Добавлен: 29.10.2018
Просмотров: 48179
Скачиваний: 190
8.2. Мультикомпьютеры
611
многие схемы соединений являются синхронизированными, поэтому как только нач-
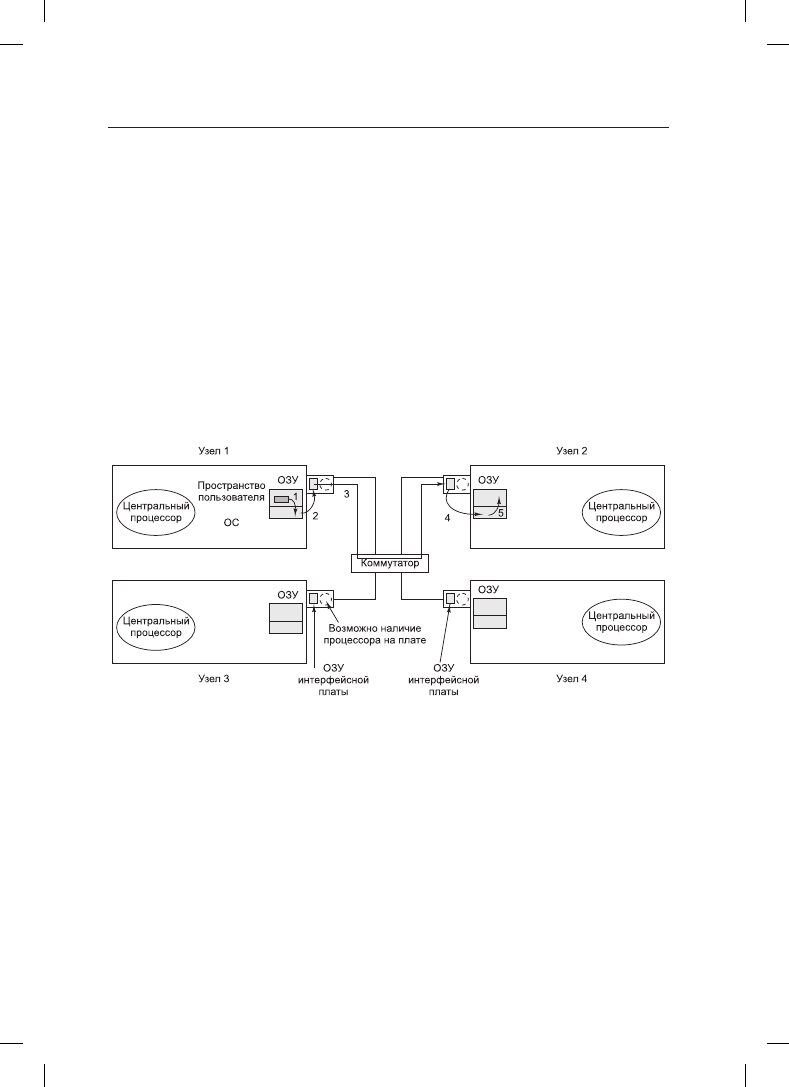
нется передача пакета, поток битов должен идти с постоянной скоростью. Если пакет
находится в основной оперативной памяти, непрерывный исходящий поток данных
в сеть не может быть гарантирован из-за того, что шина занята обеспечением обмена
и другими данными. Использование выделенной оперативной памяти на интерфейсной
плате устраняет проблему. Эта конструкция показана на рис. 8.18.
Такая же проблема существует и для входящих пакетов. Биты поступают из сети с по-
стоянной и зачастую очень высокой скоростью. Если плата сетевого интерфейса не
может сохранить их в реальном масштабе времени по мере поступления, данные будут
потеряны. Здесь попытка передачи данных по системной шине (например, по шине
PCI) в оперативную память также слишком рискованна. Поскольку сетевая плата
обычно вставляется в слот шины PCI, то это единственное имеющееся у нее подключе-
ние к основной оперативной памяти, поэтому неминуемо соревнование за захват этой
шины между платой и всеми другими устройствами ввода-вывода. Входящие пакеты
интерфейсной плате безопаснее хранить в собственной оперативной памяти, а чуть
позже копировать их в основную оперативную память.
