Файл: Курсовая Выполнить быструю сортировку (quicksort) массива, используя парадигмы программирования OpenMP и MPI..docx
ВУЗ: Пермский национальный исследовательский политехнический университет
Категория: Курсовая работа
Дисциплина: Вычислительная техника
Добавлен: 15.11.2018
Просмотров: 2352
Скачиваний: 43
СОДЕРЖАНИЕ
Парадигма программирования OpenMP
Трансляция и выполнение OpenMP-программ
Парадигма программирования MPI
Трансляция и выполнение MPI-программ
Программный код файла utils.* (Функции для расчета)
Программный код файла g2draw.*( функции для рисования графика времени расчета от размера массива).
Реализация с использованием OpenMP
Программный код файла utils.* (Функции для расчета)
Программный код файла g2draw.*( функции для рисования графика времени расчета от размера массива).
Практическая часть
Расчет производиться для массивов размеров 10000, 30000, 50000, 70000, 100000.
Ниже представлен код, реализующий алгоритм в соответствии с поставленной задачей:
Реализация с использованием MPI:
Программный код файла main.с
#include <stdio.h>
#include <stdlib.h>
#include <mpi.h>
#include "utils.h"
#include "g2draw.h"
#define QTY_ARRAY_SIZE 5
int main(int argc, char ** argv)
{
int qtyArray[ QTY_ARRAY_SIZE ] = { 10000, 30000, 50000, 70000, 100000 };
double timeArray[ QTY_ARRAY_SIZE ];
int procRank, procGroupSize;
MPI_Init(&argc, &argv);
MPI_Comm_size(MPI_COMM_WORLD, &procGroupSize);
MPI_Comm_rank(MPI_COMM_WORLD, &procRank);
int i = 0;
for ( ; i < QTY_ARRAY_SIZE; ++i )
{
double sortTime = quickSortMPI( procGroupSize, procRank, qtyArray[i] );
if ( procRank == 0 )
{
timeArray[i] = sortTime;
printf("Time required was %lf seconds for %d.\n", timeArray[i], qtyArray[i] );
}
}
if ( procRank == 0 )
{
draw_result( qtyArray, timeArray, QTY_ARRAY_SIZE, procGroupSize );
}
MPI_Finalize();
return 0;
}
Программный код файла utils.* (Функции для расчета)
#include "../qs_mpi/utils.h"
#include <stdlib.h>
#include <stdio.h>
#include <mpi.h>
void quicksort(int * arr, int lo, int hi)
{
if(lo < hi)
{
int p = partition(arr, lo, hi);
quicksort(arr, lo, p - 1);
quicksort(arr, p + 1, hi);
}
}
int partition(int * arr, int lo, int hi)
{
int pivotIdx = choosePivot(arr, lo, hi);
int pivotVal = arr[pivotIdx];
swap(&arr[pivotIdx], &arr[hi]);
int storeIdx = lo;
int i = lo;
for( ; i < hi; i++)
{
if(arr[i] < pivotVal)
{
swap(&arr[i], &arr[storeIdx]);
storeIdx++;
}
}
swap(&arr[storeIdx], &arr[hi]);
return storeIdx;
}
void swap(int * x, int * y)
{
int temp = *x;
*x = *y;
*y = temp;
}
int choosePivot(int * arr, int lo, int hi)
{
int mid = (lo+hi)/2;
if( arr[lo] > arr[hi] )
{
int temp = lo;
lo = hi;
hi = temp;
}
if( arr[lo] > arr[mid] )
{
int temp = mid;
mid = lo;
lo = temp;
}
if( arr[mid] > arr[hi] )
{
int temp = mid;
mid = hi;
hi = temp;
}
return mid;
}
