ВУЗ: Не указан
Категория: Не указан
Дисциплина: Не указана
Добавлен: 06.12.2023
Просмотров: 57
Скачиваний: 1
ВНИМАНИЕ! Если данный файл нарушает Ваши авторские права, то обязательно сообщите нам.
, как будет изменяться a из формулы (2) при добавлении нового вектора данных. В первом порядке теории возмущений найдем изменение вектора коэффициента a при изменении вектора p и матрицы Q:
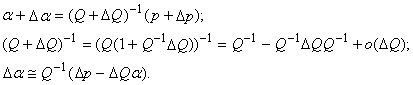
Пусть на выборке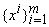 вычислены p, Q, Q‑1. При получении нового вектора данных xm+1 и соответствующего значения F(xm+1)=fm+1 имеем 2:
вычислены p, Q, Q‑1. При получении нового вектора данных xm+1 и соответствующего значения F(xm+1)=fm+1 имеем 2:
где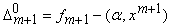 ‑ ошибка на вектореданных xm+1 регрессионной зависимости, полученной на основании выборки .
‑ ошибка на вектореданных xm+1 регрессионной зависимости, полученной на основании выборки .
Пересчитывая по приведенным формулам p, Q, Q‑1 и a после каждого получения данных, получаем процесс, в котором последовательно уточняются уравнения линейной регрессии. И требуемый объем памяти, и количество операций имеют порядок n2 ‑ из-за необходимости накапливать и модифицировать матрицу Q‑1. Конечно, это меньше, чем потребуется на обычное обращение матрицы Q на каждом шаге, однако следующий простой алгоритм еще экономнее. Он вовсе не обращается к матрицам Q, Q‑1 и основан на уменьшении на каждом шаге величины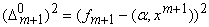 ‑ квадрата ошибки на вектореданных xm+1 регрессионной зависимости, полученной на основании выборки .
‑ квадрата ошибки на вектореданных xm+1 регрессионной зависимости, полученной на основании выборки .
Вновь обратимся к формуле (2) и будем рассматривать n+1-мерные векторы данных и коэффициентов. Обозначим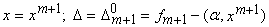 . Тогда
. Тогда
Последняя элементарная формула
столь важна в теории адаптивных сумматоров, что носит «именное название» ‑ формула Уидроу. «Обучение» адаптивного сумматора методом наискорейшего спуска состоит в изменении вектора коэффициентов a в направлении антиградиента D2: на каждом шаге к a добавляется h´D´x, где h ‑ величина шага.
Если при каждом поступлении нового вектора данных x изменять a указанным образом, то получим последовательную процедуру построения линейной аппроксимации функции F(x). Такой алгоритм обучения легко реализуется аппаратными средствами (изменение веса связи aj есть произведение прошедшего по ней сигнала xj на ошибку D и на величину шага). Возникает, однако, проблема сходимости: если h слишком мало, то сходимость будет медленной, если же слишком велико, то произойдет потеря устойчивости и сходимости не будет вовсе. Детальному изложению этого подхода и его приложений посвящен учебник [15].
Задача четкого разделения двух классов по обучающей выборке ставится так: имеется два набора векторов x1 , ..., xm и y1,...,ym . Заранее известно, что x i относится к первому классу, а y i - ко второму. Требуется построить решающее правило, то есть определить такую функцию f(x), что при f(x)>0 вектор x относится к первому классу, а при f(x)<0 ‑ ко второму.
Координаты классифицируемых векторов представляют собой значения некоторых признаков (свойств) исследуемых объектов.
Эта задача возникает во многих случаях: при диагностике болезней и определении неисправностей машин по косвенным признакам, при распознавании изображений и сигналов и т.п.
Строго говоря, классифицируются не векторы свойств, а объекты, которые обладают этими свойствами. Это замечание становится важным в тех случаях, когда возникают затруднения с построением решающего правила - например тогда, когда встречаются принадлежащие к разным классам объекты, имеющие одинаковые признаки. В этих случаях возможно несколько решений:
Линейное разделение классов состоит в построении линейного решающего правила ‑ то есть такого вектора a и числа a0 (называемого порогом), что при (x,a)>a0 x относится к первому классу, а при (x, a)0 - ко второму.
