ВУЗ: Алтайский Государственный Университет
Категория: Учебное пособие
Дисциплина: Управление проектами
Добавлен: 23.10.2018
Просмотров: 3668
Скачиваний: 14
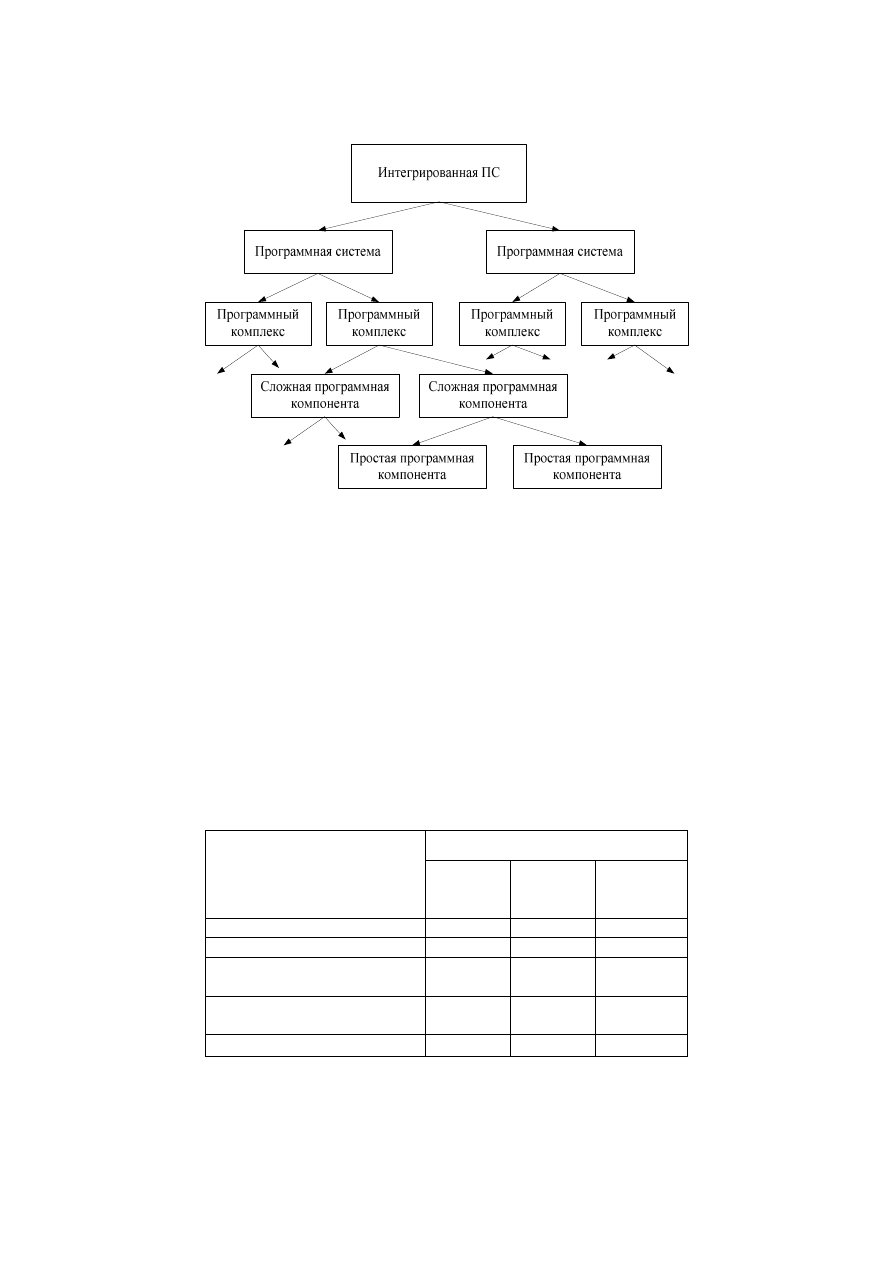
6
− программная компонента – совокупность программных кодов, реализующих элементарную
функцию бизнес-процесса.
