Добавлен: 22.04.2023
Просмотров: 158
Скачиваний: 2
СОДЕРЖАНИЕ
Глава 1. Понятие информации, данных и сообщений в современной науке и технике
Глава 2. Характеристика процессов сбора, передачи, обработки и накопления информации
2.2. Подготовка и передача информации
Глава 3. Кодирование информации
3.2. Кодирование текстовой информации
3.3. Кодирование графической информации
Второй, не менее важной целью кодирования, является обеспечение заданной надежности сообщения при передаче или хранении информация путем добавления дополнительной избыточности, но уже по простым алгоритмам и с учетом интенсивности и статистических закономерности возникновения помех в канале связи. Такое кодирование называется помехоустойчивым [8].
Выбор соответствующих устройств кодирования и декодирования зависит от статистических свойств источника сообщения, уровень и характер помех в канале связи. В передатчике (ПРД) первичный электрический сигнал преобразуется во вторичный u(t), пригодный для передачи по соответствующему каналу связи (линии). Это преобразование осуществляется с помощью модулятора [4].
Преобразование сообщения в сигнал должно быть обратимым. Это позволит выходному сигналу восстановить входной первичный сигнал, т. е. получить всю информацию, содержащуюся в передаваемом сообщении. В противном случае часть информации будет потеряна.
Линия связи - это среда, используемая для передачи сигналов от передатчика к приемнику [1].
В телекоммуникационных системах такими линиями являются кабели, волноводы. В системах радиосвязи линии являются пространствами, в котором электромагнитные волны распространяются от передатчика к приемнику. При передаче по линии связи сигналы от источника (ИП) могут быть интерферированы с n(t), что приводит к появлению искажения сигналов.
Приемное устройство, как часть приемника (ПРМ) и декодирующего устройства информации (ДИ), обрабатывает принятый сигнал z(t) = s(t) + n (t) и восстанавливает его в переданное сообщение a', соответствующее источнику информации сообщения a [8].
Система связи – это совокупность технических средств передачи информации и сообщения от источника к потребителю, включая передатчики (КИ, ПРД) и (ДИ, ПРМ) устройства и линии связи [1].
Системы связи различаются по типу передаваемых сообщений, предназначен для передачи речи (телефонной), текста (телеграфной), фотоснимков (фототелеграфной), изображений (телевизионной); вещания сигналов, передачи данных, видеотекст, телетекст, конференцсвязь, телеизмерение и телеуправление и др.
По количеству переданных сообщений на одной линии связи системы делятся на одноканальные и многоканальные.
Канал связи – это совокупность технических средств (ПРД линия связи, ПРМ), обеспечивающие передачу сигналов от источника (КИ) к приемнику сигнала (ДИ) [1].
Классификация каналов связи может осуществляться по ряду показателей:
- по типу сигналов, поступающих на вход канала и удаляемых с его выхода-дискретный, непрерывный, дискретно-непрерывный.
- по способу передачи информации между объектами каналы являются:
- дуплекс, обеспечивающий возможность передачи информации от объекта, а к объекту В, а от объекта К объекту А;
- симплекс, обеспечивающий только передачу информации в одном направлении.
- по структуре источника осуществляется связь с получателями канала связи:
- последовательные линии связи с одним фидером проходят через каждый пункт назначения;
- радиальный-каждый пункт назначения связан с объектом одинофидерной линии;
- древовидные - однофидерные линии не соединены непосредственно с объектом, а соединены с ним через отдельную линию [15].
По типу линий связи каналы делятся на проводные, радиоканалы, оптические, гидроакустические и другое.
2.3. Хранение информации
Хранение информации - это ее запись в вспомогательные запоминающие устройства на различных носителях для последующего использования [15].
