Файл: Курсовой проект по дисциплине Интеллектуальный анализ данных Тема Анализ данных о клиентах магазина.docx
ВУЗ: Не указан
Категория: Не указан
Дисциплина: Не указана
Добавлен: 29.10.2023
Просмотров: 143
Скачиваний: 5
ВНИМАНИЕ! Если данный файл нарушает Ваши авторские права, то обязательно сообщите нам.
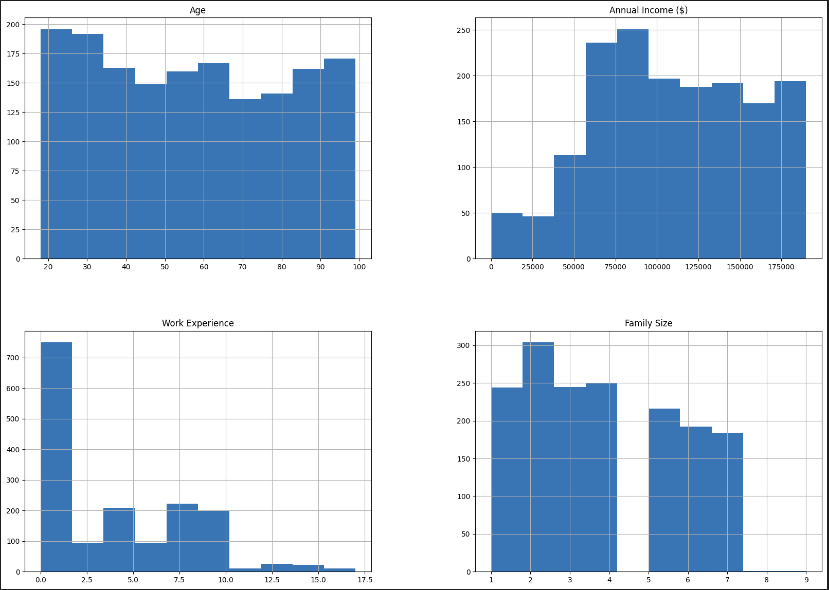
Рисунок 11 – Количество различных данных в столбцах
Теперь построим столбчатую диаграмму, на которой будут показано количество мужчин и женщин, имеющих определенную профессию. График изображен на рисунке 12.
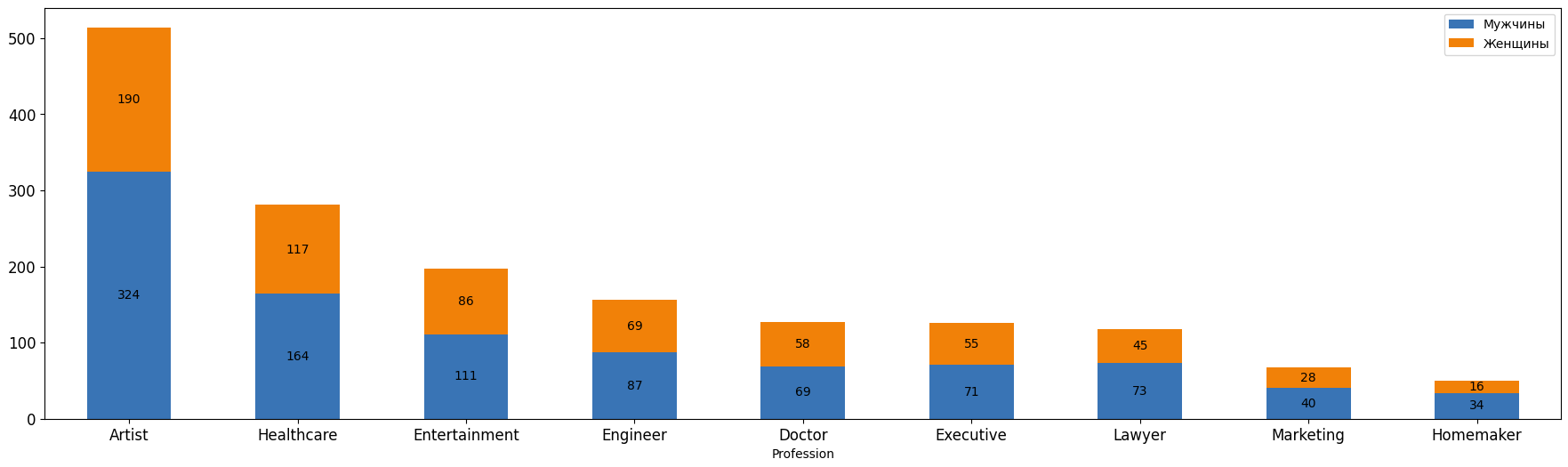
Рисунок 12 – Столбчатая диаграмма полов по профессиям
На последнем этапе подготовки к созданию модели преобразуем текстовые данные из столбца Profession в числовые, при помощи LabelEncoder. На рисунке 13 изображен итоговый вид файла с данными, записанного в переменную data.