void showarray( int* arr, int size, const char* msg, int rank)
{
printf("%s (process = %d): ", msg, rank);
int i = 0;
for( ; i < size; i++)
{
printf("%d ", arr[i]);
}
printf("\n");
}
void showarrayidx( int* arr, int lowIdx, int highIdx, const char* msg, int rank)
{
printf("%s (process = %d): from %d to %d = ", msg, rank, lowIdx, highIdx);
int i = lowIdx;
for( ; i < highIdx; i++)
{
printf("%d ", arr[i]);
}
printf("\n");
}
void fillarray( int* arr, int size, int rank)
{
srand(123456 + 10000*rank);
int i = 0;
for( ; i < size; i++)
{
arr[i] = -1000 + rand()%RANGE;
}
}
int getPivotIdx( int * arr, int arrSize, int pivot)
{
int storePivotIdx = 0;
int i = 0;
for( ; i < arrSize; i++)
{
if (arr[i] < pivot )
{
swap(&arr[i], &arr[storePivotIdx]);
storePivotIdx++;
}
}
return storePivotIdx;
}
int *mergeArrWithRecvUpper(int *arr, int *recvBuff, int recvSize, int storePivotIdx, int *newArrSize)
{
int* newArr = (int *) malloc(sizeof(int)*( recvSize + storePivotIdx ));
int i = 0;
for( ; i < storePivotIdx; i++)
newArr[i] = arr[i];
int j = 0;
for( i = storePivotIdx; i < recvSize + storePivotIdx; i++, j++)
newArr[i] = recvBuff[j];
free((void *) arr);
arr = newArr;
newArr = 0;
*newArrSize = recvSize + storePivotIdx;
return arr;
}
int *mergeArrWithRecvLower(int *arr, int *recvBuff, int recvSize, int storePivotIdx, int *newArrSize)
{
int* newArr = (int *) malloc(sizeof(int)*( recvSize + ( *newArrSize - storePivotIdx)));
int j = 0;
int i = storePivotIdx;
for( ; i < *newArrSize; i++, j++)
{
newArr[j] = arr[i];
}
for(j = 0, i = *newArrSize - storePivotIdx; i < recvSize + ( *newArrSize - storePivotIdx); i++, j++)
{
newArr[i] = recvBuff[j];
}
free((void *) arr);
arr = newArr;
newArr = 0;
*newArrSize = recvSize + ( *newArrSize - storePivotIdx);
return arr;
}
int *getRecvArray(int *recvBuffer, int recvSize, int source, int tag)
{
free((void *) recvBuffer);
recvBuffer = (int *) malloc(sizeof(int)*recvSize);
MPI_Request request;
MPI_Status status;
MPI_Irecv( recvBuffer, recvSize, MPI_INT, source, tag, MPI_COMM_WORLD, &request);
MPI_Wait(&request, &status);
return recvBuffer;
}
int arraysorttest( int* arr, int size)
{
int i = 1;
for( ; i < size; i++)
{
if ( arr[i -1] > arr[i])
{
return 0;
}
}
return 1;
}
double quickSortMPI(const int size, const int rank, const int arrsize)
{
int finalArraySize = arrsize;
int * arr = (int *) malloc(sizeof(int) * finalArraySize/size);
int * recvBuffer = (int *) malloc(sizeof(int) * finalArraySize/size);
fillarray( arr, finalArraySize/size, rank);
quicksort( arr, 0, finalArraySize/size - 1);
double start, end;
MPI_Status status;
int pivot;
if(rank == 0)
{
start = MPI_Wtime();
pivot = choosePivot(arr, 0, finalArraySize/size-1);
}
MPI_Bcast(&pivot, 1, MPI_INT, 0, MPI_COMM_WORLD);
int storePivotIdx = 0;
int arrSize = finalArraySize/size;
int partner, recvSize;
