Файл: Вариант 1 Какие задачи линейного программирования называются транспортными.doc
Добавлен: 09.12.2023
Просмотров: 43
Скачиваний: 2
ВНИМАНИЕ! Если данный файл нарушает Ваши авторские права, то обязательно сообщите нам.
и 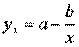 , соответственно.
, соответственно.
Первая функция характеризует нелинейные соотношения между нормой безработицы x и процентом прироста заработной платы у. Из данной зависимости следует, что с ростом уровня безработицы темпы роста заработной платы в пределе стремится к нулю.
Вторая функция устанавливает закономерность – с ростом дохода доля расходов на продовольствие - уменьшается. Здесь у, обозначает - долю расходов на непродовольственные товары; х – доходы.
Первая группа нелинейных функций легко может быть линеаризована (приведены к линейному виду). Например, для полинома к-го порядка
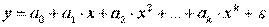 производя замену:
производя замену:
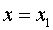 ,
, 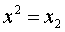 ,
, 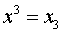 ,…,
,…, 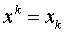
получим линейную модель вида
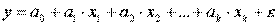 .
.
Аналогично могут быть линеаризованы и другие виды нелинейных функций 1-й группы, производя соответствующие замены.
Для оценки параметров нелинейных функций первой группы можно использовать, обычный МНК, аналогично, как и в случае линейных функций.
Иначе обстоит дело с группой регрессионных, нелинейных функций по оцениваемым параметрам. Данную группу функций можно разбить на две подгруппы: нелинейные модели внутренне линейные и нелинейные модели внутренне нелинейные.
Рассмотрим степенную функцию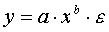 . Она нелинейна относительно параметров
. Она нелинейна относительно параметров 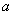 и b. Однако ее можно считать внутренне линейной, так как, прологарифмировав ее можно привести к линейному виду:
и b. Однако ее можно считать внутренне линейной, так как, прологарифмировав ее можно привести к линейному виду:
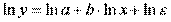 .
.
Следовательно, ее параметры могут быть найдены обычным МНК.
Если модель представить в виде:
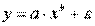
, то модель становится внутренне нелинейной, т.к. ее невозможно преобразовать в линейный вид.
Внутренне нелинейной будет и модель вида
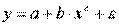
В эконометрических исследованиях, часто к нелинейным относят модели, только внутренне нелинейные по оцениваемым параметрам, а все другие модели, которые легко преобразуются в линейный вид, относятся к группе линейных моделей. Например, к линейным относят модель:
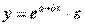 , так как
, так как
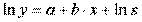 .
.
Если, модель внутренне нелинейна по параметрам, то для оценки параметров используются итеративные методы, успешность которых зависит от вида функции и особенностей применяемого итеративного подхода.
МНК в случае нелинейных функций, рассмотрим на примере оценки параметров степенной функции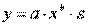 .
.
Прологарифмировав данную функцию, получим:
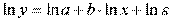 или, производя обозначения:
или, производя обозначения:
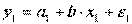 , где
, где
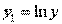 ;
; 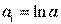 ;
; 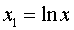 ;
; 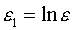 .
.
Применив МНК к полученному уравнению:
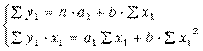 , или
, или
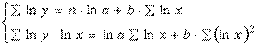
Параметр b определяется непосредственно из системы, а параметр а – косвенным путем: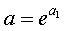
Оценка тесноты корреляционной зависимости в случае нелинейной регрессии производится с помощью индекса корреляции (
R):
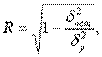
где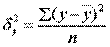 ,
,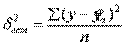 ,
, 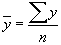 ,
,
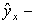 значения результативного признака, рассчитанные по уравнению регрессии.
значения результативного признака, рассчитанные по уравнению регрессии.
Величина данного показателя находится в границах: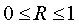 , чем она ближе к единице, тем теснее связь рассматриваемых признаков, тем надежнее найденное уравнение регрессии.
, чем она ближе к единице, тем теснее связь рассматриваемых признаков, тем надежнее найденное уравнение регрессии.
Следует помнить, что если для линейной зависимости имеет место равенство: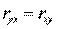 , то при криволинейной зависимости
, то при криволинейной зависимости 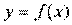
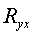 не равен
не равен 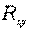 .Величина R2 называется индексом детерминации.
.Величина R2 называется индексом детерминации.