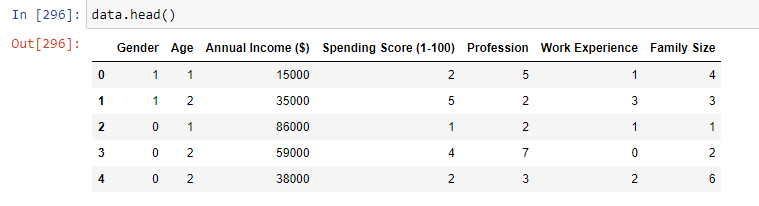
Рисунок 13 – Значения после преобразований
Таким образом, мы будем обучать модель по файлу с данными, который содержит покупателей старше 18 лет, которые являются представителями 9 различных профессий с опытом работы от 0 до 17 лет и имеющих семью из 0 – 7 человек. Целевым показателем будет являтся Spending Score — оценка, присваиваемая магазином на основе поведения покупателей и характера расходов
Глава 3. Разработка интеллектуальной модели
Для разработки интеллектуальной модели отделим столбец целевого показателя от всего файла с данными. Теперь можем разделить данные на обучающую и тестовые выборки. Для этого вызовем функцию train_test_split из библиотеки sklearn. В нее передадим: данные data, целевой показатель target, размер тестовой выборки test_size и значение для генератора случайных чисел random_state. Тестовая выборка будет составлять 30% от всех данных в файле, этот показатель выбран путем обучения модели и анализа показателей точности. В результате выполнения этой функции данные и метки разделяются на обучающую и тестовую выборки в соответствии с указанным размером тестовой выборки.
Полученные выборки сохраняются в переменных X_three_train, X_three_holdout, y_three_train и y_three_holdout. Затем вызывается метод shape для отображения размеров полученных выборок. Метки для обучающей выборки и размеры тестовых и тренировочных выборок изображены на рисунке 14.
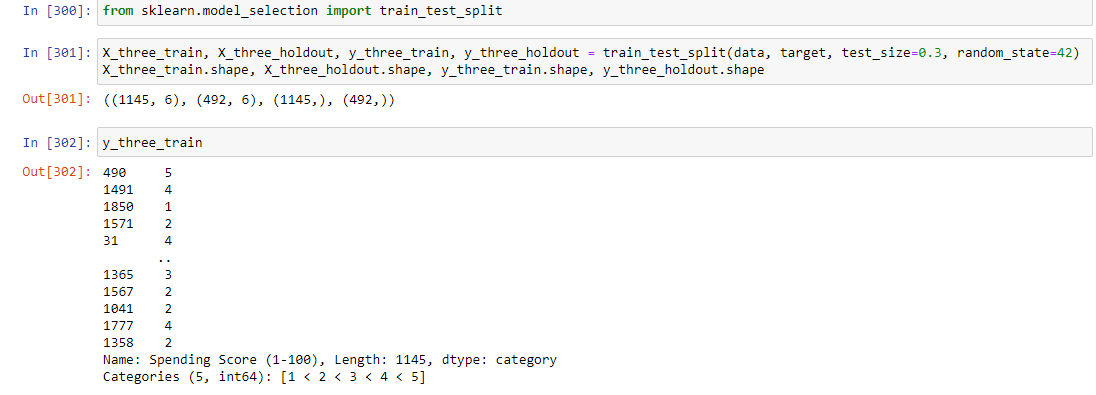
Рисунок 14 – Размеры выборок и метка
Первым методом обучения нашей модели будет DecisionThreeClassifier. Воспользуемся GridSearchCV для поиска оптимальных параметров обучения. В param_grid передаем параметры для перебора. Создаем объект класса DecisionThreeClassifier. Затем создается объект grid_search класса GridSearchCV, который принимает в качестве аргументов модель, словарь с диапазонами значений параметров и количество фолдов для кросс-валидации (cv). Далее вызывается метод fit для обучения модели с перебором по сетке. В итоге выводятся лучшие значения параметров, найденные в результате перебора по сетке (Рисунок 15).