Рис. 8.18. Расположение платы сетевого интерфейса в мультикомпьютере
Интерфейсные платы могут иметь в своем составе один и более DMA-каналов или
полноценный центральный процессор (или, может быть, даже несколько центральных
процессоров). DMA-каналы могут копировать пакеты между интерфейсной платой
и основной оперативной памятью на высокой скорости за счет запроса передачи блока
по системной шине и передачи нескольких слов без необходимости запрашивать шину
отдельно для каждого слова. Но это именно тот тип блочной передачи, который связы-
вает системную шину на несколько циклов, что в первую очередь делает необходимым
наличие на интерфейсной плате оперативной памяти.
Многие интерфейсные платы имеют полноценные центральные процессоры, возможно,
вдобавок к одному или нескольким DMA-каналам. Они называются сетевыми про-
цессорами
(network processors) и становятся все более и более мощными (El Ferkouss
et al., 2011). Такая конструкция означает, что основной центральный процессор может
переложить часть работы на сетевую плату: например, обеспечение надежной передачи

612
Глава 8. Многопроцессорные системы
данных (если базовое оборудование может терять пакеты), многоканальную рассылку
(отправление пакета более чем одному получателю), сжатие-распаковку, кодирование-
декодирование и осуществление защиты данных в системе с несколькими процессами.
Но наличие двух центральных процессоров подразумевает синхронизацию их работы
во избежание возникновения состязательных условий, что влечет за собой дополни-
тельные издержки и увеличение объема работы для операционной системы.
Копирование данных через уровни проходит безопасно, но не всегда эффективно.
Например, браузер, запрашивающий данные с удаленного веб-сервера, создаст запрос
в браузерном адресном пространстве. Затем этот запрос будет скопирован в ядро, чтобы
появилась возможность его обработки в соответствии с протоколами TCP и IP. После
этого данные будут скопированы в память сетевого интерфейса. В то же время будет
происходить обратный процесс: данные будут скопированы из сетевой карты в буфер
ядра, а из него — в веб-сервер. Копий, к сожалению, получается довольно много. Каж-
дая копия влечет за собой издержки, связанные не только с самим копированием, но
и с загрузкой кэша, TLB и т. д. Как следствие, задержка в таких сетевых соединениях
получается довольно большой.
В следующем разделе будет рассмотрена технология максимально возможного со-
кращения издержек, связанных с копированием, засорением кэша и переключением
контекста.
8.2.2. Низкоуровневые коммуникационные программы
Врагом высокоскоростного обмена данными в многомашинных системах является
излишнее копирование пакетов. В лучшем случае происходит одна операция копи-
рования из оперативной памяти на интерфейсную плату источника, одна операция
копирования с интерфейсной платы источника на интерфейсную плату приемника
(если промежуточное хранение пакетов по маршруту передачи не применяется) и одна
операция копирования с интерфейсной платы приемника в оперативную память. Итого
три операции копирования. Однако во многих системах складывается еще более непри-
ятная ситуация. В частности, если интерфейсная плата отображается на виртуальное
адресное пространство ядра, а не на виртуальное адресное пространство пользователя,
процесс пользователя может отправить пакет только за счет выдачи системного вызова,
перехватываемого ядром. Возможно, ядру потребуется скопировать как исходящие,
так и входящие пакеты в собственную память, например, чтобы избежать ошибок
отсутствия страницы во время передачи пакета по сети. Кроме того, ядро получателя
может не знать, куда следует поместить входящий пакет, пока не получит возможность
изучить его содержимое. Эти пять операций копирования показаны на рис. 8.18.
Если копирование в оперативную память и из нее является узким местом, то дополни-
тельное копирование в ядро и из ядра может удвоить сквозную задержку и наполовину
урезать пропускную способность. Чтобы избежать этой потери производительности,
на многих мультикомпьютерах интерфейсная плата отображается непосредственно на
пользовательское пространство, что позволяет пользовательскому процессу напрямую
помещать пакеты в память платы без привлечения ядра. Этот подход существенно
способствует повышению производительности, однако создает две проблемы.
Прежде всего, что будет, если на узле запущены несколько процессов, которым нужен
доступ к сети для отправки пакетов? Какой из них получит интерфейсную плату в свое
адресное пространство? Использование системного вызова для отображения платы

8.2. Мультикомпьютеры
613
на виртуальное адресное пространство и прекращение этого отображения обходится
дорого, но если плату получает только один процесс, то как смогут отправлять сообще-
ния все остальные процессы? И что произойдет, если плата отображена на виртуальное
адресное пространство процесса A, а пакет поступил для процесса B, особенно если
у A и B разные владельцы, не желающие помогать друг другу?
Одно из решений состоит в отображении интерфейсной платы на все нуждающиеся
в ней процессы, но тогда потребуется механизм для предупреждения условий состязания.
