Файл: Лабораторная работа для ипз. Проект. 1 Общие положения и задание 1.docx
ВУЗ: Не указан
Категория: Не указан
Дисциплина: Не указана
Добавлен: 07.11.2023
Просмотров: 41
Скачиваний: 2
ВНИМАНИЕ! Если данный файл нарушает Ваши авторские права, то обязательно сообщите нам.
Лабораторная работа для ИПЗ. Проект.
Оглавление
Лабораторная работа для ИПЗ. Проект. 1
0. Общие положения и задание 1
1. Загрузка и подготовка датасета для анализа 2
1.1 Переходим по ссылке, знакомимся с контентом страницы. 2
1.2. Выбор конкретного датасета, если их несколько 3
1.3. Копирование названий столбцов и их описаний с сайта 4
1.4. Отбор столбцов (признаков) для дальнейшей работы 7
1.5. Скачиваем датасет (или архив) и сохраняем его 8
1.6. Загрузка датасета в Excel. Только два способа. 9
2. Основные статистические харатеристики 11
2.1. Описательные характеристики для количественных признаков 11
2.2. Описательные характеристики для качественных признаков 12
2.3 "Что делать, если числа вопринимаются как текст" 12
3. Визуальный анализ 13
3.1. Визуализация: два количественных признака 13
3.1.1 Точечная диаграмма 13
3.1.2 Гистограмма распределения 14
3.2. Визуализация: качественные признаки. 15
3.2.1 Частотная таблица 15
3.2.2 Таблица сопряженности 17
3.3. Визуализация: Количественный и качественный признаки. 19
3.3.1 Распределение количественного признака для разных значений (категорий) качественного 19
3.3.2 Линейчатая диаграмма с категориями 19
0. Общие положения и задание
Цель. Продемонстрировать комплекс навыков по работе в MS Office.
Научиться загружать и оформлять табличные данные из сети Интернет для дальнейшего анализа, а также проводить предварительный визуальный анализ данных.
Задания.
Вариант 25
Реализуйте проект по анализу данных и принятию решений методами машинного обучения.
1. Скачайте по ссылке https://www.kaggle.com/muonneutrino/us-census-demographic-data датасет с названием US Census Demographic Data.
2. Рассчитайте основные описательные статистики
3. Проведите визуальный анализ
4. При необходимости очистите данные
(не обязательный) 5. Сформулируйте задачу проекта
(не обязательный) 6. Выберите метод машинного обучения для решения задачи и составьте модель.
(не обязательный) 7. Оцените качество построенной модели
(не обязательный) 8. Опишите, как воспользоваться построенной моделью.
9. Сделайте презентацию и подготовьте рассказ
Рекомендации.
Выполнять лабораторную работу можно в MS Excel или его аналогах, можно использовать и другой инструментарий (R, Python, статистические пакеты, облачные сервисы).
Пример ниже выполняется с помощью Google Table и MS Excel (версия 365)
Порядок выполнения работы.
1. Загрузка и подготовка датасета для анализа
1.1 Переходим по ссылке, знакомимся с контентом страницы.
