Добавлен: 29.10.2018
Просмотров: 48182
Скачиваний: 190
606
Глава 8. Многопроцессорные системы
Рис. 8.14. Обмен данными между двумя запущенными не в фазе потоками,
принадлежащими процессу A
Решение этой проблемы заключается в бригадном планировании, являющемся раз-
витием идеи совместного планирования (Ousterhout, 1982). Бригадное планирование
состоит из трех частей:
1. Группа взаимосвязанных потоков планируется совместно.
2. Все члены бригады запускаются одновременно на разных центральных процессо-
рах, работающих в режиме разделения времени.
3. У всех членов бригады кванты времени начинаются и заканчиваются одновре-
менно.
Работоспособность бригадного планирования обеспечивается тем, что работа всех
центральных процессоров планируется синхронно. Это означает, что время делится на
дискретные кванты, как на рис. 8.14. К началу каждого нового кванта времени работа
всех центральных процессоров подвергается перепланировке и на каждом из них за-
пускается новый поток. К началу следующего кванта времени происходит следующее
событие планирования. В промежутках планирование не осуществляется. Если поток
блокируется, его центральный процессор простаивает до тех пор, пока не закончится
квант времени.
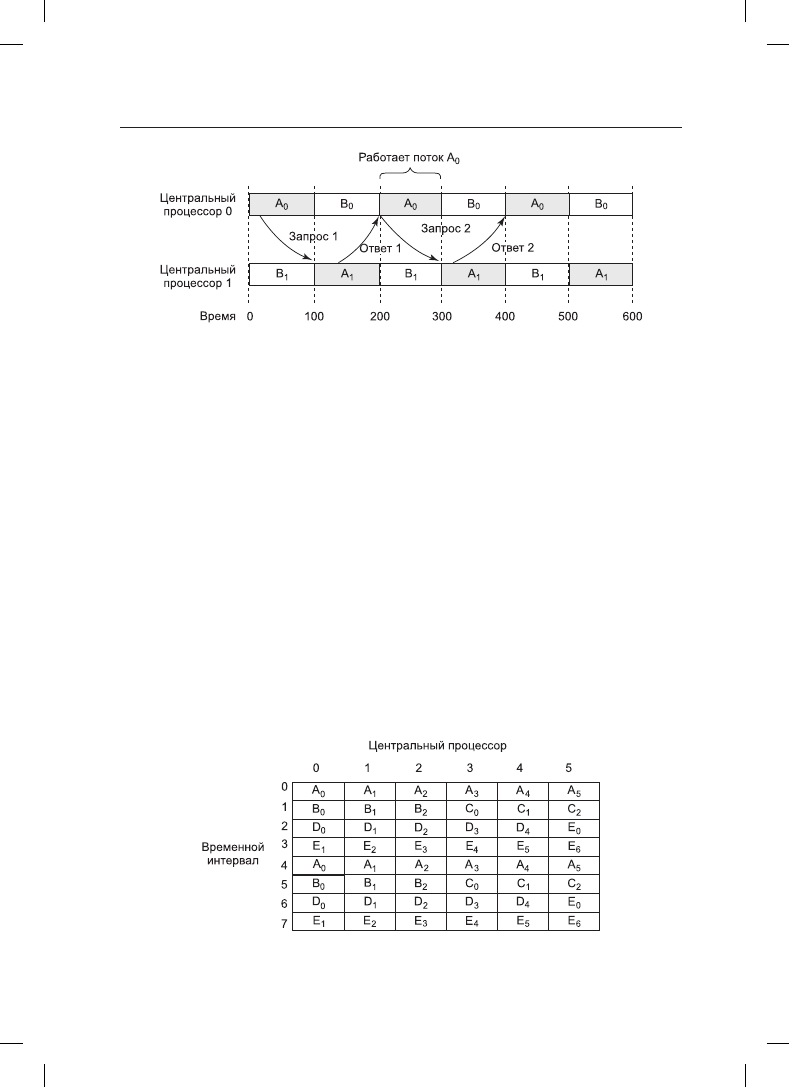
Пример работы бригадного планирования показан на рис. 8.15. На нем изображен муль-
типроцессор с шестью центральными процессорами, используемый пятью процессами,
Рис. 8.15. Бригадное планирование

8.2. Мультикомпьютеры
607
от A до E, с общим количеством готовых к работе потоков, равным 24. В течение кванта
времени 0 спланированы и запущены потоки от A
0
до A
6
. В течение кванта времени 1
спланированы и запущены потоки B
0
, B
1
, B
2
, C
0
, C
1
и C
2
. В течение кванта времени 2
запущены пять потоков, принадлежащих процессу D, и поток E
0
. Оставшиеся шесть
потоков, принадлежащих процессу E, запускаются в течение кванта времени 3. Затем
цикл повторяется, и квант времени 4 ничем не отличается от кванта времени 0 и т. д.
