ВУЗ: Не указан
Категория: Не указан
Дисциплина: Не указана
Добавлен: 11.01.2024
Просмотров: 72
Скачиваний: 1
ВНИМАНИЕ! Если данный файл нарушает Ваши авторские права, то обязательно сообщите нам.
Автономные базы данных полезны для развития тех приложений, которые распространены среди многих пользователей, каждый из которых поддерживает отдельную базу данных. Это, например, приложения, обрабатывающие документацию небольшого офиса, кадровый состав небольшого предприятия, бухгалтерские документы небольшой бухгалтерии. Каждый пользователь такого приложения манипулирует своими собственными данными на своем компьютере. Пользователю нет необходимости иметь доступ к данным любого другого пользователя, так что отдельная база данных здесь вполне приемлема.
Базы данных с разделяемыми файлами отличаются от автономных баз данных, только тем, что они могут быть доступны многим клиентам через сеть. Это очень удобно, так как изменения в таких базах данных видят все пользователи. Например, базу данных сотрудников крупного учреждения целесообразно делать именно такой, чтобы администраторы отдельных подразделений обращались к ней, а не заводили у себя локальные базы данных (позднее будет показано, как сделать, чтобы сохранялась конфиденциальность информации и чтобы каждый администратор видел только ту информацию, которая относится к его подразделению).
Для больших баз данных с множеством пользователей часто используются базы данных на платформе клиент/сервер. В этом случае доступ к базе данных для группы клиентов выполняется специальным компьютером — сервером. Клиент дает задание серверу выполнить те или иные операции поиска или обновления базы данных. И мощный сервер, ориентированный на операции с запросами самым оптимальным способом, выполняет их и сообщает клиенту результаты своей работы. При таком подходе возникает дополнительная проблема — спроектировать приложение так, чтобы оно максимально использовало возможности сервера и минимально нагружало сеть, передавая через нее только минимум информации.
Многоярусные базы данных. Это новый и многообещающий путь обработки данных в сети. Наиболее распространен трехярусный вариант:
• На нижнем уровне на компьютерах пользователя расположены приложения клиентов, обеспечивающие пользовательский интерфейс.
• На втором уровне расположен сервер приложений, обеспечивающий обмен данными между пользователями и распределенными базами данных. Сервер приложений размещается в узле сети, доступном всем клиентам.
• На третьем уровне расположен удаленный сервер баз данных, принимающий информацию от серверов приложений и управляющий ими.
Подобную концепцию обработки данных пропагандируют, в частности, фирмы Oracle и Sun. Первый, элементарный уровень состоит из «тонких клиентов», то есть несложных терминалов, предназначенных, в основном, для ввода — вывода. Второй, средний (middleware) уровень — это рабочие станции и серверы приложений, то есть значительно более серьезные машины, на которых выполняются программы, критичные к загрузке процессора. Третий и последний уровень — мощные специализированные серверы баз данных.
2.2. Создание базы данных с помощью Database Desktop
Прежде, чем начать строить приложения, работающие с базами данных, надо иметь сами базы данных. Вместе с BDE и Borland C++Builder поставляется программа Database Desktop (файл DBD.EXE для 16-разрядных приложений, файл DBD32.EXE для 32-разрядных приложений, файл DBDLOCAL.EXE — файл конфигурирования), которая позволяет создавать таблицы баз данных некоторых СУБД, задавать и изменять их структуру.
Обычно вызов Database Desktop включен в главное меню Borland C++Builder в раздел Tools. Если это не сделано, то полезно включить его туда с помощью команды Tools | Configure Tools.... Вызовите Database Desktop. Вы увидите окно, показанное на рис. 2.1 (если в предыдущем сеансе работы с Database Desktop не была открыта какая-то таблица, то таблицы в середине окна не будет видно и разделов меню будет поменьше).
Рис.2.1. Вид Database Desktop
Давайте создадим с помощью Database Desktop таблицу базы данных СУБД Paradox v.7. В Paradox v.7 база данных — это каталог, в котором лежат таблицы — файлы с расширением .db. Поэтому прежде надо создать соответствующий каталог с помощью любой программы Windows, например, с помощью «Проводника». Далее выполните команду Database Desktop File | New- Вам откроется подменю, содержащее три варианта.
Выберите Table. Вам откроется небольшое диалоговое окно, в нем из выпадающего списка вы можете выбрать СУБД, для которой хотите создать таблицу. Выберите Paradox. Вы увидите окно, представленное на рис. 2.2. В этом окне вы можете задать структуру таблицы (поля и их типы), создать вторичные индексы, ввести диапазоны допустимых значений полей, значения по умолчанию и ввести много иной полезной информации о создаваемой таблице.
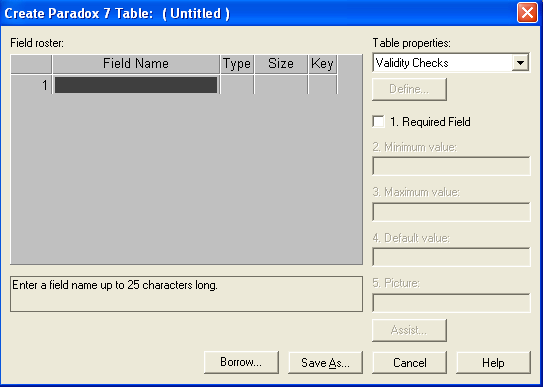
Рис.2.2. Окно создания таблицы.