Рис. 2.1. Структура программной системы
Размеры программной системы определяются в виде количества строк исходного кода в терми-
нах Lines of code-LOC [2].
При оценке количества строк исходного кода следует учитывать следующие положения:
−
строка исходного кода содержит только один оператор;
−
определение (описание) исходных данных учитывается один раз;
−
не учитываются строки, содержащие комментарии и отладочные операторы;
−
учитывается каждая инициализация, вызов, либо включение макроса в качестве исходного
кода.
Каждый из экспертов должен дать оптимистическую (о), пессимистическую (p) и реалистиче-
скую (b) оценки (табл. 2.1).
Средняя оценка по бета-распределению определяется путем умножения реалистической оценки
на 4, добавлением оптимистической и пессимистической оценок и делением полученного результата
на 6 (формула 2.1).
Таблица 2.1
Бланк экспертного оценивания размерности программной
системы
Оценки
Состав программной
системы
Оптими-
стическая
Реали-
стиче-
ская
Пессими-
стическая
1. Программная система
1.1. Программный комплекс
1.1.1. Программная компо-
нента 1
1.1.2. Программная компо-
нента 2
……………………
6
/
)
4
(
ij
p
ij
b
ij
o
ij
k
r
+
+
=
(2.1)
После оценивания всех компонент на каждом уровне, начиная с нижнего, происходит суммиро-
вание результатов измерения по принципу «снизу -вверх».

7
∑
∑
∑
=
=
=
=
i
m
j
j
i
k
n
i
q
k
q
r
R
1
1
1
/
, (2.2)
где
q
-
количество экспертов,
i
m
-
количество программных компонент на i -ом уровне,
n
-
число уровней.
Очевидно, что эффективность оценивания может быть существенно повышена при наличии про-
тотипов будущей программной системы. В этом случае эксперту предлагается оценить необходи-
мость степени модернизации имеющегося прототипа, увеличив, либо сократив исходный размер про-
граммной компоненты на некоторое количество строк.
Определение трудозатрат, длительности реализации проекта и средней численности
разработчиков
Оценка трудозатрат, длительности и средней численности разработчиков при реализации проек-
та основывается на согласовании между разработчиком и заказчиком производительности труда про-
граммиста - P.
В [4] приводятся следующие среднестатистические оценки производительности труда програм-
миста:
−
при разработке программных систем первого класса сложности (КПС) преимущественно на
языке ассемблер – 60-80 строк/чел.-месяц;
−
при разработке программных систем второго класса сложности (ИСС) на языках высокого
уровня – 250-260 строк/чел.-месяц.
В таблице 2.2. представлены статистические показатели производительности, рекомендуемые в
базовой модели Constructive Cost Model [2].
CO
nstructive COst MOdel (COCOMO – модель издержек разработки) – это алгоритмическая мо-
дель оценки стоимости разработки программного обеспечения, разработанная Барри Боэмом (Barry
Boehm). Модель использует простую формулу регрессии с параметрами, определенными из данных,
собранных по ряду проектов.
COCOMO была впервые опубликована в 1981 году в книге Боэма «Экономика разработки про-
граммного обеспечения» в качестве модели для оценки трудоемкости, себестоимости и плана-
графика для проектов по разработке ПО.
Она использовала исследование 63 проектов в аэрокосмической компании TRW, в которой Боэм
был директором отдела исследований программного обеспечения и технологий.
В исследовании проекты классифицировались по размеру в зависимости от количества строк ко-
да (от 2 до 100 тысяч), а также по языку программирования (от ассемблеров до высокоуровневого
языка PL/1).
В 1997 году была разработана модель COCOMO II, которая стала наследником первоначальной
модели и более подходящей для оценивания современных проектов разработки ПО. Она предостав-
ляет более полную поддержку современных процессов разработки ПО и построена на обновленной
базе проектов.
В целом, COCOMO состоит из иерархии трех последовательно детализируемых и уточняемых
форм.