Замысел бригадного планирования заключается в совместной работе всех потоков
одного процесса, в одно и то же время, на различных центральных процессорах, при
которой сообщение, посланное одним из потоков другому, сразу же доходит до адресата
и тот может практически сразу же на него ответить. На рис. 8.15 все потоки процесса A
запускаются вместе в течение одного кванта времени, и за этот квант они могут послать
и получить в ответ огромное количество сообщений, исключая тем самым возможность
возникновения проблемы, показанной на рис. 8.14.
8.2. Мультикомпьютеры
Популярность и привлекательность мультипроцессоров связана с тем, что они пред-
лагают простую модель обмена данными, при которой все центральные процессоры
совместно используют общую память. Процессы могут записывать в память сообщения,
которые затем могут читаться другими процессами. Синхронизация может быть реа-
лизована за счет применения мьютексов, семафоров, мониторов и других устоявшихся
технологий. Единственная загвоздка заключается в сложности построения больших
мультипроцессорных систем и, как следствие, их дороговизне. А очень большие не-
возможно создать ни за какую цену. Поэтому при необходимости масштабирования
на большое количество центральных процессоров нужно что-то еще.
Чтобы обойти эту проблему, была проведена масса исследований в области мульти-
компьютеров, представляющих собой тесно связанные друг с другом центральные
процессоры, не имеющие совместно используемой памяти. У каждого из них, как
показано на рис. 8.1, б, есть собственная оперативная память. Эти системы также из-
вестны под массой разных других имен, включая кластерные компьютеры (cluster
computers) и COWS (Clusters of Workstations — кластеры рабочих станций). Службы
облачных вычислений, поскольку они вынуждены быть большими, всегда строятся на
мультикомпьютерах.
Мультикомпьютер создать нетрудно, потому что основным его компонентом выступает
упрощенный персональный компьютер без клавиатуры, мыши или монитора, но с вы-
сокоскоростной сетевой картой. Разумеется, секрет достижения высокой производи-
тельности состоит в разработке удачной схемы соединений и интерфейсной карты. Эта
проблема полностью аналогична проблеме создания общей памяти в мультипроцессоре
(см., например, рис. 8.1, б). Но цель состоит в отправке сообщений за время, измеряемое
микросекундами, а не в доступе к памяти за наносекунды, поэтому достичь ее проще,
дешевле и легче. В следующих разделах сначала будет дан краткий обзор аппаратного
обеспечения мультикомпьютеров, особенно той его части, которая относится к схеме
соединений. Затем мы перейдем к программному обеспечению — сначала рассмотрим
низкоуровневые, а потом и высокоуровневые коммуникационные программы. Также
будут рассмотрены способы реализации общей памяти на тех системах, где она отсутству-
ет. И наконец, будут рассмотрены вопросы планирования и балансирования нагрузки.

608
Глава 8. Многопроцессорные системы
8.3.1. Аппаратное обеспечение мультикомпьютеров
Базовый узел мультикомпьютера состоит из центрального процессора, памяти, сетевого
интерфейса, иногда в нем есть также жесткий диск. Узел может быть собран в стан-
дартном корпусе персонального компьютера, и в нем практически всегда отсутствуют
монитор, клавиатура и мышь. Иногда такая конфигурация называется безголовой ра-
бочей станцией
(headless workstation), потому что перед ней нет головы пользователя.
