ВУЗ: Не указан
Категория: Не указан
Дисциплина: Не указана
Добавлен: 23.11.2023
Просмотров: 21
Скачиваний: 1
ВНИМАНИЕ! Если данный файл нарушает Ваши авторские права, то обязательно сообщите нам.
Что такое параллелизм?
Если упростить до предела, то параллелизм – это одновременное выполнение двух или более операций. В жизни он встречается на каждом шагу: мы можем одновременно идти и разговаривать или одной рукой делать одно, а второй – другое.
Говоря о параллелизме в контексте компьютеров, мы имеем в виду, что одна и та же система выполняет несколько независимых операций параллельно, а не последовательно. Идея не нова: многозадачные операционные системы, позволяющие одновременно запускать на одном компьютере несколько приложений с помощью переключения между задачами уже много лет как стали привычными, а дорогие серверы с несколькими процессорами, обеспечивающие истинный параллелизм, появились еще раньше.
Компьютеры с несколькими процессорами применяются для организации серверов и выполнения высокопроизводительных вычислений уже много лет, а теперь машины с несколькими ядрами на одном кристалле (многоядерные процессоры) все чаще используются в качестве настольных компьютеров, которые могут исполнять более одной задачи в каждый момент времени. Это называется аппаратным параллелизмом.
На рис. 1.1 показан идеализированный случай: компьютер, исполняющий ровно две задачи, каждая из которых разбита на десять одинаковых этапов.
На двухъядерной машине каждая задача может исполняться в своем ядре.
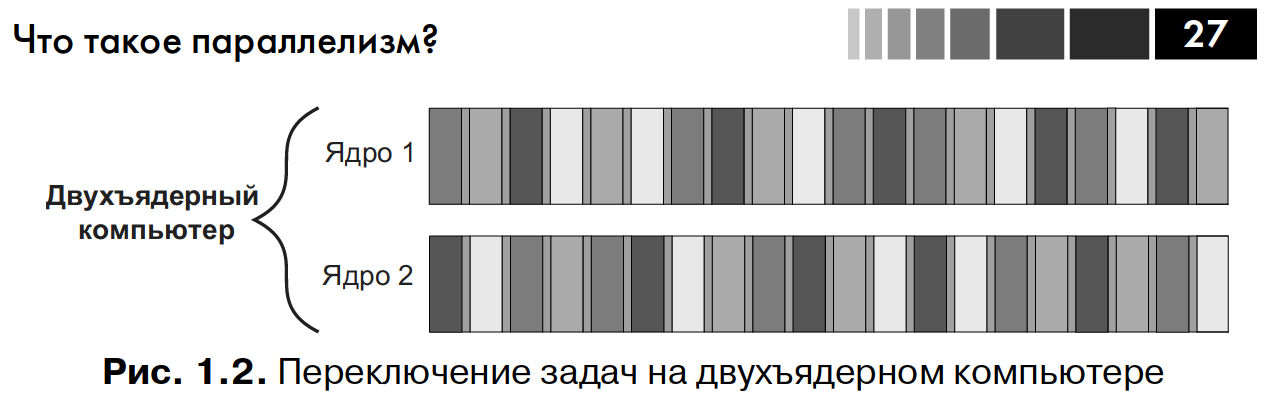
На одноядерной машине с переключением задач этапы той и другой задачи чередуются. Однако между ними существует крохотный промежуток времени - на рисунке эти промежутки изображены в виде серых полосок, разделяющих более широкие этапы выполнения. Что бы обеспечить чередование, система должна произвести контекстное переключение при каждом переходе от одной задачи к другой, а на это требуется время.
Чтобы переключить контекст, ОС должна сохранить состояние процессора и счетчик команд для текущей задачи, определить, какая задача будет выполняться следующей, и загрузить в процессор состояние новой задачи. Не исключено, что затем процессору потребуется загрузить команды и данные новой задачи в кэш-память; в течение этой операции никакие команды не выполняются, что вносит дополнительные задержки.

