Файл: Курсовой проект по дисциплине Интеллектуальный анализ данных Тема Анализ данных о клиентах магазина.docx
ВУЗ: Не указан
Категория: Не указан
Дисциплина: Не указана
Добавлен: 29.10.2023
Просмотров: 149
Скачиваний: 5
ВНИМАНИЕ! Если данный файл нарушает Ваши авторские права, то обязательно сообщите нам.
МИНИСТЕРСТВО НАУКИ И ВЫСШЕГО ОБРАЗОВАНИЯ
РОССИЙСКОЙ ФЕДЕРАЦИИ
ФЕДЕРАЛЬНОЕ ГОСУДАРСТВЕННОЕ БЮДЖЕТНОЕ
ОБРАЗОВАТЕЛЬНОЕ УЧРЕЖДЕНИЕ ВЫСШЕГО ОБРАЗОВАНИЯ
«ВОРОНЕЖСКИЙ ГОСУДАРСТВЕННЫЙ ТЕХНИЧЕСКИЙ УНИВЕРСИТЕТ»
(ФГБОУ ВО «ВГТУ», ВГТУ)
Факультет информационных технологий и компьютерной безопасности
Кафедра компьютерных интеллектуальных технологий проектирования
КУРСОВОЙ ПРОЕКТ
по дисциплине «Интеллектуальный анализ данных»
Тема «Анализ данных о клиентах магазина» .
Расчетно-пояснительная записка
Разработал(а) студент(ка) Луцик И.А
Подпись, дата Инициалы, фамилия
Руководитель Ветохин В.В.
Подпись, дата Инициалы, фамилия
Члены комиссии .
Подпись, дата Инициалы, фамилия
.
Подпись, дата Инициалы, фамилия
Нормоконтролер .
Подпись, дата Инициалы, фамилия
Защищена ____________________ Оценка ___________________________
дата
Воронеж 2023
МИНИСТЕРСТВО НАУКИ И ВЫСШЕГО ОБРАЗОВАНИЯ
РОССИЙСКОЙ ФЕДЕРАЦИИ
ФЕДЕРАЛЬНОЕ ГОСУДАРСТВЕННОЕ БЮДЖЕТНОЕ
ОБРАЗОВАТЕЛЬНОЕ УЧРЕЖДЕНИЕ ВЫСШЕГО ОБРАЗОВАНИЯ
«ВОРОНЕЖСКИЙ ГОСУДАРСТВЕННЫЙ ТЕХНИЧЕСКИЙ УНИВЕРСИТЕТ»
(ФГБОУ ВО «ВГТУ», ВГТУ)
Факультет информационных технологий и компьютерной безопасности
Кафедра компьютерных интеллектуальных технологий проектирования
ЗАДАНИЕ
на курсовой проект
по дисциплине «Интеллектуальный анализ данных»
Тема «Анализ данных о клиентах магазина»
Студент группы збАП-191 Луцик Илья Андреевич
Фамилия, имя, отчество
Номер варианта 1 .
Технические условия .
Содержание и объем работы (графические работы, расчеты и прочее): .
30 страниц, 25 рисунков , .
Сроки выполнения этапов .
Срок защиты курсовой работы .
Руководитель Ветохин В.В.
Подпись, дата Инициалы, фамилия
Задание принял студент Луцик И.А.
Подпись, дата Инициалы, фамилия
Замечания руководителя
СОДЕРЖАНИЕ
ВВЕДЕНИЕ 5
Глава 1. Теоретическая часть 6
1.1 Инструмент Jupyter Notebook 6
1.1.1Как воспользоваться Jupyter Notebook 6
1.1.2 Возможности Jupyter Notebook 8
1.2 Библиотеки для анализа данных. 11
1.2.1 Библиотека Pandas 12
1.2.2 Библиотека Sklearn 13
1.2.3 Библиотека Seaborn 13
Глава 2. Первичный анализ данных 15
Глава 3. Разработка интеллектуальной модели 21
Глава 4. Тестирование и оптимизация интеллектуальной модели 28
ЗАКЛЮЧЕНИЕ 32
СПИСОК ЛИТЕРАТУРЫ 33
ВВЕДЕНИЕ
Анализ данных - это процесс извлечения полезной информации из больших объемов данных с помощью различных методов и технологий. Анализ данных позволяет решать разнообразные задачи в различных областях деятельности, таких как бизнес, наука, образование, медицина и другие. Анализ данных способствует повышению эффективности и качества принятия решений, оптимизации процессов, выявлению закономерностей и тенденций, прогнозированию будущих событий и явлений.