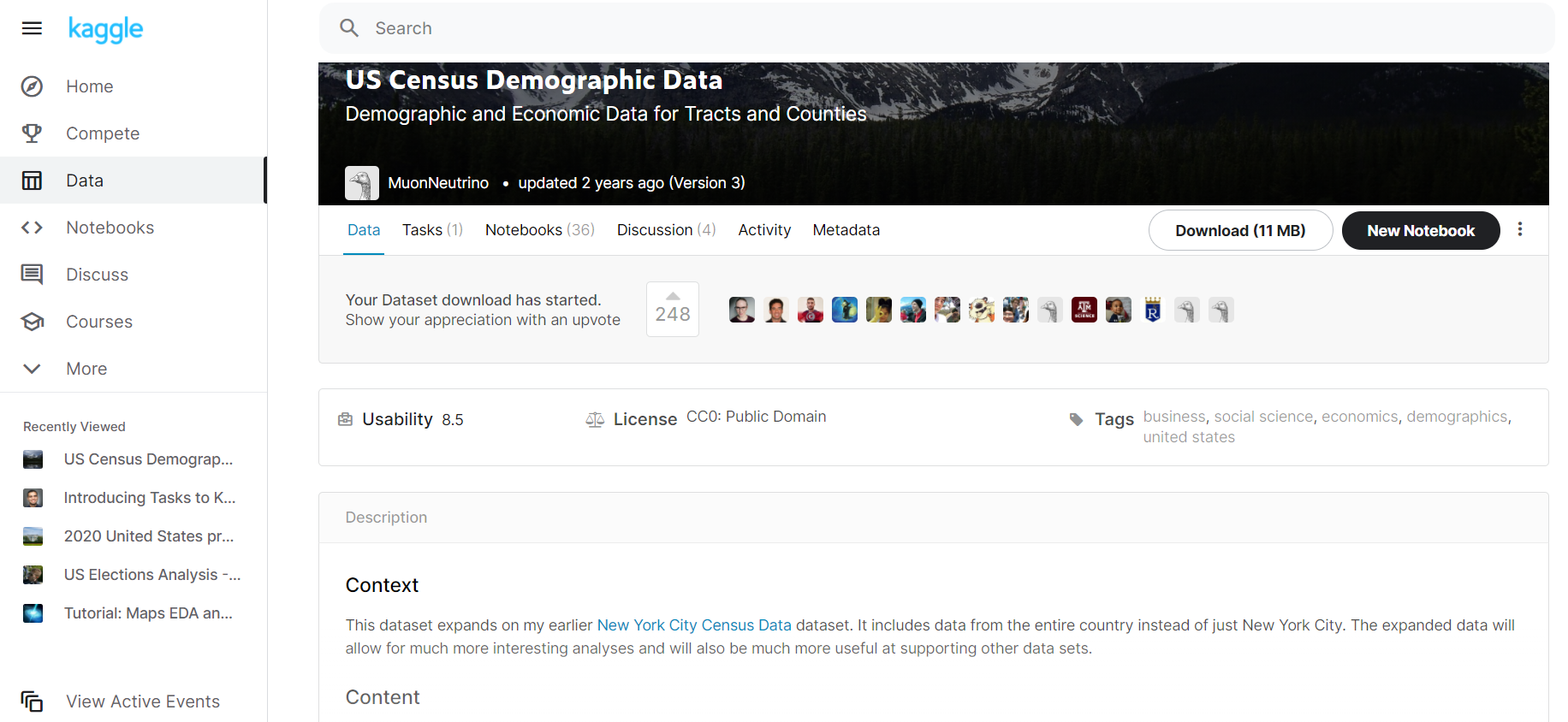
и ниже:
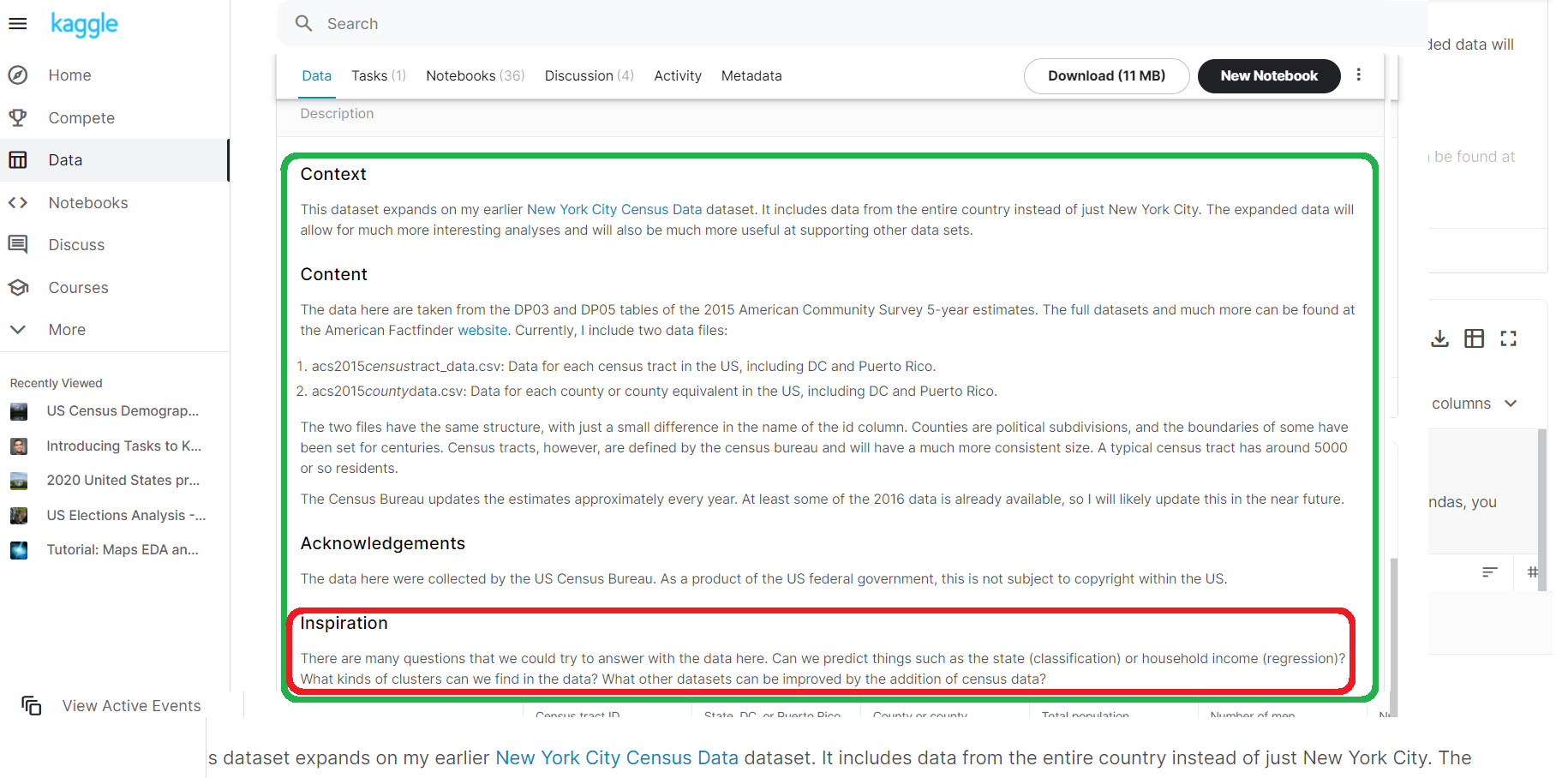
Обращаем внимание на Context, Content, Inspiration, переводим.
Из этих текстов извлекаем:
- общее описание, тему:
Набор данных включает данные переписи по США 2015 года по округам всех штатов.
В дальнейшем, по мере работы с датасетом, возможна корректировка
- идеи для анализа, предлагаемые автором датасета
Есть много вопросов, на которые мы могли бы попытаться ответить, используя данные здесь. Можем ли мы предсказать такие вещи, как состояние (классификация) или доход домохозяйства (регрессия)? Какие типы кластеров мы можем найти в данных?
1.2. Выбор конкретного датасета, если их несколько
Видим, что датасетов на странице несколько, ищем описания, по описанию выбираем датасет, с которым будем работать. В зависимости от варианта датасет может быть единственным.
Обращайте внимание на размер файлов.