Хотя аппаратная реализация параллелизма наиболее наглядно проявляется в многопроцессорных и
многоядерных компьютерах, существуют процессоры, способные выполнять несколько потоков на одном ядре.
В действительности существенным фактором является количество аппаратных потоков – характеристика числа независимых задач, исполняемых оборудованием по-настоящему одновременно.
И наоборот, в системе с истинным параллелизмом количество задач может превышать число ядер, тогда будет применяться механизм переключения задач. Например, в типичном настольном компьютере может быть запущено несколько сотен задач, исполняемых в фоновом режиме даже тогда, когда компьютер по видимости ничего не делает. Именно за счет переключения эти задачи могут работать параллельно, что и позволяет одновременно открывать текстовый процессор, компилятор, редактор и веб-браузер (да и вообще любую комбинацию приложений).
На рис. 1.2 показано переключение четырех задач на двухъядерной машине, опять-таки в идеализированном случае, когда задачи разбиты на этапы одинаковой продолжительности.
Не имеет значения, как реализован параллелизм: с помощью переключения задач или аппаратно. Однако же понятно, что способ использования параллелизма в приложении вполне может зависеть от располагаемого оборудования.
1.1.2. Подходы к организации параллелизма
Существует два основных подхода к параллелизму. Пусть разработчик – это модель потока, а кабинет – модель процесса. В первом случае имеется несколько однопоточных процессов (у каждого разработчика свой кабинет), во втором – несколько потоков в одном процессе (два разработчика в одном кабинете). Разумеется, возможны произвольные комбинации: может быть несколько процессов, многопоточных и однопоточных, но принцип остается неизменным. А теперь поговорим немного о том, как эти два подхода к параллелизму применяются в приложениях.
Параллелизм за счет нескольких процессов
Первый способ распараллелить приложение – разбить его на несколько однопоточных одновременно исполняемых процессов.
И
 менно так вы и поступаете, запуская вместе браузер и текстовый процессор. Затем эти
менно так вы и поступаете, запуская вместе браузер и текстовый процессор. Затем эти
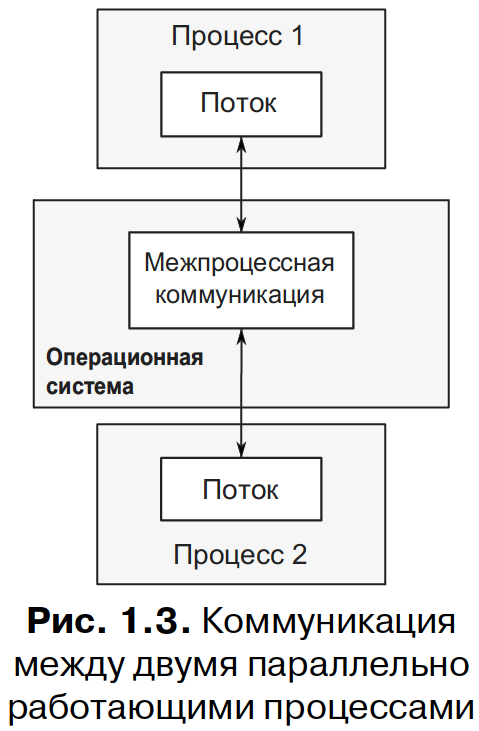
отдельные процессы могут обмениваться сообщениями, применяя стандартные каналы межпроцессной коммуникации (сигналы, сокеты, файлы, конвейеры и т. д.), как показано на рис. 1.3.
Недостаток такой организации связи между процессами в его сложности, медленности, а иногда том и другом вместе. Дело в том, что операционная система должна обеспечить защиту процессов, так, чтобы ни один не мог случайно изменить данные, принадлежащие другому. Есть и еще один недостаток – неустранимые накладные расходы на запуск нескольких процессов: для запуска процесса требуется время, ОС должна выделить внутренние ресурсы для управления процессом и т. д.
