Файл: Курсовая Выполнить быструю сортировку (quicksort) массива, используя парадигмы программирования OpenMP и MPI..docx
ВУЗ: Пермский национальный исследовательский политехнический университет
Категория: Курсовая работа
Дисциплина: Вычислительная техника
Добавлен: 15.11.2018
Просмотров: 2361
Скачиваний: 43
СОДЕРЖАНИЕ
Парадигма программирования OpenMP
Трансляция и выполнение OpenMP-программ
Парадигма программирования MPI
Трансляция и выполнение MPI-программ
Программный код файла utils.* (Функции для расчета)
Программный код файла g2draw.*( функции для рисования графика времени расчета от размера массива).
Реализация с использованием OpenMP
Программный код файла utils.* (Функции для расчета)
Программный код файла g2draw.*( функции для рисования графика времени расчета от размера массива).
const int plotYMargin = 50;
const int xUpperBound = getUpperBound( xValues[ xValuesQty - 1]);
char7 xNumbers[ NUMBERS_NUM ];
generateXNumbers( xUpperBound, xNumbers );
double yUpperBound = getUpperBound( getMaxValue( yValues, xValuesQty*yValuesQty ) );
char7 yNumbers[ NUMBERS_NUM ];
generateYNumbers( yUpperBound, yNumbers );
double xScale = (double)plotXSize/(double)xUpperBound;
double yScale = (double)plotYSize/yUpperBound;
int window = g2_open_X11( plotXSize + 2*plotXMargin, plotYSize + 2*plotYMargin );
coordinatePlane(window, xNumbers, yNumbers, plotXSize, plotYSize, plotXMargin, plotYMargin);
int i = 0;
for ( ; i < yValuesQty; ++i)
{
char title[8];
sprintf( title, "%d", categoryValues[ i ]);
pointsOnPlane(window, xValues, &yValues[ i*xValuesQty], xValuesQty, plotXMargin, plotXMargin, xScale, yScale, 3*(i + 1), title);
}
g2_string(window,250, 5, "OpenMP QuickSort result");
getchar();
g2_close(window);
}
void coordinatePlane(int window, char7* xNumbers, char7* yNumbers, int plotXSize, int plotYSize, int plotXMargin, int plotYMargin)
{
int x0 = plotXMargin;
int y0 = plotYMargin;
int X = plotXSize;
int Y = plotYSize;
int dx = plotXSize/ NUMBERS_NUM;
int dy = plotYSize/ NUMBERS_NUM;
int rx = 5;
int ry = 5;
int i = y0;
int k = -1;
for ( ; i <= Y + y0 ; i += dy, ++k)
{
g2_line(window,x0-rx,i,x0+X,i);
if ( k == -1 )
{
g2_string(window,x0/4,i, "0");
}
else
{
g2_string(window,x0/4,i, yNumbers[ k ]); // y-axis numbers
}
}
g2_line(window,x0,y0,x0,y0+Y); // y-axis
g2_string(window,50, 570, "Time(sec.)");
int j = y0;
k = -1;
for ( ; j <= X + x0 ; j += dx, ++k)
{
g2_line(window,j,y0-ry,j,y0); // horizontal lines with marks; for j = y0 - x-axis
if ( k == -1 )
{
g2_string(window, (j == y0) ? j : (j - dx/4) , y0/2, "0");
}
else
{
g2_string(window, (j == y0) ? j : j , y0/2, xNumbers[ k ]);
}
}
g2_string(window,500, 10, "Threads(qty.)");
}
void pointsOnPlane(int window, int* xValues, double* yValues, int valuesQty, int x0, int y0, double xScale, double yScale, int color, const char* title)
{
g2_pen(window, color);
int prevX = 0;
int prevY = 0;
int i = 0;
for ( ; i < valuesQty; ++i)
{
int x = (double) xValues[i] * xScale;
int y = yValues[i] * yScale;
g2_filled_circle(window, x0 + x, y0 + y, 2);
if ( i > 0 )
{
g2_line(window,x0 + prevX, y0 + prevY, x0 + x, y0 + y );
}
prevX = x;
prevY = y;
}
g2_string(window, x0 + prevX + 10, y0 + prevY, title);
}
double getMaxValue( double* arr, int arrSize)
{
double result = arr[0];
int i = 1;
for (; i < arrSize; ++i )
{
if ( result < arr[i] )
{
result = arr[i];
}
}
return result;
}
double getUpperBound( double value )
{
int deg = 0;
if ( value > 10 )
{
while( value < 10. && value > 0.1 )
{
value /= 10.;
deg++;
}
}
else if ( value < 1.)
