Добавлен: 29.10.2018
Просмотров: 48189
Скачиваний: 190
8.1. Мультипроцессоры
591
а большинство из них мало что знает о делении заданий на ряд пакетов, которые мо-
гут выполняться параллельно. Синхронизация, исключение состязательных условий
и предупреждение взаимных блокировок — все это как будто соткано из дурных снов,
но, к сожалению, при недостаточно эффективном управлении весьма существенно
страдает производительность. Семафоры здесь также не помогут.
Помимо этих начальных проблем есть и еще одна: совершенно непонятно, каким типам
приложений реально понадобятся сотни, не говоря уже о тысячах, ядер, особенно в до-
машней среде. В то же время в крупных серверных центрах для большого количества
ядер работа всегда найдется. Например, популярный сервер может запросто исполь-
зовать для каждого клиентского запроса отдельное ядро. Точно так же рассмотренные
в предыдущей главе провайдеры ресурсов для облачных вычислений могут задейство-
вать ядра для предоставления большого количества виртуальных машин, сдаваемых
в аренду клиентам, ищущим предоставляемые по запросу компьютерные мощности.
8.1.2. Типы мультипроцессорных операционных систем
Теперь перейдем от аппаратного обеспечения мультипроцессоров к их программному
обеспечению, в частности к мультипроцессорным операционным системам. Воз-
можны различные подходы к их организации, три из которых будут рассмотрены
далее. Следует заметить, что все эти подходы можно в равной степени применить
как к многоядерным системам, так и к системам, составленным из отдельных цен-
тральных процессоров.
Использование собственной операционной системы для каждого
центрального процессора
Простейший из возможных способов организации мультипроцессорной операцион-
ной системы заключается в статическом делении памяти на несколько разделов по
количеству имеющихся центральных процессоров и выделении каждому централь-
ному процессору собственной памяти и собственной копии операционной системы.
Фактически n центральных процессоров работают как n независимых компьютеров.
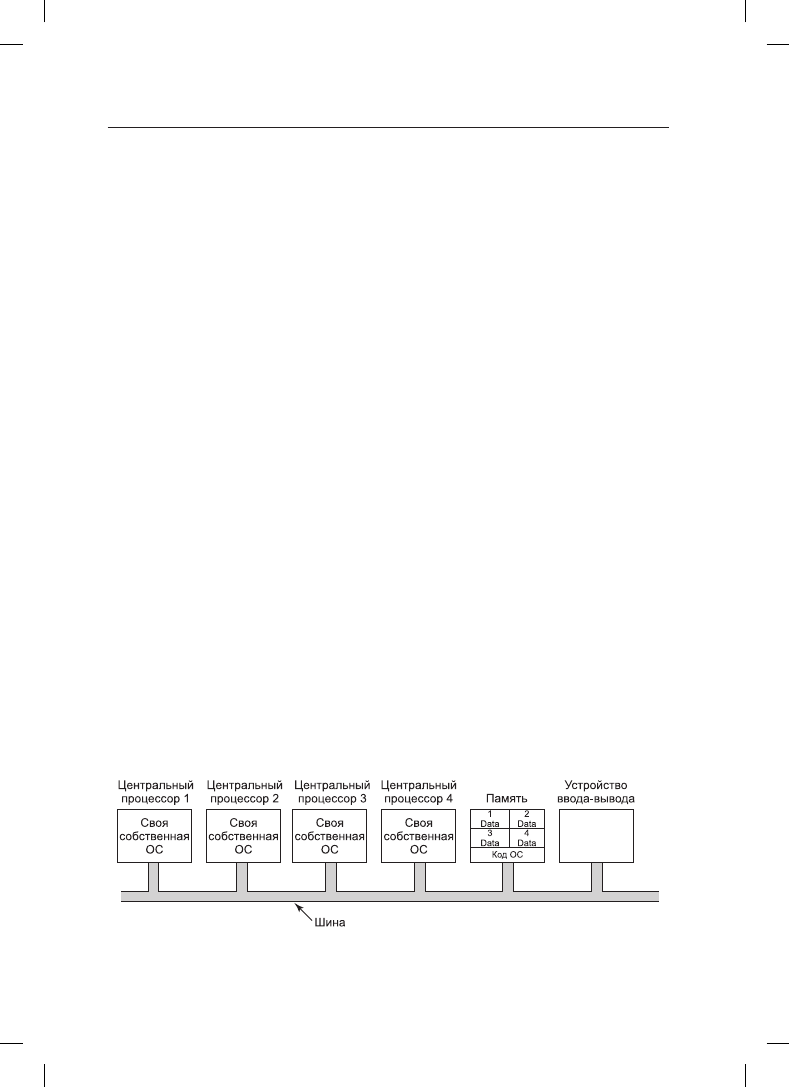
Вполне очевидна оптимизация, позволяющая всем центральным процессорам совмест-
но использовать код операционной системы и создавать собственные копии только
структуры данных операционной системы, как показано на рис. 8.7, где прямоуголь-
ники с надписями «Данные» отображают собственные данные операционных систем
каждого центрального процессора.
