Добавлен: 29.10.2018
Просмотров: 48185
Скачиваний: 190

8.1. Мультипроцессоры
601
системах ядро стремится выбрать для выполнения поток, а процесс, которому он при-
надлежит, играет в алгоритме выбора потока лишь незначительную роль (или вообще
не играет никакой роли). Далее речь пойдет о планировании потоков, но, разумеется,
в системах с однопоточными процессами или потоками, реализованными в пользова-
тельском пространстве, объектом планирования являются процессы.
Что именно подвергать планированию — процессы или потоки, не является единствен-
ным вопросом, касающимся планирования. В однопроцессорной системе планирование
ведется в одном измерении. Здесь нужно многократно отвечать лишь на один вопрос:
какой поток должен быть запущен следующим? В мультипроцессорных системах
планирование ведется в двух измерениях. Планировщик должен решить, какой поток
запускать и на каком центральном процессоре следует это сделать. Это дополнительное
измерение существенно усложняет планирование на мультипроцессорах.
Другим усложняющим фактором является то, что в некоторых системах все потоки не
связаны друг с другом в силу принадлежности к разным процессам и не могут ничего
сделать друг с другом. В других системах они сведены в группы, где все они принад-
лежат одному и тому же приложению и работают вместе. Примером первого варианта
служит серверная система, в которой независимые друг от друга пользователи запуска-
ют независимые процессы. Потоки, относящиеся к разным процессам, не связаны друг
с другом, и работа каждого из них может планироваться без оглядки на все остальные.
Второй вариант регулярно проявляется в средах разработки программ. Большие системы
часто состоят из некоторого количества заголовочных файлов, содержащих макросы,
определения типов и объявления переменных, которые используются существующими
файлами кода. При изменении заголовочного файла должны быть перекомпилированы
все файлы кода, включающие данный заголовочный файл. Для управления процессом
разработки часто используется программа make. Будучи вызванной, программа make
приступает к компиляции только тех файлов кода, которые должны быть перекомпи-
лированы из-за изменений, происшедших в заголовочных файлах или файлах кода.
Объектные файлы, сохраняющие свою актуальность, заново не создаются.
Первоначальная версия программы make выполняла свою задачу последовательно, но
ее современные версии разработаны так, чтобы мультипроцессорные системы могли
запускать все компиляции одновременно. Если требуется провести десять компиляций,
то нет никакого смысла в планировании немедленного запуска девяти из них и откла-
дывании в долгий ящик последней компиляции, поскольку пользователь не будет счи-
тать работу завершенной до тех пор, пока не будет завершена последняя компиляция.
В таком случае имеет смысл рассматривать потоки, осуществляющие компиляцию как
группу, и принимать это во внимание при планировании их работы.
Кроме того, иногда полезно планировать работу потоков, осуществляющих интенсив-
ный обмен данными, скажем, в режиме «производитель — потребитель», не только
в одно и то же время, но и близко друг к другу в пространстве. Например, они могут по-
лучить преимущество от совместного использования кэшей. Подобно этому, в NUMA-
архитектурах может быть полезно дать им возможность доступа к той памяти, которая
будет находиться поблизости.
