ВУЗ: Не указан
Категория: Не указан
Дисциплина: Не указана
Добавлен: 06.12.2023
Просмотров: 44
Скачиваний: 1
ВНИМАНИЕ! Если данный файл нарушает Ваши авторские права, то обязательно сообщите нам.
Домашняя работа по дисциплине «Эконометрика»
тема: «Регрессионный анализ»
В рамках данного задания мы будем проводить небольшое эконометрическое исследование на данных Российского мониторинга экономического положения и здоровья населения (РМЭЗ, он же RLMS). Опишем предварительные шаги, которые Вам надо будет сделать, прежде чем приступать к работе с данными.
1) Первый шаг - это выбрать данные согласно своему варианту.
2) Для загрузки данных в R необходимо воспользоваться пакетом rlms:
Пакет rlms предназначен для работы с данными исследования RLMS в R. Пакет можно установить командами:
install.packages("devtools")
devtools::install_github("bdemeshev/rlms")
или
devtools::install("./rlms-master")
3) Для исследования необходимо составить массив данных с отобранными переменными1:
-
Заработной платой на основе переменной *j13.2 -
Возрастом на основе переменной *_age -
Полом на основе переменной *h5 -
Наличием высшего образования на основе переменной *j72.5a -
Типом населенного пункта на основе переменной status -
Средней продолжительностью рабочей недели на основе переменной *j6.2 -
Семейным положением на основе переменной *j322 -
Удовлетворенностью условиями труда на основе переменной *j1.1.2
Описание переменных можно посмотреть файле описания для конкретной волны.
Чтобы получить массив для анализа нужно сделать следующие шаги:
1) Подгрузить пакеты и файл.
2) Отобрать только 8 переменных, описанных выше.
3) Отобрать только тех людей, у которых семейное положение входит в данный список:
-
Никогда в браке не состоял(а) -
Состоите в первом зарегистрированном браке -
Состоите в повторном зарегистрированном браке -
Разведены -
Вдовец/вдова
4) Отобрать только два типа населённого пункта: город и областной центр.
5) Отобрать только две категории степени удовлетворенности условиями труда: полностью удовлетворен и скорее удовлетворен.
6) Отобрать только тех людей, кто на вопрос про высшее образование ответил:
-
Учились -
Учитесь -
Нет
7) Из переменной тип населенного пункта сделать дамми-переменную, равную 1 для города и 0 для областного центра.
8) Из переменной удовлетворённость условиями труда сделать дамми-переменную
, равную 1 для полностью удовлетворен и 0 для скорее удовлетворен.
9) Из переменной пол сделать дамми-переменную, равную 1 для мужчин и 0 для женщин.
10) Переменную семейное положение необходимо превратить в набор фиктивных переменных. Использовать будем следующие категории:
-
Никогда в браке не состоял(а) -
Состоите в зарегистрированном браке или состоите в повторном зарегистрированном браке -
Разведены -
Вдовец/вдова
В итоге Вы должны получить 4 фиктивные переменные, отвечающие за принадлежность респондента к одной из этих категорий.
11) Из переменной высшее образование сделать дамми-переменную, равную 1 для тех, кто получил или получает высшее образование, и 0 для тех, кто не получал.
12) Создать массив данных, очищенный от пропущенных наблюдений, NA. Таким образом, у Вас должно получиться массив данных без NA!
Теперь, когда данные скачаны, загружены в R и отобраны в массив, Вы можете приступать к выполнению заданий.
Задание 1.
Рассчитайте основные характеристики для всех рядов вашего массива данных.
Определите чему равно количество женатых мужчин в его выборке?
Чему равно миниальное значение заработной платы, указанной респондентами?
Примечание: в этом задании необходимо представить таблицу с характеристиками переменных, такими как среднее значение, стандартное отклонение или вариация, минимальное максимальное значение и медиана, как в целом по выборке, так и отдельно по мужчинам и женщинам.
Сделайте вывод.
Задание 2.
Проведите графический анализ данных: постройте гистограммы заработной платы в зависимости от пола респондента, места проживания и наличия высшего образования и семейного положения.