Например, если A требует буфер на интерфейсной плате, а затем по истечении кванта
времени запускается B и требует тот же самый буфер, происходит катастрофа. Тут нужен
какой-то механизм синхронизации, но такие механизмы, как мьютексы, работают, только
если предполагается взаимодействие процессов. В среде с разделением времени, где не-
сколько пользователей и все они спешат выполнить свою работу, один из пользователей
может просто заблокировать мьютекс, связанный с платой, и не освобождать его никогда.
Отсюда следует вывод, что отображение интерфейсной платы на пользовательское про-
странство реально работает при наличии только одного пользовательского процесса на
каждом узле, если только не предприняты какие-то специальные меры предосторожно-
сти (например, разным процессам предоставляются различные участки интерфейсной
оперативной памяти, отображаемой на их адресные пространства).
Вторая проблема заключается в том, что ядру может понадобиться доступ к самой
схеме соединений, например, чтобы получить доступ к файловой системе на удален-
ном узле. Использование ядром интерфейсной платы совместно с любыми пользо-
вателями — неудачная идея. Предположим, что плата отображена на пространство
пользователя, а пакет прибыл для ядра. Или предположим, что пользовательский
процесс отправил пакет на удаленную машину, притворившись ядром. Из этого следует
вывод: проще всего иметь две платы сетевого интерфейса — одну, отображенную на
пространство пользователя, для обмена данными между приложениями и еще одну,
отображенную на пространство ядра, для использования операционной системой.
На многих мультикомпьютерах именно так и сделано.
В то же время самые новые сетевые интерфейсы зачастую обладают многоочеред-
ностью
, которая означает наличие у них более одного буфера для эффективной под-
держки нескольких пользователей. Например, серия сетевых карт Intel I350 имеет
8 очередей на отправку и 8 очередей на получение и обладает способностью виртуали-
зации на множество виртуальных портов. Еще больше радует, что карта поддерживает
привязку
(affinity) ядер. В частности, у нее имеется собственная логика хэширования,
что помогает направить каждый пакет в подходящий процесс. Поскольку быстрее будет
обработать все сегменты в одном и том же потоке TCP на одном и том же процессоре
(где кэши сохраняют нужные данные), карта может использовать логику хэширования
для хэширования полей потока TCP (IP-адресов и номеров TCP-портов) и добавить
все сегменты с одинаковым хэшем в одну и ту же очередь, обслуживаемую конкретным
ядром. Это также поспособствует виртуализации, поскольку позволит нам дать каждой
виртуальной машине ее собственную очередь.
Связь между узлом и сетевым интерфейсом
Еще один вопрос касается поступления пакетов на интерфейсную плату. Быстрее всего
воспользоваться для этого установленной на плате микросхемой DMA, чтобы просто
скопировать их из оперативной памяти. Но проблема при таком подходе заключается
в том, что DMA может использовать физические, а не виртуальные адреса и работает

614
Глава 8. Многопроцессорные системы
независимо от центрального процессора, если только не присутствует блок управления
памятью ввода-вывода. Начнем с того, что при точном знании виртуального адреса
любого отправляемого пакета пользовательский процесс не знает его физического
адреса. Системный вызов для отображения виртуального адреса на физический выда-
вать нежелательно, поскольку интерфейсная плата отображалась в пользовательском
пространстве в первую очередь для того, чтобы избежать необходимости выдачи си-
стемных вызовов для каждого отправляемого пакета.
Кроме этого, если операционная система решает заменить страницу в то время, как
микросхема DMA копирует с нее пакет, то будут переданы неверные данные. Будет
еще хуже, если операционная система заменит страницу в тот самый момент, когда
микросхема DMA копирует в нее входящий пакет, — это приведет не только к потере
входящего пакета, но и к повреждению не имеющей ничего общего с этой операцией
страницы с весьма вероятным и быстрым наступлением катастрофических послед-
ствий.
Этих проблем можно избежать, если использовать системные вызовы для фиксации
и освобождения страниц в памяти, отключая на время страничный обмен. Но выдача
системного вызова для фиксации страницы, содержащей каждый исходящий пакет,
а затем выдача еще одного системного вызова для освобождения этой страницы
обойдутся недешево. Если пакет невелик по размеру, скажем, 64 байта или меньше, то
издержки на фиксацию и освобождение каждой страницы, содержащей буфер, будут
неприемлемыми. При пакетах большего размера, скажем, 1 Кбайт и более, с этим еще
можно будет смириться. При пакетах промежуточных размеров все зависит от харак-
теристик конкретного оборудования. Кроме ущерба, наносимого производительности,
фиксация и освобождение страниц усложняют программное обеспечение.
