Файл: Практическая работа 8 Машинное обучение. Knearest Neighbors.docx
ВУЗ: Не указан
Категория: Не указан
Дисциплина: Не указана
Добавлен: 09.01.2024
Просмотров: 27
Скачиваний: 1
ВНИМАНИЕ! Если данный файл нарушает Ваши авторские права, то обязательно сообщите нам.
Практическая работа №8
Машинное обучение. K-Nearest Neighbors
Цель работы: загрузить набор данных клиентов, подогнать данные и использовать K-Nearest Neighbors для прогнозирования точки данных.
Теоретические сведения
K-Nearest Neighbors - это алгоритм для контролируемого обучения. В нем данные "обучаются" с помощью точек данных, соответствующих их классификации. Когда точка должна быть предсказана, для определения ее классификации учитываются "K" ближайших к ней точек.
Визуализация алгоритма K-Nearest Neighbors.
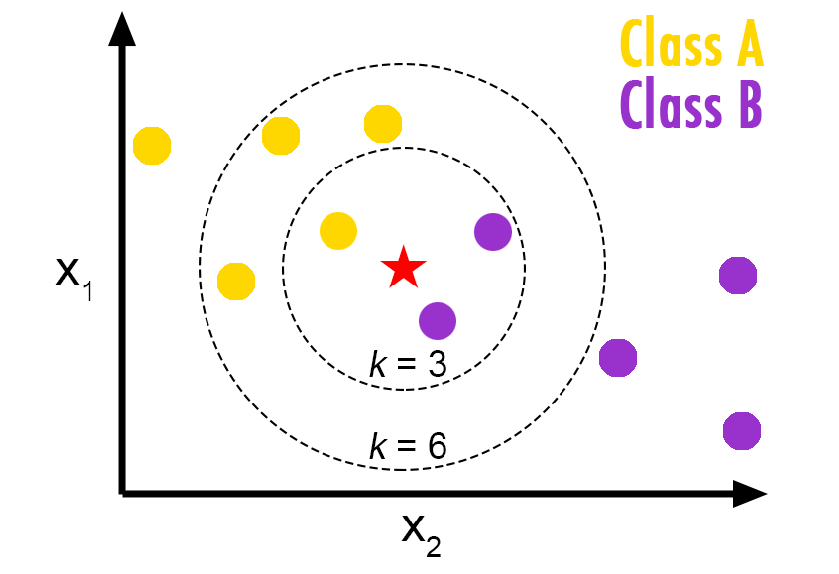
В данном случае у нас есть точки данных класса А и В. Мы хотим предсказать, что представляет собой звезда (тестовая точка данных). Если мы рассмотрим значение k, равное 3 (3 ближайшие точки данных), мы получим прогноз класса B. Если же мы рассмотрим значение k, равное 6, мы получим прогноз класса A.
Представьте себе, что поставщик телекоммуникационных услуг сегментировал свою клиентскую базу по шаблонам использования услуг, разделив клиентов на четыре группы. Если демографические данные можно использовать для прогнозирования членства в группе, компания может настроить предложения для отдельных потенциальных клиентов. Это проблема классификации. То есть, учитывая набор данных с предопределенными метками, нам нужно построить модель, которая будет использоваться для прогнозирования класса нового или неизвестного случая. В примере основное внимание уделяется использованию демографических данных, таких как регион, возраст и брак, для прогнозирования моделей использования. Целевое поле, называемое custcat, имеет четыре возможных значения, которые соответствуют четырем группам клиентов, а именно: 1 — базовая услуга 2 — электронная услуга 3 —дополнительная услуга 4 — общая услуга. Наша цель — построить классификатор, чтобы предсказать класс неизвестных случаев. Мы будем использовать особый тип классификации, называемый K ближайшим соседом.
Стандартизация данных дает данным нулевое среднее и единичную дисперсию, это хорошая практика, особенно для таких алгоритмов, как KNN, который основан на расстоянии между случаями.
Точность вне выборки - это процент правильных прогнозов, которые модель обеспечивает на данных, которые НЕ использовались для обучения модели. Выполнение обучения и тестирования на одном и том же наборе данных, скорее всего, будет иметь низкую точность вне выборки из-за вероятности избыточного соответствия.
Важно, чтобы модель имела высокую вневыборочную точность, потому что цель любой модели, конечно, состоит в том, чтобы делать правильные прогнозы на неизвестных данных.Один из способов улучшить точность вне выборки — использовать подход к оценке под названием Train/Test Split. Train/Test Split включает в себя разделение набора данных на наборы для обучения и тестирования соответственно, которые являются взаимоисключающими. После этого вы тренируетесь с тренировочным набором и тестируете с помощью тестового набора.
