ВУЗ: Не указан
Категория: Не указан
Дисциплина: Не указана
Добавлен: 29.10.2023
Просмотров: 308
Скачиваний: 6
ВНИМАНИЕ! Если данный файл нарушает Ваши авторские права, то обязательно сообщите нам.
Также можно использовать вложенный запрос
Возможно задавать имена выходным столбцам name_pol AS new_name_pol
SELECT DISTINCT name_pol1, name_pol2, … – вывод только уникальных значений совокупности полей. (Эта операция медленнее выполняется чем вывод всей таблицы)
SELECT ALL name_pol1, name_pol2, … - вывод всех записей, даже повторяющихся (значение по умолчанию)
{2} можно использовать любое табличное выражение (таблицы, подзапрос (select, delete, insert, update с returning), представления)
Псевдонимы таблиц нужны для упрощения работы с ними, мы заменяем имя таблицы на другое имя более удобное нам
Пример: FROM name_tab n_t
Можно указывать несколько табличных выражений и производить над ними реляционную операцию соединения с помощью JOIN
Операция соединение — это операция реляционной алгебры и она выполняет соединение записей (кортежей) двух таблиц по одному полю или нескольких полей.
… name_tab1 JOIN name_tab2 ON name_pol1 = name_pol2
В случае если поля одинаковы (имеют одно и тоже название) по которым происходит объединение, то можно использовать так … name_table1 JOIN name_table2 using(name_pol)
SELECT * …. Выведет дублирующиеся столбцы, чтобы вывести все столбцы по одному разу, то придется их перечислить вручную.
{3} Фильтрует выведенные строки
Условие формируется из 3 частей
1 часть это поле (колонка) по которому будет производится отбор
2 часть логическая операция (продолжение в трехзначной логике)
3 часть это может быть поле различные константы и операции между ними, поле, подзапросы
… GROUP BY {4} HAVING {5}
{4} Группировка записей по определённому полю (полям). GROUP BY схлопывает повторяющиеся строки в одно множество
Если используем группировку, то в {1} могут быть только поля, которые участвуют в группировке или поля к которым применили агрегатную функцию (MIN(name_pol), MAX(…), AVG(…), SUM(…), COUNT(…), …)
Агрегатные функции avg и sum работают только с числами
Max и min работают с числами и строками
Count работают со всеми типами данными
Агрегатные функции работают и без GROUP BY, тогда они вычисляют свое значение для всех записей
{5} работает также как и WHERE, но только фильтрует выведенные группы строк, полученные после группировки
Используется только с GROUP BY
В самом конце может идти
Сортировка: ORDER BY name_pol [ASC // DESC// USING оператор] [NULLS FIRST // LAST]
По умолчанию по возрастанию ASC
USING оператор – свой порядок, оператор указывает что является большем, что является меньшем
NULLS FIRST // LAST – определение где будут находится записи с NULL
ORDER BY name_pol1 вид сортировки, name_pol2 вид сортировки, … (сначала по первому полю, потом уж 2 и так далее (не нарушая сортировки по предыдущим полям))
Ограничение выдачи количества записей: LIMIT n (целочисленное значение) (берутся первые n записей)
По умолчанию LIMIT ALL, то есть все записи
Вывод записей, начиная с определённого номера записи: OFFSET n (целочисленное значение) (берутся записи начиная с n записи)
Комбинация функционала LINIT и OFFSET: FETCH (начать с какой записи, количество записей)
Замечание 1. LIMIT, OFFSET, FETCH не входят в основу sql, являются дополнением СУБД. Не все СУБД поддерживают эти команды (могут выглядеть по-другому), так Oracle поддерживает только FETCH.
Замечание 2. Порядок записей постоянно меняется, так как в реляционной алгебре в множествах нет порядка объекта. Лучшего всего использовать чисто для быстрого просмотра части записей в таблице.