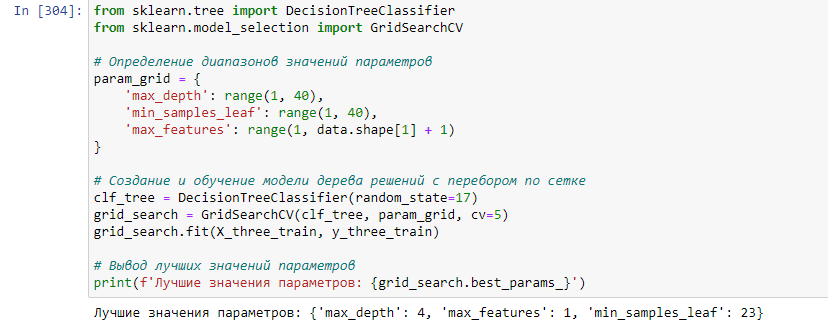
Рисунок 15 – Лучшие параметры для дерева решений
Теперь при помощи цикла будем обучать модель на тестовой и тренировочной выборке. Внутри цикла создается и обучается модель дерева решений с текущим значением min_samples_leaf и фиксированными значениями других параметров. Затем делается предсказание на тренировочной и тестовой выборках и вычисляются значения recall и precision с помощью функции recall_score и precision_score. Полученные значения сохраняются в соответствующих списках. После завершения цикла строится
график зависимости показателя recall и precision от значения min_samples_leaf на тренировочной и тестовой выборках. График изменения параметра recall и precision для двух выборок, который был построен по значениям, полученным в ходе работы цикла представлен на рисунке 16.
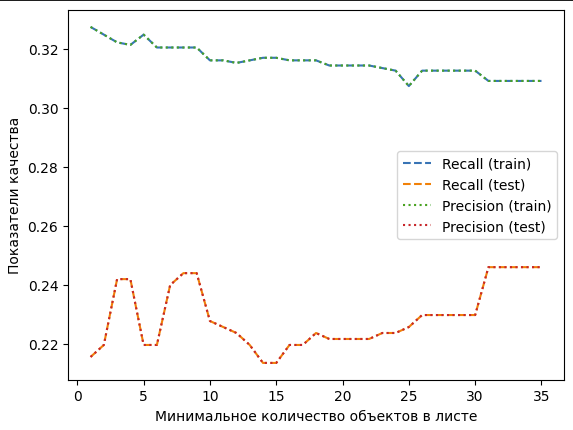
Рисунок 16 – Показатель recall для дерева решений
Судя по графику, при приближении к значению параметра min_samples_leaf, достигаются максимальные показатели recall и precision для тестовой выборки. Но разница между точностью классификации объектов на двух выборках велика, это означает, что данную модель нельзя использовать для классификации новых данных. Также это может быть связано с тем, что в исходных данных слишком много различных показателей и модели сложно обучится по ним.
Следующим методом обучения модели будет GradientBoostingClassifier. Также воспользуемся GridSearchCV для поиска лучших параметров. Найденные параметры изображены на рисунке 17.