Хранение - это одна из основных операций, осуществляемых над информацией, и основной способ обеспечения ее доступности в течение определенного периода времени [8]. Основным содержанием процесса хранения (удержания хранения) и накопления информации является создание, запись, пополнение и ведение информационных массивов и баз данных (Рис. 5). В результате реализации такого алгоритма документ, независимо от формы представления, поступивший в информационную систему, обрабатывается и затем направляется в хранилище (базу данных), где размещается на соответствующей «полке» в зависимости от принятой системы хранения. Результаты обработки переносятся в каталог [10].
Этап хранения информации может быть представлен на следующих уровнях: внешнем, концептуальном, (логическом), внутреннем, физическом.
Внешний уровень отражает содержание информации и предлагает способы (типы) представления данных пользователю во время осуществления их хранения [4].
Концептуальный уровень определяет порядок организации информационных массивов и способы хранения информации (файлов, массивы, распределенные хранилища, концентрированный и т. д.) [6].
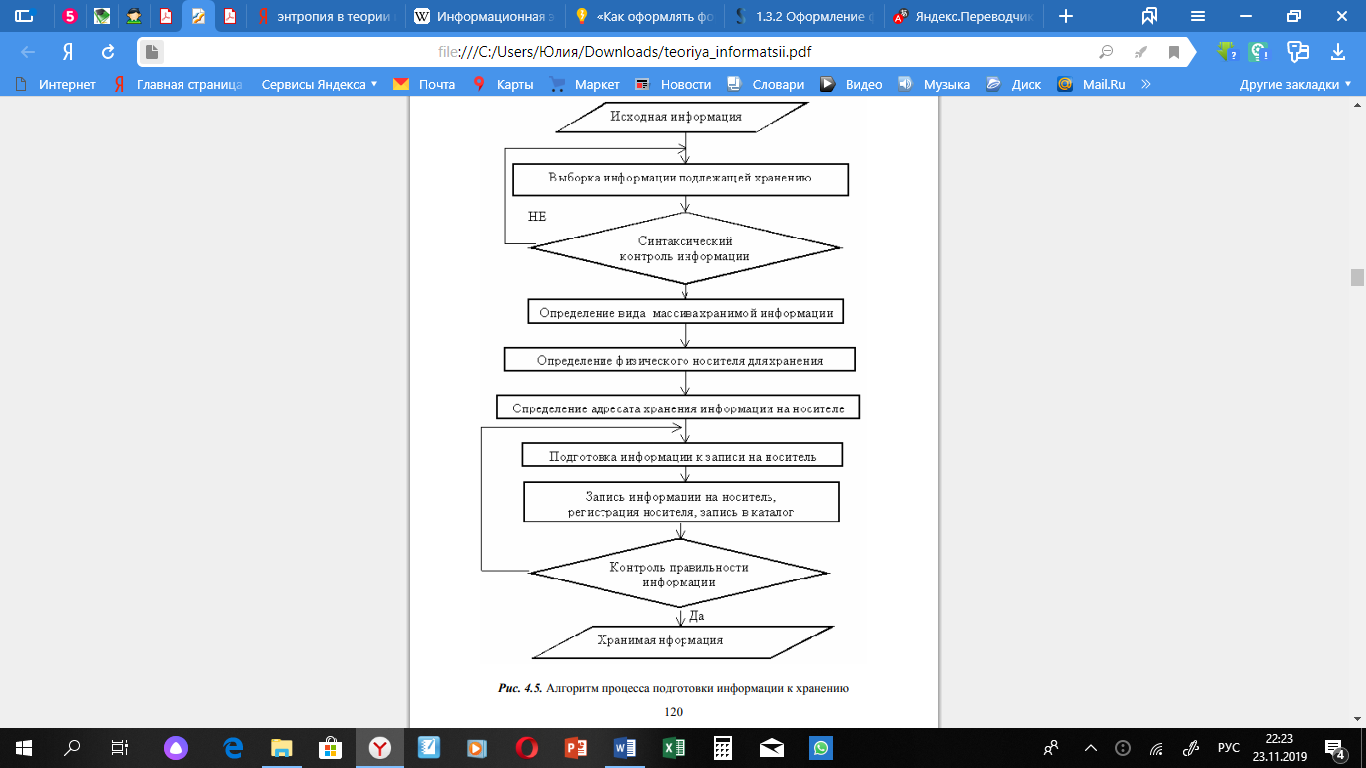
Рисунок 5. Алгоритм процесса подготовки информации к хранению.
