Файл: Архитектура вычислительных систем Способы ускорения традиционных архитектур вс.rtf
ВУЗ: Не указан
Категория: Не указан
Дисциплина: Не указана
Добавлен: 29.11.2023
Просмотров: 67
Скачиваний: 1
ВНИМАНИЕ! Если данный файл нарушает Ваши авторские права, то обязательно сообщите нам.
Рассмотрим подробно каждый способ размещения и механизмы преобразования адресов. Предположим, что кэш содержит 128 строк, размер строки 16 слов, а основная память может содержать 16384 строки. Для адресации основной памяти используется 18 бит. Из них 14 старших показывают адрес строки, а младшие 4 – адрес слова внутри этой строки. Строки КЭШ-памяти указываются 7-разрядными адресами.
Прямое распределение.
При прямом распределении место хранения строк в кэш-памяти однозначно определяется по адресу строки. Структура кэш-памяти с прямым распределением показана на рис. 6
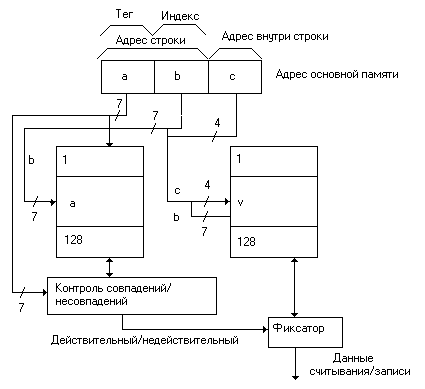
Рис. 6. Структура кэш-памяти с прямым распределением
Адрес основной памяти состоит из 14-ти разрядного адреса строки и 4-х разрядного адреса слова внутри этой строки. Адрес строки подразделяется на старшие 7 бит (тег) и младшие 7 бит (индекс). Для того чтобы поместить в кэш-память строку из основной памяти с адресом АВС, выбирается область внутри кэш-памяти с адресом В, который равен 7 младшим битам адреса строки АВ. Преобразование из АВС в В сводится только к выборке младших 7 бит адреса строки АВ. По адресу В в кэш-памяти может быть помещена любая из 128 строк основной памяти, имеющих адрес, 7 младших бит которого равны адресу В. Для того, чтобы определить, какая именно строка хранится в памяти данных в настоящий момент времени, используется запоминающее устройство емкостью 7*128 слов, в котором помещается по соответствующему адресу в качестве тега 7 старших бит адреса строки, хранящейся в данное время по адресу В кэш-памяти. Это запоминающее устройство называется теговой памятью. Память, в которой хранятся строки, называется памятью данных. Тег из теговой памяти считывается по адресу В, который образует 7 младших бит адреса строки АВ. Параллельно считыванию тега осуществляется доступ к памяти данных с помощью 11 младших бит (ВС) адреса основной памяти АВС. Если тег и старшие 7 бит адреса основной памяти совпадают, значит что данная строка существует в памяти данных (строка-V), то есть осуществляется кэш-попадание.
Если же происходит кэш-промах, то есть тег отличается от старших 7 бит, то из основной памяти считывается соответствующая строка, а из кэш-памяти удаляется строка-V, определяемая 7 младшими разрядами адреса строки, а на ее место помещается строка, считанная из основной памяти. Осуществляется также обновление соответствующего тега в теговой памяти. Способ прямого распределения реализуется довольно просто, однако из-за того, что место хранения строки в кэш-памяти однозначно определяется по адресу строки, вероятность сосредоточения областей хранения строк в некоторой части кэш-памяти высока, то есть замены строк будут происходить довольно часто. В этой ситуации эффективность кэш-памяти заметно снижается.
Полностью ассоциативное распределение
При таком способе размещения данных каждая строка основной памяти может быть размещена на месте любой строки кэш-памяти. Структура кэш-памяти с полностью ассоциативным распределением выглядит как показано на рис 7.