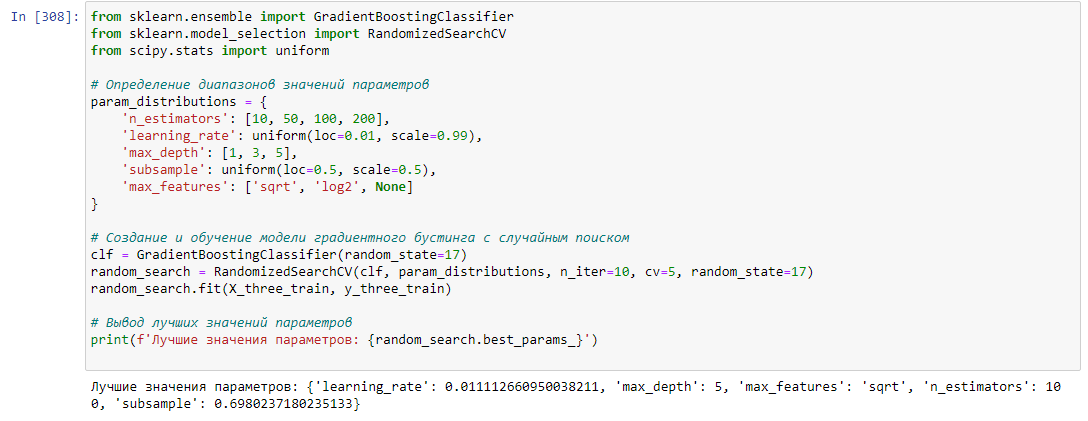
Рисунок 17 – Лучшие параметры градиентного бустинга
Далее посмотрим на графике, как меняется параметр recall и precision для этого метода обучения модели. Внутри цикла создается и обучается модель градиентного бустинга с текущим значением n_estimators и фиксированными значениями других параметров. Затем делается предсказание на обучающей и тестовой выборках и вычисляются значения recall и precision с помощью функций recall_score и precision_score. Полученные значения сохраняются в соответствующих списках. После завершения цикла строится график зависимости показателей recall и precision от значения n_estimators на обучающей и тестовой выборках. График изменения этих параметров представлен на рисунке 18.
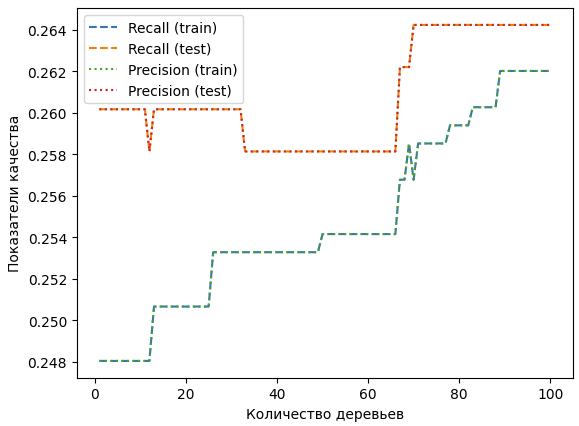
Рисунок 18 – График для градиентного бустинга
На этом графике можно увидеть, что для тестовой и обучающей выборки параметры recall и precision довольно близки, но модель по прежнему нельзя использовать для классификации новых данных, так как показатели примерно равны 0.26.
Попробуем другую модель, под названием KNeighborsClassifier. Для этой модели аналогично прошлой подберем лучшие параметры при помощи GridSearchCV. Эти параметры изображены на рисунке 19.
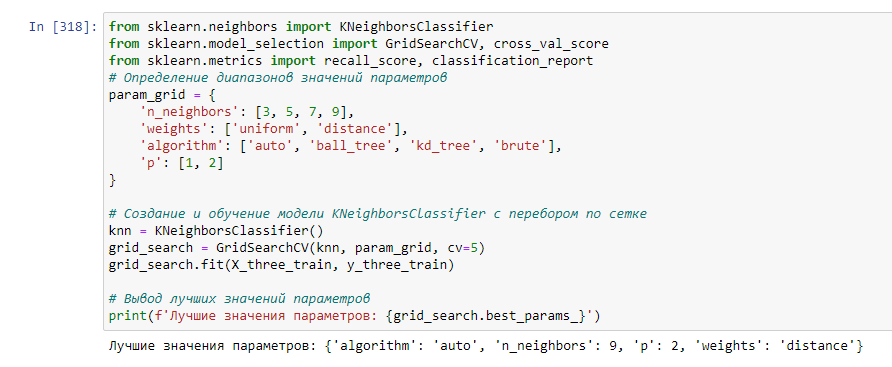
Рисунок 19 – Лучшие параметры для Ближайших соседей
Теперь при помощи графиков отобразим изменение precision и recall для этого метода обучения. Построение графиков выполнено аналогично прошлым – один параметр (количество соседей) изменяется, пока не достигнет своего самого оптимального значения, остальные параметры остаются неизменными. На рисунке 20 изображен график для тренировочной и тестовой выборки.