Разделение времени
Сначала давайте обратимся к случаю планирования независимых потоков, а потом
рассмотрим, как нужно планировать зависимые друг от друга потоки. Простейший
602
Глава 8. Многопроцессорные системы
алгоритм планирования для работы с независимыми потоками заключается в под-
держке для готовых к работе потоков единой структуры данных для всей системы,
возможно, в виде простого списка, но, скорее всего, в виде набора списков для потоков
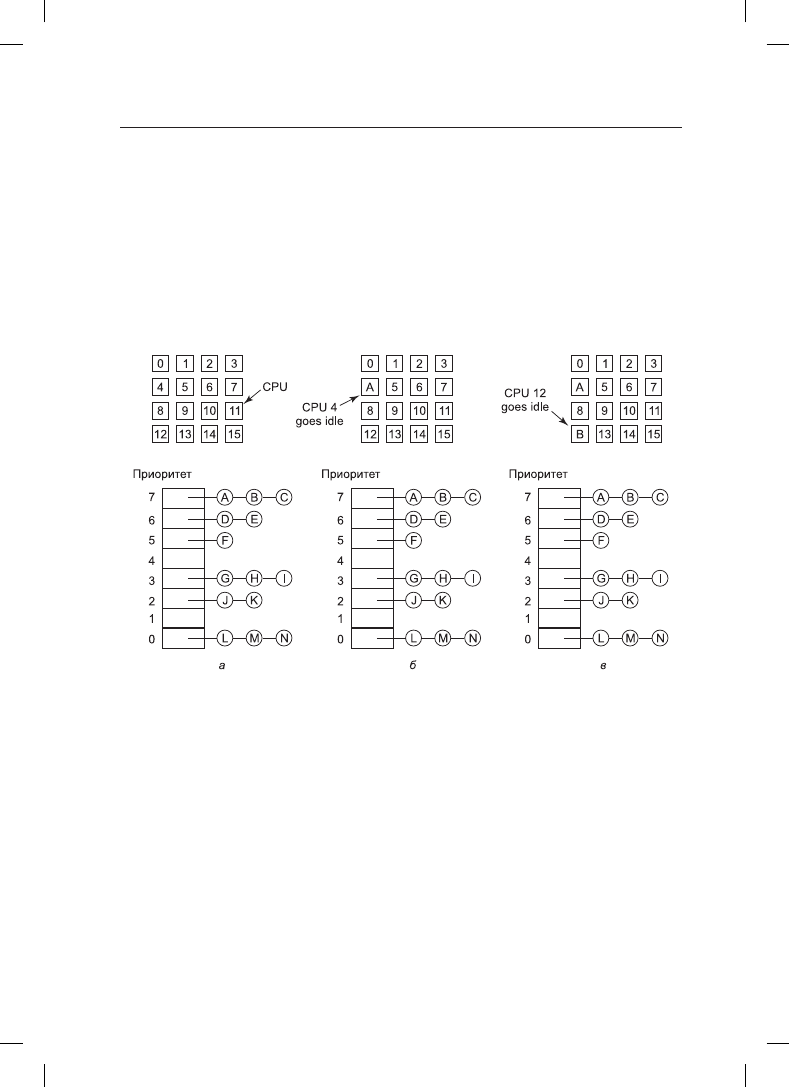
с разными приоритетами (рис. 8.12, а). Здесь показаны 16 центральных процессоров,
которые в данный момент заняты работой, и набор из готовых к работе 14 потоков, име-
ющих разные приоритеты. Первым процессором, завершившим свою работу (или стол-
кнувшимся с блокировкой своего потока), станет центральный процессор 4, который
заблокирует очереди планируемых потоков и выберет поток A, имеющий наивысший
приоритет (рис. 8.12, б). Затем освободится центральный процессор 12, который вы-
берет поток B (рис. 8.12, в). Пока потоки совершенно не связаны друг с другом, такого
рода планирование будет вполне разумным и легко реализуемым выбором.
Рис. 8.12. Использование единой структуры данных для планирования
работы мультипроцессора
Наличие единой структуры данных, используемой всеми центральными процессора-
ми, позволяет этим процессорам работать в режиме разделения времени, во многом
напоминающем такой режим на однопроцессорной системе. За счет этого также обе-
спечивается автоматическая сбалансированность нагрузки благодаря исключению
случаев, когда один центральный процессор простаивает, в то время как другие пере-
гружены. У этого подхода имеется два недостатка: потенциальная конкуренция за до-
ступ к структуре данных, используемой при планировании по мере роста количества
центральных процессоров, и обычные издержки при переключении контекста, когда
поток блокируется в ожидании завершения операций ввода-вывода.