Для отображения всех столбцов с их расшифровками выберите Select All
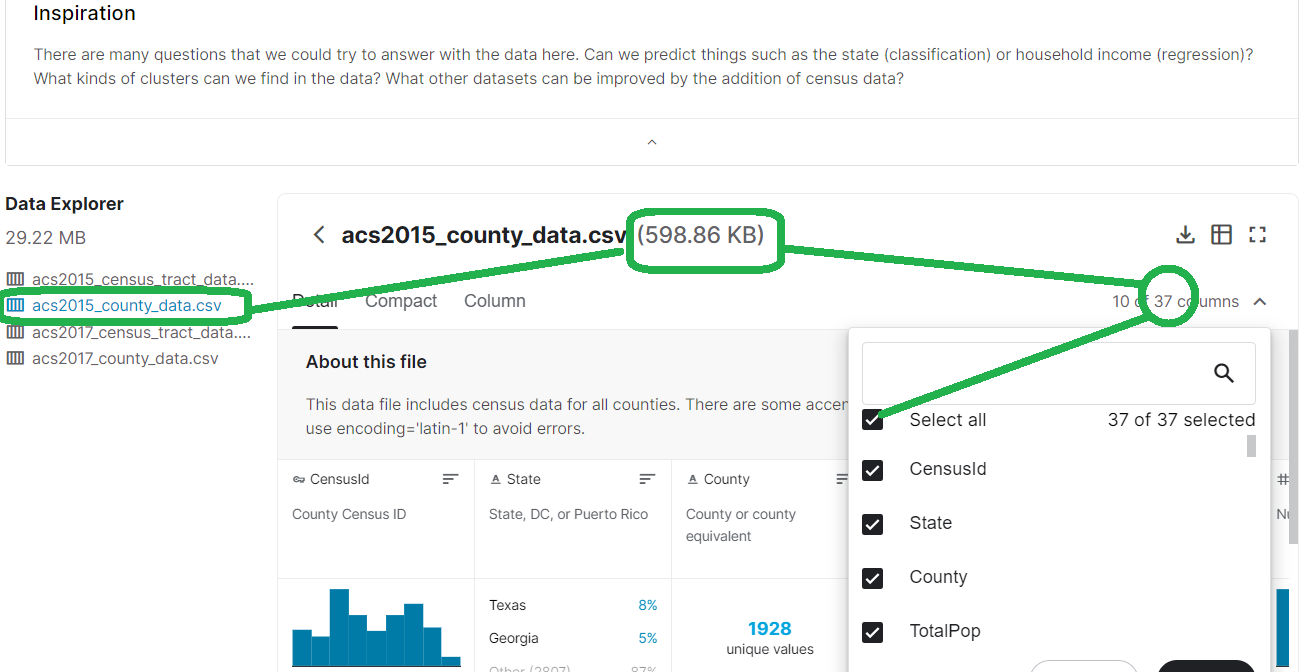
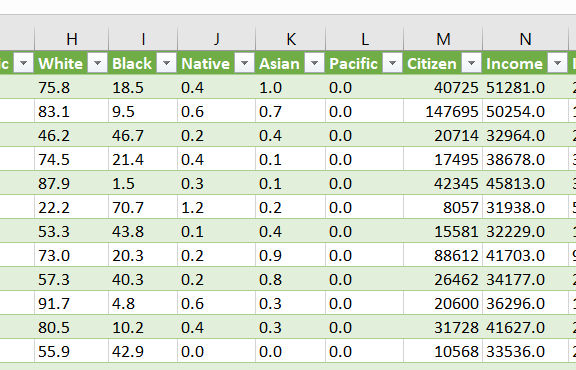
1.3. Копирование названий столбцов и их описаний с сайта
По разделу About this file можно перемещаться стрелками. Скопируем названия столбцов и их описания, переведем описания, это пригодится для отчета и для того, чтобы выбрать те столбцы, с которыми дальше будем работать.
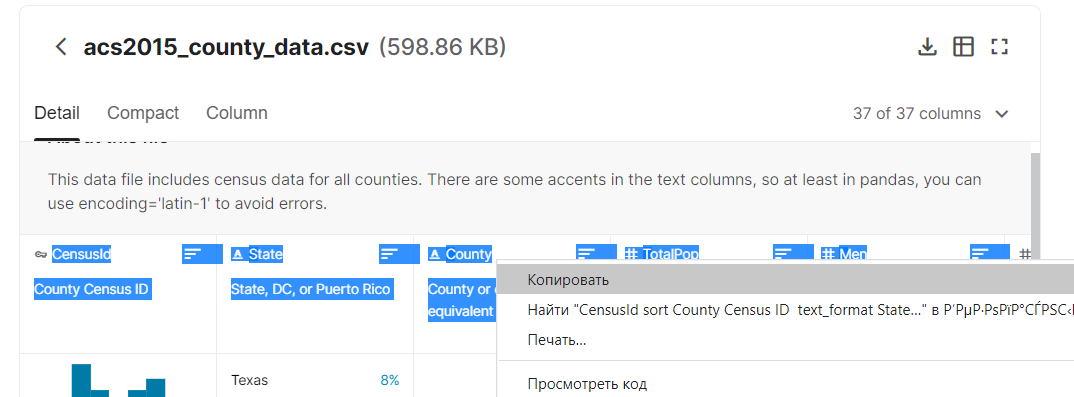
Выделяйте мышью, аккуратно и до конца. Получится примерно так, как ниже.