Внутренний уровень представляет собой организацию хранения информационных массивов в системе их обработки и определяется разработчиком [15].
Физический уровень хранения относится к реализации хранения информация на конкретных физических носителях [15].
Информация должна хранится так, что она могла быть найдена быстро для будущего использования. Возможность быстрого поиску закладывается в процессе организации процесса запоминания. Для этого используются методы маркировки запоминаемой информации, обеспечивающие поиск и последующий доступ к ней. Эти методы используются для работы с файлами, графическими базами данных. Маркер - метка на носителе информации, указывающая начало или конец данных, или их части (блока). В современных медиа используются маркеры: адреса (address) - код или физическая метка на дорожке диска, указывающая к началу адреса сектора [8].
Хранение информации в ЭВМ связано как с процессом ее арифметической обработки, так и с принципами организации информационных массивов, поиска, обновления, представления информации и т.д. Важным шагом на этапе автоматизированного хранения является организация массивов данных.
Массив - упорядоченный набор данных. Массив данных системы хранения в том числе представление данных и отношений между ними, т. е. принципов их организации. Массивы по своей структуре близки к файлам и отличаются от последних двумя основными признаками: каждый элемент массива может быть явно обозначен, и к нему имеется прямой доступ; число элементов массива определятся при его описании [13].
На физическом уровне любое информационное поле записывается представлены в виде двоичных символов. Доступ к памяти требуется большой объем и большая длина адреса. Информация хранится на специальных носителях. Исторически наиболее распространенным носителем информации была бумага, которая, однако, непригодна в нормальных (не специальных) условиях для длительного хранения информации. На бумагу оказывают вредное воздействие – температурные условия: либо разбухает, либо ломается, способен к воспламенению. Для ЭВТ различают следующие машинные носители по материалу изготовления: бумага, металл, пластик, комбинированные и др [10].
О принципе воздействия и возможности изменения структуры существуют магнитные, полупроводниковые, диэлектрические, перфорационные, оптические и др [1].
По способу считывания различают контактные, магнитные, электрические, оптические. Особое значение при построении информационного обеспечения имеют характеристики доступа к информации, записано на носителе. Выделяются средства прямого и последовательного доступа. Пригодность носителя для хранения информации оценивается по следующим параметрам: время доступа, емкость плотность памяти и записи [15].
Вывод по второй главе: Таким образом, можно сделать вывод, что хранение информации (хранение данных) представляет собой процесс передачи информации во времени, связанный с обеспечением неизменности состояния материального носителя.