Глава 1. Теоретическая часть
1.1 Инструмент Jupyter Notebook
Jupyter Notebook — это мощный инструмент для разработки и представления проектов Data Science в интерактивном виде. Он объединяет код и вывод все в виде одного документа, содержащего текст, математические уравнения и визуализации
Один из плюсов этого инструмента в том, что код можно разделить на кусочки и работать над ними в любом порядке. Например, написать скрипт и сразу посмотреть, как он работает. Остальные фрагменты кода при этом запускать не нужно, результат появляется тут же, под частью кода.
1.1.1Как воспользоваться Jupyter Notebook
Для начала работы с Jupyter нужно скачать его. Для этого в командной строке пропишем pip install jupyter (рис. 1)
Рисунок 1 – Установка Jupyter Notebook
После начнется весьма длительная установка. Далее нужно запустить Jupyter notebook, прописав команду jupyter notebook в командной строке. После выполнения команды, в консоли появится ссылка, по которой нужно перейти.
Перейдя по ссылке, откроется в браузере окно jupyter, где создадим новый файл.
Рисунок 2 – Окно Jupyter Notebook
В созданном проекте имеются ячейки, которые могут быть текстом, либо кодом (рис. 4).
Рисунок 3 – Виды ячеек в Jupyter Notebook
Merkdown – текст
Code – код
1.1.2 Возможности Jupyter Notebook
Рассмотрим некоторые возможности jupyter.
Во-первых, это заголовки, поддержка html тегов, возможность создавать курсивный, жирный, зачеркнутый текст, создание списков, ссылок, поддержка математических функций.
Во-вторых, это код, который будет работать точно также, как и в среде разработки.
Можно использовать библиотеки python для реализации более сложных задач, например, библиотека для отражения графиков.
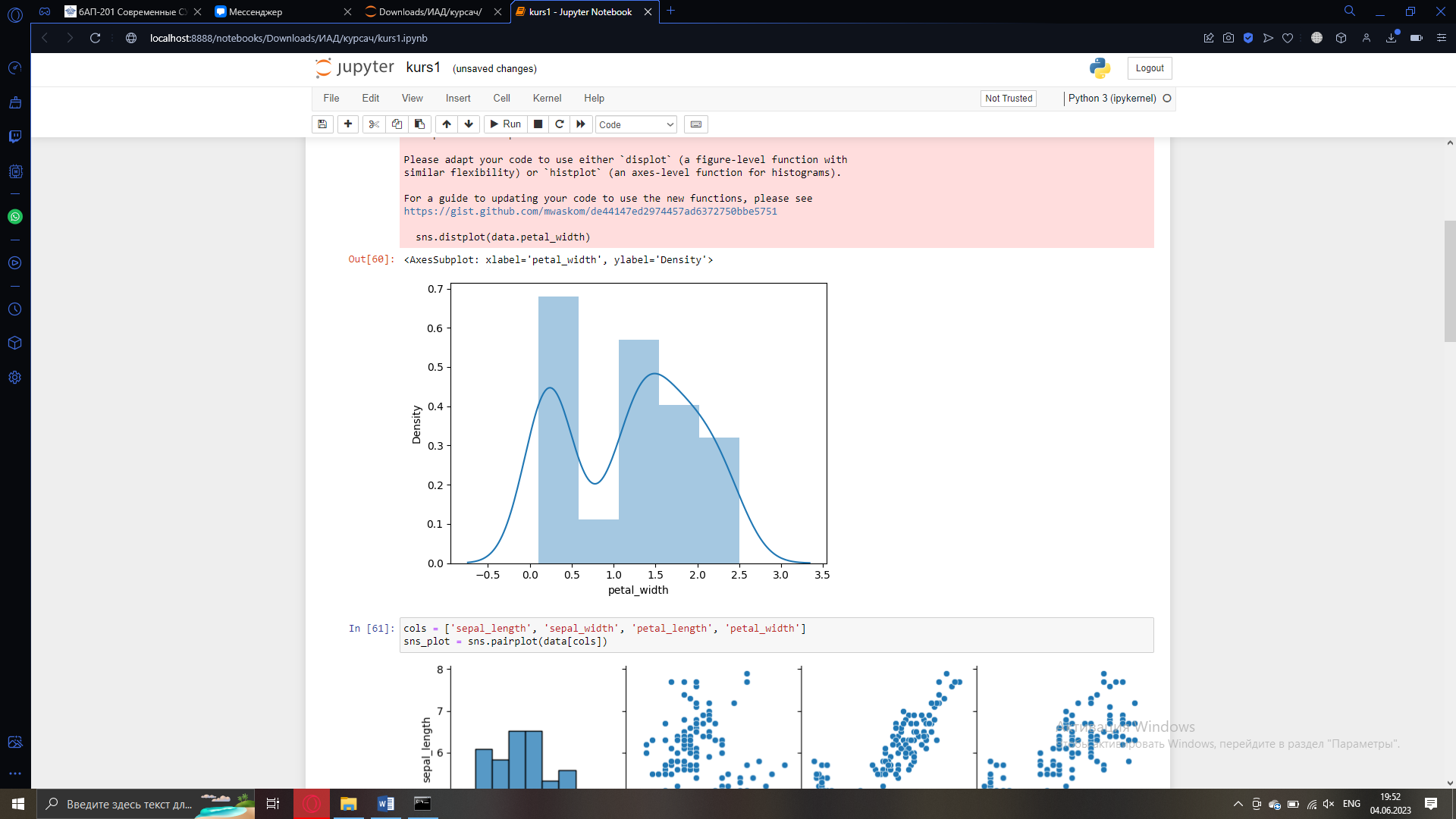
Рисунок 4 – Отображения графика
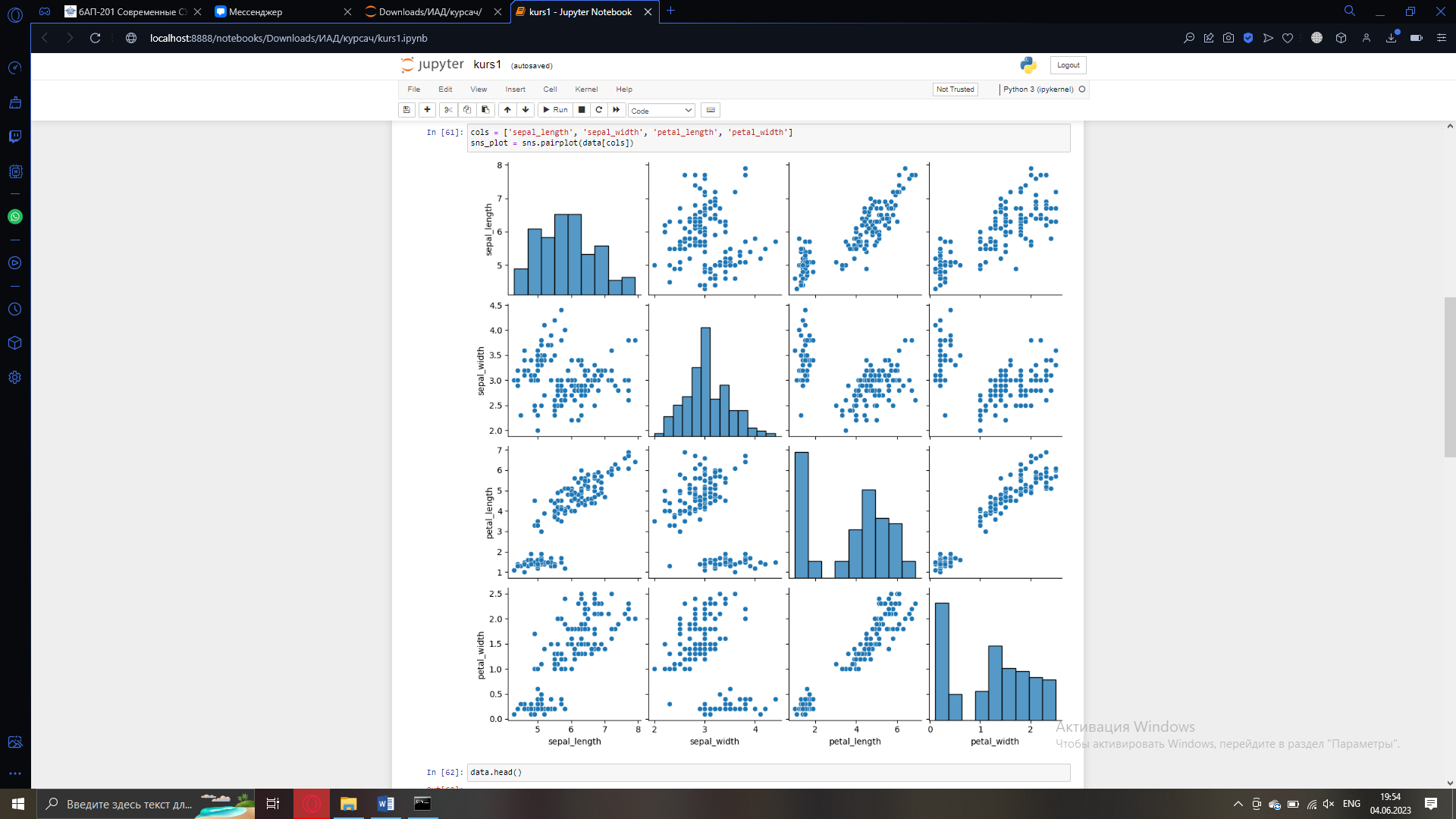
Рисунок 5 – Отображения графиков
Также в Jupyter Notebook можно сохранять файлы в файл с другим расширением. Jupyter поддерживает множество других расширений.
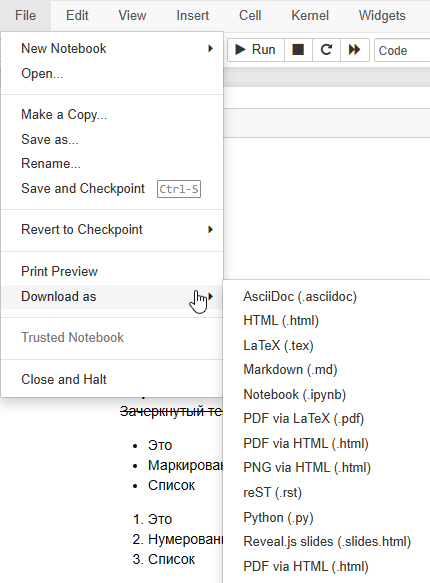
Рисунок 6 – Список расширений
1.2 Библиотеки для анализа данных.
С помощью Pandas проводится начальный анализ данных, а sklearn поможет в вычислении прогнозной модели.
Библиотека Pandas – это высокоуровневая библиотека позволяет строить сводные таблицы, выделять колонки, использовать фильтры по параметрам, выполнять группировку по параметрам, запускать функции (сложение, нахождение медианы, среднего, минимального, максимального значений), объединять таблицы и многое другое. В pandas можно создавать и многомерные таблицы.
Библиотека Sklearn содержит ряд методов, охватывающих всё, что может понадобиться в течение первых нескольких лет в карьере аналитика данных: алгоритмы классификации и регрессии, кластеризацию, валидацию и выбор моделей. Также её можно применять для уменьшения размерности данных и выделения признаков.
1.2.1 Библиотека Pandas
Pandas – это библиотека с открытым исходным кодом на Python. Она предоставляет готовые к использованию высокопроизводительные структуры данных и инструменты анализа данных. Модуль Pandas работает поверх NumPy и широко используется для обработки и анализа данных.
NumPy – это низкоуровневая структура данных, которая поддерживает многомерные массивы и широкий спектр математических операций с массивами. Pandas имеет интерфейс более высокого уровня. Он также обеспечивает оптимизированное согласование табличных данных и мощную функциональность временных рядов.