Выделены примеры служебных слов, которые нужно удалить (меню Главная -Заменить - ...)
CensusIdsort
County Census ID
text_formatStatesort
State, DC, or Puerto Rico
text_formatCountysort
County or county equivalent
grid_3x3TotalPopsort
Total population
grid_3x3Mensort
Number of men
grid_3x3Womensort
Number of women
grid_3x3Hispanicsort
% of population that is Hispanic/Latino
grid_3x3Whitesort
% of population that is white
grid_3x3Blacksort
% of population that is black
grid_3x3Nativesort
% of population that is Native American/Native Alaskan
grid_3x3Asiansort
% of population that is Asian
grid_3x3Pacificsort
% of population that is Native Hawaiian or Pacific Islander
grid_3x3Citizensort
Number of citizens
grid_3x3Incomesort
Median household income ($)
grid_3x3IncomeErrsort
Median household income error ($)
grid_3x3IncomePerCapsort
Income per capita ($)
grid_3x3IncomePerCapErrsort
Income per capita error ($)
grid_3x3Povertysort
% under poverty level
grid_3x3ChildPovertysort
% of children under poverty level
grid_3x3Professionalsort
% employed in management, business, science, and arts
grid_3x3Servicesort
% employed in service jobs
grid_3x3Officesort
% employed in sales and office jobs
grid_3x3Constructionsort
% employed in natural resources, construction, and maintenance
grid_3x3Productionsort
% employed in production, transportation, and material movement
grid_3x3Drivesort
% commuting alone in a car, van, or truck
grid_3x3Carpoolsort
% carpooling in a car, van, or truck
grid_3x3Transitsort
% commuting on public transportation
grid_3x3Walksort
% walking to work
grid_3x3OtherTranspsort
% commuting via other means
grid_3x3WorkAtHomesort
% working at home
grid_3x3MeanCommutesort
Mean commute time (minutes)
grid_3x3Employedsort
Number of employed (16+)
grid_3x3PrivateWorksort
% employed in private industry
grid_3x3PublicWorksort
% employed in public jobs
grid_3x3SelfEmployedsort
% self-employed
grid_3x3FamilyWorksort
% in unpaid family work
grid_3x3Unemploymentsort
Unemployment rate (%)
Очищенный текст преобразуем в таблицу с двумя столбцами (Вставка -Таблица – преобразровать в таблицу) , добавляем третий с переводом.
1.4. Отбор столбцов (признаков) для дальнейшей работы
Начинаем продумывать тему для анализа данных. На какие вопросы вы бы хотели (сможете) получить ответ, какие картинки нарисовать?
Работаем с таблицей описаний признаков (см. ниже)
Выделяем те прзнаки, которые в дальнейшем оставим для работы. Оставляйте идентификатор, 2-4 качественных и 3-4 количественных признака. Не нужно замахиваться на масштабные исследования))
Например, относительно данного датасета можно интересоваться распределением рабочих мест по разным формам собственности и уровнем безработицы, оставить данные о подушевом доходе, занятость в разрезах форм собственности рабочих мест и уровень безработицы.
В четвертом столбце укажите тип признака (качественный или количественный). Определения типов данных выясните самостоятельно.