Первый уровень – Базовый, хорош для быстрых ранних оценок стоимости разработки ПО, одна-
ко не принимает во внимание различия в аппаратных ограничениях, качестве и опыте персонала, а
также использованию современных техник и средств разработки и других факторов, которые невоз-
можно учесть на ранних стадиях разработки.
Средний уровень COCOMO учитывает эти факторы, тогда как Детальный уровень дополни-
тельно учитывает влияние отдельных фаз проекта на его общую стоимость.
Средний уровень (COCOMO Model 2: Intermediate) – рассчитывает трудоемкость разработки как
функцию от размера программы и множества «факторов стоимости», включающих субъективные
оценки характеристик продукта, проекта, персонала и аппаратного обеспечения. Детальный уровень
(COCOMO Model 3: Advanced/Detailed) – включает в себя все характеристики среднего уровня с
оценкой влияния данных характеристик на каждый этап процесса разработки ПО.
Приведенные ниже нормативы отражают не только трудоемкость непосредственного написания
текстов программ, но и процессы комплексирования и испытания всего программного комплекса. С
учетом вышеизложенного, трудозатраты на разработку системы могут быть определены следующим
образом:

8
P
R
Т
/
=
(2.3)
Таблица 2.2
Нормативы трудоемкости разработки программ
Класс сложности
ПС
Размеры и трудоёмкость создания ПС
простые – до 30
тыс. строк
сложные – до 500
тыс. строк
Первый тип – КПС
до 140 строк/чел.-
месяц
до 80 строк/чел.-
месяц
Второй тип – ИСС
до 220 строк/чел.-
месяц
до 160 строк/чел.-
месяц
Длительность разработки (Д) может быть задана директивно заказчиком, исходя из реальных по-
требностей его бизнеса и наличия финансовых ресурсов. В этом случае средняя численность специа-
листов, которые должны быть привлечены к реализации программной системы определяется по фор-
муле:
Д
/
T
Z
=
(2.4)
Прямой метод целесообразно использовать на ранних стадиях проектирования при разработке
концепции и технического задания на будущую программную систему. Это позволит разработчику и
заказчику определить трудоемкость реализации каждого бизнес-процесса, проранжировать их в соот-
ветствии с пожеланиями заказчика, соизмерить финансовые возможности заказчика и сроки реализа-
ции проекта.
2.3.2.
Определение технико-экономических показателей программной системы с исполь-
зованием метода функциональных точек
Метод функциональных точек
(Function point – FP) основывается на том, что размеры про-
граммной системы оцениваются в терминах количества и сложности бизнес-процессов (функций),
реализуемых в данном программном коде [2].
Функциональная точка
– это комбинация свойств программного обеспечения:
−
интенсивности использования ввода и вывода внешних данных;
−
взаимодействия системы с пользователем;
−
внешних интерфейсов;
−
файлов, используемых системой.
Будущая система с использованием методологии структурного анализа и проектирования опи-
сывается в виде многоуровневой графической модели, представленной в виде совокупности взаимо-
связанных функциональных диаграмм (пользовательских бизнес-процессов).
Каждый из бизнес-процессов включает в себя входные и выходные данные, преобразования и
внешние интерфейсы.
Процедура оценивания размеров программной системы соотносится с одним из пользователь-
ских бизнес-процессов и состоит из следующей последовательности этапов (ввод, вывод, опросы,
структуры данных, интерфейсы):
−
выделение множества бизнес-процессов;
−
подсчет количества функциональных точек бизнес-процесса в разрезе каждой категории;
−
определение весовых коэффициентов сложности каждой функции;
−
учет факторов и требований среды разработки программной системы;
−
вычисление интегральных показателей сложности;
−
вычисление итогового количества функциональных точек;
−
определение размеров программного комплекса в показателях LOC;
−
определение размеров программной системы в целом.
При определении количества функций каждого бизнес-процесса следует руководствоваться сле-
дующими требованиями:
−
учитываются только сложные функции, перечисленные в техническом задании;
−
при декомпозиции сложной функции учитываются все логические преобразования с данны-
9
ми.