Переключение контекста может происходить также по истечении кванта времени
потоков. На мультипроцессорах это явление имеет ряд свойств, отсутствующих
у однопроцессорной системы. Предположим, что поток удерживает спин-блокировку
на момент истечения кванта времени. Другие центральные процессоры, ожидающие
освобождения спин-блокировки, напрасно теряют время на циклические ожидания,

8.1. Мультипроцессоры
603
пока работа нашего потока не возобновится и он не освободит блокировку. На одно-
процессорных системах спин-блокировки используются довольно редко, так что если
процесс приостанавливается, удерживая при этом мьютекс, и запускается другой по-
ток, пытающийся заполучить мьютекс, он будет немедленно заблокирован, поэтому
впустую тратится совсем немного времени.
Чтобы обойти эту аномальную ситуацию, на некоторых системах используется
разумное планирование
(smart scheduling), при котором поток, получивший спин-
блокировку, устанавливает флажок, видимый всему процессу, чтобы показать, что
он в данный момент владеет спин-блокировкой (Zahorjan et al., 1991). Когда он осво-
бождает блокировку, флажок снимается. Тогда планировщик не останавливает поток,
удерживающий спин-блокировку, а дает ему еще немного времени на завершение вы-
полнения кода в критической области и освобождение блокировки.
Еще один вопрос, играющий роль при планировании, связан с тем фактом, что пока
все центральные процессоры находятся в равноправном положении, у некоторых цен-
тральных процессоров все же имеются некие привилегии. В частности, когда поток A
отработал длительное время на центральном процессоре k, то кэш-память этого процес-
сора будет заполнена блоками, необходимыми потоку A. Если A вскоре опять получит
возможность выполнения, то эффективнее всего он будет работать на центральном
процессоре k, поскольку в его кэше все еще могут находиться нужные потоку A блоки.
Наличие заранее загруженных блоков повысит число реализаций запросов за счет
кэша, а следовательно, и скорость работы потока. Кроме того, в TLB также могут со-
держаться нужные страницы, что сокращает количество отказов TLB.
На некоторых мультипроцессорах все это берется в расчет и используется так назы-
ваемое родственное планирование (affinity scheduling) (Vaswani and Zahorjan, 1991).
Основной замысел состоит в стремлении выполнять поток на том же самом централь-
ном процессоре, на котором он запускался в последний раз.
Один из способов поддержания такой родственной связи заключается в использова-
нии двухуровневого алгоритма планирования (two-level scheduling algorithm). При
создании поток назначается конкретному центральному процессору, к примеру тому,
у которого в данный момент наименьшая нагрузка. Это назначение потока централь-
ному процессору является верхним уровнем алгоритма. В результате такой политики
каждый центральный процессор располагает своим собственным набором потоков.
А непосредственное планирование потоков представляет собой нижний уровень
алгоритма. Он исполняется каждым центральным процессором по отдельности с ис-
пользованием приоритетов или каких-нибудь других средств выбора. Родственность
максимально поддерживается за счет стремления выполнять поток в течение всего
цикла его существования на одном и том же центральном процессоре. Но если у цен-
трального процессора отсутствуют потоки для запуска, он не простаивает, а забирает
поток у другого процессора.
У двухуровневого планирования есть три преимущества. Во-первых, оно распределяет
нагрузку среди имеющихся центральных процессоров примерно поровну. Во-вторых,
по возможности используется родственность содержимого кэша запускаемому потоку.
В-третьих, предоставление каждому центральному процессору своего собственного
списка готовых потоков сводит к минимуму конкуренцию за использование списков
готовности, поскольку попытки воспользоваться списком, принадлежащим другому
центральному процессору, предпринимаются довольно редко.
604
Глава 8. Многопроцессорные системы
Совместное использование пространства
Еще один общий подход к планированию работы мультипроцессора может использо-
ваться в том случае, когда потоки каким-то образом связаны друг с другом. Ранее уже
приводился пример параллельной работы программы make. Также часто бывает, что
у одного процесса есть несколько совместно работающих потоков. Например, если
потоки процесса часто обмениваются данными, то полезнее будет их выполнять одно-
временно. Планирование одновременной работы нескольких потоков на нескольких
центральных процессорах называется совместным использованием пространства
(space sharing).
