ВУЗ: Не указан
Категория: Не указан
Дисциплина: Не указана
Добавлен: 22.11.2023
Просмотров: 81
Скачиваний: 1
ВНИМАНИЕ! Если данный файл нарушает Ваши авторские права, то обязательно сообщите нам.
Информация в многомерной модели представляется в виде многомерных массивов, называемых гиперкубами. В одной базе данных, построенной на многомерной модели, может храниться множество таких кубов, на основе которых можно проводить совместный анализ показателей. Конечный пользователь в качестве внешней модели данных получает для анализа определенные срезы или проекции кубов, представляемые в виде обычных двумерных таблиц или графиков.
Развитию многомерных моделей способствовало и то, что широко распространенные реляционные модели и соответствующим образом организованные базы данных хорошо подходили для оперативной, то есть транзакционной обработки данных. В случае же аналитической обработки, то есть поддержки принятия решений реляционные системы не давали желаемого результата. А многомерные базы данных хорошо обслуживают именно аналитическую обработку данных и обычно являются узко специализированными. Они обеспечивают более быстрый поиск и чтение данных по сравнению с реляционными моделями, а также избавляют от необходимости многократного связывания таблиц. Среднее время ответа у них на сложный вопрос в десятки раз меньше, чем при использовании реляционной модели.
Основными понятиями для многомерной модели являются: агрегируемость, историчность, прогнозируемость.
Агрегируемость данных означает рассмотрение и возможность анализа данных на разных уровнях обобщения: для пользователя, аналитика, руководителя. Историчность данных обозначает привязку их ко времени и высокий уровень неизменности (статичности) данных и их взаимосвязей. Временная привязка позволяет выполнять запросы, имеющие значения даты и времени. А статичность – использовать специализированные методы загрузки, хранения, выборки. Прогнозируемость данных предполагает задание функций прогнозирования и применение их к различным временным интервалам.
Многомерность модели данных – это, прежде всего, многомерное логическое представление структуры данных при их описании и в операциях манипулирования ими, а не многомерность их визуализации. По сравнению с реляционной моделью многомерная организация данных обладает более высокой информативностью. Для того чтобы убедиться в этом, рассмотрим многомерное представление данных и сопоставим его с реляционным (рис. 10-11).
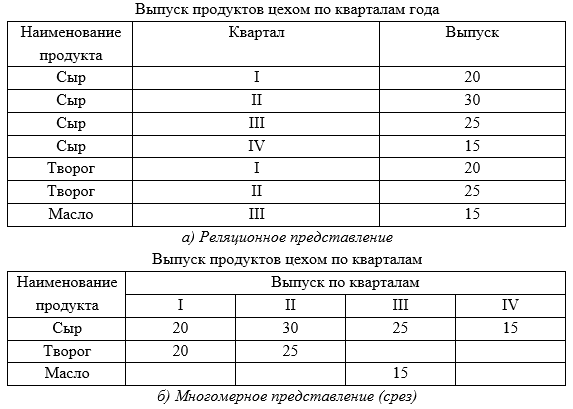
Рис. 10. Реляционное и многомерное представление данных
В
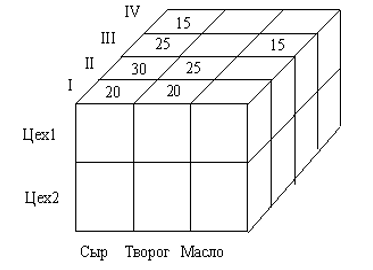
примере на рис. 11 каждое значение выпуска однозначно определяется комбинацией временного измерения (квартал), названием выпускающего цеха и наименованием товара.
Рис. 11. Пример трехмерной модели
В современных многомерных системах используется обычно два варианта (схемы) организации данных: гиперкубическая и поликубическая. В гиперкубической схеме все показатели определяются одним и тем же набором измерений и даже при наличии нескольких гиперкубов в базе все они имеют одинаковую размерность и совпадающие измерения. При поликубической организации в базе может быть определено несколько гиперкубов с различной размерностью и с различными измерениями в качестве граней. Примером поликубической системы является сервер Oracle Express Server.
Для многомерной модели применяются специальные операции: Срез, Сечение, Вращение, Агрегация, Детализация.