По логике, рабочая станция с человеком в качестве пользователя должна называться
рабочей станцией с головой, но почему-то она так не называется. В некоторых случаях
вместо одного центрального процессора этот персональный компьютер может содер-
жать двух- или четырехпроцессорную плату, на которой могут быть установлены двух-,
четырех- или восьмиядерные процессоры, но для простоты изложения материала мы
будем считать, что у каждого узла имеется один центральный процессор. Довольно
часто мультикомпьютер составляется из сотен или даже тысяч связанных друг с другом
узлов. Далее будет дан краткий обзор организации аппаратного обеспечения таких
систем.
Технология соединений
У каждого узла имеется карта сетевого интерфейса, от которой отходит один или два
электрических (или оптоволоконных) кабеля. Эти кабели подключены либо к другим
узлам, либо к коммутаторам. В небольших системах может быть один коммутатор,
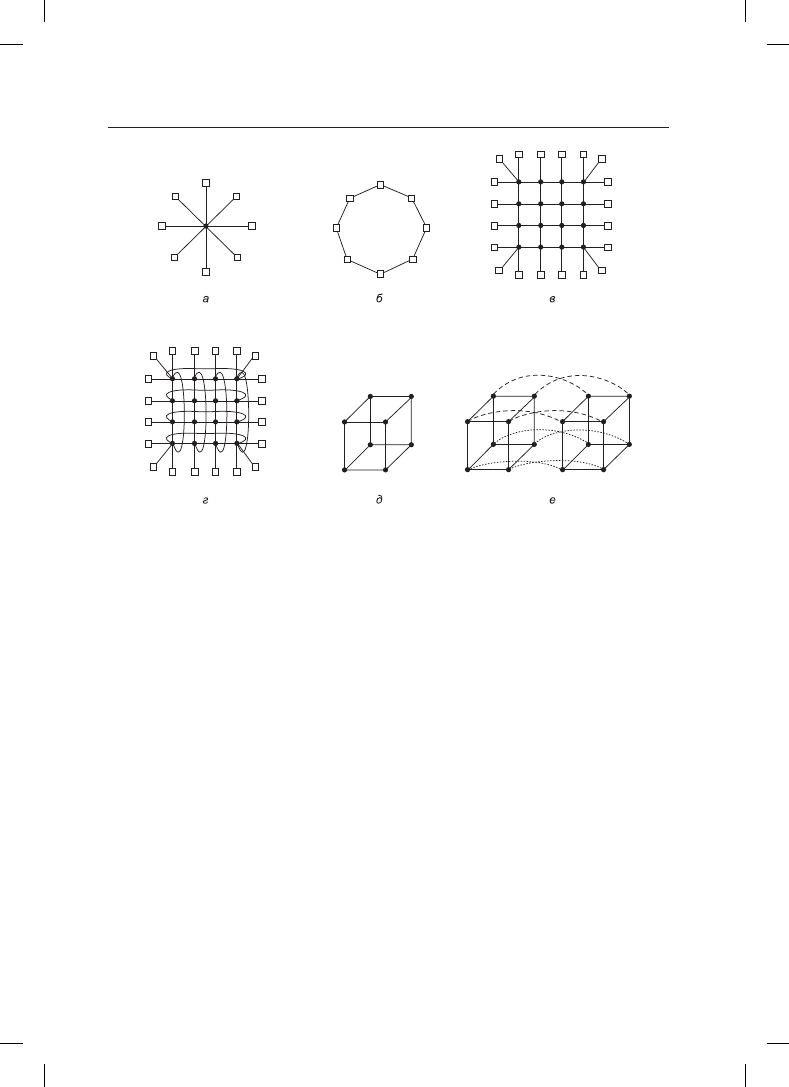
к которому по топологии «звезда» (рис. 8.16, а) подключены все узлы. Эта топология
используется в современных коммутируемых сетях Ethernet.
В качестве альтернативы схеме с одним коммутатором узлы могут выстраиваться
в кольцо, при этом из сетевой интерфейсной карты будут выходить два кабеля, один —
к левому, а другой — к правому узлу (рис. 8.16, б). Как видно из рисунка, при такой
топологии коммутаторы не нужны.