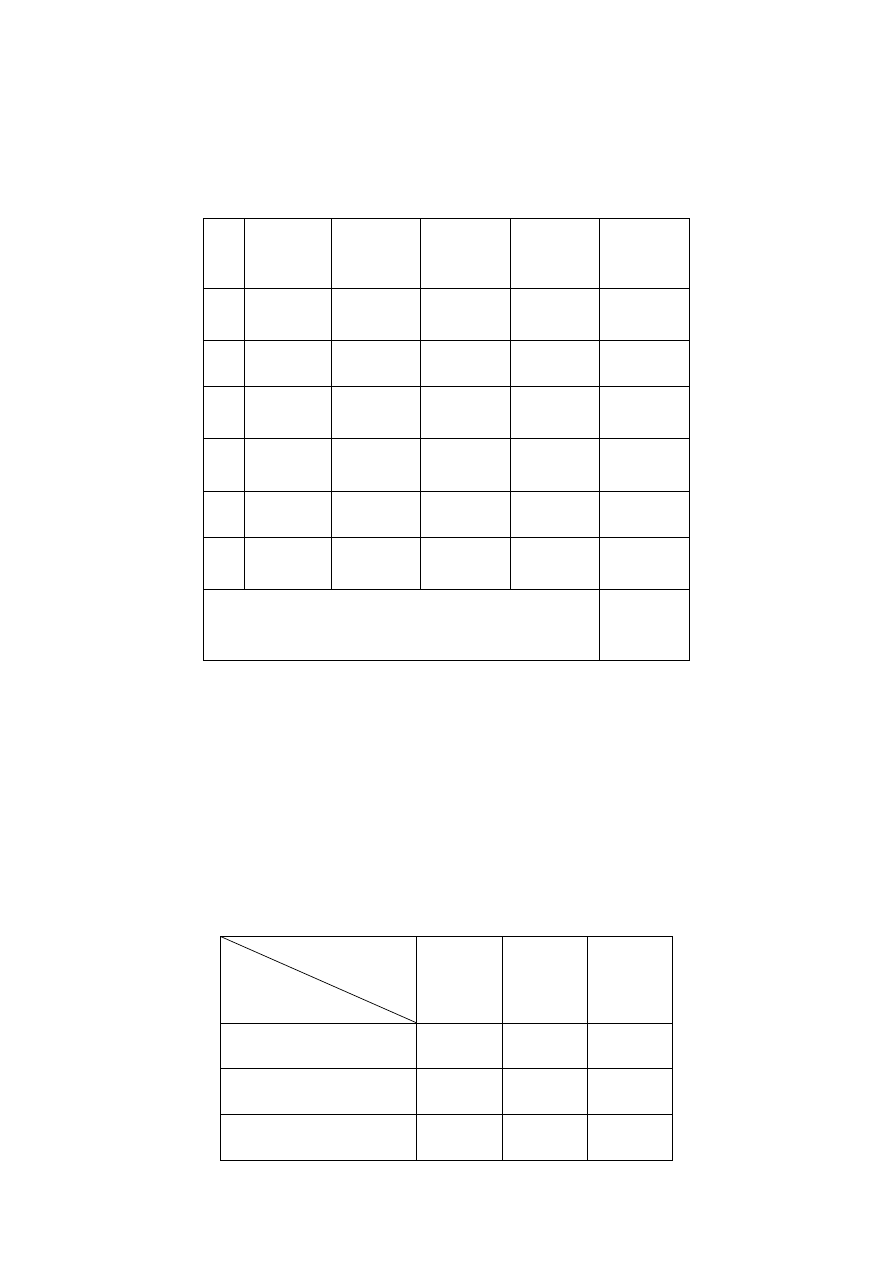
Расчет количества функциональных точек по каждому бизнес-процессу рекомендуется сводить в
следующую таблицу (табл. 2.3)
Таблица 2.3
Рабочая таблица определения количества
функциональных точек
№
п.п.