for( partner = size/2; partner > 0; partner = partner >> 1)
{
storePivotIdx = getPivotIdx( arr, arrSize, pivot);
MPI_Request request, requestSend;
if ( (rank / partner) % 2 == 0 )
{
int upperPivotArrSize = arrSize - storePivotIdx;
MPI_Isend(&upperPivotArrSize, 1, MPI_INT, rank+partner, partner+size, MPI_COMM_WORLD, &requestSend);
recvSize = 0;
MPI_Irecv(&recvSize, 1, MPI_INT, rank+partner, partner+size, MPI_COMM_WORLD, &request);
MPI_Wait(&request, &status);
if ( upperPivotArrSize > 0)
{
MPI_Isend( arr + storePivotIdx, upperPivotArrSize, MPI_INT, rank + partner, partner,MPI_COMM_WORLD, &requestSend);
}
if ( recvSize > 0 )
{
recvBuffer = getRecvArray( recvBuffer, recvSize, rank + partner, partner);
}
}
else
{
int lowerPivotArrSize = storePivotIdx;
MPI_Isend(&lowerPivotArrSize, 1, MPI_INT, rank-partner, partner+size, MPI_COMM_WORLD, &requestSend);
recvSize = 0;
MPI_Irecv(&recvSize, 1, MPI_INT, rank-partner, partner+size, MPI_COMM_WORLD, &request);
MPI_Wait(&request, &status);
if ( storePivotIdx > 0 )
{
MPI_Isend( arr, lowerPivotArrSize, MPI_INT, rank - partner, partner, MPI_COMM_WORLD, &requestSend);
}
if ( recvSize > 0 )
{
recvBuffer = getRecvArray( recvBuffer, recvSize, rank - partner, partner);
}
}
MPI_Barrier(MPI_COMM_WORLD);
if(recvSize > 0)
{
if((rank / partner) % 2 == 0)
{
arr = mergeArrWithRecvUpper( arr, recvBuffer, recvSize, storePivotIdx, &arrSize );
}
else
{
arr = mergeArrWithRecvLower( arr, recvBuffer, recvSize, storePivotIdx, &arrSize );
}
}
else
{
arrSize = 0;
}
if(rank % partner == 0)
{
pivot = choosePivot(arr, 0, arrSize-1);
int i = 1;
for( ; i < partner; i++)
{
MPI_Send(&pivot, 1, MPI_INT, rank+i, partner+1, MPI_COMM_WORLD);
}
}
else
{
MPI_Recv(&pivot, 1, MPI_INT, partner*(rank/partner), partner+1, MPI_COMM_WORLD, MPI_STATUS_IGNORE);
}
}
if(arrSize > 0)
{
quicksort(arr, 0, arrSize-1);
}
int * sizeArr, * fullArr, * displacement;
if(rank == 0)
{
sizeArr = (int *) malloc(sizeof(int)*size);
fullArr = (int *) malloc(sizeof(int)* finalArraySize);
displacement = (int *) malloc(sizeof(int)*size);
}
MPI_Gather(&arrSize, 1, MPI_INT, sizeArr, 1, MPI_INT, 0, MPI_COMM_WORLD);
if ( rank == 0 )
{
int i = 0;
displacement[0] = 0;
for(i = 1; i < size; i++)
{
displacement[i] = sizeArr[i-1] + displacement[i-1];
}
}
MPI_Gatherv(arr, arrSize, MPI_INT, fullArr, sizeArr, displacement, MPI_INT, 0, MPI_COMM_WORLD);
MPI_Barrier(MPI_COMM_WORLD);
if ( arrSize > 0 )
{
free((void *) arr);
}
if ( rank == 0 )
{
printf("Final Array with size %d test return %s. \n", finalArraySize, (arraysorttest( fullArr, finalArraySize)) ? "SUCCESS" : "FAIL");
end = MPI_Wtime();
free((void *) fullArr);
free((void *) sizeArr);
free((void *) displacement);
}
return end-start;
}
Программный код файла g2draw.*( функции для рисования графика времени расчета от размера массива).