Это обеспечит более точную оценку точности вне выборки, поскольку набор данных тестирования не является частью набора данных, который использовался для обучения данных.
В многометочной классификации показатель точности классификации - это функция, которая вычисляет точность подмножества. Эта функция равна функции jaccard_similarity_score. По сути, она вычисляет, насколько близко совпадают фактические и предсказанные метки в тестовом наборе.
Ход работы
1. Загрузить библиотеки
2. Загрузить данные из CSV файла
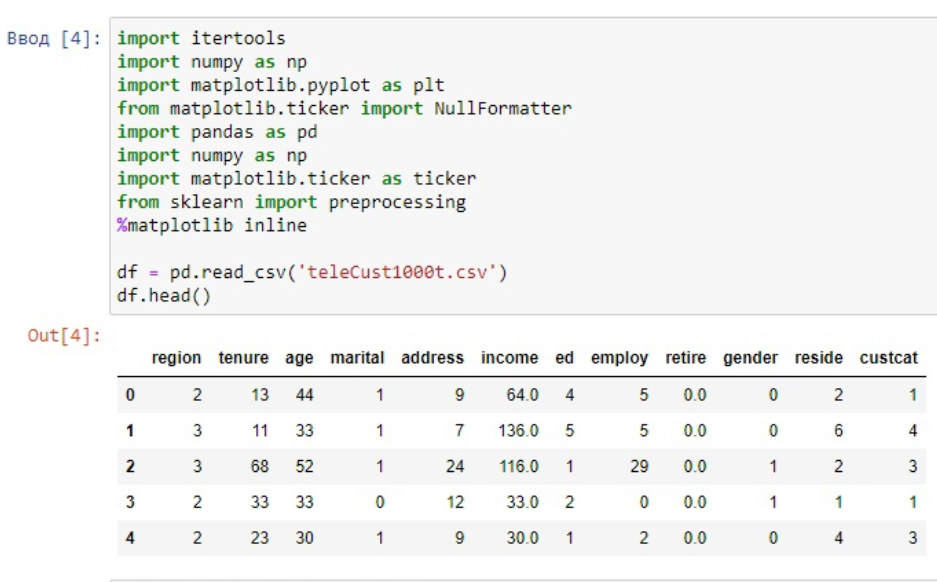
Рисунок 1 - импортирование библиотек и выгрузка данных из файла