Примечание: в итоге у Вас должно получиться четыре графика.
Сделайте вывод.
Задание 3.
Оцените зависимость заработной платы
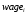 в рублях, респондента от дамми на пол
в рублях, респондента от дамми на пол 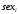 , возраста
, возраста 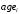 в годах, дамми на наличие высшего образования
в годах, дамми на наличие высшего образования 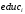 , дамми на проживание в городе или областном центре
, дамми на проживание в городе или областном центре 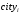
, дамми на удовлетворённость условиями труда
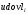 , средней продолжительности рабочей недели
, средней продолжительности рабочей недели 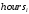 в часах и три дамми на семейный статус, беря одиноких людей за базовую категорию.
в часах и три дамми на семейный статус, беря одиноких людей за базовую категорию.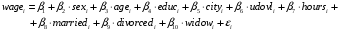
Дайте характеристику качества полученной модели: укажите чему равен скорректированный
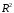 , как интерпретируется тест Фишера, а также укажите переменные значимо влияющие на результат, дайте их интерпретацию.
, как интерпретируется тест Фишера, а также укажите переменные значимо влияющие на результат, дайте их интерпретацию.Выпишите уравнение для разведенной женщины, проживающей в городе, имеющей высшее образование.
Примечание: в данном задании надо привести таблицу с коэффициентами модели, а также с указанием качественных характеристик модели.
Выпишите уравнение для разведенной женщины, проживающей в городе, имеющей высшее образование
Задание 4.
С помощью критерия VIF проверьте построенную в п.3 модель на мультиколлинеарность. Для этого используйте пакет library(car) .
Сделайте вывод.
Задание 5.
Оценив регрессию, проведите формальный тест на гетероскедастичность, а именно тест Бройша-Пагана. Для этого используйте пакет library(lmtest) .
Чему равно наблюдаемое значение тестовой статистики в данном тесте? И какой можно сделать вывод.
Задание 6.
Если есть гетероскедастичность в данных, оцените регрессию и проверьте гипотезы, используя стандартные ошибки с поправкой на гетероскедастичность. Для этого используйте пакет library(lmtest) .
Какие факторы являются значимыми при робастных ошибках? Как изменились Ваши выводы относительно влияния переменных по сравнению с выводами из п.3? Для чего необходимо было переходить к робастным оценкам?
Примечание: как и в п.3 в этом задании должна быть представлена таблица с результатами анализа.
Задание 7.
Вам необходимо проверить, можно ли использовать более короткую модель без дамми на семейный статус с помощью теста Вальда. Для этого используйте пакет library(lmtest) функцию waldtest().
Альтернативная модель имеет следующйи вид:
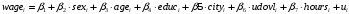
При тестировании гипотезы о нескольких линейных ограничениях, как рассчитывается и чему равно значение тестовой статистики? И какой Вы сделаете вывод.
Задание 8.
Также сравните две модели с помощью информационных критериев AIC и BIC. Для этого используйте пакет library(memisc) .
Какой вывод Вы можете сделать?
Задание 9.
Возможно в Вашей первой модели есть пропущенные переменные в данных, поэтому необходимо провести тест Рамсея на пропущенные переменные. Для этого используйте пакет library(lmtest) .
Какой вывод после проведения теста можете сделать?
Предложите свою спецификацию модели. Оцените её и проверьте с помощью теста Рамсея на пропущенные переменные.
Задание 10.
Теория человеческого капитала утверждает, что модель заработной платы – это полулогарифмическую модель:
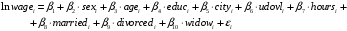
Оцените уравнение полулогарифмической модели, дайте интерпретацию всех значимых оценок коэффициентов модели.
Какая из моделей (из п.3 или п.10) лучше описывает исходные данные? Для ответа на этот вопрос проведите тест Бокса-Кокса (в ответе приведите гипотезу теста и его результат).
Если данная модель лучше модели из п.3, повторите для нее все задания с 4 по 9.
1 Вместо «*» ставим букву согласно своей волне.