Рис. 8.7. Разделение памяти между четырьмя центральными процессорами, использующими
общий код операционной системы

592
Глава 8. Многопроцессорные системы
Эта схема все же лучше, чем схема, состоящая из n отдельных компьютеров, потому
что она дает возможность всем машинам совместно использовать набор дисков и дру-
гих устройств ввода-вывода, а также позволяет гибко решать вопросы совместного
использования памяти. Например, даже при статическом выделении памяти одному
центральному процессору может быть выделена очень большая доля памяти для
эффективной работы с большими программами. Кроме этого, процессы могут осу-
ществлять эффективный обмен данными, позволив поставщику записывать данные
непосредственно в память, а потребителю — извлекать их из того места, куда они были
записаны поставщиком. И все же с точки зрения разработчиков операционных систем
наличие у каждого центрального процессора собственной операционной системы яв-
ляется слишком примитивным подходом.
Стоит отметить четыре не самых очевидных аспекта этой схемы. Во-первых, когда
процесс осуществляет системный вызов, то этот системный вызов перехватывается
и обрабатывается на его собственном центральном процессоре с использованием
структуры данных в таблицах его операционной системы.
Во-вторых, поскольку у каждой операционной системы имеются собственные табли-
цы, то у нее также имеется и собственный набор процессов, планированием работы
которых она сама и занимается. Совместно используемых процессов не существует.
Если пользователь вошел в систему на центральном процессоре 1, то все его про-
цессы работают именно на этом процессоре. Следовательно, может случиться так,
что центральный процессор 1 простаивает, в то время как центральный процессор 2
загружен работой.
В-третьих, не существует совместно используемых физических страниц. Возможна
ситуация, при которой у центрального процессора 1 имеются в запасе страницы, а цен-
тральный процессор 2 постоянно занимается свопингом. А позаимствовать несколько
страниц у центрального процессора 1 центральный процессор 2 не может из-за фик-
сированного распределения памяти.
В-четвертых, что самое плохое, если операционная система поддерживает буферный
кэш недавно востребованных дисковых блоков, то каждая операционная система делает
это независимо от всех других операционных систем. И может сложиться ситуация, при
которой какой-нибудь дисковый блок одновременно присутствует сразу в нескольких
буферных кэшах в уже измененном состоянии, что приведет к несогласованности дан-
ных. Избежать этой проблемы можно, лишь отказавшись от буферных кэшей. Сделать
это несложно, но тогда существенно упадет производительность работы.
По этим причинам данная модель теперь используется крайне редко, хотя она и при-
менялась на заре мультипроцессоров, когда стояла задача как можно быстрее перенести
существующие операционные системы на какие-нибудь новые мультипроцессоры.
В исследованиях интерес к этой модели возродился, но с существенным количеством
всевозможных поправок. Есть еще кое-что недосказанное относительно сохранения
строгой обособленности операционных систем. Если полное состояние каждого про-
цессора хранится локально, то практическое отсутствие обмена ведет к возникновению
проблем согласованности или блокировки. В то же время, если нескольким процес-
сорам приходится обращаться к одной и той же таблице процесса и вносить в нее
изменения, блокировка очень быстро усложнится (и окажет существенное влияние
на производительность). Далее мы еще вернемся к данной теме при рассмотрении
симметричных мультипроцессоров.