DataFrame является ключевой структурой данных в Pandas. Это позволяет хранить и обрабатывать табличные данные, как двумерную структуру данных. Pandas предоставляет богатый набор функций для DataFrame. Например, выравнивание данных, статистика данных, нарезка, группировка, объединение, объединение данных и т.д.
DataFrame – самая важная и широко используемая структура данных, а также стандартный способ хранения данных. Она содержит данные, выровненные по строкам и столбцам, как в таблице SQL или в базе данных электронной таблицы.
Импорт данных из CSV
Можно создать DataFrame, импортировав файл CSV.
Файл CSV – это текстовый файл с одной записью данных в каждой строке. Значения в записи разделяются символом «запятая». Pandas предоставляет полезный метод с именем read_csv() для чтения содержимого файла CSV.
1.2.2 Библиотека Sklearn
Scikit-learn — библиотека машинного обучения на языке программирования Python с открытым исходным кодом. Содержит реализации практически всех возможных преобразований, и нередко ее одной хватает для полной реализации модели. В данной библиотеки реализованы методы разбиения датасета на тестовый и обучающий, вычисление основных метрик над наборами данных, проведение Кросс-валидация. В библиотеке также есть основные алгоритмы машинного обучения: линейной регрессии и её модификаций Лассо, гребневой регрессии, опорных векторов, решающих деревьев и лесов и др. Есть и реализации основных методов кластеризации. Кроме того, библиотека содержит постоянно используемые исследователями методы работы с признаками: например, понижение размерности методом главных компонент.
1.2.3 Библиотека Seaborn
Seaborn — это библиотека для создания статистических графиков на Python. Она основывается на matplotlib и тесно взаимодействует со структурами данных pandas.
Архитектура Seaborn позволяет вам быстро изучить и понять свои данные. Seaborn захватывает целые фреймы данных или массивы, в которых содержатся все ваши данные, и выполняет все внутренние функции, нужные для семантического маппинга и статистической агрегации для преобразования данных в информативные графики. Она абстрагирует сложность, позволяя вам проектировать графики в соответствии с вашими нуждами.
Глава 2. Первичный анализ данных
Первоначально импортируем библиотеки pandas, matplotlib.pyplot и seaborn для визуализации данных. Библиотека warnings импортируется для подавления предупреждений, которые могут возникнуть во время выполнения кода.
Затем считываем файл CSV с именем ‘Customers.csv’ с помощью функции read_csv() из библиотеки pandas и сохраняем его в переменной с именем data. Функция head() вызывается на переменной data, чтобы отобразить первые 5 строк данных. Посмотрим на эти 5 строк (Рисунок 6)
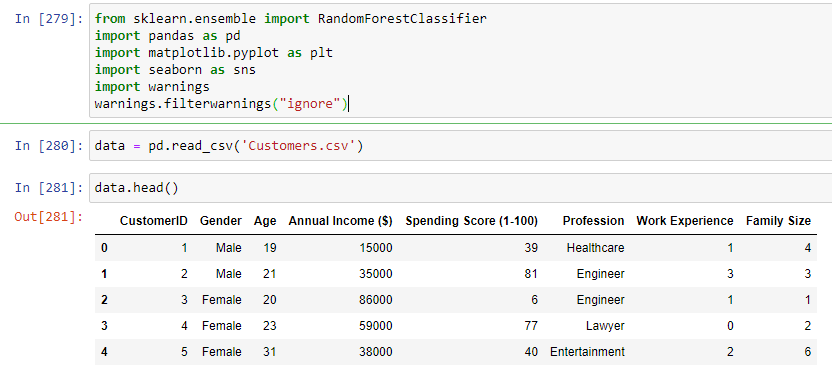
Рисунок 6 – Первые 5 записей из файла с данными
Как можно заметить, в этом файле с данными присутствуют текстовые значения, в дальнейшем мы их преобразуем в числовой формат, для обучения модели. Теперь посмотрим на число записей в файле и тип данных у колонок. Это можно сделать вызвав функцию info() для переменной, в которую записан файл с данными (Рисунок 7).