Замечание 3. Можно задать сортировку записей в таблице, и тогда порядок записей будет одинаковым (ORDER BY)
Чтобы объединить результаты двух select, которые выводят две одинаковых таблицы, в одну общую таблицу необходимо использовать объединение (UNION)
(SELECT …)
UNION
(SELECT …)
Чтобы вывести совпадающие результаты (пересечение строк) двух select, которые выводят две одинаковых таблицы, в одну общую таблицу необходимо использовать пересечение INTERSECT
Синтаксис такой же
Чтобы вывести все записи одного запроса, кроме записей которые не совпадают (не пересекаются) с записями из другого запроса используем разность EXCEPT
Синтаксис такой же
Эти операции убирают дублирующиеся строки из результата так же, как это делает DISTINCT, если только не указано UNION // INTERSECT // EXCEPT ALL.
-
Стандартные функции SQL особенности применения
Арифметические функции
Синтаксис Возвращаемое значение
ABS(x) абсолютное значение x
SQRT(x) квадратный корень от x
MAX(x, y, ...) значение наибольшего элемента из списка x, y, ...
MIN(x,y, ...) значение наименьшего элемента из списка x, y, ...
ROUND(X,n) Округляет число Х до числа с n знаками после десятичной точки
Функции обработки строк
Синтаксис Возвращаемое значение
LCASE(s) строка, полученная из s преобразованием всех букв в строчные
UCASE(s) строка, полученная из s преобразованием всех букв в прописные
CONCAT(s1, s2, ...) строка, полученная конкатенацией (слиянием) строк s1, s2, ...
LENGTH(s) длина строки s
Агрегатные функции
Синтаксис Возвращаемое значение
SUM(x) сумма значений столбца x результирующей таблицы
MAX(x) наибольшее значение из всех значений ячеек столбца x
MIN(x) наименьшее значение из всех значений ячеек столбца x
AVG(x) среднее значение для всех значений ячеек столбца x
COUNT(x) общее количество ячеек в столбце x
Расширенные функции
Синтаксис Возвращаемое значение
CAST Преобразует значение из одного типа данных в другой тип данных
IFNULL Позволяет вернуть альтернативное значение, если выражение равно NULL
ISNULL Проверяет, является ли выражение NULL
-
Пользовательские функции
UDF (user define function) это функция, определяемая пользователем. В СУБД можно создать объект, который называется хранимая процедура.
Хранимая процедура — это объект, который хранится в базе данных, имеет имя и который представляет собой программу, написанную на одном из встроенных языков программирования. Обращение происходит по имени.
Процедура не возвращает значение в отличие от функции.
Встроенные языки программирования — это чистый sql и plpgsql
Также можно установить другие языки программирования
Встроенный язык программирования sql выполняет последовательность команд написанных на sql
В sql нельзя создавать циклы, операторы ветвления, объявлять переменные
Все хранимые процедуры выполняются в самом СУБД, что позволяет уменьшить количеством взаимодействий с СУБД и посредников (библиотеки для работы с СУБД).
Без хранимых процедур данные сначала передаются из СУБД (перед этим произошла отрывка запроса в СУБД с помощью библиотек) в программу, там обрабатываются, а затем обратно возвращаются. Этот способ имеет преимущество так как возможно поменять СУБД, так как в этом случае оно содержит лишь данные, все вычисления в программе.
CREATE [OR REPLACE (создать или заменить)] FUNCTION new_name(name_arg тип данных, …) RETURNS тип данных
AS ‘ (вместо кавычек лучше использовать символы $$, если в теле присутствуют другие кавычки, или придется их экранировать )
Тело функции
’ LANGUAGE имя языка
=== После идут не обязательные параметры===
Тип функции (IMMUTABLE // STABLE // VOLATILE (значение по умолчанию))
CALLED ON NULL INPUT (значение по умолчанию)(функция будет выполнятся, но нужна доп проверка в самом теле функции для NULL)//STRICT(тоже самое что и следующее выражение)//
RETURNS NULL ON NULL INPUT; (вернуть null если есть хотя бы один null в аргументах)
IMMUTABLE гарантированно всегда возвращает одинаковые результаты для одних и тех же аргументов. Эта характеристика позволяет оптимизатору предварительно вычислить функцию, когда она вызывается в запросе с постоянными аргументами. (2+2 = 4)
STABLE гарантированно возвращает одинаковый результат, получая одинаковые аргументы, для всех строк в одном операторе. Эта характеристика позволяет оптимизатору заменить множество вызовов этой функции одним. (пример с now() всегда выдает одно и тоже время в рамке одной транзакции)
VOLATILE может возвращать различные результаты при нескольких вызовах с одинаковыми аргументами. Оптимизатор не делает никаких предположений о поведении таких функций. В запросе, использующем изменчивую функцию, она будет вычисляться заново для каждой строки, когда потребуется её результат. Пример timeofdate() здесь уже время меняется в транзакциях
Имя аргументов можно не указывать тогда обращение к передаваемым аргументам будет происходить через $1, $2, $3 и тд
Перегрузка функций допустима поэтому переменные обязательно указывать, чтобы обращаться к конкретной функции.