#include "g2draw.h"
#include <stdio.h>
#include <g2.h>
#include <g2_X11.h>
#define NUMBERS_NUM 10
typedef char char7[7];
double getUpperBound( double value );
double getMaxValue( double* arr, int arrSize);
void generateXNumbers( int xBound, char7* xNumbers );
void generateYNumbers( double yBound, char7* yNumbers );
void coordinatePlane(int window, char7* xNumbers, char7* yNumbers, int plotXSize, int plotYSize, int plotXMargin, int plotYMargin);
void pointsOnPlane(int window, int* xValues, double* yValues, int valuesQty, int x0, int y0, double xScale, double yScale);
void draw_result(int* xValues, double* yValues, int valuesQty, int processQty)
{
const int plotXSize = 500; // points
const int plotYSize = 500; // points
const int plotXMargin = 50;
const int plotYMargin = 50;
int window = g2_open_X11( plotXSize + 2*plotXMargin, plotYSize + 2*plotYMargin );
const int maxXValue = xValues[ valuesQty - 1];
char7 xNumbers[ NUMBERS_NUM ];
generateXNumbers( maxXValue, xNumbers );
double maxYValue = getUpperBound( getMaxValue( yValues, valuesQty ) );
char7 yNumbers[ NUMBERS_NUM ];
generateYNumbers( maxYValue, yNumbers );
coordinatePlane(window, xNumbers, yNumbers, plotXSize, plotYSize, plotXMargin, plotYMargin);
double xScale = (double)plotXSize/(double)maxXValue;
double yScale = (double)plotYSize/maxYValue;
pointsOnPlane(window, xValues, yValues, valuesQty, plotXMargin, plotXMargin, xScale, yScale);
char title[ 64 ];
sprintf( title, "MPI QuickSort result (%d process)", processQty);
g2_string(window,200, 5, title);
getchar();
g2_close(window);
}
void coordinatePlane(int window, char7* xNumbers, char7* yNumbers, int plotXSize, int plotYSize, int plotXMargin, int plotYMargin)
{
int x0 = plotXMargin;
int y0 = plotYMargin;
int X = plotXSize;
int Y = plotYSize;
int dx = plotXSize/ NUMBERS_NUM;
int dy = plotYSize/ NUMBERS_NUM;
int rx = 5;
int ry = 5;
int i = y0;
int k = -1;
for ( ; i <= Y + y0 ; i += dy, ++k)
{
g2_line(window,x0-rx,i,x0+X,i); //
if ( k == -1 )
{
g2_string(window,x0/4,i, "0");
}
else
{
g2_string(window,x0/4,i, yNumbers[ k ]); // y-axis numbers
}
}
g2_line(window,x0,y0,x0,y0+Y); // y-axis
g2_string(window,50, 570, "Time(sec.)");
int j = y0;
k = -1;
for ( ; j <= X + x0 ; j += dx, ++k)
{
g2_line(window,j,y0-ry,j,y0); // horizontal lines with marks; for j = y0 - x-axis
if ( k == -1 )
{
g2_string(window, (j == y0) ? j : (j - dx/4) , y0/2, "0");
}
else
{
g2_string(window, (j == y0) ? j : (j - dx/4) , y0/2, xNumbers[ k ]);
}
}
g2_string(window,470, 10, "Sorted array size");
}
void pointsOnPlane(int window, int* xValues, double* yValues, int valuesQty, int x0, int y0, double xScale, double yScale)
{
g2_pen(window, 3);
int prevX = 0;
int prevY = 0;
int i = 0;
for ( ; i < valuesQty; ++i)
{
int x = (double) xValues[i] * xScale;
int y = yValues[i] * yScale;
g2_filled_circle(window, x0 + x, y0 + y, 2);
if ( i > 0 )
{
g2_line(window,x0 + prevX, y0 + prevY, x0 + x, y0 + y );
}
prevX = x;
prevY = y;
}
}
double getMaxValue( double* arr, int arrSize)
{
double result = arr[0];
int i = 1;
for (; i < arrSize; ++i )
{
if ( result < arr[i] )
{
result = arr[i];
}
}
return result;
}
double getUpperBound( double value )
{
int deg = 0;
if ( value > 10 )
{
while( value < 10. && value > 0.1 )
{
value /= 10.;
deg++;
}
}
else if ( value < 1.)
{
while( value < 1. )
{
value *= 10.;
deg--;
}
deg++;
}
else
{
deg = 1;
}
double mult = ( value > 5. ) ? 1. : .5;
return mult*pow( 10., deg);
}
void generateXNumbers( int xBound, char7* xNumbers )
{
int i = 0;
int dx = xBound/NUMBERS_NUM;
for ( ; i < NUMBERS_NUM; ++i )
{
sprintf( xNumbers[i], "%d", (i+1)*dx);
}
return ;
}
void generateYNumbers( double yBound, char7* yNumbers )
{
int i = 0;
double dy = yBound/NUMBERS_NUM;
for ( ; i < NUMBERS_NUM; ++i )
{
sprintf( yNumbers[i], "%1.3f", (i+1)*dy);
}
return ;
}
Протестируем разработанный параллельный алгоритм, вычислив ускорение и эффективность работы алгоритма в зависимости от размера матрицы.
Ускорением параллельного алгоритма называют отношение времени выполнения лучшего последовательного алгоритмам к времени выполнения параллельного алгоритма:
???? = ???? / ????????
