ВУЗ: Не указан
Категория: Не указан
Дисциплина: Не указана
Добавлен: 17.04.2024
Просмотров: 155
Скачиваний: 0
СОДЕРЖАНИЕ
Информационные системы и их функционирование. Информационная деятельность человека
Представление информации в эвм. Кодирование информации
Основные виды устройств для хранения информации.
Основные внешние устройства компьютера
Операционные системы: их развитие и основные функции.
Концепция ос семействаwindows.
Алгоритмизация и программирование. Алгоритмизация
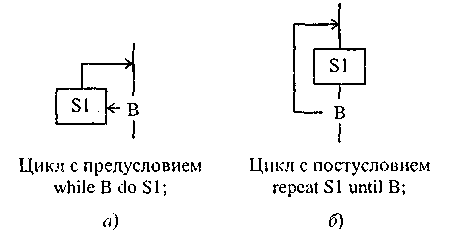
рис. 8. Структура «итерация»
Процесс структурного программирования обычно начинается с разработки блок-схемы. Для представления алгоритма в полном и законченном виде, а также для обозначения связей с окружающей средой добавляют дополнительные структуры ввода-вывода и начала-конца программного блока, модуля, алгоритма:
![]()
Заметим, что для начального шага разработки программы чрезвычайно важным и необходимым является определение исходных (ввод) и выходных (вывод) данных задачи. С этого этапа начинается разработка практически любого алгоритма.Метод разработки программы сверху-вниз предполагает процесс пошагового разбиения алгоритма (блок-схемы) на все более мелкие части до уровня элементарных конструкций, для которых можно составить конкретные команды. Идея структурного программирования сверху-вниз состоит в том, что, если для некоторой функции f существует ее композиция через две другие функции g и h, т.е. F=h(g(x)), то проблема разработки алгоритма для f сводится к проблемам разработки алгоритмов для h и g. В структурном программировании сверху-вниз на каждом шаге пытаются текущую функцию выразить как композицию двух (или более) других функций, которые представимы в виде рассмотренных выше управляющих структур.Зачастую используют метод структурного программирования снизу-вверх. По сути, мы приходим к конечному результату системным методом. Сначала разбиваем задачу на отдельные блоки (модули) с их связями между собой (декомпозиция), затем, после их разработки, проводим сборку блоков в единую программу (синтез). Принцип снизу-вверх широко распространен среди программистов, которые предпочитают модульный подход, предполагающий максимальное использование стандартных и специализированных библиотек процедур, функций, модулей и объектов.
Трансляторы: интерпретаторы и компиляторы.
Практически во всех трансляторах (и в компиляторах, и в интерпретаторах) в том или ином виде присутствует большая часть перечисленных ниже процессов: лексический анализ; синтаксический анализ; семантический анализ; генерация внутреннего представления программы; оптимизация; генерация объектной программы. Транслятор — это программа, которая переводит входную программу на исходном (входном) языке в эквивалентную ей выходную программу на результирующем (выходном) языке. В работе транслятора участвуют всегда три программы: 1) сам транслятор является программой обычно он входит в состав системного по вычислительной системы. То есть транслятор — это часть по. Он представляет собой набор машинных команд и данных и выполняется компьютером, как и все прочие программы в рамках ос. 2)исходными данными для работы транслятора служит текст входной программы — некоторая последовательность предложений входного языка программирования. Этот файл должен содержать текст программы, удовлетворяющий синтаксическим и семантическим требованиям входного языка. 3)выходными данными транслятора является текст результирующей программы. Результирующая программа строится по синтаксическим правилам, заданным в выходном языке транслятора, а ее смысл определяется семантикой выходного языка. Важным требованием в определении транслятора является эквивалентность входной и выходной программ т.е совпадение их смысла с точки зрения семантики входного языка (для исходной программы) и семантики выходного языка (для результирующей программы). Чтобы создать транслятор, необходимо, прежде всего, выбрать входной и выходной языки. С точки зрения преобразования предложений входного языка в эквивалентные им предложения выходного языка транслятор выступает как переводчик. Результатом работы транслятора будет результирующая программа в том случае, если текст исходной программы является правильным — не содержит ошибок с точки зрения синтаксиса и семантики входного языка. Если исходная программа неправильная, то результатом работы транслятора будет сообщение об ошибке. Кроме понятия «транслятор»широко употребляется также близкое ему по смыслу понятие«компилятор».