Удаленный непосредственный доступ к памяти
В некоторых областях значительные сетевые задержки просто неприемлемы. Напри-
мер, для конкретных приложений в высокопроизводительных вычислениях время
вычисления сильно зависит от сетевых задержек. Более того, интенсивный трейдинг
всецело заключается в выполнении компьютерами транзакций (по покупке и прода-
же акций) на очень высоких скоростях, — счет идет на микросекунды. Есть ли смысл
в торговле с помощью компьютерных программ акциями на миллионы долларов в мил-
лисекунды, в то время когда все программное обеспечение в значительной степени не
застраховано от ошибок, — это вопрос, который мог бы заинтересовать обедающих
философов при условии, что они не заняты захватом своих вилок. Но он явно не для
этой книги. Главное здесь в том, что если вам удастся снизить задержки, вы непременно
станете любимчиком своего босса.
В данных сценариях придется платить уменьшением количества копирований. По-
этому некоторыми сетевыми интерфейсами поддерживается технология удаленного
непосредственного доступа к памяти (Remote Direct Memory Access (RDMA)), которая
позволяет одной машине выполнять непосредственный доступ к памяти с одного ком-
пьютера на другой. Технология RDMA не связана ни с одной операционной системой,
и данные непосредственно извлекаются из памяти приложения или записываются
в эту память.
RDMA представляется весьма интересной технологией, но она не лишена недостатков.
Как и при использовании обычного DMA, операционной системе на обменивающихся

8.2. Мультикомпьютеры
615
данными узлах нужно закрепить страницы, вовлеченные в обмен данными. Кроме того,
простое помещение данных в память удаленного компьютера не приведет к существен-
ному сокращению задержки, если в курсе этого не будет другая программа. Успешный
RDMA-доступ не появляется автоматически вместе с явными уведомлениями. Вместо
этого широкое распространение получило решение, при котором получатель опраши-
вает байт в памяти. После осуществления передачи отправитель изменяет байт, чтобы
уведомить получателя о наличии новых данных. При всей работоспособности такого
решения оно не идеально и приводит к пустой трате циклов центрального процессора.
Для действительно серьезного высокоскоростного трейдинга создаются специализи-
рованные сетевые карты с использованием программируемых вентильных матриц.
Задержка от получения битов на сетевую карту до передачи сообщения на покупку
многолиллионных ценностей связана только с проводными соединениями и занимает
порядка микросекунды. Покупка ценных акций на 1 млн долларов за 1 мкс дает про-
изводительность в 1 терадоллар в секунду, что весьма неплохо, если вы способны пра-
вильно отлавливать все взлеты и падения курса и у вас крепкие нервы. Операционные
системы в таких экстремальных настройках особой роли не играют.
8.2.3. Коммуникационные программы
пользовательского уровня
Процессы, работающие на разных центральных процессорах мультикомпьютера, обме-
ниваются данными путем отправки друг другу сообщений. В простейшем виде отправка
сообщений предоставлена пользовательским процессам. Иными словами, операцион-
ная система предоставляет способ отправки и получения сообщений и библиотечные
процедуры, которые делают эти основные вызовы доступными пользовательским про-
цессам. В более сложной форме отправка сообщения скрыта от пользователей за счет
осуществления обмена данными с удаленными узлами, похожего на вызов процедуры.
Далее будут рассмотрены оба этих метода.
Библиотечные процедуры Send и Receive
Предоставляемые коммуникационные услуги по самому минимуму могут быть све-
дены к двум вызовам библиотечных процедур, одна из которых будет отправлять,
а другая — принимать сообщения. Вызов процедуры, отправляющей сообщение, может
иметь следующий вид:
send(dest, &mptr);
а вызов получающей процедуры может быть оформлен следующим образом:
receive(addr, &mptr);
Первая из этих процедур отправляет сообщение, на которое указывает переменная mptr,
процессу, который идентифицируется переменной dest, и блокирует вызывающий про-
цесс до тех пор, пока не будет отправлено сообщение. А вторая процедура блокирует
вызывающий процесс до тех пор, пока не будет получено сообщение. Как только это
произойдет, сообщение копируется в буфер, на который указывает переменная mptr,
и вызывающая процедура разблокируется. Параметр addr указывает адрес, отслежива-
емый получателем сообщения. Существует множество вариантов этих двух процедур
и их параметров.