Конечно, есть и плюсы. Благодаря надежной защите процессов, обеспечиваемой операционной системой, и высокоуровневым механизмам коммуникации написать безопасный параллельный код проще, когда имеешь дело с процессами, а не с потоками.
У применения процессов для реализации параллелизма есть и еще одно достоинство – процессы можно запускать на разных машинах, объединенных сетью. Хотя затраты на коммуникацию при этом возрастают, но в хорошо спроектированной системе такой способ повышения степени параллелизма может оказаться очень эффективным, и общая производительность увеличится.
Параллелизм за счет нескольких потоков
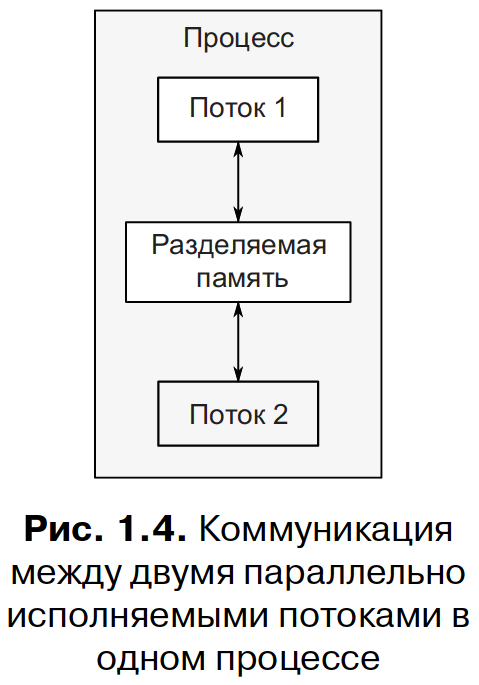
Альтернативный подход к организации параллелизма – запуск нескольких потоков в одном процессе. Потоки можно считать облегченными процессами – каждый поток работает независимо от всех остальных, и все потоки могут выполнять разные последовательности команд. Однако все принадлежащие процессу потоки разделяют общее адресное пространство и имеют прямой доступ к большей части данных – глобальные переменные остаются глобальными, указатели и ссылки на объекты можно передавать из одного потока в другой. Для процессов тоже можно организовать доступ к разделяемой памяти, но это и сделать сложнее, и управлять не так просто, потому что адреса одного и того же элемента данных в разных процессах могут оказаться разными. На рис. 1.4 показано, как два потока в одном процессе обмениваются данными через разделяемую память.
Б
 лагодаря общему адресному пространству и отсутствию защиты данных от доступа со стороны разных потоков накладные расходы, связанные с наличием нескольких потоков, существенно меньше, так как на долю операционной системы выпадает гораздо меньше учетной работы, чем в случае нескольких процессов.
лагодаря общему адресному пространству и отсутствию защиты данных от доступа со стороны разных потоков накладные расходы, связанные с наличием нескольких потоков, существенно меньше, так как на долю операционной системы выпадает гораздо меньше учетной работы, чем в случае нескольких процессов.
Однако же за гибкость разделяемой памяти приходится расплачиваться – если к некоторому элементу данных обращаются несколько потоков, то программист должен обеспечить согласованность представления этого элемента во всех потоках. Возникающие при этом проблемы, а также средства и рекомендации по их разрешению рассматриваются на протяжении всей книги, а особенно в главах 3, 4, 5 и 8. Эти проблемы не являются непреодолимыми, надо лишь соблюдать осторожность при написании кода. Но само их наличие означает, что коммуникацию между потоками необходимо тщательно продумывать.