Поиск такого решающего правила можно рассматривать как разделение классов в проекции на прямую. Вектор a задает прямую, на которую ортогонально проектируются все точки, а число a0 ‑ точку на этой прямой, отделяющую первый класс от второго.
Простейший и подчас очень удобный выбор состоит в проектировании на прямую, соединяющую центры масс выборок. Центр масс вычисляется в предположении, что массы всех точек одинаковы и равны 1. Это соответствует заданию a в виде
Во многих случаях удобнее иметь дело с векторами единичной длины. Нормируя a, получаем:
a= ((y1+ y2+...+ym)/m ‑(x1+ x2+...+ x n)/n)/||(y1+ y2+...+ym)/m ‑(x1+ x2+...+ x n)/n||.
Выбор a0 может производиться из различных соображений. Простейший вариант ‑ посередине между центрами масс выборок:
a0=(((y1+ y2+...+ym)/m,a)+((x1+ x2+...+ x n)/n,a))/2.
Более тонкие способы построения границы раздела классов a0 учитывают различные вероятности появления объектов разных классов, и оценки плотности распределения точек классов на прямой. Чем меньше вероятность появления данного класса, тем более граница раздела приближается к центру тяжести соответствующей выборки.
Можно для каждого класса построить приближенную плотность вероятностей распределения проекций его точек на прямую (это намного проще, чем для многомерного распределения) и выбирать a0, минимизируя вероятность ошибки. Пусть решающее правило имеет вид: при (x, a)>a0 x относится к первому классу, а при (x, a)0 ‑ ко второму. В таком случае вероятность ошибки будет равна
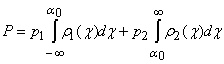
где p1, p2 ‑ априорные вероятности принадлежности объекта соответствующему классу,
r1(c), r2(c) ‑ плотности вероятности для распределения проекций c точек x в каждом классе.
Приравняв нулю производную вероятности ошибки по a0, получим: число a0, доставляющее минимум вероятности ошибки, является корнем уравнения:
либо (если у этого уравнения нет решений) оптимальным является правило, относящее все объекты к одному из классов.
Если принять гипотезу о нормальности распределений:
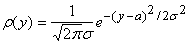 ,
,
то для определения a0 получим:
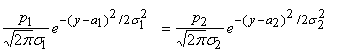 ,
,
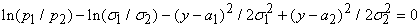
Если это уравнение имеет два корня y=a1, a2, (a12) то наилучшим решающим правилом будет: при a1<(x, a)2 объект принадлежит одному классу, а при a1>(x, a) или (x, a)>a2 ‑ другому (какому именно, определяется тем, которое из произведений p iri(c) больше). Если корней нет, то оптимальным является отнесение к одному из классов. Случай единственного корня представляет интерес только тогда, когда s1=s2. При этом уравнение превращается в линейное и мы приходим к исходному варианту ‑ единственной разделяющей точке a0.
Таким образом, разделяющее правило с единственной разделяющей точкой a0 не является наилучшим для нормальных распределений и надо искать две разделяющие точки.
Если сразу ставить задачу об оптимальном разделении многомерных нормальных распределений, то получим, что наилучшей разделяющей поверхностью является квадрика (на прямой типичная «квадрика» ‑ две точки). Предполагая, что ковариационные матрицы классов совпадают (в одномерном случае это предположение о том, что s1=s2), получаем линейную разделяющую поверхность. Она ортогональна прямой, соединяющей центры выборок не в обычном скалярном произведении, а в специальном: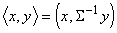 , где S ‑ общая ковариационная матрица классов. За деталями отсылаем к прекрасно написанной книге [17], см. также [11,12,16].