8.1. Мультипроцессоры
593
Мультипроцессоры, работающие по схеме
«главный — подчиненный»
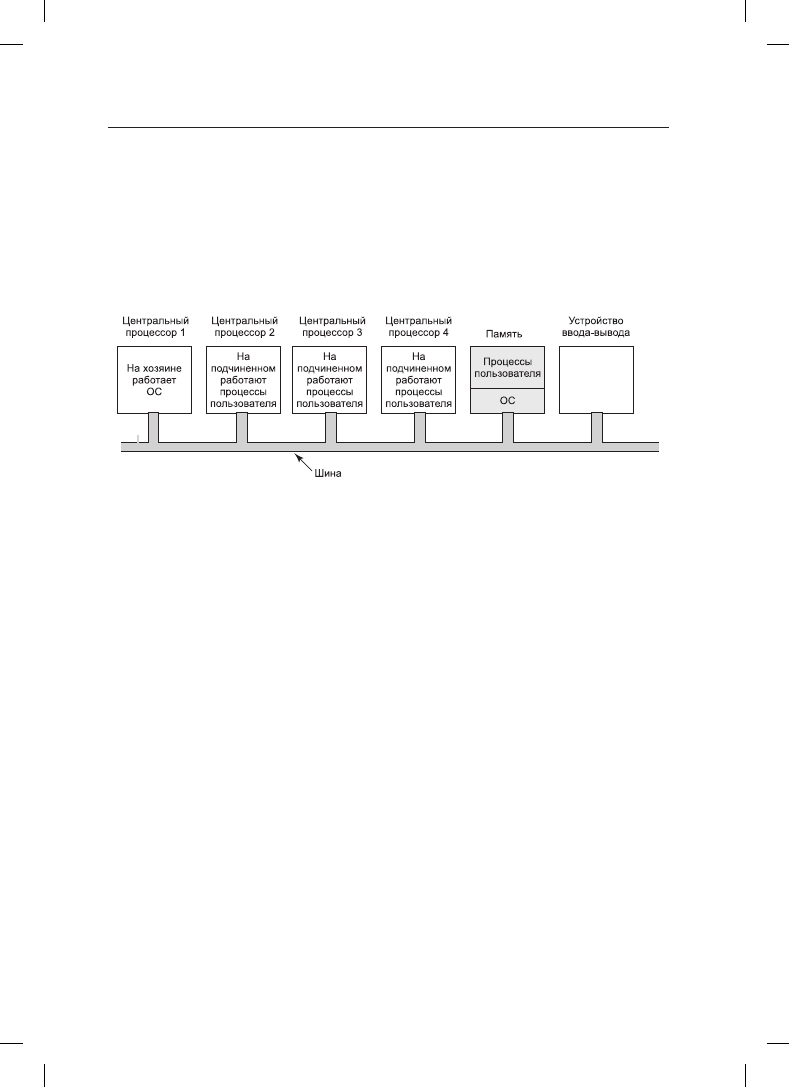
Вторая модель показана на рис. 8.8. Здесь используется одна копия операционной систе-
мы, а ее таблицы существуют исключительно для центрального процессора 1. Все систем-
ные вызовы переадресуются для последующей обработки центральному процессору 1.
Этот центральный процессор, если ему на это хватает времени, может также запускать
пользовательские процессы. Эта модель называется «главный — подчиненный», потому
что центральный процессор 1 является главным, а все другие — подчиненными.
Рис. 8.8. Мультипроцессорная модель «главный — подчиненный»
В модели «главный — подчиненный» решается большинство проблем первой модели.
В ней имеется единая структура данных (например, один список или набор при-
оритетных списков), позволяющая отслеживать готовые к работе процессы. Когда
центральный процессор остается без работы, он просит операционную систему на
центральном процессоре 1 дать ему процесс, готовый к работе, и получает его. Тем
самым исключаются простои одного центрального процессора, в то время как другой
не справляется со своей нагрузкой. Кроме того, страницы могут распределяться между
всеми процессами в динамическом режиме, и используется только один буферный кэш,
исключающий несогласованность данных.
Проблема данной модели заключается в том, что при большом количестве централь-
ных процессоров главный процессор становится ее узким местом, ведь кроме всего
прочего он должен обрабатывать все системные вызовы, поступающие от других
центральных процессоров. Если, скажем, 10 % всего времени он тратит на обработку
системных вызовов, то 10 центральных процессоров дадут ему предельную нагрузку,
а при 20 центральных процессорах он будет абсолютно перегружен. Таким образом, эта
модель подходит для небольших мультипроцессорных систем, но на больших системах
она работать не будет.
