ВУЗ: Не указан
Категория: Не указан
Дисциплина: Не указана
Добавлен: 11.01.2024
Просмотров: 70
Скачиваний: 1
ВНИМАНИЕ! Если данный файл нарушает Ваши авторские права, то обязательно сообщите нам.
Последним этапом проектирования является проектирование физической модели. С появлением персональных компьютеров этот этап фактически перестал существовать, так как операционная система, СУБД автоматически проектирует физическую среду хранения информации.
Пример 1.2. Для примера 1.1. нормализовать структуру баз данных.
В процессе ввода данных о студентах ВУЗа можно сделать вывод, что вводится избыточная информация. Так в каждой записи студентов одной группы мы вводим название специальности и факультета, что во-первых требует дополнительных ресурсов вычислительной системы, а во-вторых позволяет ввести неверную информацию о студентах, т.е. студентам одной группы ввести различные специальности. Для этих целей после первичного построения инфологической модели проводится анализ и выявление вспомогательных сущностей. В данном примере ею может являться академическая группа. К характеристикам группы можно отнести следующие:
- номер группы;
- специальность;
- факультет;
- ФИО старосты.
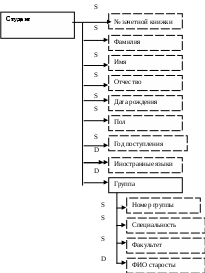
В общем виде в инфологической модели (рис.1.2) сущность группа будет атрибутом сущности студент.
На рис.1.3. представлена полученная инфологическая модель
Р
 ис. 1.3. Инфологическая модель.
ис. 1.3. Инфологическая модель.На основе полученной инфологической модели построим схему данных (даталогическую модель данных). Она представлена в двух таблицах (для каждой сущности) 1.2.,1.3.
Таблица 1.2.
Схема данных для хранения информации о студентах ВУЗа
| № | Наименование | Назначение | Тип | Размерность |
| 1 | N_Zac | Номер зачетной книжки | Символьный | 6 |
| 2 | Fam | Фамилия | Символьный | 25 |
| 3 | Im | Имя | Символьный | 25 |
| 4 | Otc | Отчество | Символьный | 25 |
| 5 | D_R | Дата рождения | Дата | 8 |
| 6 | Pol | Пол | Логический | 1 |
| 7 | Year_P | Год поступления | Числовой | |
| 8 | In_s | Иностранные языки | Символьный | 25 |
| 9 | N_Gr | Номер группы | Символьный | 4 |
Таблица 1.3.
Схема данных для хранения информации об академических группах
| № | Наименование | Назначение | Тип | Размерность |
| 1 | N_Gr | Номер группы | Символьный | 4 |
| 2 | Spec | Специальность | Символьный | 45 |
| 3 | F_tet | Факультет | Символьный | 8 |
| 4 | Fam_S | ФИО старосты | Символьный | 30 |
Контрольные вопросы
-
В чем заключается этап инфологического моделирования? -
Какие основные конструктивные элементы используются при проектировании инфологической модели? -
Что является идентификатором и ключом? -
В чем заключается даталогическое проектирование? -
Вследствие каких процессов физическое проектирование баз данных утратило свое значение?
1.3. Задание к лабораторной работе №1
-
Изучить и выписать основные положения проектирования баз данных. -
Проектировать базу данных. Варианты заданий приведены в таблице 1.4.
Таблица 1.4.
Таблица вариантов задания к лабораторной работе №1
| № варианта | Предметная область | Пояснения |
| 1 | БД жильцов в доме. | |
| 2 | БД аудиторий в ДГТУ. | |
| 3 | БД больных в больнице. | |
| 4 | БД городских телефонных номеров. | |
| 5 | БД автотранспортных средств. | |
| 6 | БД сотрудников ВУЗа. | |
| 7 | БД налогоплательщиков. | |
| 8 | БД предприятий г. Махачкала. | |
| 9 | БД картотека уголовных преступлений. | |
| 10 | БД лиц, находящихся на учете в МВД. | |
ЛАБОРАТОРНАЯ РАБОТА № 2
Тема: “Ознакомление с Borland C++ Builder. Инструмент Database Desktop. Создание и заполнение баз данных”
2.1 Основные понятия баз данных
База данных — это прежде всего набор таблиц. Таблицу можно представлять себе как обычную двумерную таблицу с характеристиками (атрибутами) какого-то множества объектов. Таблица имеет имя — идентификатор, по которому на нее можно сослаться. Столбцы таблицы соответствуют тем или иным характеристикам объектов - полям. Каждое поле характеризуется именем и типом хранящихся данных. Имя поля — это идентификатор, который используется в различных программах для манипуляции данными. Он строится по тем же правилам, как любой идентификатор, т.е. пишется латинскими буквами, состоит из одного слова и т.д. Таким образом имя — это не то, что отображается на экране или в отчете в заголовке столбца (это отображение, естествено, писать по-русски), а идентификатор, соответствующий этому заголовку. Тип поля характеризует тип хранящихся в поле данных. Это могут быть строки, числа, булевы значения, большие тексты (например, характеристики сотрудников), изображения (фотографии сотрудников) и т.п.