, где S ‑ общая ковариационная матрица классов. За деталями отсылаем к прекрасно написанной книге [17], см. также [11,12,16].
Важная возможность усовершенствовать разделяющее правило состоит с использовании оценки не просто вероятности ошибки, а среднего риска: каждой ошибке приписывается «цена» ci и минимизируется сумма c1p1r1(c)+c2p2r2(c). Ответ получается практически тем же (всюду p i заменяются на cip i), но такая добавка важна для многих приложений.
Требование безошибочности разделяющего правила на обучающей выборке принципиально отличается от обсуждавшихся критериев оптимальности. На основе этого требования строится персептрон Розенблатта ‑ «дедушка» современных нейронных сетей [1].
Возьмем за основу при построении гиперплоскости, разделяющей классы, отсутствие ошибок на обучающей выборке. Чтобы удовлетворить этому условию, придется решать систему линейных неравенств:
(x i, a)>a0 (i =1,...,n)
(yj , a)
0 (j=1,...,m).
Здесь x i (i =1,..,n) - векторы из обучающей выборки, относящиеся к первому классу, а yj (j=1,..,n) - ко второму.
Удобно переформулировать задачу. Увеличим размерности всех векторов на единицу, добавив еще одну координату ‑a0 к a, x0 =1 - ко всем x и y0 =1 ‑ ко всем y . Сохраним для новых векторов прежние обозначения - это не приведет к путанице.
Наконец, положим z i =x i (i =1,...,n), zj = ‑yj (j=1,...,m).
Тогда получим систему n+m неравенств
(z i,a)>0 (i =1,...,n+m),
которую будем решать относительно a. Если множество решений непусто, то любой его элемент a порождает решающее правило, безошибочное на обучающей выборке.
Итерационный алгоритм решения этой системы чрезвычайно прост. Он основан на том, что для любого вектора x его скалярный квадрат (x,x) больше нуля. Пусть a ‑ некоторый вектор, претендующий на роль решения неравенств (z i,a)>0 (i =1,...,n+m), однако часть из них не выполняется. Прибавим те z i, для которых неравенства имеют неверный знак, к вектору a и вновь проверим все неравенства (z i,a)>0 и т.д. Если они совместны, то процесс сходится за конечное число шагов. Более того, добавление z i к a можно производить сразу после того, как ошибка ((z i,a)<0) обнаружена, не дожидаясь проверки всех неравенств ‑ и этот вариант алгоритма тоже сходится [2].
0>
Пусть на выборке
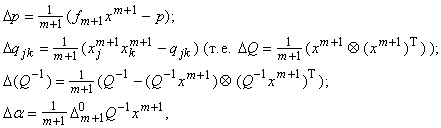 | (4) |
где
Пересчитывая по приведенным формулам p, Q, Q‑1 и a после каждого получения данных, получаем процесс, в котором последовательно уточняются уравнения линейной регрессии. И требуемый объем памяти, и количество операций имеют порядок n2 ‑ из-за необходимости накапливать и модифицировать матрицу Q‑1. Конечно, это меньше, чем потребуется на обычное обращение матрицы Q на каждом шаге, однако следующий простой алгоритм еще экономнее. Он вовсе не обращается к матрицам Q, Q‑1 и основан на уменьшении на каждом шаге величины
Вновь обратимся к формуле (2) и будем рассматривать n+1-мерные векторы данных и коэффициентов. Обозначим
| | (5) |
Последняя элементарная формула
столь важна в теории адаптивных сумматоров, что носит «именное название» ‑ формула Уидроу. «Обучение» адаптивного сумматора методом наискорейшего спуска состоит в изменении вектора коэффициентов a в направлении антиградиента D2: на каждом шаге к a добавляется h´D´x, где h ‑ величина шага.