Симметричные мультипроцессоры
Асимметрия модели «главный — подчиненный» устраняется в нашей третьей моде-
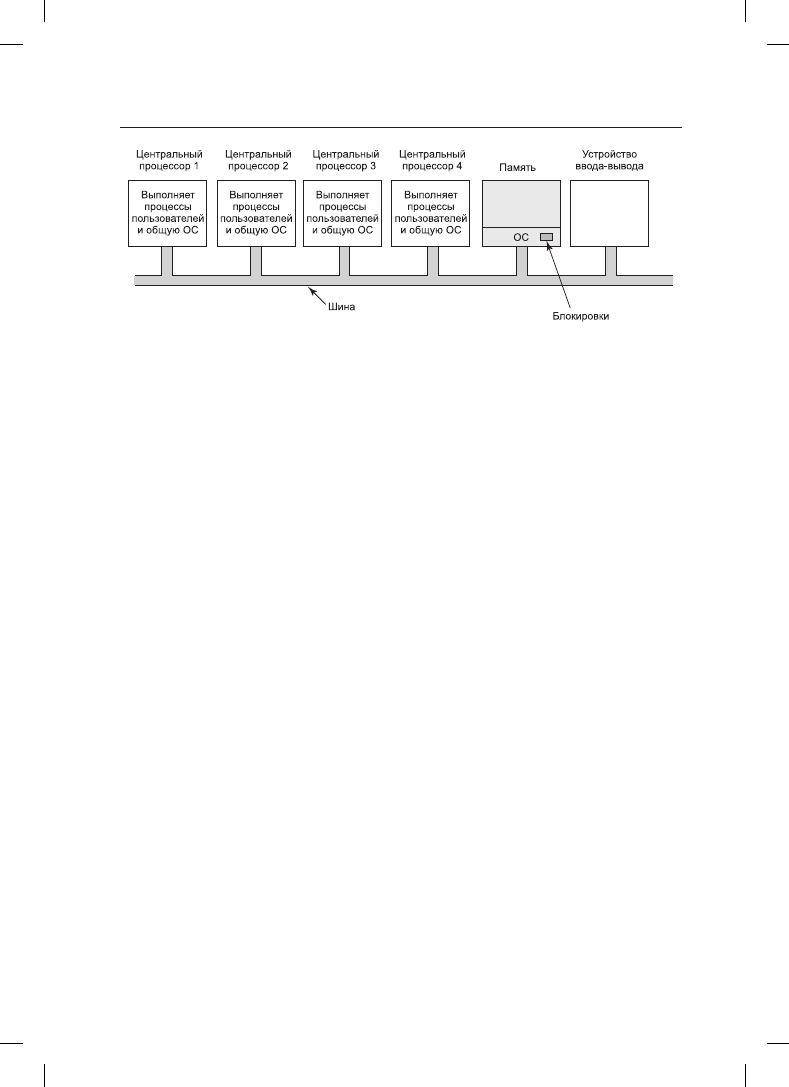
ли — симметричных мультипроцессорах (Symmetric MultiProcessor (SMP)). В памяти
присутствует только одна копия операционной системы, но ее может запустить любой
центральный процессор. При осуществлении системного вызова центральный процес-
сор, на котором произошел системный вызов, переходит в режим ядра и обрабатывает
этот системный вызов. Модель SMP показана на рис. 8.9.
594
Глава 8. Многопроцессорные системы
Рис. 8.9. Мультипроцессорная модель SMP
В этой модели баланс процессов и памяти осуществляется в динамическом режиме, по-
скольку используется только один набор таблиц операционной системы. Узкое место,
связанное с главным центральным процессором, за неимением такового также отсут-
ствует, но возникают новые проблемы. В частности, если два или более центральных
процессора запускают код операционной системы в одно и то же время, может произой-
ти авария. Представьте, что два центральных процессора одновременно выбирают для
работы один и тот же процесс или требуют одну и ту же свободную страницу памяти.
Простейший способ обхода этих проблем заключается в связывании с каждой опера-
ционной системой мьютекса (то есть блокировки), что превращает всю систему в одну
большую критическую область. Когда центральному процессору требуется запустить
код, он в первую очередь должен получить мьютекс. Если мьютекс заблокирован, про-
цессор просто переходит в режим ожидания. Таким образом, в любой момент времени
выполнять код операционной системы может любой, но только один центральный
процессор. Такой подход носит название большой блокировки ядра (big kernel lock).
Эта модель работает не намного лучше модели «главный — подчиненный». Предпо-
ложим еще раз, что 10 % всего рабочего времени тратится на выполнение кода опера-
ционной системы. Если используются 20 центральных процессоров, то из них может
выстроиться длинная очередь ожидающих доступа к коду операционной системы.