3. Вывести количество представителей классов: "Плюс Сервис"," Базового Сервиса","Тотал сервиса","E-Сервиса"
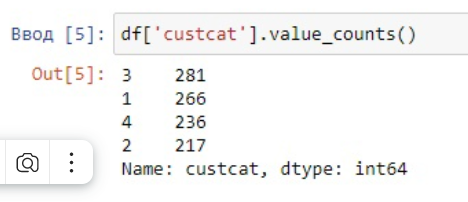
Рисунок 2 - Количество представителей классов
4. Визуализировать данные
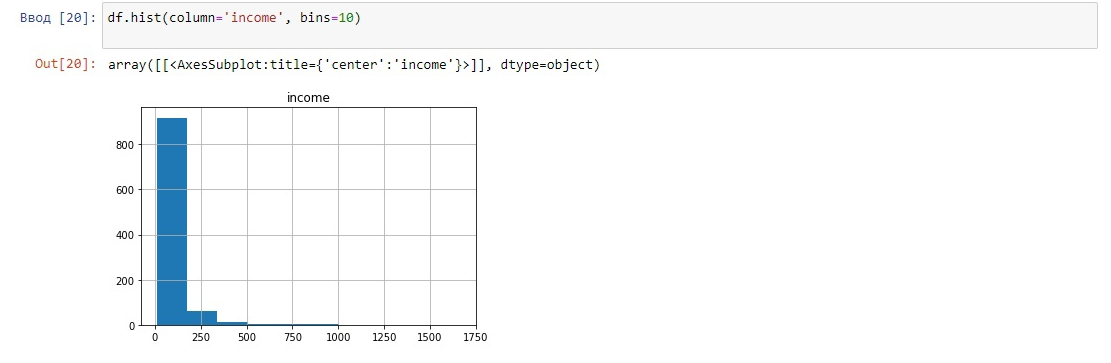
Рисунок 3 - График доходов
5. Определить наборы характеристик по X
6. Чтобы использовать библиотеку scikit-learn преобразовать кадр данных Pandas в массив Numpy
7. Вывести ярлыки данных
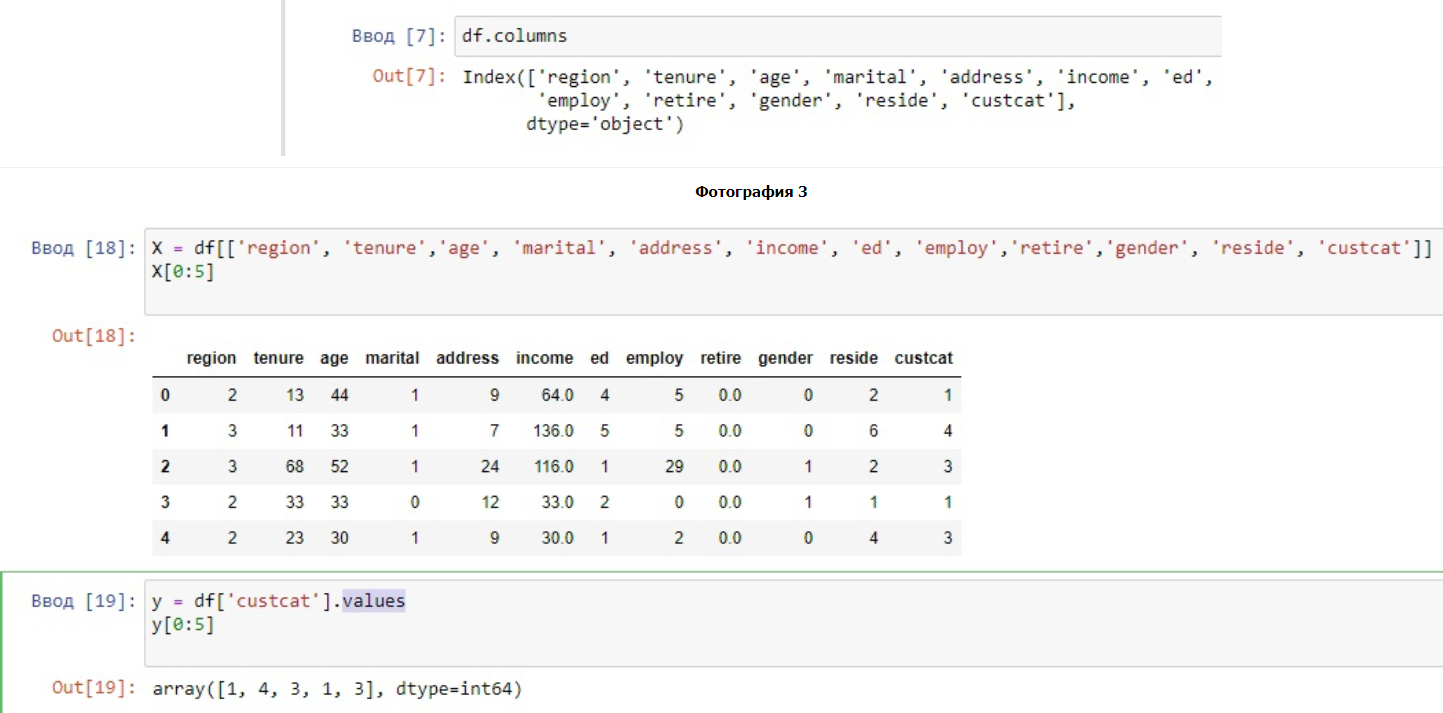
Рисунок 4 - Определение данных по X, их преобразование, нахождение ярлыков
8. Стандартизировать данные
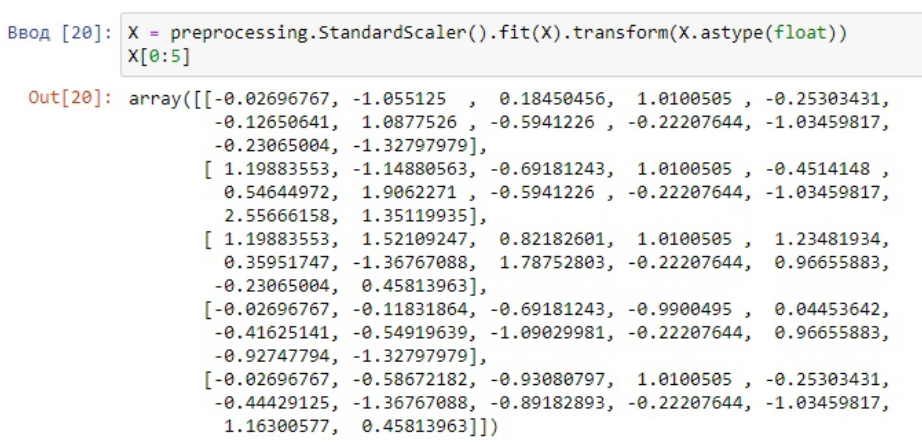
Рисунок 5 - Стандартизация данных
9. Разделить данные на наборы для обучения и тестирования
