается эта таблица создается заново.
Представления используются по нескольким причинам:
-
они позволяют сделать так, что разные пользователи базы данных будут видеть ее по-разному; -
с их помощью можно ограничить доступ к данным, разрешая пользователям видеть только некоторые из строк и столбцов таблицы; -
они упрощают доступ к базе данных, показывая каждому пользователю структуру хранимых данных в наиболее подходящем виде.