Для каждого поля создаваемой таблицы прежде всего указывается имя (Field Name) — идентификатор поля. Он может включать до 25 символов и не может начинаться с пробела (но внутри пробелы допускаются). Затем надо выбрать тип (Type) данных этого поля. Для этого перейдите в раздел Type поля и щелкните правой кнопкой мыши. Появится список доступных типов, из которого вы можете выбрать необходимый вам. Приведем пояснения типов данных, используемых в Paradox.
Таблица 2.1
| Обозначение | Размер | Обозначение в списке | Пояснение |
| 1 | 2 | 3 | 4 |
| А | 1-255 | Alpha | Строковое поле, содержащее любые печатаемые символы ASCII. Размер число символов |
| N | | Number | Действительные числа от -10 307-10308с 15 значащими разрядами. |
| $ | | Money | Положительные или отрицательные числа, отличающиеся от Number формой представления |
| S | | Short | Короткие числа -32767 до 32767 |
| I | | Long Integer | Длинные числа от -2 147 483 648 до 2 147 483 647 |
| 1 | 2 | 3 | 4 |
| # | 0-32 | BCD | Числа в формате BCD Binary Coded Decimal, вычисления проводятся с большей точностью. |
| D | | Date | Значения представления даты |
| T | | Time | Значения представления времени |
| @ | | Timestamp | Значения, хранящие и дату и время |
| M | 1-240 | Memo | Поля для хранения текстов неограниченной длины. Тексты хранятся в отдельных файлах .mb |
| F | 0-240 | Formatted Memo | Поля для хранения форматированных текстов неограниченной длины. Тексты хранятся в отдельных файлах .mb |
| G | | Graphic | Изображение из файлов в форматах .bmp, .pcx, .tif, gif, .eps. Database Desktop преобразует их в формат .bmp. |
| O | | OLE | Данные типа OLE – изображения, звуки, документы. Database Desktop не поддерживает поля этого типа. |
| L | | Logical | Логические поля – true, false |
| + | | Autoincrement | Автоматическое увеличение на 1. |
| B | | Binary | Данные хранящиеся в отдельных двоичных файлах .mb. Database Desktop не поддерживает поля этого типа |
| Y | 1-255 | Bytes | Database Desktop не поддерживает поля этого типа. |
Для базы данных хранящей информацию о сотрудниках предприятия структура таблица представлена на рис.2.3.
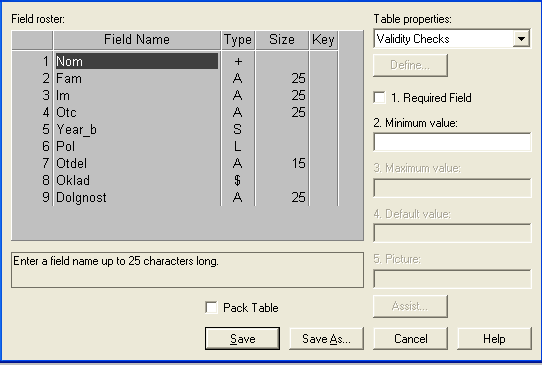
Рис.2.3. Структура таблицы данных Kadr.db
-
Задание свойств таблицы
Теперь обратите внимание на правую часть окна (рис. 2.3). В нем задаются свойства таблицы (Table properties). Вверху имеется выпадающий список с рядом разделов.
Validity Checks — проверка правильности значений
Начнем с первого из них: Validity Checks — проверка правильности значений. Вы можете задать следующие характеристики поля: - поля с обязательным заполнением, минимальное значение, максимальное значение, значение по умолчанию, шаблон данных.
Table Lookup — таблица просмотра
Следующий раздел в выпадающем списке свойств таблицы в правом верхнем углу экрана на рис. 2.3: Table Lookup — таблица просмотра. Этот раздел позволяет связать с полем данной таблицы какое-то поле другой, просматриваемой таблицы, из которой будут браться интересующие нас значения. При выборе Table Lookup на экране появляется кнопка Define — определить. При ее нажатии открывается диалоговое окно. В нем вы можете для данного поля задать таблицу просмотра (Lookup table). При этом вы можете воспользоваться выпадающим списком драйверов или псевдонимов (Drive or Alias) и кнопкой просмотра (Browse...). А затем кнопкой со стрелкой занести поле просматриваемой таблицы, из которого будут браться данные.
Secondary Indexes — вторичные индексы
Следующий раздел в выпадающем списке свойств таблицы: Secondary Indexes — вторичные индексы. Этот раздел позволяет создавать необходимые для дальнейшей работы вторичные индексы (первичный индекс создается по ключевым полям).
Чтобы создать новый вторичный индекс, нажмите кнопку Define — определить. В его левом окне Fields содержится список доступных полей, в правом окне Indexed fields вы можете подобрать и упорядочить список полей, включаемых в индекс. Для переноса поля из левого окна в правое надо выделить интересующее вас поле или группу полей и нажать кнопку со стрелкой вправо. Стрелками Change order (изменить последовательность) можно изменить порядок следования полей в индексе.
Referential Integrity — целостность на уровне ссылок
Речь идет о способах, позволяющих обеспечить постоянные связи между данными отдельных таблиц. Если устанавливается целостность на уровне ссылок между двумя таблицами, одна из которых — головная (родительская), а другая — вспомогательная (дочерняя), то во вспомогательной таблице указывается поле (или группа полей), которые могут брать свои значения только из ключевого поля (или полей) головной таблицы.