10. Запустить алгоритм для четырех ближайших точек
11. Использовать модель для прогнозирования ближайшего набор
12. Вывести показатель точности классификации
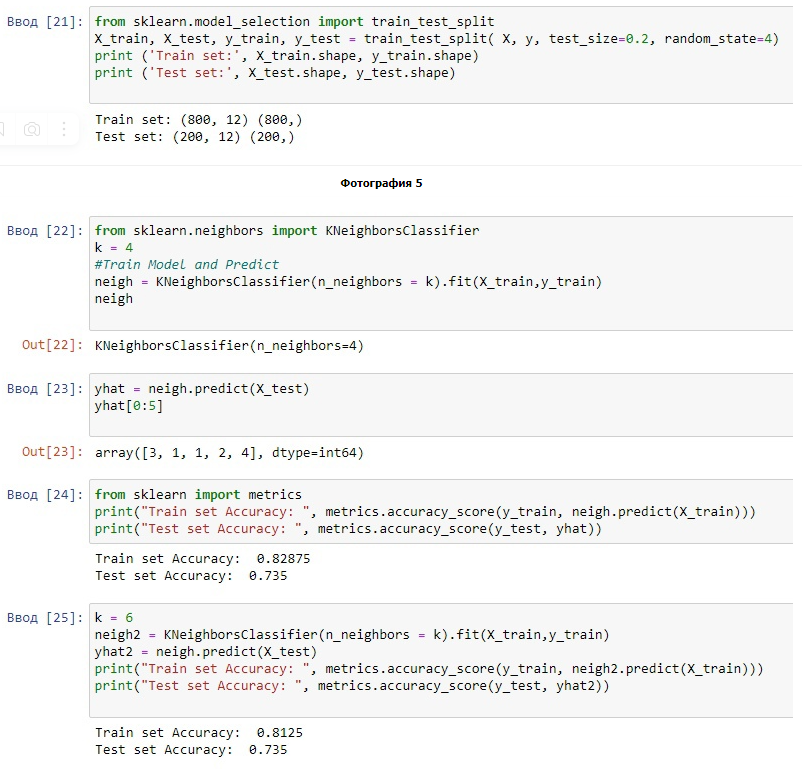
Рисунок 6 - Результат работы алгоритма для 8 ближайших точек
13. Рассчитать точность KNN для различных K и вывести лучший результат
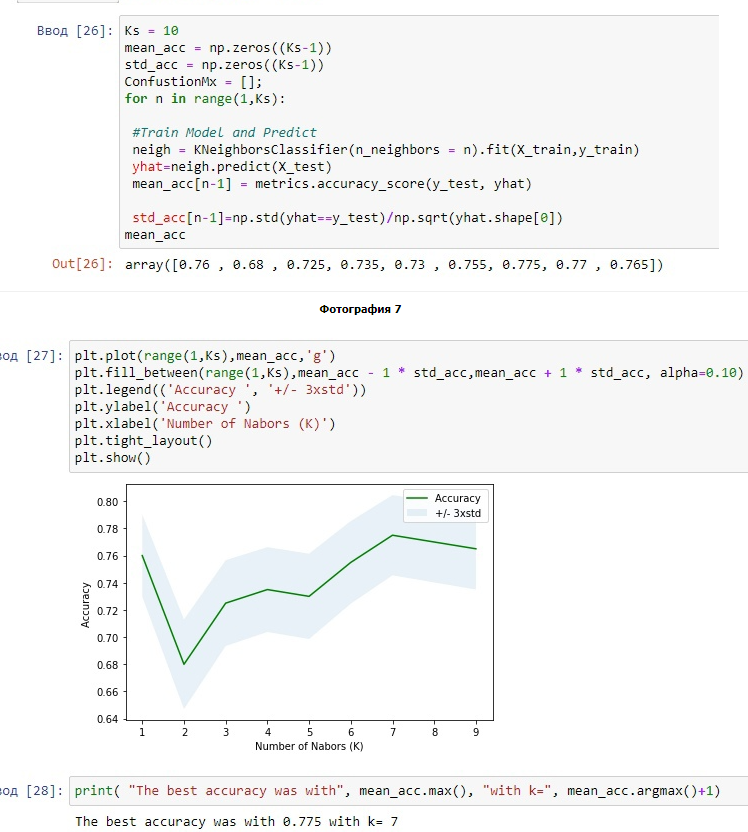
Рисунок 7 - Нахождение лучшего результата k в данной выборке
Заключение
Изучили метод K-Nearest Neighbors для прогнозирования точки данных и нашли лучшую k в выборке.
| ФИО преподавателя | Подпись | Дата |
| Гладких С.А | | |
| ФИО студентов | ||
| Щербаков А.А |