Простейший алгоритм совместного использования пространства работает следующим
образом. Предположим, что одновременно создается целая группа взаимосвязанных по-
токов. На момент ее создания планировщик проверяет, имеется ли в его распоряжении
достаточное для всех этих потоков количество свободных центральных процессоров.
Если он располагает таким количеством, то каждому потоку назначается свой выделен-
ный (то есть не загруженный несколькими задачами) центральный процессор и все пото-
ки запускаются на выполнение. Если центральных процессоров не хватает, то ни один из
потоков не запускается до тех пор, пока не наберется их достаточное количество. Каждый
поток держится за свой центральный процессор до тех пор, пока не завершит свою работу,
и тогда центральный процессор возвращается в пул доступных процессоров. Если поток
блокируется в ожидании завершения операции ввода-вывода, он продолжает удерживать
центральный процессор, который простаивает до тех пор, пока поток не возобновит свою
работу. С появлением нового пакета потоков применяется тот же самый алгоритм.
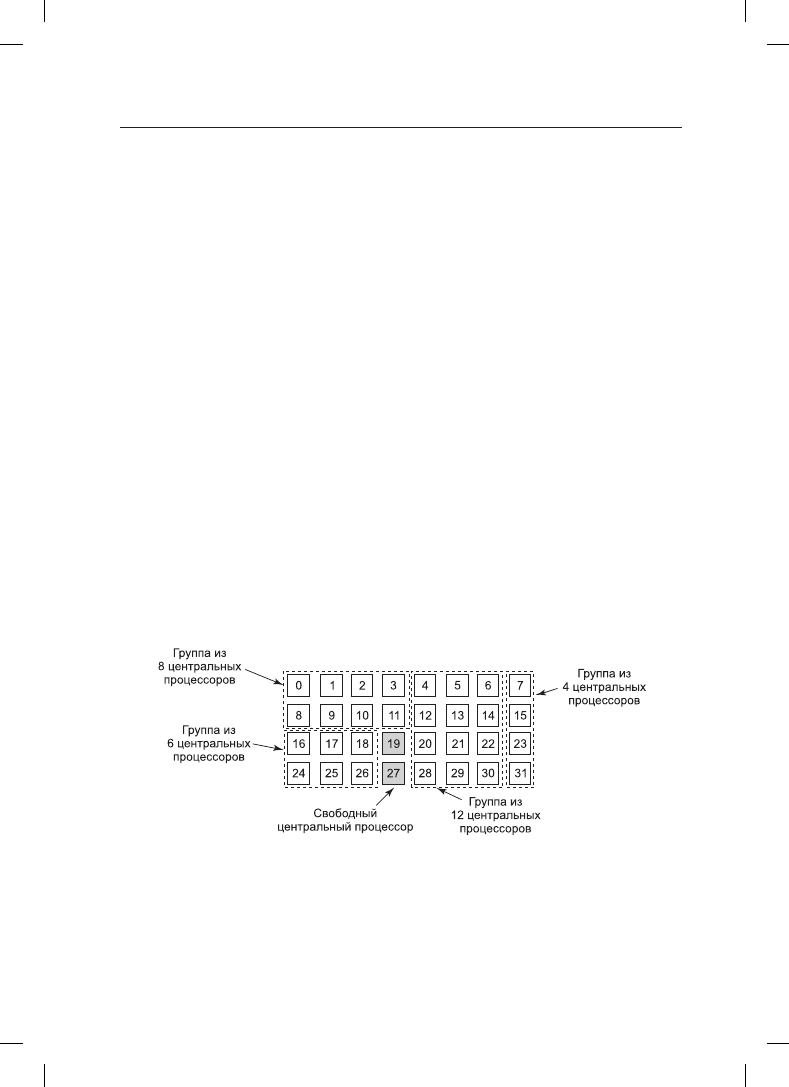
В любой момент времени набор центральных процессоров статически разбивается на
определенное количество секций, каждая из которых выполняет потоки одного про-
цесса. К примеру, на рис. 8.13 показаны секции, состоящие из 4, 6, 8 и 12 центральных
процессоров. Со временем количество и размеры секций будут изменяться по мере
создания новых и завершения и прекращения работы старых потоков.