Оценка существенности индекса корреляции проводится, так же как и оценка надежности коэффициента корреляции. Индекс детерминации используется для проверки существенности в целом уравнения нелинейной регрессии по F-критерию Фишера:
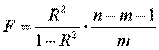 ,
,
где R2 - индекс детерминации;
n - число наблюдений;
m - число параметров при переменных х.
Индекс детерминации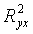 можно сравнивать с коэффициентом детерминации
можно сравнивать с коэффициентом детерминации 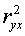 для обоснования возможности применения линейной функции.
для обоснования возможности применения линейной функции.
Если величина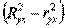 не превышает 0,1, то предположение о линейной форме связи считается оправданным. В противном случае проводится оценка существенности различия между
не превышает 0,1, то предположение о линейной форме связи считается оправданным. В противном случае проводится оценка существенности различия между
 и r2yx, вычисленных по одним и тем же исходным данным, через t - критерий Стьюдента:
и r2yx, вычисленных по одним и тем же исходным данным, через t - критерий Стьюдента:
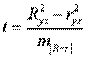 ,
,
где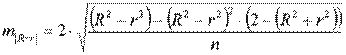 ,
,
Если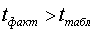 , то различия между
, то различия между 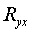 и
и 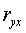 существенны и замена нелинейной регрессии линейной - невозможна. Практически, если
существенны и замена нелинейной регрессии линейной - невозможна. Практически, если 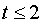 , то различия между и несущественны, и, следовательно, возможно применение линейной регрессии.
, то различия между и несущественны, и, следовательно, возможно применение линейной регрессии.
Фактические значения результативного признака отличаются от теоретических, рассчитанных по уравнению регрессии, т.е.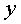 и
и 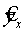 . Чем меньше это отличие, тем ближе теоретические значения подходят к эмпирическим данным, лучше качество модели. Чтобы иметь общее представление о качестве модели из относительных отклонений по каждому наблюдению, определяют среднюю ошибку аппроксимации:
. Чем меньше это отличие, тем ближе теоретические значения подходят к эмпирическим данным, лучше качество модели. Чтобы иметь общее представление о качестве модели из относительных отклонений по каждому наблюдению, определяют среднюю ошибку аппроксимации:
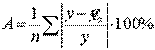
Существует и другая формула определения средней ошибки аппроксимации:
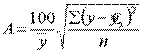 , где
, где  .
.
Ошибка аппроксимации в пределах 5-7% свидетельствует о хорошем подборе модели к исходным данным.
Возможность построения нелинейных моделей, как с помощью их приведения к линейному виду, так и путем использования нелинейной регрессии, значительно повышает универсальность регрессионного анализа, но и усложняет задачу исследователя.
Возникает вопрос: с чего начать - с линейной зависимости или с нелинейной, и если с последней, то, какого типа.
Если ограничиться парной регрессией, то можно построить график наблюдений у и х и принять решение. Однако очень часто несколько разных нелинейных функций приблизительно соответствуют наблюдениям, если они лежат на некоторой кривой. А в случае множественной регрессии невозможно даже построить график.
При рассмотрении альтернативных моделей с одним и тем же определением зависимой переменной процедура выбора достаточно проста. Наиболее разумным является оценивание регрессии на основе всех вероятных функций, и выбор функции, в наибольшей степени объясняющей изменения зависимой переменной. Если для одной модели коэффициент R2 значительно больше, чем для другой, то вы сможете сделать оправданный выбор без особых раздумий, однако, если значения R2 для двух моделей приблизительно равны, то проблема выбора существенно усложняется.
В этом случае следует использовать стандартную процедуру, известную под названием теста Бокса – Кокса.
Если необходимо сравнить модели с использованием у и lny в качестве зависимой переменной, то можно использовать вариант теста, разработанный Полом Зарембкой. Процедура включает следующие шаги:
1) Вычисляется среднее геометрическое значений у в выборке, (оно совпадает с экспонентой среднего арифметического lny):
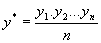
2) Пересчитываются наблюдения у, т.е. они делятся на это значение, то есть
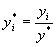
3) Оценивается регрессия для линейной модели с использованием у*i вместе yi и для логарифмической модели с использованием ln(y*i) вместо ln(yi). Теперь значения суммы квадратов отклонений для двух регрессий сравнимы, и, следовательно, модель с меньшей суммой квадратов отклонений обеспечивает лучшее соответствие.
Первая функция характеризует нелинейные соотношения между нормой безработицы x и процентом прироста заработной платы у. Из данной зависимости следует, что с ростом уровня безработицы темпы роста заработной платы в пределе стремится к нулю.