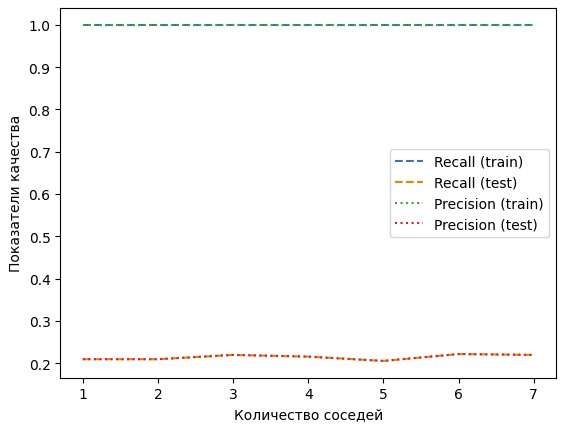
Рисунок 20 – График для метода Ближайших соседей
Как видно на графике, для тренировочной выборки модель научилась идеально классифицировать значения, а для тестовой показатель по-прежнему крайне мал. Это означает, что модель слишком хорошо подстроилась под обучающую выборку и не может обобщить данные для предсказания на новых данных.
Глава 4. Тестирование и оптимизация интеллектуальной модели
Чтобы упростить классификацию для модели, попробуем разделить возраста покупателей на 5 категорий. Для метода обучения под названием GradientBoostingClassifier попробуем нахождение лучших параметров при помощи случайного поиска, для этого создадим объект RandomizedSearchCV со следующими параметрами:
-
n_estimators: количество деревьев в ансамбле; -
learning_rate: коэффициент обучения, который уменьшает вклад каждого дерева; -
max_depth: максимальная глубина каждого дерева; -
subsample: доля выборок, используемых для обучения каждого базового оценщика; -
max_features: количество признаков, которые нужно учитывать при поиске лучшего разделения.
Теперь заново построим график, отображающий recall и precision, на котором будет изменяться количество деревьев. Он представлен на рисунке 21.
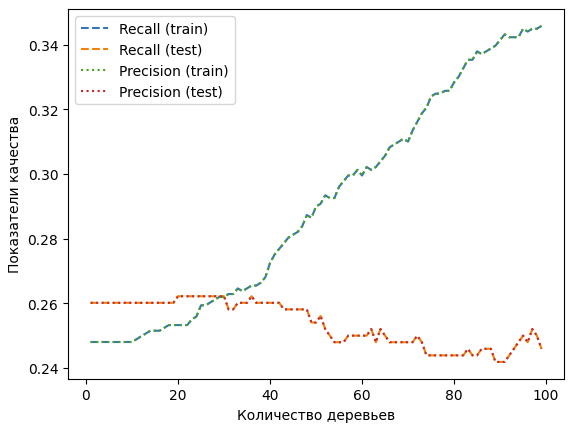
Рисунок 21 – График для Градиентного бустинга
Теперь заново обучим модель, используя лучшие параметры, найденные при помощи RandomizedSearchCV. После этого выведем все результаты обучения, при помощи classification_report. Полученные значения изображены на рисунке 22.
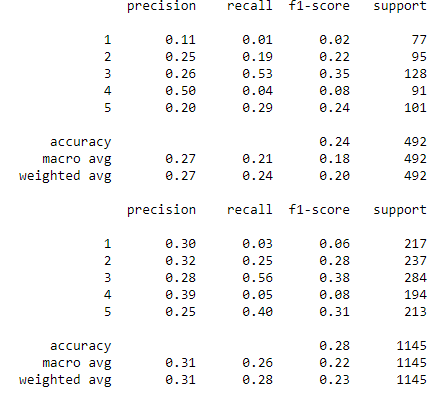
Рисунок 22 – Показатели для Градиентного бустинга
Изменение параметров для Градиентного бустинга и распределение по группам значений из столбца привело к тому, что уменьшилась разница между recall и precision, а также модель теперь может идентифицировать все группы значений, хоть и с переменным успехом.
Теперь посмотрим, как повлияло разбиение возрастов покупателей на группы на другие методы обучения.
Для деревьев решений заново запустим алгоритм построения графика и посмотрим на изменения (Рисунок 23).
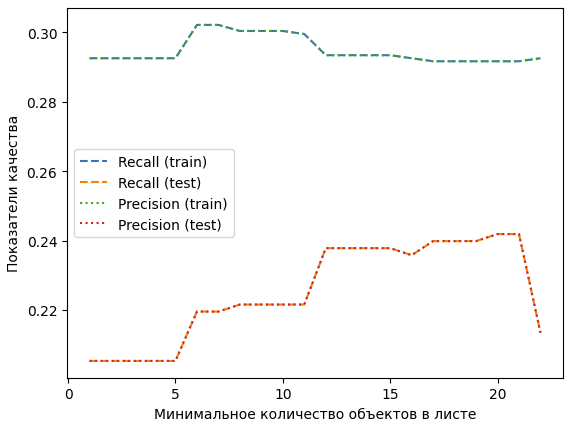
Рисунок 23 – Графики для Дерева решений
Далее заново обучим модель, с лучшими параметрами, найденными при помощи GridSearchCV. Выведем эти значения (Рисунок 24).