Низкие накладные расходы на запуск потоков внутри процесса и коммуникацию между ними стали причиной популярности этого подхода во всех распространенных языках программирования, включая C++, даже несмотря на потенциальные проблемы, связанные с разделением памяти. Кроме того, в стандарте C++ не оговаривается встроенная поддержка межпроцессной коммуникации, а, значит, приложения, основанные на применении нескольких процессов, вынуждены полагаться на платформенно-зависимые API. Поэтому в этой книге мы будем заниматься исключительно параллелизмом на основе многопоточности, и в дальнейшем всякое упоминание о параллелизме предполагает использование нескольких потоков.
Определившись с тем, что понимать под параллелизмом, посмотрим, зачем он может понадобиться в приложениях.
1.2. Зачем нужен параллелизм?
Существует две основных причины для использования параллелизма в приложении: разделение обязанностей и производительность.
Разделение обязанностей почти всегда приветствуется при разработке программ: если сгруппировать взаимосвязанные и разделить несвязанные части кода, то программа станет проще для понимания и тестирования и, стало быть, будет содержать меньше ошибок.
Использовать распараллеливание для разделения функционально не связанных между собой частей программы имеет смысл даже, если относящиеся к разным частям операции должны выполняться одновременно: без явного распараллеливания нам пришлось бы либо реализовать какую-то инфраструктуру переключения задач, либо то и дело обращаться к коду из посторонней части программы во время выполнения операции.
Много процессорные системы существуют уже десятки лет, но до недавнего времени они использовались исключительно в суперкомпьютерах, больших ЭВМ и крупных серверах.
Однако ныне производители микропроцессоров предпочитают делать процессоры с 2, 4, 6 и более ядрами на одном кристалле, а не наращивать производительность одного ядра.
Увеличение вычислительной мощи в этом случае связано не с тем, что каждая отдельная задача работает быстрее, а с тем, что несколько задач исполняются параллельно.
Когда параллелизм вреден? Чем больше работает потоков, тем чаще операционная система должна выполнять контекстное переключение. На каждое такое переключение уходит время, которое можно было бы потратить на полезную работу, поэтому в какой-то момент добавление нового потока не увеличивает, а снижает общую производительность приложения.
Поэтому, пытаясь достичь максимально возможной производительности системы, вы должны выбирать число потоков с учетом располагаемого аппаратного параллелизма (или его отсутствия).
1.3. Параллелизм и многопоточность в C++
Стандартизованная поддержка параллелизма за счет многопоточности – вещь новая для C++. Чтобы разобраться в подоплёке многочисленных решений, принятых в новой стандартной библиотеке C++ Thread Library, необходимо вспомнить историю.
Начнем с классического примера – программы, которая печатает фразу «Здравствуй, мир». Ниже приведена тривиальная однопоточная программа такого сорта, от нее мы будем отталкиваться при переходе к нескольким потокам.
#include
int main() {
std::cout<<”Здравствуй, мир\n”;
}
Эта программа всего лишь выводит строку «Здравствуй мир» в стандартный поток вывода. Сравним ее с простой программой «Здравствуй, параллельный мир», показанной в листинге 1.1, – в ней для вывода сообщения запускается отдельный поток.
Листинг 1.1. Простая программа «Здравствуй, параллельный мир»
#include
#include
void hello() // 2
{
std::cout<<”Здравствуй, параллельный мир\n”; }
int main()
{
std::thread t (hello); //3
t.join(); //4
}
Прежде всего, отметим наличие дополнительной директивы #include
Далее, код вывода сообщения перемещен в отдельную функцию (2).
Это объясняется тем, что в каждом потоке должна быть начальная функция, в которой начинается исполнение потока. Для первого потока в приложении таковой является main(), а для всех остальных задается в конструкторе объекта std::thread. В данном случае в качестве начальной функции объекта типа std::thread, названного t (3), выступает функция hello().
Есть и еще одно отличие – вместо того чтобы сразу писать на стандартный вывод или вызывать hello() из main(), эта программа запускает новый поток, так что теперь общее число потоков равно двум: главный, с начальной функцией main(), и дополнительный, начинающий работу в функции hello().