Вторая функция устанавливает закономерность – с ростом дохода доля расходов на продовольствие - уменьшается. Здесь у, обозначает - долю расходов на непродовольственные товары; х – доходы.
Первая группа нелинейных функций легко может быть линеаризована (приведены к линейному виду). Например, для полинома к-го порядка
получим линейную модель вида
Аналогично могут быть линеаризованы и другие виды нелинейных функций 1-й группы, производя соответствующие замены.
Для оценки параметров нелинейных функций первой группы можно использовать, обычный МНК, аналогично, как и в случае линейных функций.
Иначе обстоит дело с группой регрессионных, нелинейных функций по оцениваемым параметрам. Данную группу функций можно разбить на две подгруппы: нелинейные модели внутренне линейные и нелинейные модели внутренне нелинейные.
Рассмотрим степенную функцию
Следовательно, ее параметры могут быть найдены обычным МНК.
Если модель представить в виде:
, то модель становится внутренне нелинейной, т.к. ее невозможно преобразовать в линейный вид.
Внутренне нелинейной будет и модель вида
В эконометрических исследованиях, часто к нелинейным относят модели, только внутренне нелинейные по оцениваемым параметрам, а все другие модели, которые легко преобразуются в линейный вид, относятся к группе линейных моделей. Например, к линейным относят модель:
Если, модель внутренне нелинейна по параметрам, то для оценки параметров используются итеративные методы, успешность которых зависит от вида функции и особенностей применяемого итеративного подхода.
МНК в случае нелинейных функций, рассмотрим на примере оценки параметров степенной функции
Прологарифмировав данную функцию, получим:
Применив МНК к полученному уравнению:
, илиПараметр b определяется непосредственно из системы, а параметр а – косвенным путем:
Оценка корреляции для нелинейной регрессии
Оценка тесноты корреляционной зависимости в случае нелинейной регрессии производится с помощью индекса корреляции (
R):
где
Величина данного показателя находится в границах:
Следует помнить, что если для линейной зависимости имеет место равенство:
Оценка существенности индекса корреляции проводится, так же как и оценка надежности коэффициента корреляции. Индекс детерминации используется для проверки существенности в целом уравнения нелинейной регрессии по F-критерию Фишера:
,где R2 - индекс детерминации;
n - число наблюдений;
m - число параметров при переменных х.
Индекс детерминации
Если величина
,где
,Если
Фактические значения результативного признака отличаются от теоретических, рассчитанных по уравнению регрессии, т.е.
Существует и другая формула определения средней ошибки аппроксимации:
, где Ошибка аппроксимации в пределах 5-7% свидетельствует о хорошем подборе модели к исходным данным.
Возможность построения нелинейных моделей, как с помощью их приведения к линейному виду, так и путем использования нелинейной регрессии, значительно повышает универсальность регрессионного анализа, но и усложняет задачу исследователя.
Возникает вопрос: с чего начать - с линейной зависимости или с нелинейной, и если с последней, то, какого типа.
Если ограничиться парной регрессией, то можно построить график наблюдений у и х и принять решение. Однако очень часто несколько разных нелинейных функций приблизительно соответствуют наблюдениям, если они лежат на некоторой кривой. А в случае множественной регрессии невозможно даже построить график.
При рассмотрении альтернативных моделей с одним и тем же определением зависимой переменной процедура выбора достаточно проста. Наиболее разумным является оценивание регрессии на основе всех вероятных функций, и выбор функции, в наибольшей степени объясняющей изменения зависимой переменной. Если для одной модели коэффициент R2 значительно больше, чем для другой, то вы сможете сделать оправданный выбор без особых раздумий, однако, если значения R2 для двух моделей приблизительно равны, то проблема выбора существенно усложняется.
В этом случае следует использовать стандартную процедуру, известную под названием теста Бокса – Кокса.
Если необходимо сравнить модели с использованием у и lny в качестве зависимой переменной, то можно использовать вариант теста, разработанный Полом Зарембкой. Процедура включает следующие шаги:
1) Вычисляется среднее геометрическое значений у в выборке, (оно совпадает с экспонентой среднего арифметического lny):
2) Пересчитываются наблюдения у, т.е. они делятся на это значение, то есть
3) Оценивается регрессия для линейной модели с использованием у*i вместе yi и для логарифмической модели с использованием ln(y*i) вместо ln(yi). Теперь значения суммы квадратов отклонений для двух регрессий сравнимы, и, следовательно, модель с меньшей суммой квадратов отклонений обеспечивает лучшее соответствие.