Файл: Программам бакалавриата Кафедра Мультимедийных сетей и услуг связи.docx
ВУЗ: Не указан
Категория: Не указан
Дисциплина: Не указана
Добавлен: 05.12.2023
Просмотров: 40
Скачиваний: 1
ВНИМАНИЕ! Если данный файл нарушает Ваши авторские права, то обязательно сообщите нам.
Федеральное Агентство Связи
Ордена Трудового Красного Знамени федеральное государственное бюджетное образовательное учреждение высшего образования
«Московский технический университет связи и информатики»
Центр заочного обучения по программам бакалавриата
Кафедра «Мультимедийных сетей и услуг связи»
Дисциплина: Бизнес аналитика и технологии «больших данных»
Доклад
Технологии интеллектуального анализа данных
(Data Mining, DM)
Выполнил: Иванов Иван, студент группы БСТ17хх
Проверил:
Москва, 2019
Содержание
Введение
Одним из основных ресурсов человечества испокон времен являлась информация, в различных ее представлениях. В связи с совершенствованием технологий записи и хранения данных на людей обрушились колоссальные потоки информационной руды в самых различных областях. Деятельность любого предприятия (коммерческого, производственного, медицинского, научного и т.д.) теперь сопровождается регистрацией и записью всех подробностей его деятельности. Что делать с этой информацией? Стало ясно, что без продуктивной переработки потоки сырых данных образуют никому не нужную свалку. Тут на помощь человечеству и приходят технологии интеллектуального анализа данных.
Основная часть
Data Mining (рус. добыча данных, интеллектуальный анализ данных, глубинный анализ данных) — собирательное название, используемое для обозначения совокупности методов обнаружения в данных ранее неизвестных, нетривиальных, практически полезных и доступных интерпретации знаний, необходимых для принятия решений в различных сферах человеческой деятельности. (Термин введён Григорием Пятецким-Шапиро в 1989 году.)
На бытовом уровне это звучит примерно так: «Вы мучаете данные, пока они не признаются».
Стоит отметить, что процесс обнаружения знаний не полностью автоматический - он требует участия пользователя. Проще говоря, пользователь должен знать, что он ищет, основываясь на собственных гипотезах. В итоге часто вместо подтверждения имеющейся гипотезы процесс поиска вызывает появление новых гипотез. Все это обозначается термином discovery-driven data mining (DDDM), и термины Data Mining, knowledge discovery в общем случае относятся к DDDM.
Декомпозиция «Data Mining» включает:
-
Некие технологии, инструменты и методы; -
Данные уже структурированы, так как уже как-то хранятся и с ними уже как-то работают; -
Данные могут быть любых размеров; -
Обработка данных должна быть продуктивной (быть выгодна в каком-либо смысле для конечных лиц).
Традиционная математическая статистика, долгое время претендовавшая на роль основного инструмента анализа данных, откровенно спасовала перед лицом возникших проблем. Главная причина – концепция усреднения по выборке, приводящая к операциям над фиктивными величинами (типа средней температуры пациентов по больнице, средней высоты дома на улице, состоящей из дворцов и лачуг и т.п.). Методы математической статистики оказались полезными главным образом для проверки заранее сформулированных гипотез (verification-driven data mining) и для “грубого” разведочного анализа, составляющего основу оперативной аналитической обработки данных (online analytical processing, OLAP).
В основу современной технологии Data Mining (discovery-driven data mining) положена концепция шаблонов (паттернов), отражающих фрагменты многоаспектных взаимоотношений в данных. Эти шаблоны представляют собой закономерности, свойственные подвыборкам данных, которые могут быть компактно выражены в понятной человеку форме. Поиск шаблонов производится методами, не ограниченными рамками априорных предположений о структуре выборке и виде распределений значений анализируемых показателей.
Важное положение Data Mining – нетривиальность разыскиваемых шаблонов. Это означает, что найденные шаблоны должны отражать неочевидные, неожиданные регулярности в данных, составляющие так называемые скрытые знания. К обществу пришло понимание, что сырые данные содержат глубинный пласт знаний, при грамотной раскопке которого могут быть обнаружены настоящие самородки.
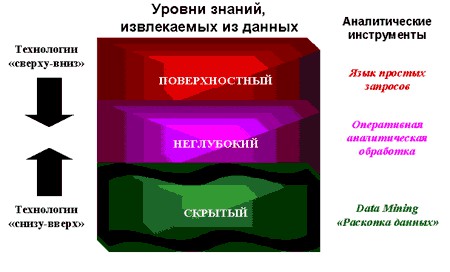
Сфера применения Data Mining ничем не ограничена – она везде, где имеются какие-либо данные. Но в первую очередь методы Data Mining сегодня, мягко говоря, заинтриговали коммерческие предприятия, развертывающие проекты на основе информационных хранилищ данных (Data Warehousing). Опыт многих таких предприятий показывает, что отдача от использования Data Mining может достигать 1000%.