| Название столбца (признака) | Смысл (англ.) | Смысл (русск., google) | Тип признака |
| CensusId | County Census ID | Идентификатор переписи населения округа | идентификатор |
| State | State, DC, or Puerto Rico | Штат, округ Колумбия или Пуэрто-Рико | качественный |
| County | County or county equivalent | Округ или эквивалент округа | качественный |
| TotalPop | Total population | Всего населения | количественный |
| Men | Number of men | Количество мужчин | |
| Women | Number of women | Количество женщин | |
| Hispanic | % of population that is Hispanic/Latino | % населения, испанского / латиноамериканского происхождения | |
| White | % of population that is white | % белого населения | |
| Black | % of population that is black | % населения чернокожих | |
| Native | % of population that is Native American/Native Alaskan | % населения коренных американцев / коренных жителей Аляски | |
| Asian | % of population that is Asian | % населения азиатского происхождения | |
| Pacific | % of population that is Native Hawaiian or Pacific Islander | % населения Гавайских островов или жителей островов Тихого океана | |
| Citizen | Number of citizens | Количество граждан | |
| Income | Median household income ($) | Средний доход домохозяйства ($) | |
| IncomeErr | Median household income error ($) | Ошибка среднего дохода домохозяйства ($) | |
| IncomePerCap | Income per capita ($) | Доход на душу населения ($) | количественный |
| IncomePerCapErr | Income per capita error ($) | Ошибка дохода на душу населения ($) | |
| Poverty | % under poverty level | % ниже уровня бедности | |
| ChildPoverty | % of children under poverty level | % детей за чертой бедности | |
| Professional | % employed in management, business, science, and arts | % занятых в менеджменте, бизнесе, науке и искусстве | |
| Service | % employed in service jobs | % занятых в сфере обслуживания | |
| Office | % employed in sales and office jobs | % занятых в продажах и офисах | |
| Construction | % employed in natural resources, construction, and maintenance | % занятых в сфере природных ресурсов, строительства и технического обслуживания | |
| Production | % employed in production, transportation, and material movement | % занятых в производстве, транспортировке и перемещении материалов | |
| Drive | % commuting alone in a car, van, or truck | % ездят в одиночку на машине, фургоне или грузовике | |
| Carpool | % carpooling in a car, van, or truck | % совместное использование автомобилей в автомобиле, фургоне или грузовике | |
| Transit | % commuting on public transportation | % поездок на общественном транспорте | |
| Walk | % walking to work | % пешком до работы | |
| OtherTransp | % commuting via other means | % поездок на работу другим способом | |
| WorkAtHome | % working at home | % работают дома | |
| MeanCommute | Mean commute time (minutes) | Среднее время в пути (минуты) | |
| Employed | Number of employed (16+) | Количество работающих (16+) | |
| PrivateWork | % employed in private industry | % занятых в частном секторе | количественный |
| PublicWork | % employed in public jobs | % занятых на государственных должностях | количественный |
| SelfEmployed | % self-employed | % частный предприниматель | количественный |
| FamilyWork | % in unpaid family work | % в неоплачиваемой семейной работе | количественный |
| Unemployment | Unemployment rate (%) | Уровень безработицы (%) | количественный |
1.5. Скачиваем датасет (или архив) и сохраняем его
Теперь скачаем датасет (или архив, как в данном случае)
Размещаем выбранный датасет в рабочем каталоге

1.6. Загрузка датасета в Excel. Только два способа.
Ваш файл имеет расширение CSV (от англ. Comma-Separated Values — значения, разделённые запятыми) — текстовый формат, предназначенный для представления табличных данных. Строка таблицы соответствует строке текста, которая содержит одно или несколько полей, разделенных запятыми.
Формат CSV стандартизирован не полностью.
Поэтому при открытии в MS Excel данные в некоторых столбцах (даты, десятичные числа, номера версий продуктов) могут отображаться неверно.
Содержимое файла можно увидеть в Блокноте (Открыть с помощью...):
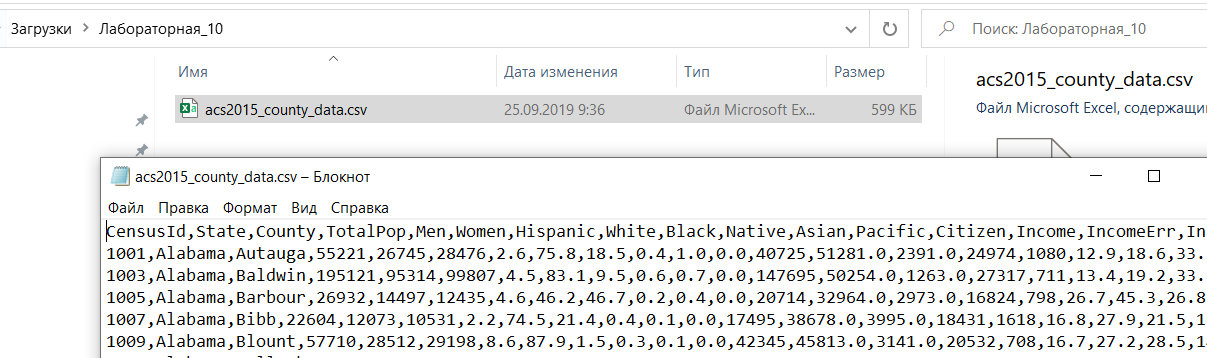
Посмотрите на данные в Блокноте.