{
while( value < 1. )
{
value *= 10.;
deg--;
}
deg++;
}
else
{
deg = 1;
}
double mult = ( value > 5. ) ? 1. : .5;
return mult*pow( 10., deg);
}
void generateXNumbers( int xBound, char7* xNumbers )
{
int i = 0;
int dx = xBound/NUMBERS_NUM;
for ( ; i < NUMBERS_NUM; ++i )
{
sprintf( xNumbers[i], "%d", (i+1)*dx);
}
return ;
}
void generateYNumbers( double yBound, char7* yNumbers )
{
int i = 0;
double dy = yBound/NUMBERS_NUM;
for ( ; i < NUMBERS_NUM; ++i )
{
sprintf( yNumbers[i], "%1.3f", (i+1)*dy);
}
return ;
}
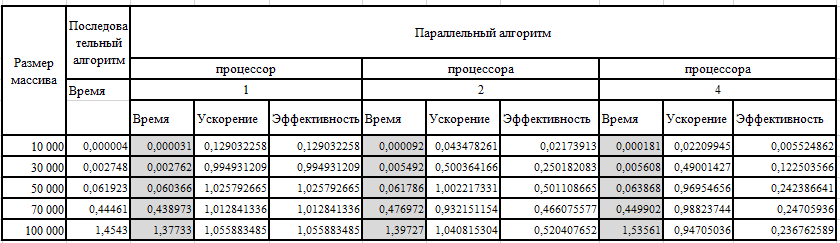
Таблица 2 – Результаты вычислительных экспериментов
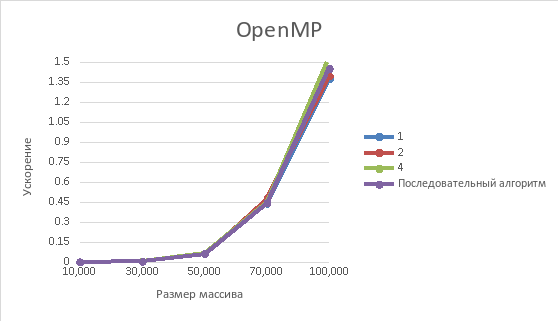
Рисунок 5 – Зависимость времени выполнения от размеров массива
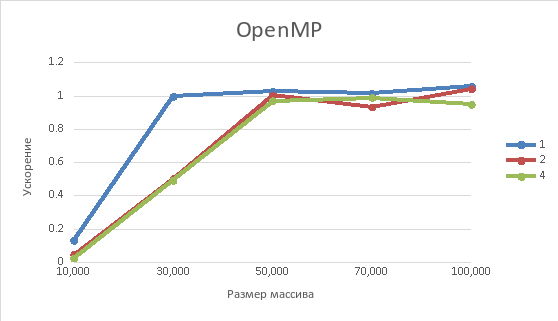
Рисунок 6 – Зависимость ускорения от размеров массива
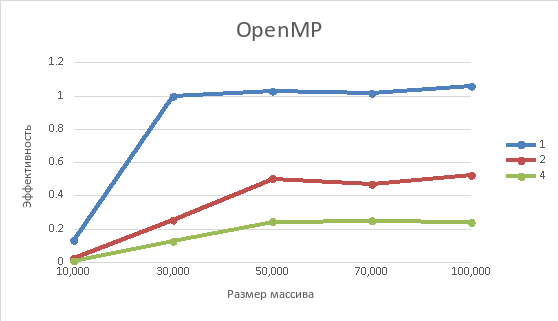
Рисунок 7 – Зависимость эффективности от размера массива
Заключение
В результате выполнения курсовой работы был реализован алгоритм быстрой сортировки для массивов размерностью 10000, 30000, 50000, 70000, 100000.
После тестирования алгоритмов были получены результаты экспериментов, представленные в таблицах 1 и 2, а также для наглядности сформированы графики по времени выполнения алгоритма, ускорению и эффективности. Из них следует, что параллельный алгоритм с использованием библиотеки OpenMP работает эффективнее, чем алгоритм с использованием MPI.
Тестирование алгоритмов были проведены для массивов размерностью 10000, 30000, 50000, 70000, 100000.
Список литературы:
-
Метод быстрой сортировки quicksort. [Электронный ресурс]. URL: http://www.studfiles.ru/preview/2157429/page:2/. (дата обращения 11.09.2016).
-
Две парадигмы параллельного программирования [Электронный ресурс]. URL: http://www.intuit.ru/EDI/22_05_15_7/1432246798-28527/tutorial/450/objects/1/files/01.pdf. (дата обращения 12.09.2016).