Функцию можно вызвать в любом sql запросе указав имя функции
Pl/pgsql это уже полноценный язык программирования который похож на паскаль.
Синтаксис pl/pgsql
Declare (опись переменных)
Begin
Код программы
Return
End;
-
Анонимные блоки
Do блоки - функция без имени. Похоже на CTE так как она одноразова. Является запросом sql. Не хранится в базе данных. С помощью него можно вставить данные или вывести сообщения на экран (raise notice …).
DO $$ код функции $$ language имя языка программирования.
-
CTE
CTE похожи на представления, так как они в себе содержат запрос и могут использоваться в других запросах в качестве источника данных. CTE используется только на время исполнения запроса, дальше она недоступна в отличие от представления.
Применение подзапросов в запросах очень громоздкая и не понятная вещь поэтому нужно использовать представления или CTE
WITH new_name AS (SELECT …) дальше продолжаем писать основной запрос SELECT * FROM new_name (которое в самом начале указывали)
-
Управление транзакциями
Транзакции — это группа операций на чтение/ записи, которые выполняются только если все операции из группы успешно выполнены.
B
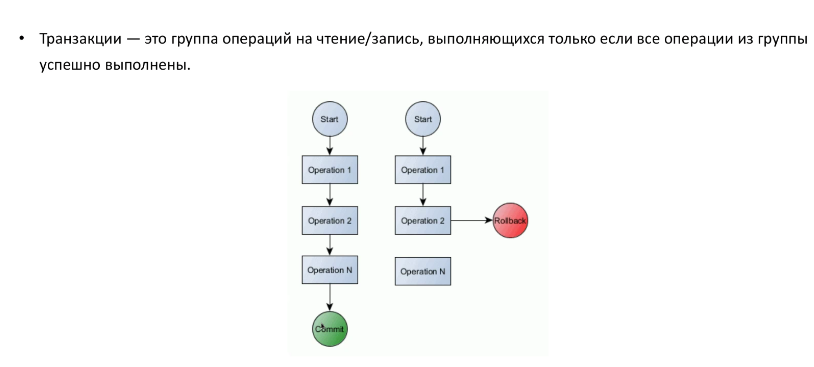 egin; (открытие, создание транзакции)
egin; (открытие, создание транзакции)Операция
…
Операция
Commit; (фиксирование результатов транзакции)
Rollback; это операция отмены изменений, полученных от транзакцией, при нарушения хода выполнения операций в транзакции. Эту команду можно использовать в коде для отмены результатов в текущей транзакции
При выполненные транзакции результаты операций записываются в специальную структуру данных (WRITE AHEAD LOG (журнал упреждающий записи)) как строки. Когда все операции выполнены успешно то все данные из WAL переносятся в базу данных. Если что-то случилось, то все данные ликвидируются из Wal и они не поступают в базу данных. В этом заключается принцип двойной записи. Это все замедляет работу базы данных, но это обеспечивает транзакционости.
Auto commit – это режим работы, то есть автоматическое отрытые Begin и закрытием Commit при написании операций. Если вручную открыть транзакцию, то это режим отключится и чтоб данные внеслись в таблицу на постоянной основе нужно вручную закрыть транзакцию и чтоб все операции выполнились успешно.
При ручном написании Begin отключается Auto commit, то есть нужно в ручною написать Commit или Rollback чтобы закрыть транзакцию.