Если при каждом поступлении нового вектора данных x изменять a указанным образом, то получим последовательную процедуру построения линейной аппроксимации функции F(x). Такой алгоритм обучения легко реализуется аппаратными средствами (изменение веса связи aj есть произведение прошедшего по ней сигнала xj на ошибку D и на величину шага). Возникает, однако, проблема сходимости: если h слишком мало, то сходимость будет медленной, если же слишком велико, то произойдет потеря устойчивости и сходимости не будет вовсе. Детальному изложению этого подхода и его приложений посвящен учебник [15].
Задача четкого разделения двух классов по обучающей выборке ставится так: имеется два набора векторов x1 , ..., xm и y1,...,ym . Заранее известно, что x i относится к первому классу, а y i - ко второму. Требуется построить решающее правило, то есть определить такую функцию f(x), что при f(x)>0 вектор x относится к первому классу, а при f(x)<0 ‑ ко второму.
Координаты классифицируемых векторов представляют собой значения некоторых признаков (свойств) исследуемых объектов.
Эта задача возникает во многих случаях: при диагностике болезней и определении неисправностей машин по косвенным признакам, при распознавании изображений и сигналов и т.п.
Строго говоря, классифицируются не векторы свойств, а объекты, которые обладают этими свойствами. Это замечание становится важным в тех случаях, когда возникают затруднения с построением решающего правила - например тогда, когда встречаются принадлежащие к разным классам объекты, имеющие одинаковые признаки. В этих случаях возможно несколько решений:
-
искать дополнительные признаки, позволяющие разделить классы; -
примириться с неизбежностью ошибок, назначить за каждый тип ошибок свой штраф (c12 - штраф за то, что объект первого класса отнесен ко второму, c21 - за то, что объект второго класса отнесен к первому) и строить разделяющее правило так, чтобы минимизировать математическое ожидание штрафа; -
перейти к нечеткому разделению классов - строить так называемые "функции принадлежности" f1(x) и f2(x) ‑ fi(x) оценивает степень уверенности при отнесении объекта к i -му классу (i =1,2), для одного и того же x может быть так, что и f1(x)>0, и f2(x)>0.
Линейное разделение классов состоит в построении линейного решающего правила ‑ то есть такого вектора a и числа a0 (называемого порогом), что при (x,a)>a0 x относится к первому классу, а при (x, a)0 - ко второму.
Поиск такого решающего правила можно рассматривать как разделение классов в проекции на прямую. Вектор a задает прямую, на которую ортогонально проектируются все точки, а число a0 ‑ точку на этой прямой, отделяющую первый класс от второго.
Простейший и подчас очень удобный выбор состоит в проектировании на прямую, соединяющую центры масс выборок. Центр масс вычисляется в предположении, что массы всех точек одинаковы и равны 1. Это соответствует заданию a в виде
| a= (y1+ y2+...+ym)/m ‑(x1+ x2+...+ x n)/n. | (6) |
Во многих случаях удобнее иметь дело с векторами единичной длины. Нормируя a, получаем:
a= ((y1+ y2+...+ym)/m ‑(x1+ x2+...+ x n)/n)/||(y1+ y2+...+ym)/m ‑(x1+ x2+...+ x n)/n||.
Выбор a0 может производиться из различных соображений. Простейший вариант ‑ посередине между центрами масс выборок:
a0=(((y1+ y2+...+ym)/m,a)+((x1+ x2+...+ x n)/n,a))/2.
Более тонкие способы построения границы раздела классов a0 учитывают различные вероятности появления объектов разных классов, и оценки плотности распределения точек классов на прямой. Чем меньше вероятность появления данного класса, тем более граница раздела приближается к центру тяжести соответствующей выборки.
Можно для каждого класса построить приближенную плотность вероятностей распределения проекций его точек на прямую (это намного проще, чем для многомерного распределения) и выбирать a0, минимизируя вероятность ошибки. Пусть решающее правило имеет вид: при (x, a)>a0 x относится к первому классу, а при (x, a)0 ‑ ко второму. В таком случае вероятность ошибки будет равна
где p1, p2 ‑ априорные вероятности принадлежности объекта соответствующему классу,
r1(c), r2(c) ‑ плотности вероятности для распределения проекций c точек x в каждом классе.