???? − время работы последовательного алгоритма
???????? − время работы параллельного алгоритма
Параллельный алгоритм может давать большое ускорение, но использовать для этого множество процессов неэффективно.
Для оценки масштабируемости параллельного алгоритма используется понятие эффективности:
???? = ???? / ????
???? − ускорение ???? − количество процессоров.
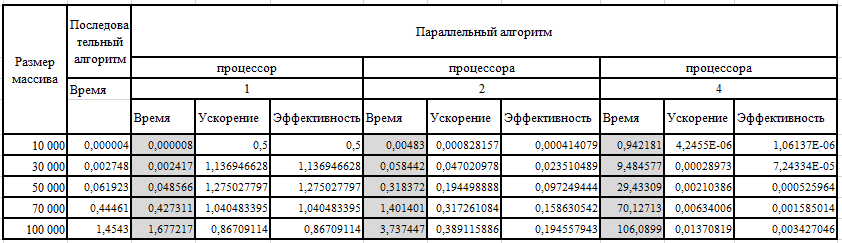
Таблица 1 – Результаты вычислительных экспериментов
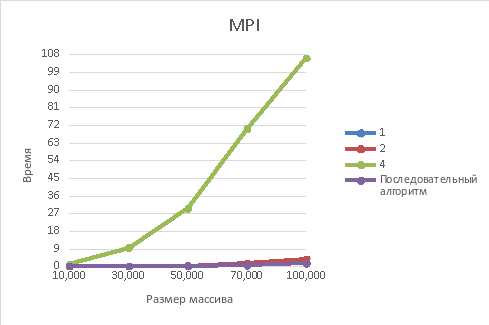
Рисунок 2 – Зависимость времени выполнения от размера массива
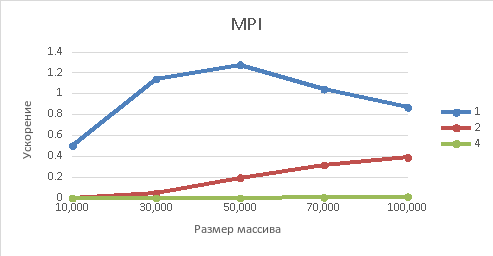
Рисунок 3– Зависимость ускорения от размера массива
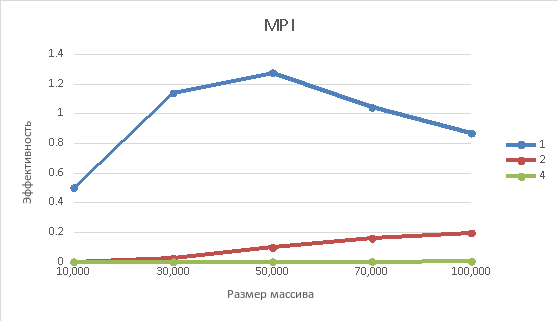
Рисунок 4 – Зависимость эффективности от размера массива
Реализация с использованием OpenMP
Программный код файла main.с
#include "g2draw.h"
#include "utils.h"
#include <stdio.h>
#define THREAD_QTY 8
#define ARRAY_SIZES_NUM 5
int main()
{
int sortArraySizes[ARRAY_SIZES_NUM] = { 10000, 30000, 50000, 70000, 100000 };
int threadNum[ THREAD_QTY ] = { 1,2,3,4,5,6,7,8 };
double result[ARRAY_SIZES_NUM][THREAD_QTY];
int k = 0;
for ( ; k < ARRAY_SIZES_NUM; ++k)
{
result[k][0] = serialsortarray( sortArraySizes[k] );
int j = 2;
for ( ; j <= THREAD_QTY ; ++j)
{
result[k][j - 1] = sortarray( sortArraySizes[k], j );
}
}
draw_result( threadNum, THREAD_QTY, result, ARRAY_SIZES_NUM, sortArraySizes);
}
Программный код файла utils.* (Функции для расчета)
#include "utils.h"
#include <omp.h>
#include <stdio.h>
#include <stdlib.h>
void quicksort(int arr[], int low_index, int high_index, int thread_num)
{
int j;
if(low_index < high_index)
{
j = partition(arr, low_index, high_index);
#pragma omp parallel sections num_threads(thread_num)
{
#pragma omp section
{
quicksort(arr, low_index, j - 1, thread_num);
}
#pragma omp section
{
quicksort(arr, j + 1, high_index, thread_num);
}
}
}
}
void serialquicksort(int arr[], int low_index, int high_index)
{
int j;
if(low_index < high_index)
{
j = partition(arr, low_index, high_index);
serialquicksort(arr, low_index, j - 1);
serialquicksort(arr, j + 1, high_index);
}
}
void swap(int * x, int * y)
{
int temp = *x;
*x = *y;
*y = temp;
}
int choosePivot(int * arr, int lo, int hi)
{
int mid = (lo+hi)/2;
if (arr[lo] > arr[hi] )
{
int temp = lo;
lo = hi;
hi = temp;
}
if( arr[lo] > arr[mid] )
{
int temp = mid;
mid = lo;
lo = temp;
}
if( arr[mid] > arr[hi] )
{
int temp = mid;
mid = hi;
hi = temp;
}
return mid;
}
int partition(int * arr, int lo, int hi)
{
int pivotIdx = choosePivot(arr, lo, hi);