Каждая строка таблицы соответствует одному из объектов. Она называется записью и содержит значения всех полей, характеризующих данный объект. При построении таблиц баз данных важно обеспечивать непротиворечивость информации. Обычно это делается введением ключевых полей — обеспечивающих уникальность каждой записи. Ключевым может быть одно или несколько полей. При работе с таблицей пользователь или программа как бы скользит курсором по записям. В каждый момент времени есть некоторая текущая запись, с которой и ведется работа. Записи в таблице базы данных физически могут располагаться без какого-либо порядка, просто в последовательности их ввода. Но когда данные таблицы предъявляются пользователю, они должны быть упорядочены. Пользователь может хотеть просматривать их в алфавитном порядке, или рассортированными по отделам, или по мере нарастания года рождения и т.п. Для упорядочивания данных используется понятие индекса. Индекс показывает, в какой последовательности желательно просматривать таблицу. Курсор скользит по индексу, а индекс указывает на ту или иную запись таблицы. Для пользователя таблица выглядит упорядоченной, причем он может сменить индекс и последовательность просматриваемых записей изменится. Но в действительности это не связано с какой-то перестройкой самой таблицы и с физическим перемещением в ней записей. Меняется только индекс, т.е. последовательность ссылок на записи.
Индексы могут быть первичными и вторичными. Например, первичным индексом могут служить поля, отмеченные при создании базы данных как ключевые. А вторичные индексы могут создаваться из других полей как в процессе создания самой базы данных, так и позднее в процессе работы с ней. Вторичным индексам присваиваются имена — идентификаторы, по которым их можно использовать.
Если индекс включает в себя несколько полей, то упорядочивание базы данных сначала осуществляется по первому полю, а для записей, имеющих одинаковые значения первого поля — по второму и т.д. Например, базу данных персонала можно индексировать по отделам, а внутри каждого отдела — по алфавиту. База данных обычно содержит не одну, а множество таблиц. Например, база данных о некоторой организации может содержать таблицу имеющихся в ней подразделений с характеристикой каждого из них.
2.2 Типы баз данных
Для разных задач целесообразно использовать различные модели баз данных, поскольку, конечно, базу данных сведений о сотрудниках какого-то небольшого коллектива и базу данных о каком-нибудь банке, имеющем филиалы во всех концах страны, надо строить по-разному.
Процесс определения того, какая база данных более подходит для конкретного приложения, называется масштабированием. Это сложная задача, которую мы не будем затрагивать. Однако, прежде, чем двигаться дальше, необходимо иметь представление о возможных моделях баз данных, поскольку это влияет на построение приложений в Borland C++Builder.
Рассмотрим коротко следующие четыре модели баз данных:
• Автономные;
• С разделяемыми файлами;
• Клиент/сервер;
• Многоярусные.
Автономные базы данных являются наиболее простыми. Они хранят свои данные в локальной файловой системе на том компьютере, на котором установлены; система управления и машина базы данных, осуществляющая к ним доступ, находятся на том же самом компьютере. Сеть не используется. Поэтому разработчику автономной базы данных не приходится иметь дело с проблемой параллельного доступа, когда два человека пытаются одновременно изменить одну и ту же запись, потому что такого никогда не может быть. Вообще, автономные базы данных не используются для приложений, требующих значительной вычислительной мощности, потому что процессорное время будет потрачено на выполнение манипуляций с данными и в целом будет потеряно для приложения.