Традиционный процесс Data Mining включает следующие этапы:
-
Анализ предметной области
Предметная область – мысленно ограниченная область реальной действительности, подлежащая описанию или моделированию и исследованию.
В процессе изучения предметной области должна быть создана ее модель. Знания из различных источников должны быть формализованы при помощи каких-либо средств. Это могут быть текстовые описания предметной области или специализированные графические нотации. Модель предметной области описывает процессы, происходящие в предметной области, и данные, которые в этих процессах используются. От того, насколько верно смоделирована предметная область, зависит успех дальнейшей разработки приложения Data Mining.
-
Постановка задачи
Постановка задачи Data Mining включает следующие шаги:
-
Формулировка задачи; -
Формализация задачи.
Постановка задачи включает также описание статического и динамического поведения исследуемых объектов. Описание статики подразумевает описание объектов и их свойств. При описании динамики описывают поведение объектов, и те причины, которые влияют на их поведение.
Порой этапы анализа предметной области и постановка задачи объединяют в один этап.
-
Подготовка данных
Основная цель этапа – разработка базы данных для Data Mining.
Подготовка данных является важнейшим этапом, от качества выполнения которого зависит возможность получения качественных результатов всего процесса DM.
Шаги этого этапа:
-
Определение и анализ требований к данным
Прежде всего необходимо решить, что именно будет анализироваться, какими исходными данными мы обладаем и с какими данными способна работать наша система интеллектуального анализа данных
-
Сбор данных -
Предварительная обработка данных -
Построение моделей -
Проверка и оценка моделей -
Выбор модели -
Применение модели -
Коррекция и обновление модели
Основные методы:
-
Ассоциация
Наиболее известный и простой метод интеллектуального анализа данных. Для выявления моделей делается простое сопоставление двух и более элементов, часто одного и того же типа. (Пример – Сеть ресторанов Макдональдс решила отследить привычки покупок и выяснила, что к обеду люди всегда берут кока-колу или аналогичную газировку. Исходя из полученных данных можно внести изменения в меню, добавив Комбо-обеды с напитком, поскольку это явно заинтересует покупателя).
-
Классификация
Используется для получения представления о типе покупателей, товаров или объектов, описывая несколько атрибутов для идентификации определенного класса. Как мебель можно классифицировать по типу (столы, стулья, шкафы, гардеробы и т.д.), так и покупателей можно классифицировать по различным критериям (возраст, пол, соц. группа, раса). Кроме того, классификацию используют в качестве входных данных для других методов.
-
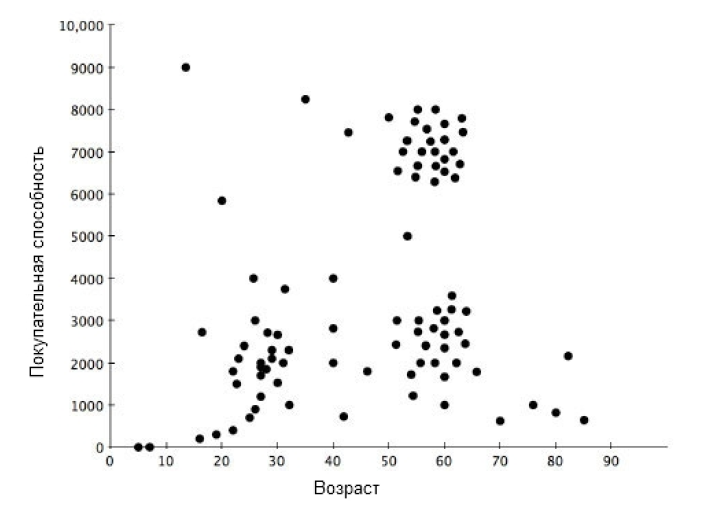
Кластеризация
Исследуя один или более атрибутов или классов, возможно сгруппировать отдельные элементы данных вместе, получая структурированное заключение. На простом уровне при кластеризации используется один или несколько атрибутов в качестве основы для определения кластера сходных результатов. Кластеризация полезна при определении различной информации, потому что она коррелируется с другими примерами, так что можно увидеть, где подобия и диапазоны согласуются между собой.