К счастью, улучшить ситуацию довольно просто. Многие части операционной систе-
мы независимы друг от друга. Например, если один центральный процессор запустит
планировщик, другой в это же время займется обработкой системного вызова, связан-
ного с файлом, а третий параллельно с этим будет обрабатывать ошибку отсутствия
страницы, то проблем не возникнет.
Благодаря этому операционную систему можно разбить на несколько независимых
критических областей, не взаимодействующих друг с другом. Каждая критическая об-
ласть защищается собственным мьютексом, поэтому исполнять ее код в любой момент
времени может только один из центральных процессоров. Таким образом можно достичь
большей параллельности в работе. Но может сложиться ситуация, что некоторые табли-
цы, например таблица процессов, используются программным кодом сразу в нескольких
критических областях. Например, таблица процессов нужна планировщику, но она же
нужна и обработчику системного вызова fork, а также нужна для обработки сигнала.
Каждая таблица, которая может понадобиться коду сразу нескольких критических об-
ластей, нуждается в собственном мьютексе. При этом в каждый момент времени код каж-
дой критической области может исполняться только одним центральным процессором
и к каждой критической таблице может обращаться только один центральный процессор.

8.1. Мультипроцессоры
595
Такая система используется большинством современных мультипроцессоров. Слож-
ности создания операционной системы для такой машины связаны отнюдь не с тем,
что создаваемый код сильно отличается от кода обычной операционной системы,
а с тем, что разбить операционную систему на критические области, которые могут
исполняться параллельно разными центральными процессорами без причинения друг
другу каких-либо даже малейших косвенных проблем, довольно трудно. Кроме этого,
каждая таблица, которая используется кодом в двух и более критических областях,
должна иметь отдельную мьютексную защиту, и все фрагменты кода, использующие
таблицу, должны использовать мьютекс корректно.
Более того, нужно приложить массу усилий, чтобы избежать взаимных блокировок.
Если коду сразу в двух критических областях нужны таблица A и таблица B и один из
фрагментов кода первым затребовал A, а другой первым затребовал B, то рано или поздно
произойдет взаимная блокировка и никто не поймет почему. Теоретически всем таблицам
можно присвоить целочисленное значение, и программный код во всех критических об-
ластях может быть написан с учетом требования запроса таблиц по порядку возрастания
их номеров. Эта стратегия позволит избежать взаимных блокировок, но потребует от
программиста тщательно взвесить, какие таблицы кодом каких критических областей
будут востребованы, и обеспечить выдачу запросов в правильном порядке.
Со временем вносимые в систему изменения могут привести к тому, что коду в кри-
тической области потребуется ранее не нужная таблица. Если программист не в курсе
прежних разработок и не понимает всей логики работы системы, то он будет стремиться
лишь к захвату мьютекса таблицы в нужный момент и к его освобождению, когда на-
добность в таблице исчезнет. Несмотря на кажущуюся логичность его устремлений, они
могут привести к взаимным блокировкам, которые пользователями будут восприняты
как зависание системы. Разобраться в этой ситуации не так-то просто, а удерживать ее
под контролем многие годы в условиях смены программистов и того труднее.
8.1.3. Синхронизация мультипроцессоров
Центральные процессоры, входящие в состав мультипроцессора, часто нуждаются
в синхронизации. Только что была рассмотрена ситуация, при которой критические об-
ласти ядра и таблицы должны быть защищены мьютексами. А теперь мы присмотримся
к тому, как эта синхронизация работает в мультипроцессоре. Вскоре станет ясно, что
здесь далеко не все так просто.
Для начала надо будет выбрать правильные примитивы синхронизации. Если про-
цесс на однопроцессорной системе осуществляет системный вызов, который требует
доступа к некой критической таблице, находящейся в ядре, то программный код ядра
может до предоставления доступа к таблице просто запретить прерывания. Но на муль-
типроцессорной системе запрет прерываний воздействует только на тот центральный
процессор, который их и запретил. Остальные центральные процессоры продолжат
свою работу и все равно смогут получить доступ к критической таблице. Следова-
тельно, требуется подходящий мьютекс-протокол, соблюдаемый всеми центральными
процессорами и гарантирующий работу взаимного исключения.
Основой любого практического мьютекс-протокола является специальная команда
процессора, позволяющая провести проверку и установку значения за одну неделимую
операцию. На рис. 2.16 был показан пример использования команды TSL (Test and Set
Lock — проверить и установить блокировку) при реализации критических областей.