С

рез – это подмножество гиперкуба, полученное в результате фиксации одного или нескольких измерений. Так, в нашем примере можно ограничить значение наименования продукта продуктом Сыр. В этом случае получим срез в виде двумерной таблицы выпуска этого продукта по кварталам года цехами предприятия (рис. 12).
Рис. 12. Срез многомерной модели
Вращение изменяет порядок измерений при визуальном представлении данных.
Вращение применяется обычно при двумерном представлении данных. Так, в примере на рис. 10 вращение приведет к изменению вида таблицы, так, что по оси ОХ будет Наименование продукта, а по оси OY – Выпуск по кварталам (таблица 4).
Таблица 4
О
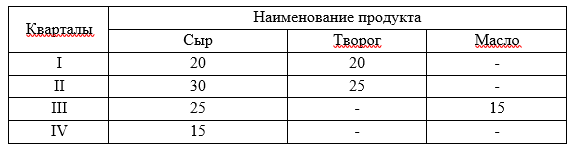
перацию вращения можно обобщить и на многомерный случай для изменения порядка следования измерений, например, перестановки местами двух произвольных измерений.
Агрегация и Детализация означают соответственно переход к более общему и более детальному представлению данных. Для понимания сути операции агрегации положим, что имеется гиперкуб, в котором кроме измерений, приведенных на рис. 10, имеются еще подразделение Участок. В этом случае в гиперкубе будет иерархия Цех – Участок. Допустим, в гиперекубе определено, сколько произведено продукции каждым из участков цеха 1. Тогда, поднимаясь на более высокую ступень иерархии, с помощью операции Агрегация можно определить выпуск и для всего цеха 1.
Достоинством многомерной модели является удобство и эффективность анализа больших объемов данных, имеющих временную связь, а также быстрота реализации сложных нерегламентированных запросов. Недостаток этой модели в громоздкости в случае ее использования для решения стандартных задач оперативной обработки. Она, по сравнению с реляционными, не эффективно использует память, так как в ней резервируется место для всех значений, даже если некоторые из них будут отсутствовать (рис. 14). Обычно многомерную модель применяется, когда объем базы не велик и гиперкуб использует стабильный по времени набор измерений.
Многомерные модели поддерживают следующие системы: Essbase (фирма Arbor Software), Media Multi-matrix (фирма Speedware), Oracle Express Server (фирма Oracle), Cache (фирма InterSystems). Некоторые системы поддерживают одновременно реляционную и многомерную модель, например, Media/MR (фирма Speedware).
3 вопрос: Цели создания и использования баз данных.
Если вы будете делать веб-приложение – например интернет-магазин, блог или игры, – почти наверняка вы столкнётесь с базой данных. Вот что это такое с точки зрения программирования, какие тут основные понятия и что с ними делать.
Данные
Вокруг нас всегда много разных данных, например:
• телефонные номера;
• дела на день;
• записи на бумажках, стикерах и в блокнотах;
• опубликованные мысли разных людей;
• фотографии в смартфоне;
• и всё остальное, что можно прочитать, увидеть или услышать.
Если это компьютерная игра, то данными будут типы и местоположения врагов, их уровень здоровья, уровень здоровья героя, тип героя, его положение, характеристики карты.
Если это приложение для работы с клиентом, то там будут храниться имя клиента, его заказы, номер телефона, уровень в программе лояльности.
Если это служба слежения за гражданами – фотография, имя, посещённые станции метро и улицы, место работы.
База данных и СУБД
Есть понятие базы данных — это набор данных, организованных каким-то способом. Например, если у вас в квартире есть гардеробная или кладовка, то всё это помещение со всем её содержимым может считаться базой (но не данных, а вещей или банок с огурцами, что не меняет сути).
Есть понятие системы управления базой данных (СУБД) — это когда семья села за стол и самого младшего отправляют в кладовку за огурцами, он приносит её и не разбивает по дороге. То есть СУБД — это какое-то средство для манипуляции данными в базе, например программа.
Для чего нужны
Вот основные задачи БД на примере гардеробной:
• Сохранить наши данные по запросу — чтобы вы могли открыть дверь, повесить куртку, закрыть дверь и больше не думать ни о куртке, ни о гардеробной.