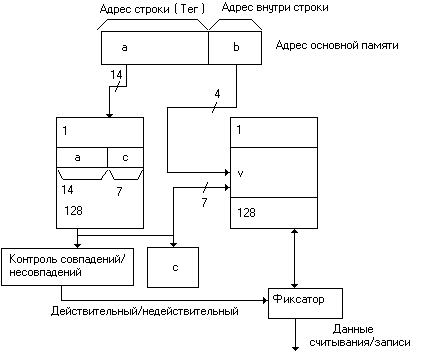
Рис. 7. Структура кэш-памяти с полностью ассоциативным распределением
При полностью ассоциативном распределении механизм преобразования адресов должен давать ответ на вопрос, существует ли копия строки с произвольным адресом в кэш-памяти, и, если существует, то по какому адресу. Для этого необходимо, чтобы теговая память являлась ассоциативной памятью. Входной информацией для ассоциативной памяти тегов является тег А (14-ти разрядный адрес строки), а выходной информацией – адрес строки внутри кэш-памяти (С). Каждое слово теговой памяти состоит из 14-разрядного тега и 7-разрядного адреса С строки внутри кэш-памяти. Ключом для поиска адреса строки внутри кэш-памяти является тег А (старшие 14 разрядов адреса основной памяти). При совпадении ключа А с одним из тегов Т теговой памяти (случай попадания) происходит выборка соответствующих данному тегу адреса С и обращение к памяти данных. Входной информацией для памяти данных является 11-ти разрядное слово ВС (7 бит адреса строки В + 4 бита адреса слова в данной строке С). В случае несовпадения ключа ни с одним из тегов теговой памяти (случай промаха) формируется запрос к основной памяти на выборку строки с соответствующим адресом и считывание этой строки. По этому способу при замене строк кандидатом на удаление могут быть все строки в кэш-памяти.
Частично ассоциативное распределение.
При данном способе размещения, несколько соседних строк (фиксированное число, не менее двух) из 128 строк кэш-памяти образуют структуру называемую группой. Структура кэш-памяти, основанная на использовании частично ассоциативного распределения, показана на рис. 8. В данном случае в одну группу Е входят 4 строки А, В, С, D.
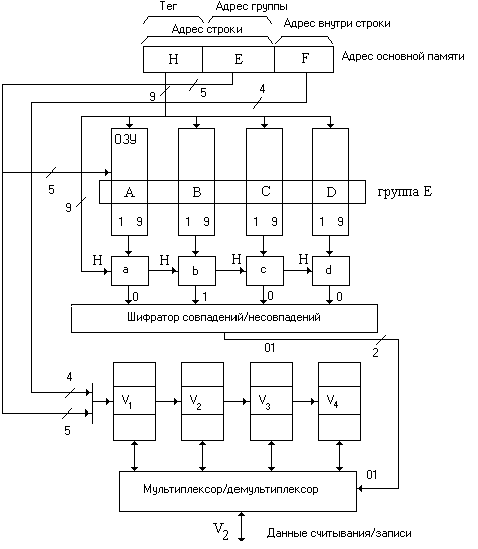
Рис. 8. Структура кэш-памяти, основанная на использовании частично ассоциативного распределения.
Адрес строки НЕ основной памяти (14 бит) разделяется на две части: Н-тег (старшие 9 бит) и Е - адрес группы (младшие 5 бит). Адрес строки внутри кэш-памяти, состоящий из 7 бит, разделяется на адрес группы Е (5 бит) и адрес строки внутри группы (2 бит: 00,01,10,11).
Для помещения в кэш-память строки, хранимой в ОП по адресу НЕF, необходимо выбрать группу с адресом Е. При этом не имеет значения, какая из четырех строк в группе может быть выбрана. Для выбора группы используется метод прямого распределения, а для выбора строки в группе используется метод полностью ассоциативного распределения.
Когда центральный процессор запрашивает доступ по адресу НЕF, то осуществляется обращение к массиву тегов по адресу Е, выбирается группа из четырёх тегов (а, b, с, d), каждый из которых сравнивается со старшими 9 битами (Н) адреса строки. На выходе четырех схем сравнения формируется унитарный код совпадения ( Н=А – код: 1000, Н=В – код: 0100, Н=С – код: 0010, Н=D – код: 0001), который на шифраторе преобразуется в двухразрядный позиционный код, служащий адресом для выбора банка данных (00,01,10,11) – адрес строки внутри группы.
Одновременно осуществляется обращение к массиву данных (банкам V1, V2, V3, V4,) по адресу ЕF (9 бит) и считывание из банка V2 требуемой строки или слова.
При пересылке новой строки в кэш-память удаляемая из нее строка выбирается из четырех строк соответствующего набора (группы).
Распределение секторов.
По этому способу основная память разбивается на секторы, состоящие из фиксированного числа строк, кэш-память также разбивается на секторы, состоящие из такого же числа строк. Допустим, в секторе 16 строк, а в строке – 16 слов. Структура кэш-памяти с распределением секторов представлена на рис. 9
В адресе основной памяти 10 старших бит задают адрес сектора А, следующие 4 бита – адрес строки В в секторе и младшие 4 бита – адрес слова С в строке.