Рис. 8.13. Набор из 32 центральных процессоров, разбитый на четыре секции
с двумя свободными процессорами
Периодически нужно принимать решения по планированию. На однопроцессорных
системах для пакетного планирования широко известен алгоритм, при котором первым
выполняется самое короткое задание. Аналогичный алгоритм для мультипроцессорной
системы заключается в выборе процесса, нуждающегося в наименьшем количестве тактов

8.1. Мультипроцессоры
605
центрального процессора, то есть потока, у которого среди других кандидатов наимень-
шее произведение количества центральных процессоров на время выполнения. Но на
практике эта информация доступна довольно редко, поэтому осуществление алгоритма
затруднено. Фактически исследования показали, что на практике алгоритм, при котором
первым обслуживается первый же готовый поток, превзойти трудно (Krueger et al., 1994).
В нашей модели разбиения на секции поток просто запрашивает некоторое количество
центральных процессоров и либо получает их все, либо вынужден ждать, пока они не
освободятся. Другой подход в работе с потоками заключается в активном управлении
степенью параллельности. Один из способов управления параллельностью преду-
сматривает использование центрального сервера, следящего за тем, какие потоки
выполняются и требуют выполнения и каковы их минимальные и максимальные по-
требности в центральных процессорах (Tucker and Gupta, 1989). Периодически каждое
приложение опрашивает центральный сервер, чтобы узнать, сколько центральных
процессоров оно может использовать. Затем оно подгоняет количество потоков под
количество доступных центральных процессоров. Например, веб-сервер может иметь
5, 10, 20 или любое другое количество параллельно запущенных потоков. Если у него
в какой-то момент времени имеется 10 потоков и возникает потребность в центральных
процессорах и ему предписывается сократить количество потоков до пяти, то когда
следующие пять потоков завершат свою текущую работу, они, вместо того чтобы полу-
чить новую работу, получают команду на выход. Эта схема позволяет очень динамично
менять размеры секций, чтобы они лучше соответствовали текущей нагрузке, чем при
использовании фиксированной системы, показанной на рис. 8.13.
Бригадное планирование
Явным преимуществом совместного использования пространства является исключе-
ние многозадачности, которое, в свою очередь, исключает издержки на контекстные
переключения. Но таким же явным недостатком является пустая трата времени, когда
центральный процессор заблокирован и вообще ничем не занят, пока снова не возник-
нут условия готовности к работе. Поэтому велся поиск алгоритма, который пытался
вести планирование как во времени, так и в пространстве, особенно для процессов,
создающих несколько потоков, которым обычно требовался взаимный обмен данными.
Чтобы разобраться с проблемой, которая может появиться, когда потоки процесса
планируются независимо друг от друга, рассмотрим систему с потоками A
0
и A
1
, при-
надлежащими процессу A, и потоками B
0
и B
1
, принадлежащими процессу B. Потоки
A
0
и B
0
выполняются в режиме разделения времени на центральном процессоре 0; по-
токи A
1
и B
1
выполняются в режиме разделения времени на центральном процессоре 1.
Потоки A
0
и A
1
нуждаются в частом обмене данными. Схема обмена данными состоит
в том, что A
0
посылает A
1
сообщение, затем A
1
посылает обратно A
0
ответ, после чего
происходит еще одна такая же последовательность обмена данными, часто встречаю-
щаяся в ситуациях «клиент — сервер». Предположим, что все так удачно сложилось
и сначала были запущены потоки A
0
и B
1
, как показано на рис. 8.14.
На кванте времени 0 A
0
посылает A
1
запрос, но A
1
не получает его, пока не будет запу-
щен в кванте времени 1 на отметке 100 мс. Он тут же посылает ответ, но A
0
не получает
его, пока он снова не будет запущен на отметке времени 200 мс. В итоге получается одна
последовательность «запрос — ответ» каждые 200 мс, а это не самый лучший результат
с точки зрения производительности.