• Изменить наши данные по запросу — чтобы можно было легко извлечь из гардеробной все дырявые носки и положить на их место целые.
• Найти эти данные по запросу — чтобы быстро найти приличный пиджак или парный носок.
• Не дать прочитать эти данные тем, кому не следует, а кому надо – дать. Например, младший брат может смотреть на ваши кроссовки, но не может их брать. А девушка (или парень) может положить свои вещи, но только на определённую полку.
• Поддерживать порядок и не дать захламиться – если вам было лень и вы просто кинули толстовку куда попало, чтобы гардеробная либо сама нашла, куда эту толстовку правильно положить, либо сказала: «Э БРАТ ЗАЧЕМ ЗАХЛАМЛЯЕШЬ ПОЛОЖИ НОРМАЛЬНО ДАВАЙ»
• Масштабироваться – чтобы вы могли просто вешать в гардеробную вещи и не думать об объёме полок.
• Не потерять данные – если квартира будет гореть, приличная гардеробная не должна даже нагреться. Или, если она всё-таки горит, чтобы где-то в защищённом подземном гараже была точная копия этой гардеробной со всеми актуальными вещами.
Базы данных и их системы управления заточены на работу с большим объёмом данных и от лица большого числа пользователей. Сейчас вы поймёте.
Представьте, что у вас есть экселька со списком клиентов. Это не база данных, это просто таблица. Чтобы прочитать или записать что-то в эту эксельку, вам нужно её открыть, сделать дело, сохранить.
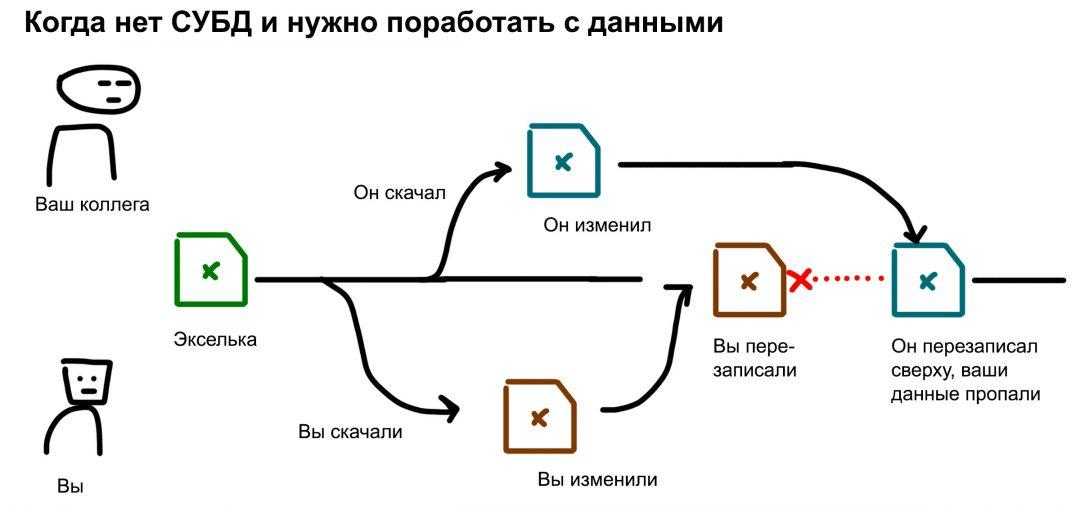
Допустим, экселька с клиентами лежит на сетевом диске. Вы открыли её и ковыряетесь в данных, вносите изменения. Пока вы это делаете, ваш коллега тоже её открыл и тоже вносит изменения. Потом вы сохранились и закрыли эксельку. Экселька перезаписалась вашими данными. Но у вашего коллеги эти данные не отобразились, он-то открыл её раньше. Теперь, когда он сохранит свою эксельку, его данные перезапишутся поверх ваших, а ваши данные пропадут. Это полный ахтунг: вся ваша работа потеряна.