Категории
простых
функций
Простые
Средние
Сложные
Количест-
во функ-
циональ-
ных точек
1
Количест-
во выво-
дов
11
11
Χ
•
α
12
12
Χ
•
α
13
13
Χ
•
α
1
Χ
2
Количест-
во вводов
21
21
Χ
•
α
22
22
Χ
•
α
23
23
Χ
•
α
2
Χ
3
Количест-
во опросов
вывода
31
31
Χ
•
α
32
32
Χ
•
α
33
33
Χ
•
α
3
Χ
4
Количест-
во опросов
ввода
41
41
Χ
•
α
42
42
Χ
•
α
43
43
Χ
•
α
4
Χ
5
Количест-
во файлов
51
51
Χ
•
α
52
52
Χ
•
α
53
53
Χ
•
α
5
Χ
6
Количест-
во интер-
фейсов
61
61
Χ
•
α
62
62
Χ
•
α
63
63
Χ
•
α
6
Χ
Общее количество функциональных точек
∑
=
=
Χ
6
1
i
i
i
Примечание:
ij
α
— весовой коэффициент сложности
i
-й функции
j
-й категории сложности;
ij
x
— количество эле-
ментов данных
i
-й функции
j
-й категории сложности.
Определение количества выводов. Под
выводами будем понимать следующие единицы инфор-
мации, получаемые на выходе рассматриваемого бизнес-процесса:
−
файлы, продуцируемые в данном бизнес-процессе для передачи другим бизнес-процессам,
либо за пределы программной системы;
−
единицы деловой информации, предназначенные для конечных пользователей, оформленные
в виде экранных форм, либо бумажных документов.
Каждый из выводов, в зависимости от количества файлов, используемых при формировании вы-
ходов, рекомендуется отнести к одной из категорий сложности: простой, средний, сложный. В табл.
2.4 представлены весовые коэффициенты сложности выводов.
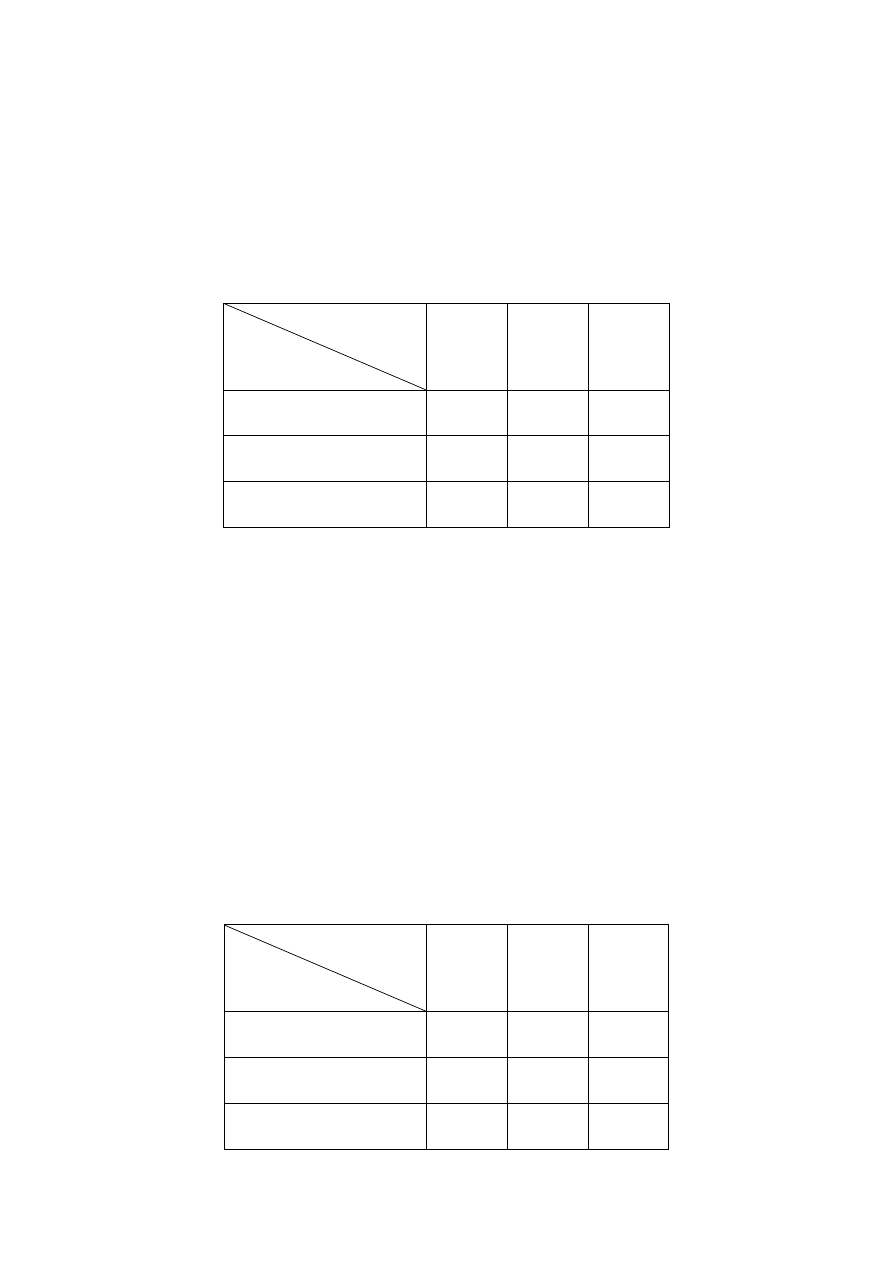
Таблица 2.4
Весовые коэффициенты сложности выводов
Количество
элементов
данных
Количество
файлов
от 1 до 5
от 6
до 19
20 и
более
1
4
11
=
α
4
12
=
α
5
13
=
α
2-3
4
11
=
α
5
12
=
α
7
13
=
α
4 и более
5
11
=
α
7
12
=
α
7
13
=
α
10
Определение количества вводов. Под
вводами будем понимать следующие единицы информа-
ции, поступающие на вход рассматриваемого бизнес-процесса:
−