Закройте Блокнот.
Теперь импортируем датасет в MS Excel.
Способ 1 (неофициальный, но рекомендую). В Блокноте выполнить замену запятой на точку с запятой по всему файлу. Сохранить под новым именем. Из Проводника новый файл открыть в MS Excel.
Способ 2.
Запускаем MS Excel. Создаем Новую книгу. Далее меню Данные – из текстового/CSV-файла.
Загрузить.
Замечание к обоим способам.
Если какие-то столбцы исказились (например, версии продукта4.01.03 превратилась в 4 января 2003), то в данной лабораторной работе откажитесь от использования этих столбцов, возьмите для анализа другие. В реальных условиях (на работе) рекомендую открыть файл в Google Table или Libre Office, искажений будет меньше. Дальше исправлять средствами Excel.
Проверьте, что установлен разделитель целой и десятичной части как точка (Файл – Параметры – снять галочку Использовать системные разделители – установить Разделитель точка)
Оставим только выбранные ранее столбцы. Удалите лшние.
2. Основные статистические харатеристики
Ценное Замечание: Выделить диапазон от позиции курсора до конца вниз Ctrl-Shift-↓
Создадим новый лист с названием Описательные характеристики, скопируем на него заголовки столбцов:

2.1. Описательные характеристики для количественных признаков
Для количественных данных рассчитаем, пользуясь функциями и переходя на нужные листы:
-
средние значения (=СРЗНАЧ(...)) -
дисперсии (=ДИСП() -
среднеквадратические отклонения (=СТАНДОТКЛОН(...)) -
медианы (=МЕДИАНА(...)) -
моды (=МОДА(...))
Выяснть самостоятельно смысл этих понятий.