Многие коммерческие системы используют двумерную схему решетки (grid) или ячеи-
стой сети
(mesh (рис. 8.16, в). Она обладает высокой степенью упорядоченности и легко
наращивается до больших размеров. Одной из ее характеристик является диаметр —
самый длинный путь между любыми двумя узлами, который растет пропорционально
значению квадратного корня от количества узлов. Вариантом решетки является двой-
ной тор
(рис. 8.16, г), где решетка имеет соединенные грани. Эта топология не только
более отказоустойчива, но и имеет меньший диаметр, потому что противоположные
узлы теперь всего в двух шагах друг от друга.
Топология куб (рис. 8.16, д) имеет правильную трехмерную структуру. На рисунке по-
казан куб 2 × 2 × 2, но в более общем виде он может быть представлен как куб k × k × k.
На рис. 8.16, е показан четырехмерный куб, построенный из двух трехмерных кубов
с соединенными соответствующими узлами.
За счет дублирования структуры (рис. 8.16, е) и соединения соответствующих узлов,
чтобы получить форму блока из четырех кубов, можно создать пятимерный куб. Для
перехода в шестимерную форму можно повторить блок из четырех кубов и соединить
друг с другом соответствующие узлы и т. д. Сформированный таким образом n-мерный
куб называется гиперкубом. Эта топология используется на многих параллельных ком-
пьютерах, поскольку рост диаметра имеет линейную зависимость от роста размерности.
Иными словами, диаметр вычисляется как логарифм по основанию 2 от числа узлов.
8.2. Мультикомпьютеры
609
Рис. 8.16. Различные топологии связи: а — с одним коммутатором; б — кольцо; в — решетка;
г — двойной тор; д — куб; е — четырехмерный куб
К примеру, 10-мерный гиперкуб имеет 1024 узла, однако диаметр у него равен лишь
10, что придает ему великолепные характеристики с низкими задержками. Обратите
внимание на то, что в отличие от него 1024 узла, выстроенные в решетку 32 × 32, имеют
диаметр, равный 62, что более чем в шесть раз хуже аналогичного показателя гиперку-
ба. Цена, которую приходится платить за небольшой диаметр, выражается в большом
числе ответвлений и, следовательно, большом количестве связей (и их стоимости),
которых у гиперкуба значительно больше.
В мультикомпьютерах используются две разновидности схем коммутации. В первой
из них каждое сообщение разбивается (средствами пользовательской программы или
сетевого интерфейса) на части некой максимальной длины, которые называются па-
кетами
. Коммутационная схема, называемая коммутацией пакетов с промежуточным
хранением
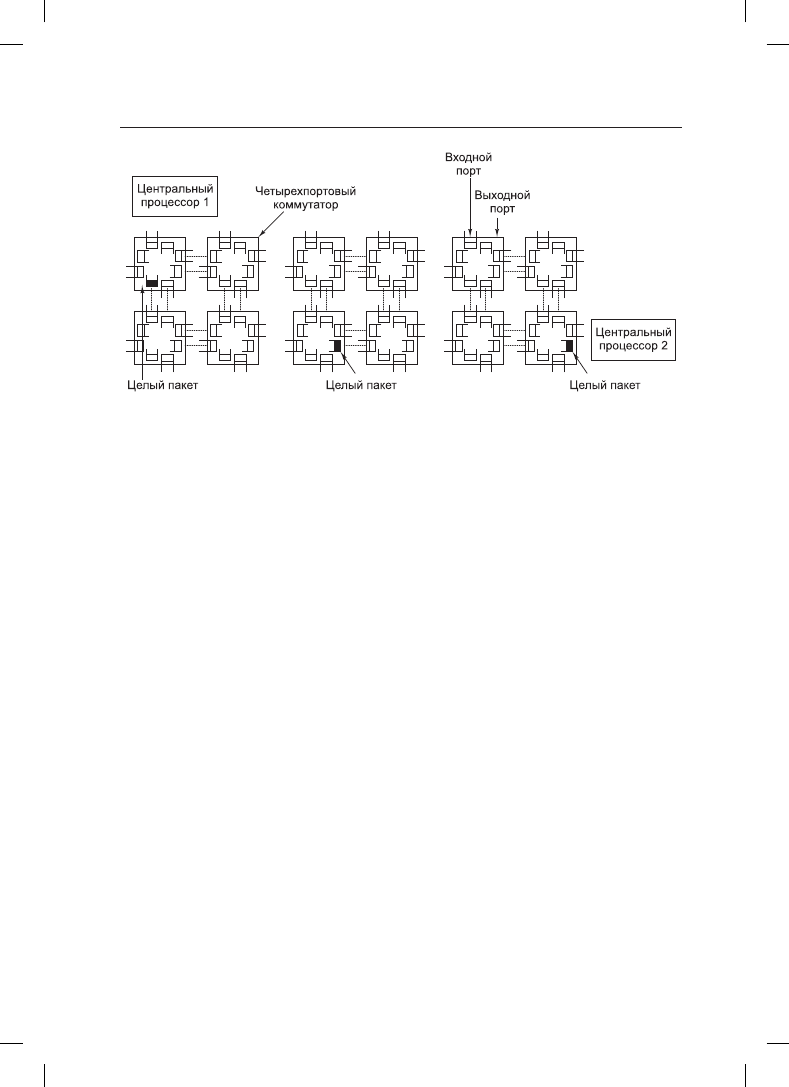
(store-and-forward packet switching), состоит из пакета, доставляемого на
первый коммутатор интерфейсной сетевой платой узла-источника (рис. 8.17, а). Дан-
ные поступают побитно, и когда во входной буфер прибудет весь пакет, он копируется
на линию, ведущую к следующему коммутатору на маршруте доставки (рис. 8.17, б).