Глава 3. Кодирование информации
3.1. Двоичное кодирование
Для автоматизации работы с данными, принадлежащими к разным типам, очень важно унифицировать их форму представления — для этого обычно используется несколько техник кодирования, то есть выражения данных одного типа через данные другого типа. В ВТ существует система кодирования - она называется двоичным кодированием и основана на представлении данных последовательностью всего из двух символов: 0 и 1. Эти знаки называются двоичными цифрами, по — английски-binary digit или сокращенно bit (бит). Один бит может выражать два понятия: 0 или 1 (Да или нет, черное или белое, истинное или ложное и т.). Если количество битов увеличить до двух, то мы можем выразить четыре различных понятия: 00 01 10 11, три бита могут кодировать восемь различных значений: 000 001 010 011 100 101 110 111, увеличивая на единицу количество цифр в системе двоичного кодирования, мы увеличиваем вдвое количество значений, которые могут быть выражены в этой системе, то есть общая формула такова: N=2i, где N — количество независимых кодированных значений; i-разрядность двоичного кодирования, принятая в этой системе. Кодирование целых и вещественных чисел целые числа кодируются двоичным кодом довольно просто — достаточно взять целое число и разделить его пополам, пока частное не станет равным единице. Множество остатков от каждого деления, записанное справа налево вместе с последним частным, и образует двоичный аналог десятичного числа. 19:2 = 9+1 9:2=4+1 4:2=2+0 2:2=1+0. Таким образом, 1910 = 100112. Для кодирования целых чисел от 0 до 255 достаточно иметь 8 бит двоичного кода (8 бит). Шестнадцать бит позволяют кодировать целые числа от 0 до 65 535, а 21 бит — уже более 16,5 миллиона различных значений. 80-битное кодирование используется для кодирования вещественных чисел. Первая часть числа называется мантиссой, а вторая часть-характеристикой.
3.2. Кодирование текстовой информации
Кодирование текстовой информации. Если каждому символу алфавита присвоено определенное целое число (например, порядковый номер), то двоичный код может кодировать текстовую информацию. Восьми двоичных битов достаточно для кодирования 256 различных символов. Этого достаточно, чтобы выразить в различных комбинациях из восьми бит все символы английского и русского языков, как строчные, так и прописные, а также знаки препинания, символы основных арифметических операций и некоторые общепринятые специальные символы, такие как символ «§» технически это выглядит очень просто, но всегда были довольно значительные организационные трудности. В первые годы развития вычислительной техники они были связаны с отсутствием необходимых стандартов, а сейчас они вызваны, наоборот, обилием одновременно действующих и противоречивых стандартов. Для английского языка, который захватил де-факто нишу международного средства коммуникации, противоречия уже сняты. Американский Национальный институт стандартов (ANSI) ввел систему кодирования ASCII (American Standard Code for Information Interchange) (см. Приложение 1). Система ASCII имеет две таблицы кодирования — базовая и расширенная. Базовая таблица фиксирует значения кодов от 0 до 127, а расширенная таблица относится к символам с числами от 128 до 255. Первые 32 кода базовой таблицы, начиная с нуля, выдаются производителям оборудования (в первую очередь производителям компьютеров и принтеров). В этой области размещаются так называемые управляющие коды, которые не соответствуют никаким языковым символам, и, соответственно, эти коды не выводятся на экран или на печатающее устройство, но ими можно управлять путем вывода других данных. Начиная с кода 32 до кода 127 существуют коды символов английского алфавита, знаков препинания, цифр, арифметических операций и некоторых вспомогательных символов. Универсальная система кодирования текстовых данных если проанализировать организационные трудности, связанные с созданием единой системы кодирования текстовых данных, то можно сделать вывод, что они вызваны ограниченным набором кодов (256). В то же время очевидно, что если, например, кодировать символы не восьми битными двоичными числами, а числами с большим числом цифр, то диапазон возможных значений кодов станет значительно больше. Такая система, основанная на 16-битной кодировке символов, получила название universal — UNICODE (см. Приложение 1). Шестнадцать цифр позволяют предоставить уникальные коды для 65 536 различных символов — этого поля достаточно, чтобы разместить в одной таблице символы большинства языков планеты. Несмотря на тривиальные доказательства такого подхода, простой механический переход к этой системе долгое время сдерживался из-за недостаточных ресурсов компьютерной техники (в системе кодирования UNICODE все текстовые документы автоматически становятся вдвое длиннее). Во второй половине 1990-х годов технические средства достигли необходимого уровня ресурсоемкости, и сегодня наблюдается постепенный переход документов и программного обеспечения на универсальную систему кодирования. Для отдельных пользователей это еще больше усугубило проблемы согласования документов, выполненных в различных системах кодирования, с программным обеспечением, но это следует понимать, как трудности переходного периода.