И
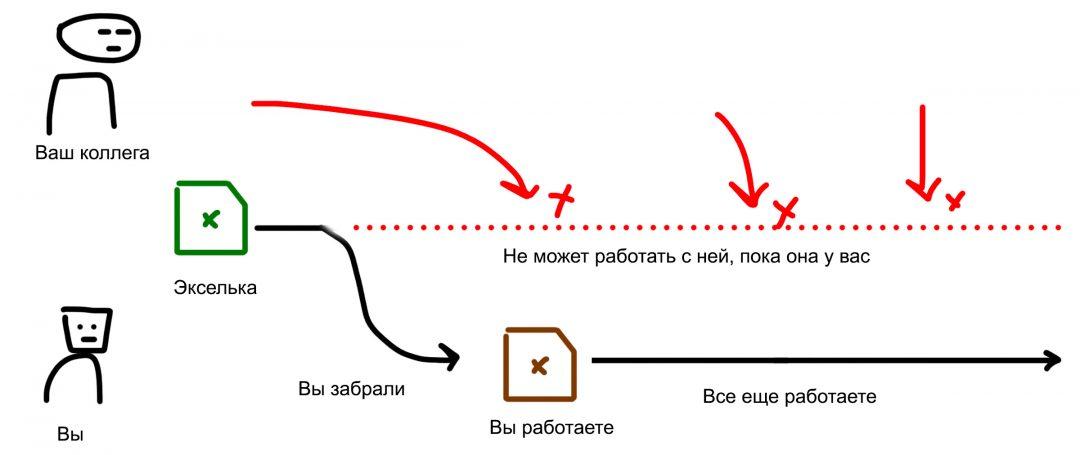
ли у вас в компании правило: экселька всегда на одной флешке, работаем только с неё. Сейчас флешка в вашем компьютере, вы с ней работаете. А вашему коллеге нужно с ней тоже поработать. Он говорит: «Дай». Вы ему «Отстань». Ну и слово за слово…
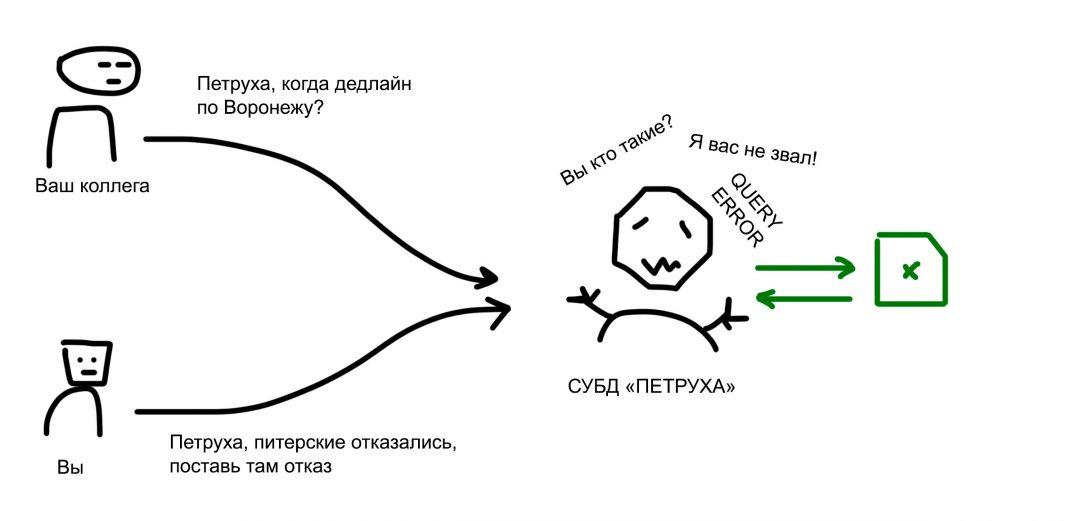
Но можно организовать своего рода СУБД. Один ответственный сотрудник назначается главным по эксельке. Она открыта на его компьютере, а вы ему говорите: «Петруха, добавь в клиента такого-то вот такие данные». «Петруха, а шо, когда дедлайн по поставке для этих ребят из Воронежа?», «Петруха, питерские отказались, поставь там отказ».
Петруха — ваша система управления базой данных. А экселька — это его база данных.
Понятно, что Петруха медленный и не всегда многозадачный, но хотя бы он избавляет от проблемы рассинхрона версий и потери данных.
Скорость — ещё одно преимущество базы данных. База данных устроена так, что она легко и быстро находит, записывает, переписывает и снова находит данные. Всё потому, что СУБД всегда знает, что где лежит и по какому критерию искать. Там не будет случайных данных в случайном месте.