Когда пакет (рис. 8.17, в) прибывает на коммутатор, подключенный к узлу-получателю,
он копируется на карту сетевого интерфейса этого узла и в конечном счете попадает
в его оперативную память.
При всей гибкости и эффективности схемы коммутации пакетов с промежуточным
хранением у нее есть проблема нарастающего времени ожидания (задержки) при
передаче пакетов по схеме соединений. Предположим, что время перемещения пакета
по одному транзитному участку, показанному на рис. 8.17, составляет T наносекунд.
Поскольку на пути от центрального процессора 1 до центрального процессора 2 пакет
610
Глава 8. Многопроцессорные системы
Рис. 8.17. Коммутация пакетов с промежуточным хранением
должен быть скопирован четыре раза (на коммутаторы A, C, D и, наконец, на получа-
ющий его центральный процессор), и копирование не может осуществляться, пока не
будет завершено предыдущее копирование, задержка схемы соединений составит 4T.
Один из выходов из такого положения состоит в создании сети, в которой пакет может
быть логически разделен на небольшие части. Как только первая часть поступит на
коммутатор, она может быть послана дальше еще до того, как на этот коммутатор при-
будет окончание пакета. По-видимому, такую часть можно уменьшить до одного бита.
Другой режим коммутации называется коммутацией каналов (circuit switching) и за-
ключается в предварительной установке маршрута через все коммутаторы к коммутатору
назначения. Как только маршрут будет установлен, биты без задержки с максимально
возможной скоростью проследуют по всему маршруту от источника к получателю.
Никакой буферизации на промежуточных коммутаторах не осуществляется. Для ком-
мутации каналов требуется установочный этап, на который уходит определенное время,
но когда этот этап завершится, передача данных ведется быстрее. После того как пакет
будет отправлен, маршрут может быть снова закрыт. При использовании разновидности
коммутации каналов, называемой маршрутизацией способом коммутации каналов
(wormhole routing), каждый пакет разбивается на подпакеты, что позволяет первому
подпакету приступить к перемещению даже до того, как будет выстроен весь маршрут.
Сетевые интерфейсы
Все узлы в мультикомпьютере имеют съемную плату, на которой находятся средства
подключения узла к схеме соединений, которая и формирует мультикомпьютер. Кон-
струкция этих плат и способ их подключения к основному центральному процессору
и оперативной памяти имеют существенное значение для операционной системы.
В этом разделе будет дан краткий обзор некоторых связанных с этим вопросов, который
частично основан на работе Bhoedjang (2000).
Фактически на всех мультикомпьютерах интерфейсная плата содержит объемную
оперативную память для хранения исходящих и входящих пакетов. Как правило,
перед передачей на первый коммутатор исходящий пакет должен быть скопирован
в оперативную память интерфейсной платы. Такая конструкция продиктована тем, что