Приравняв нулю производную вероятности ошибки по a0, получим: число a0, доставляющее минимум вероятности ошибки, является корнем уравнения:
| p1r1(c)=p2r2(c), | (7) |
либо (если у этого уравнения нет решений) оптимальным является правило, относящее все объекты к одному из классов.
Если принять гипотезу о нормальности распределений:
то для определения a0 получим:
,Если это уравнение имеет два корня y=a1, a2, (a12) то наилучшим решающим правилом будет: при a1<(x, a)2 объект принадлежит одному классу, а при a1>(x, a) или (x, a)>a2 ‑ другому (какому именно, определяется тем, которое из произведений p iri(c) больше). Если корней нет, то оптимальным является отнесение к одному из классов. Случай единственного корня представляет интерес только тогда, когда s1=s2. При этом уравнение превращается в линейное и мы приходим к исходному варианту ‑ единственной разделяющей точке a0.
Таким образом, разделяющее правило с единственной разделяющей точкой a0 не является наилучшим для нормальных распределений и надо искать две разделяющие точки.
Если сразу ставить задачу об оптимальном разделении многомерных нормальных распределений, то получим, что наилучшей разделяющей поверхностью является квадрика (на прямой типичная «квадрика» ‑ две точки). Предполагая, что ковариационные матрицы классов совпадают (в одномерном случае это предположение о том, что s1=s2), получаем линейную разделяющую поверхность. Она ортогональна прямой, соединяющей центры выборок не в обычном скалярном произведении, а в специальном:
Важная возможность усовершенствовать разделяющее правило состоит с использовании оценки не просто вероятности ошибки, а среднего риска: каждой ошибке приписывается «цена» ci и минимизируется сумма c1p1r1(c)+c2p2r2(c). Ответ получается практически тем же (всюду p i заменяются на cip i), но такая добавка важна для многих приложений.
Требование безошибочности разделяющего правила на обучающей выборке принципиально отличается от обсуждавшихся критериев оптимальности. На основе этого требования строится персептрон Розенблатта ‑ «дедушка» современных нейронных сетей [1].
Возьмем за основу при построении гиперплоскости, разделяющей классы, отсутствие ошибок на обучающей выборке. Чтобы удовлетворить этому условию, придется решать систему линейных неравенств:
(x i, a)>a0 (i =1,...,n)
(yj , a)
0 (j=1,...,m).
Здесь x i (i =1,..,n) - векторы из обучающей выборки, относящиеся к первому классу, а yj (j=1,..,n) - ко второму.
Удобно переформулировать задачу. Увеличим размерности всех векторов на единицу, добавив еще одну координату ‑a0 к a, x0 =1 - ко всем x и y0 =1 ‑ ко всем y . Сохраним для новых векторов прежние обозначения - это не приведет к путанице.
Наконец, положим z i =x i (i =1,...,n), zj = ‑yj (j=1,...,m).
Тогда получим систему n+m неравенств
(z i,a)>0 (i =1,...,n+m),
которую будем решать относительно a. Если множество решений непусто, то любой его элемент a порождает решающее правило, безошибочное на обучающей выборке.
Итерационный алгоритм решения этой системы чрезвычайно прост. Он основан на том, что для любого вектора x его скалярный квадрат (x,x) больше нуля. Пусть a ‑ некоторый вектор, претендующий на роль решения неравенств (z i,a)>0 (i =1,...,n+m), однако часть из них не выполняется. Прибавим те z i, для которых неравенства имеют неверный знак, к вектору a и вновь проверим все неравенства (z i,a)>0 и т.д. Если они совместны, то процесс сходится за конечное число шагов. Более того, добавление z i к a можно производить сразу после того, как ошибка ((z i,a)<0) обнаружена, не дожидаясь проверки всех неравенств ‑ и этот вариант алгоритма тоже сходится [2].
0>