входные файлы, полученные из других бизнес-процессов, либо других программных систем;
−
уникальная единица деловой информации, вводимая конечным пользователем.
По аналогии с выводом все вводы также рекомендуется разделять на простые, средние и слож-
ные (см. табл. 2.5).
Таблица 2.5
Весовые коэффициенты сложности ввода
Количество
элементов
данных
Количество
файлов
от 1 до 5
от 6
до 19
20 и
более
1
4
21
=
α
4
22
=
α
5
23
=
α
2-3
4
21
=
α
5
22
=
α
7
23
=
α
4 и более
5
21
=
α
7
22
=
α
7
23
=
α
Определение количества опросов ввода, вывода.
Под опросами будем понимать следующие
действия, исполняемые программной системой в рассматриваемом бизнес-процессе:
−
обращение к внешним процедурам, оформленным в виде специфических команд или запро-
сов, генерируемых извне и выполняемых программной системой;
−
выполнение процедур, обеспечивающих непосредственный доступ к базе данных и выпол-
няющих выборку с помощью простых ключей в режиме реального времени, но не выполняющих
функции обновления.
Рекомендуется учитывать каждую уникальную единицу опроса, если:
−
формат опроса отличается от формата ввода, вывода;
−
формат опроса совпадает с форматом ввода, вывода, но требует дополнительной логики обра-
ботки.
При определении количества опросов не следует учитывать запросы к базам данных, исполь-
зующие несколько ключей и выполняющие определенные операции, либо вычисления с последую-
щим оформлением выводов.
Все опросы также рекомендуется разделять на простые, средние и сложные. В таблицах 2.6 и 2.7
приведены рекомендации по выбору весовых коэффициентов.
Таблица 2.6
Весовые коэффициенты сложности опросов вывода
Количество
элементов
данных
Количество
файлов
от 1 до 5
от 6
до 19
20 и
более
1
4
31
=
α
4
32
=
α
5
33
=
α
2-3
4
31
=
α
5
32
=
α
7
33
=
α
4 и более
5
31
=
α
7
32
=
α
7
33
=
α