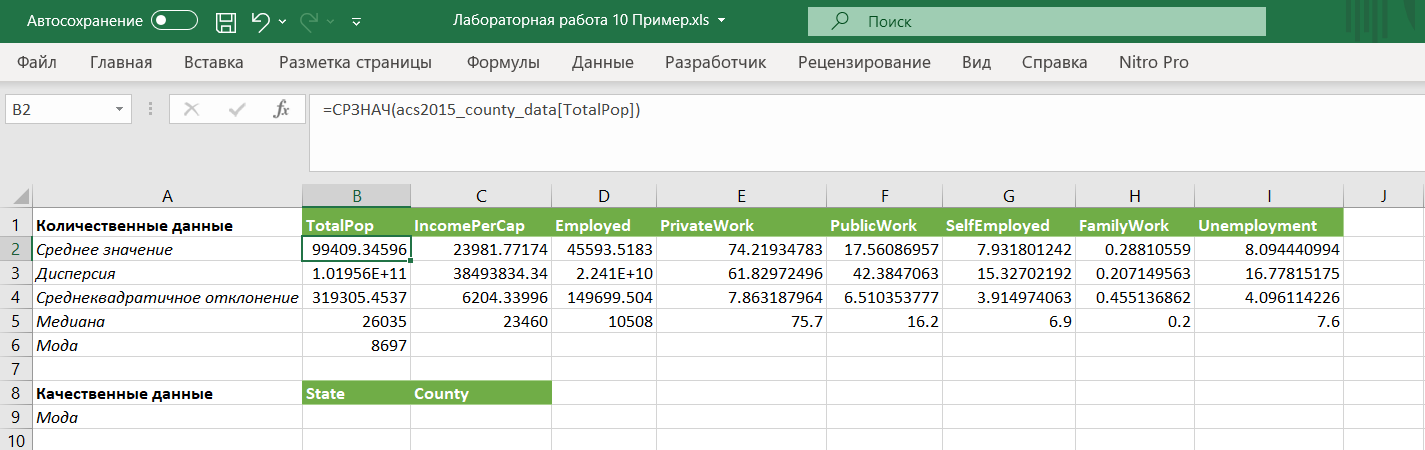
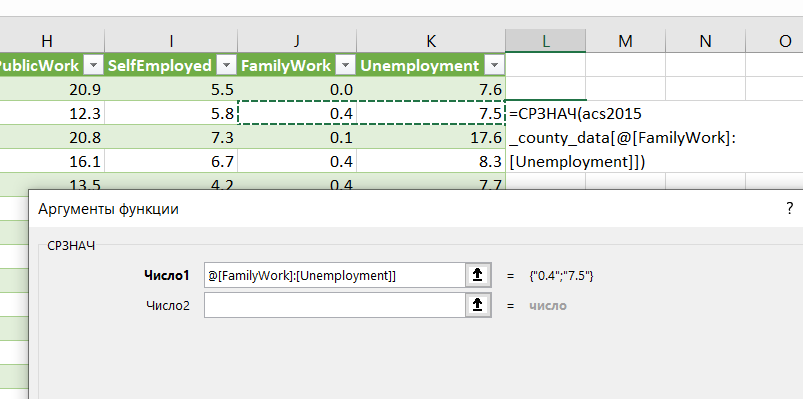
Замечание: Обратите внимание на запись диапазона ячеек: если вы используете строку заголовков (щелчок по таблице – Конструктор таблиц – строка заголовков), то диапазон записывается по названию заголовка =СРЗНАЧ(acs2015_county_data[TotalPop]), а не =СРЗНАЧ(D2:D3221)
2.2. Описательные характеристики для качественных признаков
Для качественных данных рассчитаем
-
моды
Моду можно найти в Excel, если построить частотную таблицу (таблица частоты встречамости для каждого значения признака) и взять максимальное значение. Сделаем это в разделе Визуализация
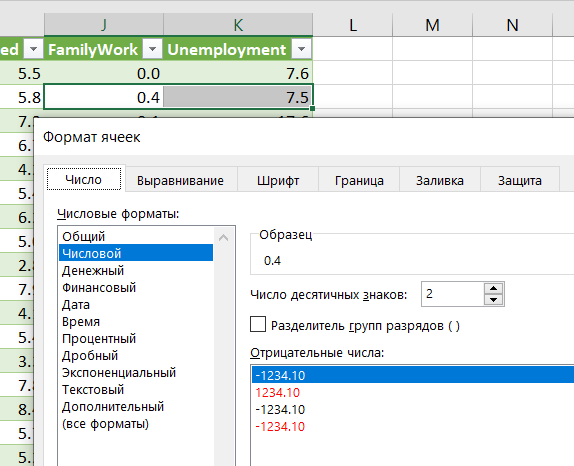
2.3 "Что делать, если числа вопринимаются как текст"
Возможно, при вычислении среднего появится деление на ноль. Причина в том, что, хотя формат ячейки Числовой, данные воспринимаются как текстовые. Исправление: Главная – Заменить – точку на точку (да-да!)
Всё получится.
3. Визуальный анализ
Формулировать постановку задачи для визуализации нужно самостоятельно. Достаточно одного - двух графиков для каждой комбнации типов данных: два количественных признака, два качественных признака, качественный и количественный признаки.
3.1. Визуализация: два количественных признака
Автором сформулрованы самостоятельно такие задачи.
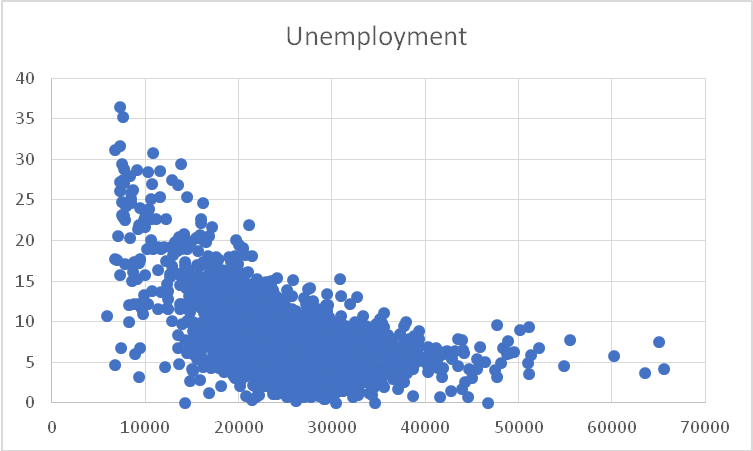
3.1.1 Точечная диаграмма
Задача 1. Визуализировать, как распределены значения подушевого дохода и уровня безработицы
Решение. Строим Точечную диаграмму по двум столбцам