После запуска нового потока (3) начальный поток продолжает работать. Если бы он не ждал завершения нового потока, то просто дошел бы до конца main(), после чего исполнение программы закончилось бы – быть может, еще до того, как у нового потока появился шанс начать работу. Чтобы предотвратить такое развитие событие, мы добавили обращение к функции join() (3); в главе 2 объясняется, что это заставляет вызывающий поток (main()) ждать завершения потока, ассоциированного с объектом std::thread, – в данном случае t.
Если вам показалось, что для элементарного вывода сообщения на стандартный вывод работы слишком много, то так оно и есть, – в разделе 1.2.3 выше мы говорили, что обычно для решения такой простой задачи не имеет смысла создавать несколько потоков, особенно если главному потоку в это время нечего делать. Но далее мы встретимся с примерами, когда запуск нескольких потоков дает очевидный выигрыш.
2.1.1. Запуск потока
В главе 1 мы видели, что для запуска потока следует сконструировать объект std::thread , который определяет, какая задача будет исполняться в потоке. В простейшем случае задача представляет собой обычную функцию без параметров, возвращающую void.
Эта функция работает в своем потоке, пока не вернет управление, и в этом момент поток завершается. С другой стороны, в роли задачи может выступать объект-функция, который принимает дополнительные параметры и выполняет ряд независимых операций, информацию о которых получает во время работы от той или иной системы передачи сообщений. И останавливается такой поток, когда получит соответствующий сигнал, опять же с помощью системы передачи сообщений. Вне зависимости от того, что поток будет делать и откуда он запускается, сам запуск потока в стандартном C++ всегда сводится к конструированию объекта std::thread:
void do_some_work();
std::thread my_thread(do_some_work);
Как видите, все просто. Разумеется, как и во многих других случаях в стандартной библиотеке C++, класс std::thread работает с любым типом, допускающим вызов (Callable), поэтому конструктору std::thread можно передать экземпляр класса, в котором определен оператор вызова:
class background_task {
public: void operator()() const {
do_something();
do_something_else();
}
};
background_task f;
std::thread my_thread(f);
В данном случае переданный объект-функция копируется в память, принадлежащую только что созданному потоку выполнения, и оттуда вызывается. Поэтому необходимо, чтобы с точки зрения поведения копия была эквивалентна оригиналу, иначе можно получить неожиданный результат.
При передаче объекта-функции конструктору потока нужно избегать феномена «самого досадного разбора в C++». Синтаксически передача конструктору временного объекта вместо именованной переменной выглядит так же, как объявление функции, и именно так компилятор и интерпретирует эту конструк-цию. Например, в предложении
std::thread my_thread(background_task());
объявлена функция my_thread, принимающая единственный параметр (типа указателя на функцию без параметров, которая возвращает объект background_task) и возвращающая объект std::thread.
Никакой новый поток здесь не запускается. Решить эту проблему можно тремя способами:
-
поименовать объект-функцию, как в примере выше; -
добавить лишнюю пару скобок или воспользоваться новым универсальным синтаксисом инициализации, например:
std::thread my_thread((background_task())); // (1)
std::thread my_thread{background_task()};// (2)
В случае (1) наличие дополнительных скобок не дает компилятору интерпретировать конструкцию как объявление функции, так что действительно объявляется переменная my_thread типа std:: thread. В случае (2) использован новый универсальный синтаксис инициализации с фигурными, а не круглыми скобками, он тоже приводит к объявлению переменной.
В стандарте C++11 имеется новый тип допускающего вызов объекта, в котором описанная проблема не возникает, – лямбда-выражение.
Этот механизм позволяет написать локальную функцию, которая может захватывать некоторые локальные переменные, из-за чего передавать дополнительные аргументы просто не нужно (см. раздел 2.2).
Подробная информация о лямбда-выражениях приведена в разделе A.5 приложения A. C помощью лямбда-выражений предыдущий пример можно записать в таком виде:
std::thread my_thread([]{ do_something();
do_something_else();
});