int pivotVal = arr[pivotIdx];
swap(&arr[pivotIdx], &arr[hi]);
int storeIdx = lo;
int i;
for(i = lo; i < hi; i++)
{
if(arr[i] < pivotVal)
{
swap(&arr[i], &arr[storeIdx]);
storeIdx++;
}
}
swap(&arr[storeIdx], &arr[hi]);
return storeIdx;
}
int* generatearray(const int size)
{
srand( time(NULL) );
int* array = (int*) malloc( size * sizeof(int) );
int index = 0;
for ( ;index < size; ++index)
{
array[index] = LOWER_BAND + rand() % (UPPER_BAND - LOWER_BAND);
}
return array;
}
void purgearray(int* arr)
{
free( arr );
}
void showarray(int arr[], int size)
{
int i = 0;
for( ;i < size;i++)
{
printf("%d\t",arr[i]);
}
}
void showDoubleArray(double arr[], int size)
{
int i = 0;
for( ;i < size;i++)
{
printf("%f\t",arr[i]);
}
}
double sortarray( int size, int thread_num)
{
int* arr = generatearray( size );
double start_time = omp_get_wtime();
quicksort ( arr, 0, size - 1, thread_num);
double end_time = omp_get_wtime();
double elapsed = end_time - start_time;
if ( checkarray( arr, size) )
{
printf("Array size %d thread num %d: time = %g seconds.\n", size, thread_num, elapsed);
}
else
{
printf("Array size %d thread num %d: sort failed!\n", size, thread_num);
}
purgearray( arr );
return elapsed;
}
double serialsortarray( int size)
{
int* arr = generatearray( size );
double start_time = omp_get_wtime();
serialquicksort ( arr, 0, size - 1);
double end_time = omp_get_wtime();
purgearray( arr );
printf("Array size %d: time = %g seconds.\n", size, end_time - start_time);
return end_time - start_time;
}
int checkarray(int arr[], int size)
{
int i = 1;
for( ;i < size ;i++)
{
if ( arr[i - 1] > arr[i] )
{
return 0;
}
}
return 1;
}
Программный код файла g2draw.*( функции для рисования графика времени расчета от размера массива).
#include "g2draw.h"
#include <stdio.h>
#include <g2.h>
#include <g2_X11.h>
#include <math.h>
#define NUMBERS_NUM 10
typedef char char7[7];
double getUpperBound( double value );
double getMaxValue( double* arr, int arrSize);
void generateXNumbers( int xBound, char7* xNumbers );
void generateYNumbers( double yBound, char7* yNumbers );
void coordinatePlane(int window, char7* xNumbers, char7* yNumbers, int plotXSize, int plotYSize, int plotXMargin, int plotYMargin);
void pointsOnPlane(int window, int* xValues, double* yValues, int valuesQty, int x0, int y0, double xScale, double yScale, int color, const char* title);
void draw_result(int* xValues, int xValuesQty, double* yValues, int yValuesQty, int* categoryValues)
{
const int plotXSize = 500; // points
const int plotYSize = 500; // points
const int plotXMargin = 50;