-
Прогнозирование
Данный метод (в сочетании с другими методами интеллектуального анализа данных) предполагает анализ тенденций, классификацию, сопоставление с моделью и отношения. Анализируя прошлые события или экземпляры, можно «предсказывать будущее», а точнее строить те самые прогнозы. (Пример – известная сеть кофеен, проанализировав статистику популярности напитка «глинтвейн», было выяснено, что в холодные сезоны она (популярность) гораздо выше, чем во все остальные сезоны, на основании чего руководством кофеен было принято решение закупать вино и корицу заблаговременно перед холодными сезонами).
-
Последовательные модели
Последовательные модели часто используют для анализа долгосрочных данных, что может быть полезно, если поставленной задачей является выявление тенденций или регулярных повторений подобных определенных событий. (Как можно догадаться, данный метод схож с прогнозированием, разница лишь в том, что в методе последовательных моделей задачей является выявление явных циклических повторений, на основе которых строится модель. Прогнозирование же больше склоняется в сторону «гадания», однако не исключает возможности точности расчетов по результатам анализа).
-
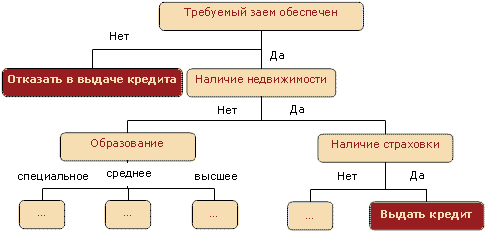
Деревья решений
Данный метод можно использовать либо в рамках критериев отбора, либо для поддержки выбора определенных данных в рамках общей структуры. Дерево решений начинают с простого запроса, который имеет два ответа (или больше, при необходимости). Каждый ответ приводит к следующему вопросу, помогая классифицировать и идентифицировать данные или делать прогнозы. Строение дерева решений похоже на строение блок-схемы в информатике.
-
Комбинации
На практике очень редко используется только один из методов. Методы классификации и кластеризации схожи. Используя кластеризацию для выполнения задачи, можно дополнительно уточнить классификацию. Деревья решений часто используют для построения и выявления классификаций, которые можно прослеживать на исторических периодах для определения последовательностей и моделей.
-
Обработка с запоминанием
При всех основных методах часто имеет смысл записывать и впоследствии изучать полученную информацию. Например, метод деревьев решений для решения реальной задачи вряд ли обойдется единственным деревом. В процессе сбора информации, в исходное дерево будут вноситься изменения, а при невозможности данного действия – строиться новое дерево, с учетом знаний, зафиксированных в предыдущих «версиях» анализа.
Data Mining является мультидисциплинарной областью, возникшей и развивающейся на базе достижений прикладной статистики, распознавания образов, методов искусственного интеллекта, теории баз данных и др. Отсюда обилие методов и алгоритмов, реализованных в различных действующих системах Data Mining. Многие из таких систем интегрируют в себе сразу несколько подходов. Тем не менее, как правило, в каждой системе имеется какая-то ключевая компонента, на которую делается главная ставка.
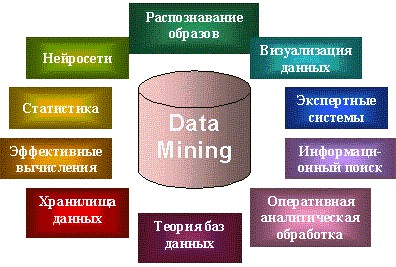
Области применения
-
Розничная торговля
Предприятия розничной торговли сегодня собирают подробную информацию о каждой отдельной покупке, используя кредитные карточки с маркой магазина и компьютеризованные системы контроля. Вот типичные задачи, которые можно решать с помощью Data Mining в сфере розничной торговли:
-
Анализ покупательской корзины (анализ сходства) предназначен для выявления товаров, которые покупатели стремятся приобретать вместе. Знание покупательской корзины необходимо для улучшения рекламы, выработки стратегии создания запасов товаров и способов их раскладки в торговых залах. -
Исследование временных шаблонов помогает торговым предприятиям принимать решения о создании товарных запасов. Оно дает ответы на вопросы типа “Если сегодня покупатель приобрел видеокамеру, то через какое время он вероятнее всего купит новые батарейки и пленку”” -
Создание прогнозирующих моделей дает возможность торговым предприятиям узнавать характер потребностей различных категорий клиентов с определенным поведением, например, покупающих товары известных дизайнеров или посещающих распродажи. Эти знания нужны для разработки точно направленных, экономичных мероприятий по продвижению товаров.
-
Банковское дело
Достижения технологии Data Mining используются в банковском деле для решения следующих распространенных задач: