Файл: Архитектура вычислительных систем Способы ускорения традиционных архитектур вс.rtf
ВУЗ: Не указан
Категория: Не указан
Дисциплина: Не указана
Добавлен: 29.11.2023
Просмотров: 68
Скачиваний: 1
ВНИМАНИЕ! Если данный файл нарушает Ваши авторские права, то обязательно сообщите нам.
такт синхронизации не может быть меньше, чем время, необходимое для работы наиболее медленной ступени конвейера. Накладные расходы на организацию конвейера возникают из-за задержки сигналов в конвейерных регистрах (защелках) и из-за перекосов сигналов синхронизации. Конвейерные регистры к длительности такта добавляют время установки и задержку распространения сигналов. В предельном случае длительность такта можно уменьшить до суммы накладных расходов и перекоса сигналов синхронизации, однако при этом в такте не останется времени для выполнения полезной работы по преобразованию информации. При реализации конвейерной обработки возникают ситуации, которые препятствуют выполнению очередной команды из потока команд в предназначенном для нее такте. Такие ситуации называются конфликтами.
Конфликты снижают реальную производительность конвейера Существуют три класса конфликтов:
1. Структурные конфликты, которые возникают из-за конфликтов по ресурсам, когда аппаратные средства не могут поддерживать все возможные комбинации команд в режиме одновременного выполнения с совмещением.
2. Конфликты по данным, возникающие в случае, когда выполнение одной команды зависит от результата выполнения предыдущей команды.
3. Конфликты по управлению, которые возникают при конвейеризации команд переходов и других команд, которые изменяют значение счетчика команд.
Конфликты в конвейере приводят к необходимости приостановки выполнения команд (pipeline stall). Обычно в простейших конвейерах, если приостанавливается какая-либо команда, то все следующие за ней команды также приостанавливаются. Команды, предшествующие приостановленной, могут продолжать выполняться, но во время приостановки не выбирается ни одна новая команда.
Расслоение памяти.
Другой способ повышения пропускной способности оперативной памяти связан с построением памяти, состоящей на физическом уровне из нескольких модулей (банков) с автономными схемами адресации, записи и чтения. При этом на логическом уровне управления памятью организуются последовательные обращения к различным физическим модулям. Обращения к различным модулям могут перекрываться, и т.о. образуется своеобразный конвейер. Эта процедура носит название расслоения памяти. Целью данного метода является увеличение скорости доступа к памяти посредством совмещения фаз обращений ко многим модулям памяти. Существуют несколько вариантов организации расслоения. Наиболее часто используемый способ – расслоение обращений за счет расслоения адресов. Этот способ основывается на свойстве локальности программ и данных, предполагающем, что адрес следующей команды на 1 больше адреса предыдущей (иными словами, линейность программы нарушается только командами перехода). Аналогичная последовательность адресов генерируется процессором при чтении слов данных.
Т.о., типичный случай распределения адресов – последовательность вида а, а+1, а+2, а+3 и т.д. (для слов данных – увеличение на 1 – условно, на самом деле 1 – число байт в машинном слове). Из этого следует, что расслоение обращений возможно, если ячейки с адресами а, а+1, а+2, а+3 и т.д будут размещаться в блоках 0,1,2… Такое распределение ячеек по модулям (банкам) обеспечивается за счет использования адресов вида (см. рис. 2).
Здесь В – k–разрядный адрес модуля (младшая часть m–разрядного адреса), С – n–разрядный адрес ячейки в модуле В (старшая часть адреса).
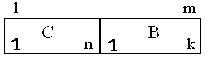
Рис. 2. Формат адреса при организации расслоении обращений к памяти за счет расслоения адресов.
Принцип расслоения адресов иллюстрирован на рис 3. (а).
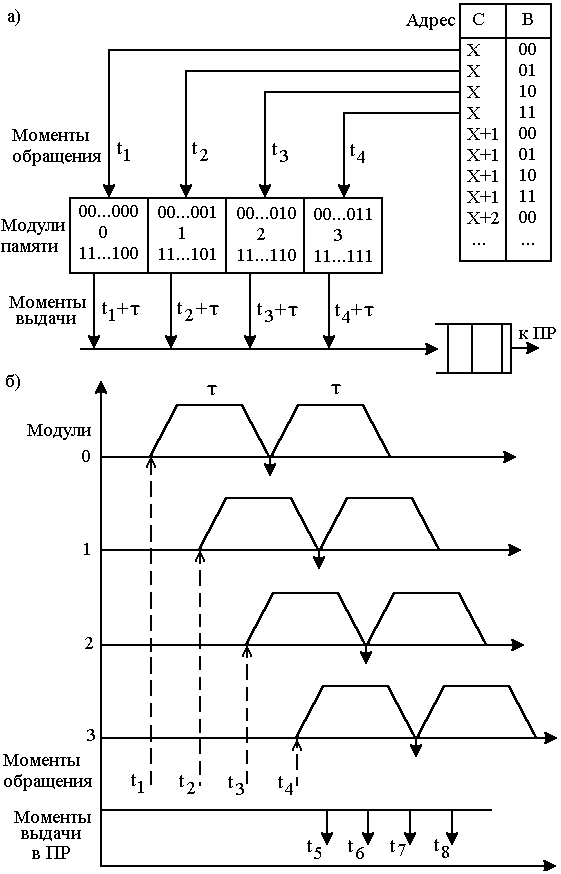
Рис 3 .Организация адресного пространства при расслоении памяти (а), временная диаграмма работы модулей (б)
Все команды и данные размещены в адресном пространстве последовательно. Однако ячейки памяти, имеющие смежные адреса, находятся в различных модулях памяти. Если ОП состоит из 4-х модулей, то номер модуля кодируется двумя младшими разрядами адреса. При этом полные m – разрядные адреса 0,4,8,…. Относятся к блоку 0, адреса 1,5,9,13 – к блоку 1, адреса 2,6,10 – к блоку 2 и адреса 3,7,11,15 – к блоку 3. Т.о., последовательность обращений к адресам 0,1,2,3,4,5,6….будет расслоена между 4 модулями : 0,1,2,3,0,1,2…(см рис 4)
0, 1, 2, 3, 4, 5, 6

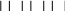
0, 1, 2, 3, 0, 1, 2…..
Рис. 4 Расслоение последовательности обращений к адресам между модулями памяти
Поскольку каждый модуль памяти имеет собственные схемы управления выборкой, можно обращение к следующему модулю производить, не дожидаясь ответа от предыдущего.
На временной диаграмме видно, что время доступа к каждому модулю равно: τ =4Т, где Т=t i+1-ti – длительность такта. В каждом такте следуют обращения к модулям памяти в моменты времени t1,t2,t3,…. При наличии 4-х модулей темп выдачи квантов информации из памяти в процессор будет соответствовать 1 такту Т, при этом скорость выдачи информации из каждого модуля в 4 раза ниже, т.е. составит 4Т.
Задержка в выдаче кванта информации относительно момента обращения к модулю также составит 4 такта, однако задержка в выдаче каждого последующего кванта относительно момента выдачи предыдущего составит Т.
При реализации расслоения по адресам число модулей памяти может быть произвольным и необязательно кратным 2. В некоторых компьютерах предусмотрено произвольное отключение модулей памяти, что позволяет исключить из конфигурации неисправные модули.
В современных высокопроизводительных компьютерах число модулей составляет 4-16, но иногда превышает 64.
Для повышения производительности мультипроцессорных систем, работающих в многозадачных режимах, применяют другие методы расслоения, при которых разные процессоры обращаются к различным модулям памяти.
Необходимо помнить, что процессоры ввода-вывода также занимают циклы памяти и вследствие этого могут сильно влиять на производительность системы. Для уменьшения этого влияния обращения ЦП и процессоров ввода-вывода организуют к разным модулям памяти.
Обобщением идеи расслоения памяти является возможность реализации нескольких независимых обращений, когда несколько контролеров памяти позволяют модулям памяти (или группам расслоенных модулей памяти) работать независимо.
Прямое уменьшение числа конфликтов чередующихся при обращении к памяти может быть достигнуто путем размещения программ данных в разных модулях.
Поскольку обращения к командам и элементам данных чередуются, то разделение памяти на память команд и память данных повышает быстродействие машины подобно рассмотренному выше механизму расслоения. Разделение памяти на память команд и память данных широко используется в системах управления или обработки сигналов. В подобного рода системах в качестве данных используются ПЗУ, цикл которых меньше цикла устройств, допускающих запись. Такое решение делает разделение данных и команд весьма эффективным.
Выбор той или иной схемы расслоения для компьютерной и др. вычислительной системы определяется целями (достижение высокой производительности при решении множества задач или высокого быстродействия при решении одной задачи), а также архитектурными и структурными особенностями системы и элементной базой (соотношением длительности циклов памяти и узлов обработки).
Кэш-память.
В функциональном отношении кэш-память рассматривается как буферное ЗУ, размещённое между основной (оперативной) памятью и процессором. Основное назначение кэш-памяти - кратковременное хранение и выдача активной информации процессору, что сокращает число обращений к основной памяти, скорость работы которой меньше, чем кэш-памяти.
За единицу информации при обмене между основной памятью и кэш-памятью принята строка, причём под строкой понимается набор слов, выбираемый из оперативной памяти при одном к ней обращении. Хранимая в оперативной памяти информация представляется, таким образом, совокупностью строк с последовательными адресами. В любой момент времени строки в кэш-памяти представляют собой копии строк из некоторого их набора в ОП, однако расположены они необязательно в такой же последовательности, как в ОП.
Построение кэш-памяти может осуществляться по различным принципам, которые будут рассмотрены ниже.
Типовая структура кэш-памяти
Рассмотрим типовую структуру кэш-памяти (рис. 5), включающую основные блоки, которые обеспечивают её взаимодействие с ОП и центральным процессором.
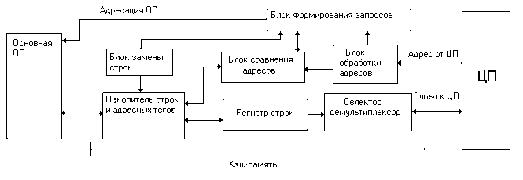
Рис. 5. Типовая структура кэш-памяти
Строки, составленные из информационных слов, и связанные с ними адресные теги хранятся в накопителе, который является основой кэш-памяти. Адрес требуемого слова, поступающий от центрального процессора (ЦП), вводится в блок обработки адресов, в котором реализуются принятые в данной кэш-памяти принципы использования адресов при организации их сравнения с адресными тегами. Само сравнение производится в блоке сравнения адресов (БСА), который конструктивно совмещается с накопителем, если кэш-память строится по схеме ассоциативной памяти. Назначение БСА состоит в выявлении попадания или промаха при обработке запросов от центрального процессора. Если имеет место кэш-попадание (т.е. искомое слово хранится в кэш-памяти, о чём свидетельствует совпадение кодов адреса, поступающего от центрального процессора, и одного из адресов некоторого адресного тега), то соответствующая строка из кэш-памяти переписывается в регистр строк. С помощью селектора-демультиплексора из неё выделяется искомое слово, которое и направляется в центральный процессор. В случае промаха с помощью блока формирования запросов осуществляется инициализация выборки из ОП необходимой строки. Адресация ОП при этом производится в соответствии с информацией, поступившей от центрального процессора. Выбираемая из памяти строка вместе со своим адресным тегом помещается в накопитель и регистр строк, а затем искомое слово передается в центральный процессор.
Для высвобождения места в кэш-памяти с целью записи выбираемой из ОП строки одна из строк удаляется. Определение удаляемой строки производится посредством блока замены строк, в котором хранится информация, необходимая для реализации принятой стратегии обновления находящихся в накопителе строк.
Способы размещения данных в кэш-памяти.
Существует четыре способа размещения данных в кэш-памяти:
-прямое распределение,
-полностью ассоциативное,
-частично ассоциативное,
-распределение секторов.
Конфликты снижают реальную производительность конвейера Существуют три класса конфликтов:
1. Структурные конфликты, которые возникают из-за конфликтов по ресурсам, когда аппаратные средства не могут поддерживать все возможные комбинации команд в режиме одновременного выполнения с совмещением.
2. Конфликты по данным, возникающие в случае, когда выполнение одной команды зависит от результата выполнения предыдущей команды.
3. Конфликты по управлению, которые возникают при конвейеризации команд переходов и других команд, которые изменяют значение счетчика команд.
Конфликты в конвейере приводят к необходимости приостановки выполнения команд (pipeline stall). Обычно в простейших конвейерах, если приостанавливается какая-либо команда, то все следующие за ней команды также приостанавливаются. Команды, предшествующие приостановленной, могут продолжать выполняться, но во время приостановки не выбирается ни одна новая команда.
Расслоение памяти.
Другой способ повышения пропускной способности оперативной памяти связан с построением памяти, состоящей на физическом уровне из нескольких модулей (банков) с автономными схемами адресации, записи и чтения. При этом на логическом уровне управления памятью организуются последовательные обращения к различным физическим модулям. Обращения к различным модулям могут перекрываться, и т.о. образуется своеобразный конвейер. Эта процедура носит название расслоения памяти. Целью данного метода является увеличение скорости доступа к памяти посредством совмещения фаз обращений ко многим модулям памяти. Существуют несколько вариантов организации расслоения. Наиболее часто используемый способ – расслоение обращений за счет расслоения адресов. Этот способ основывается на свойстве локальности программ и данных, предполагающем, что адрес следующей команды на 1 больше адреса предыдущей (иными словами, линейность программы нарушается только командами перехода). Аналогичная последовательность адресов генерируется процессором при чтении слов данных.
Т.о., типичный случай распределения адресов – последовательность вида а, а+1, а+2, а+3 и т.д. (для слов данных – увеличение на 1 – условно, на самом деле 1 – число байт в машинном слове). Из этого следует, что расслоение обращений возможно, если ячейки с адресами а, а+1, а+2, а+3 и т.д будут размещаться в блоках 0,1,2… Такое распределение ячеек по модулям (банкам) обеспечивается за счет использования адресов вида (см. рис. 2).
Здесь В – k–разрядный адрес модуля (младшая часть m–разрядного адреса), С – n–разрядный адрес ячейки в модуле В (старшая часть адреса).
Рис. 2. Формат адреса при организации расслоении обращений к памяти за счет расслоения адресов.
Принцип расслоения адресов иллюстрирован на рис 3. (а).
Рис 3 .Организация адресного пространства при расслоении памяти (а), временная диаграмма работы модулей (б)
Все команды и данные размещены в адресном пространстве последовательно. Однако ячейки памяти, имеющие смежные адреса, находятся в различных модулях памяти. Если ОП состоит из 4-х модулей, то номер модуля кодируется двумя младшими разрядами адреса. При этом полные m – разрядные адреса 0,4,8,…. Относятся к блоку 0, адреса 1,5,9,13 – к блоку 1, адреса 2,6,10 – к блоку 2 и адреса 3,7,11,15 – к блоку 3. Т.о., последовательность обращений к адресам 0,1,2,3,4,5,6….будет расслоена между 4 модулями : 0,1,2,3,0,1,2…(см рис 4)
0, 1, 2, 3, 4, 5, 6
0, 1, 2, 3, 0, 1, 2…..
Рис. 4 Расслоение последовательности обращений к адресам между модулями памяти
Поскольку каждый модуль памяти имеет собственные схемы управления выборкой, можно обращение к следующему модулю производить, не дожидаясь ответа от предыдущего.
На временной диаграмме видно, что время доступа к каждому модулю равно: τ =4Т, где Т=t i+1-ti – длительность такта. В каждом такте следуют обращения к модулям памяти в моменты времени t1,t2,t3,…. При наличии 4-х модулей темп выдачи квантов информации из памяти в процессор будет соответствовать 1 такту Т, при этом скорость выдачи информации из каждого модуля в 4 раза ниже, т.е. составит 4Т.
Задержка в выдаче кванта информации относительно момента обращения к модулю также составит 4 такта, однако задержка в выдаче каждого последующего кванта относительно момента выдачи предыдущего составит Т.
При реализации расслоения по адресам число модулей памяти может быть произвольным и необязательно кратным 2. В некоторых компьютерах предусмотрено произвольное отключение модулей памяти, что позволяет исключить из конфигурации неисправные модули.
В современных высокопроизводительных компьютерах число модулей составляет 4-16, но иногда превышает 64.
Для повышения производительности мультипроцессорных систем, работающих в многозадачных режимах, применяют другие методы расслоения, при которых разные процессоры обращаются к различным модулям памяти.
Необходимо помнить, что процессоры ввода-вывода также занимают циклы памяти и вследствие этого могут сильно влиять на производительность системы. Для уменьшения этого влияния обращения ЦП и процессоров ввода-вывода организуют к разным модулям памяти.
Обобщением идеи расслоения памяти является возможность реализации нескольких независимых обращений, когда несколько контролеров памяти позволяют модулям памяти (или группам расслоенных модулей памяти) работать независимо.
Прямое уменьшение числа конфликтов чередующихся при обращении к памяти может быть достигнуто путем размещения программ данных в разных модулях.
Поскольку обращения к командам и элементам данных чередуются, то разделение памяти на память команд и память данных повышает быстродействие машины подобно рассмотренному выше механизму расслоения. Разделение памяти на память команд и память данных широко используется в системах управления или обработки сигналов. В подобного рода системах в качестве данных используются ПЗУ, цикл которых меньше цикла устройств, допускающих запись. Такое решение делает разделение данных и команд весьма эффективным.
Выбор той или иной схемы расслоения для компьютерной и др. вычислительной системы определяется целями (достижение высокой производительности при решении множества задач или высокого быстродействия при решении одной задачи), а также архитектурными и структурными особенностями системы и элементной базой (соотношением длительности циклов памяти и узлов обработки).
Кэш-память.
В функциональном отношении кэш-память рассматривается как буферное ЗУ, размещённое между основной (оперативной) памятью и процессором. Основное назначение кэш-памяти - кратковременное хранение и выдача активной информации процессору, что сокращает число обращений к основной памяти, скорость работы которой меньше, чем кэш-памяти.
За единицу информации при обмене между основной памятью и кэш-памятью принята строка, причём под строкой понимается набор слов, выбираемый из оперативной памяти при одном к ней обращении. Хранимая в оперативной памяти информация представляется, таким образом, совокупностью строк с последовательными адресами. В любой момент времени строки в кэш-памяти представляют собой копии строк из некоторого их набора в ОП, однако расположены они необязательно в такой же последовательности, как в ОП.
Построение кэш-памяти может осуществляться по различным принципам, которые будут рассмотрены ниже.
Типовая структура кэш-памяти
Рассмотрим типовую структуру кэш-памяти (рис. 5), включающую основные блоки, которые обеспечивают её взаимодействие с ОП и центральным процессором.
Рис. 5. Типовая структура кэш-памяти
Строки, составленные из информационных слов, и связанные с ними адресные теги хранятся в накопителе, который является основой кэш-памяти. Адрес требуемого слова, поступающий от центрального процессора (ЦП), вводится в блок обработки адресов, в котором реализуются принятые в данной кэш-памяти принципы использования адресов при организации их сравнения с адресными тегами. Само сравнение производится в блоке сравнения адресов (БСА), который конструктивно совмещается с накопителем, если кэш-память строится по схеме ассоциативной памяти. Назначение БСА состоит в выявлении попадания или промаха при обработке запросов от центрального процессора. Если имеет место кэш-попадание (т.е. искомое слово хранится в кэш-памяти, о чём свидетельствует совпадение кодов адреса, поступающего от центрального процессора, и одного из адресов некоторого адресного тега), то соответствующая строка из кэш-памяти переписывается в регистр строк. С помощью селектора-демультиплексора из неё выделяется искомое слово, которое и направляется в центральный процессор. В случае промаха с помощью блока формирования запросов осуществляется инициализация выборки из ОП необходимой строки. Адресация ОП при этом производится в соответствии с информацией, поступившей от центрального процессора. Выбираемая из памяти строка вместе со своим адресным тегом помещается в накопитель и регистр строк, а затем искомое слово передается в центральный процессор.
Для высвобождения места в кэш-памяти с целью записи выбираемой из ОП строки одна из строк удаляется. Определение удаляемой строки производится посредством блока замены строк, в котором хранится информация, необходимая для реализации принятой стратегии обновления находящихся в накопителе строк.
Способы размещения данных в кэш-памяти.
Существует четыре способа размещения данных в кэш-памяти:
-прямое распределение,
-полностью ассоциативное,
-частично ассоциативное,
-распределение секторов.