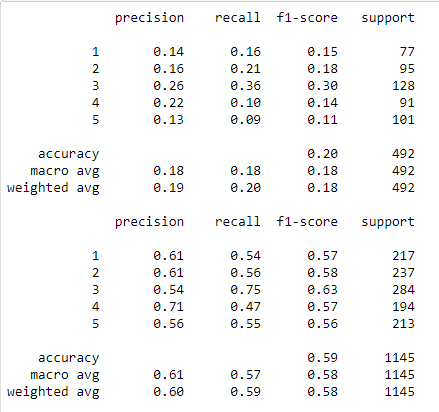
Рисунок 24 – Отчет по Дереву решений
Здесь заметна аналогичная ситуация, модель научилась классифицировать все группы. Разница между precision и recall довольно велика. Общий показатель точности предсказания у этого метода обучения самый высокий среди всех методов.
Аналогично прошлым способам обучения, для метода Ближайших соседей простроим график, показывающий precision и recall для двух выборок. На нем отсутствуют изменения, поэтому обучим модель с лучшими параметрами, найденными при помощью GridSeacrhCV и посмотрим на отчет (Рисунок 25).
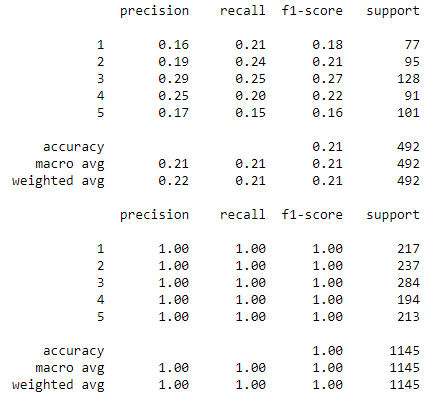
Рисунок 25 – Отчет по методу Ближайших соседей
Преобразование колонки с возрастом для этого метода не привело к улучшениям показателей. Модель по-прежнему переобучается. Таким образом, лучшие средние показатели recall и precision для тестовой выборки достигаются в методе Деревьев решений, а для тренировочной выборки лучшим является метод Ближайших соседей.
ЗАКЛЮЧЕНИЕ
В ходе данной курсовой работы была проведена разработка и обучение модели по набору данных о клиентах магазина товаров для творчества. Целью работы была выявление платежеспособности клиентов на основе различных характеристик. Для достижения поставленной цели были решены следующие задачи:
-
проведен анализ и предобработка данных, включая заполнение пропусков, удаление выбросов, кодирование категориальных признаков; -
проведен корреляционный анализ и отбор наиболее значимых признаков для построения модели; -
подобраны наиболее оптимальные параметры для достижения максимально возможных показателей точности классификации -
создана и обучена модель по обработанным данным, используя различные способы обучения
СПИСОК ЛИТЕРАТУРЫ
-
Бенгфорт, Б. Прикладной анализ текстовых данных на Python. Машинное обучение и создание приложений обработки естественного языка / Б. Бенгфорт. — СПб.: Питер, 2019. — 368 c. -
Козлов А.Ю. Статистический анализ данных в MS Excel: Учебное пособие / А.Ю. Козлов, В.С. Мхитарян, В.Ф. Шишов. — М.: Инфра-М, 2018. — 80 c. -
Кулаичев А.П. Методы и средства комплексного анализа данных: Учебное пособие / А.П. Кулаичев. — М.: Форум, 2018. — 160 c. -
Макшанов А.В. Технологии интеллектуального анализа данных: Учебное пособие / А.В. Макшанов, А.Е. Журавлев. — СПб.: Лань, 2018. — 212 c. -
Макшанов А.В. Технологии интеллектуального анализа данных. — М.: Лань. 2019. 212 с. -
Миркин Б. Г. Введение в анализ данных. — М.: Юрайт. 2020. 175 с. -
Мхитарян В. С. Теория планирования эксперимента и анализ статистических данных. — М.: Юрайт. 2020. 491 с.