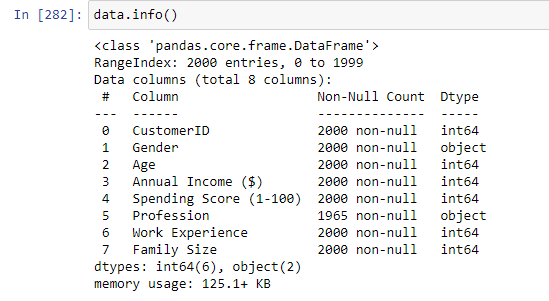
Рисунок 7 – Информация о файле с данными
Файл состоит из 2000 записей, колонки, в которых содержится информация о поле, профессии покупателя должны быть преобразованы в числовой формат. А колонка, которая в дальнейшем будет целевым показателем будет разбита на 5 групп, для удобства обучения модели. Приступаем к преобразованиям файла с данными.
После распределения на 5 групп целевого показателя, посмотрим есть ли пустые значения в файле с данными. Для этого вызовем следующие функции (Рисунок 8).
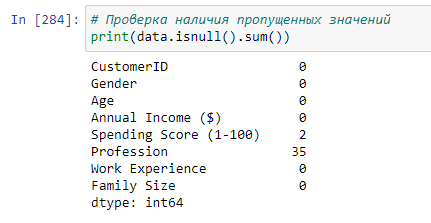
Рисунок 8 – Число пустых значений
Как видим, такие записи присутствуют, их необходимо удалить. Для этого вызовем функцию dropna() у файла с данными. Так как в колонке с полом содержится всего 2 типа значений, резонно будет их заменить на 0 и 1. Строка с заменой и информацией по файлу с данными, после преобразований представлена на рисунке 9.
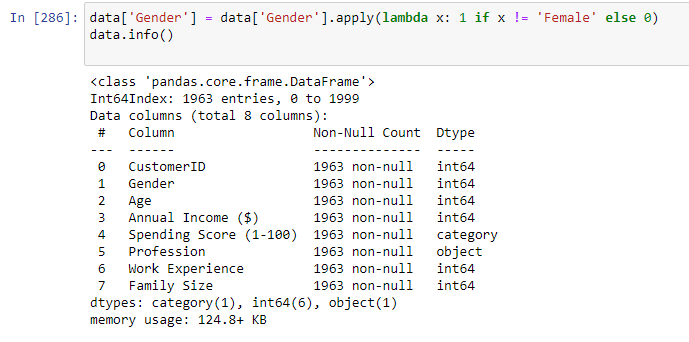
Рисунок 9 – Замена значений в столбце
Далее займемся удалением столбца, с айди записи, так как он не несет в себе никакой смысловой нагрузки. Также необходимо отсеять в файле с данными информацию о людях, младше 18 лет, эти данные являются ошибочными, ведь официально иметь профессию они не могут. Строки с преобразованием файла с данными и текущую информацию о нем, можно увидеть на рисунке 10.
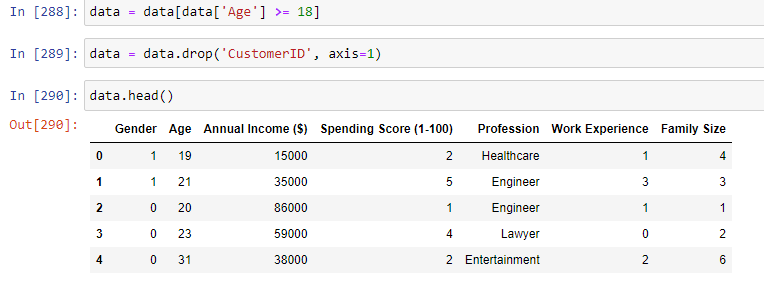
Рисунок 10 – Удаление информации из файла
Строку, содержащую информацию о профессии мы преобразуем в дальнейшем, перед началом обучения модели. Это сделано для удобства построения графиков. Теперь построим гистограмму всех столбцов, кроме пола для .csv файла. Гистограмма изображена на рисунке 11.