При данной организации кэш-памяти, распределение секторов в кэш-памяти и основной памяти осуществлено полностью ассоциативно, то есть, каждый сектор А основной памяти может соответствовать любому сектору D в кэш-памяти. К каждой строке V, хранящейся в кэш-памяти, добавляется один бит достоверности (действительности); он показывает, совпадает или нет содержимое этой строки с содержимым строки в основной памяти, которая в данный момент анализируется на соответствие строки кэш-памяти. Если слова, запрашиваемого центральным процессором при доступе, не существует в кэш-памяти (бит достоверности, выбранный по адресу ВD равен 0), то сначала центральный процессор проверяет, был ли сектор А, содержащий это слово, помещен ранее в кэш-память. Если он отсутствует, то один из секторов кэш-памяти заменяется на этот сектор.
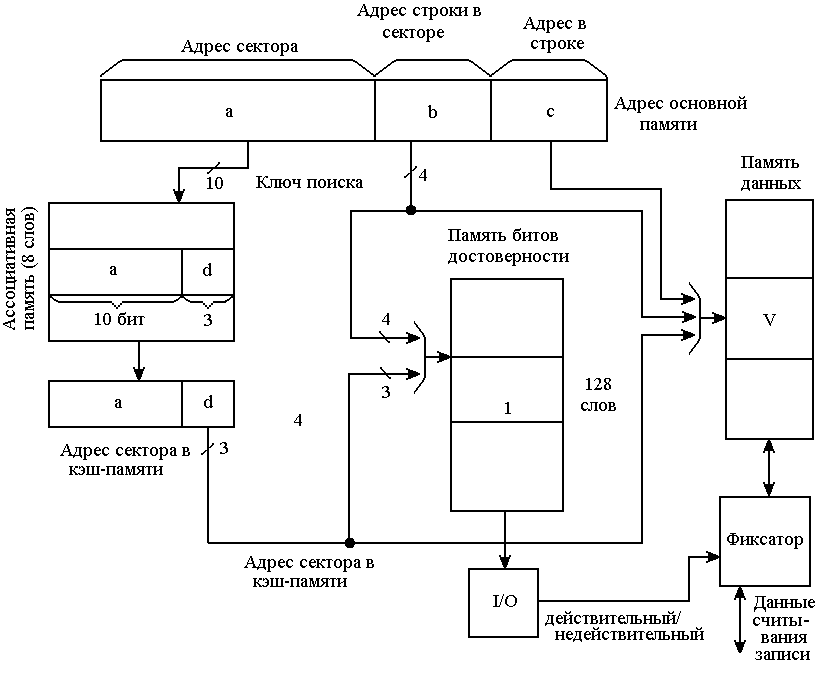
Рис. 9. Структура кэш-памяти с распределением секторов.
Если все сектора кэш-памяти используются, то выбирается один какой-нибудь сектор, и при необходимости только некоторые строки этого сектора возвращаются в основную память, а этот сектор можно использовать дальше.
Когда осуществляется доступ к сектору А в кэш-памяти и строка В, содержащая нужное слово С, пересылается из основной памяти, то бит достоверности устанавливается до пересылки строки. Все биты достоверности других строк этого сектора сбрасываются. Если сектор А, содержащий слово В доступ к которому запрашивается, уже находится в кэш-памяти, то, в том случае когда бит достоверности строки, содержащей это слово, равен 0, этот бит устанавливается и строка пересылается из основной памяти в данную область кэш-памяти. В том случае, когда бит достоверности уже равен 1, нужное слово можно считать из кэш-памяти.
Методы обновления строк в основной памяти
В таблице 1 приведены условия сохранения и обновления информации в ячейках кэш-памяти и основной памяти.
Если процессору требуется информация из некоторой ячейки основной памяти, а копия этой ячейки уже есть в кэш-памяти, то вместо оригинала считывается копия. В этом случае информация ни в кэш-памяти, ни в основной памяти не изменяется.
Табл.1.
Условия сохранения и обновления информации
| Режим работы | Наличие копии ячейки ОП в кэш-памяти | Информация в ячейке кэш-памяти | Информация в ячейке ОП |
| Чтение | Копия есть | Не изменяется | Не изменяется |
| Копии нет | Обновляется (создается копия) | Не изменяется | |
| Сквозная запись | Копия есть | Обновляется | Обновляется |
| Копии нет | Не изменяется | Обновляется | |
| Обратная запись | Копия есть | Обновляется | Не изменяется |
| Копии нет | Обновляется | Не изменяется |
При записи строк существует несколько методов обновления старой информации. Эти методы называются стратегией обновления строк основной памяти. Если результат обновления строк кэш-памяти не возвращается в основную память, то содержимое основной памяти становится неадекватным вычислительному процессу. Чтобы избежать таких ошибок, предусмотрены различные методы обновления основной памяти.