Компилятор — это транслятор, который осуществляет перевод исходной программы в эквивалентную ей объектную программу на языке машинных команд или на языке ассемблера.т.о. Компилятор отличается от транслятора лишь тем, что его результирующая программа всегда должна быть написана на языке машинных кодов или на языке ассемблера. Результирующая программа компилятора называется«объектной программой»или«объектным кодом». Файл, в который она записана, обычно называется«объектным файлом». Порожденная компилятором программа не может непосредственно выполняться на компьютере, так как она не привязана к конкретной области памяти, где должны располагаться ее код и данные..компиляторы, безусловно, самый распространенный вид трансляторов. Они имеют самое широкое практическое применение, которым обязаны широкому распространению всевозможных языков программирования. Сейчас в современных системах программирования стали появляться компиляторы, в которых результирующая программа создается не на языке машинных команд и не на языке ассемблера, а на некотором промежуточном языке. Он не может непосредственно исполняться на компьютере, а требует специального промежуточного интерпретатора, для выполнения написанных на нем программ.интерпретатор — это программа, которая воспринимает входную программу на исходном языке и выполняет ее.в отличие от трансляторов интерпретаторы не порождают результирующую программу — и в этом принципиальная разница между ними. Интерпретатор, так же как и транслятор, анализирует текст исходной программы. Но он не порождает результирующей программы, а сразу же выполняет исходную в соответствии с ее смыслом, заданным семантикой входного языка. Т.о, результатом работы интерпретатора будет некоторый желаемый рез-т(если программа правильна) или сообщение об ошибке. Чтобы исполнить исходную программу, интерпретатор должен преобразовать ее в язык машинных кодов. Полученные машинные коды не доступны пользователю. Они порождаются интер-ом, исполняются и уничтожаются по мере надобности. Пользователь видит результат выполнения этих кодов — т.е результат выполнения исходной программы.
Назначение трансляторов, компиляторов и интерпретаторов
Первыми компиляторами были компиляторы с языков ассемблера или, как они назывались, мнемокодов. Мнемокоды превратили текст программы, написанный на языке машинных команд в более-менее доступный пониманию специалиста язык. Создавать программы стало значительно проще, но исполнять сам мнемокод ни один компьютер неспособен, соответственно, возникла необходимость в создании компиляторов. Следующим этапом стало создание языков высокого уровня. Они представляют собой промежуточное звено между чисто формальными языками и языками естественного общения людей. От первых им досталась строгая формализация синтаксических структуру предложений языка, от вторых — значительная часть словарного запаса, семантика основных конструкций и выражений. Появление языков высокого уровня существенно упростило процесс программирования. Однако преобладают компьютеры традиционной, архитектуры, которые умеют понимать только машинные команды, поэтому вопрос о создании компиляторов продолжает быть актуальным. Компиляторы создавались и продолжают создаваться не только для новых, но и для давно известных языков. С тех пор как большинство теоретических аспектов в области компиляторов получили свою практическую реализацию (это произошло в конце 60-х годов), развитие компиляторов пошло по пути их дружественности пользователю, разработчику программ на языках высокого уровня. Логичным завершением этого процесса стало создание систем программирования — программных комплексов, объединяющих в себе кроме непосредственно компиляторов множество связанных с ними компонентов по.на сегодняшний день компиляторы являются неотъемлемой частью любой вычислительной системы. Без их существования программирование любой прикладной задачи было бы затруднено, а то и просто невозможно. Да и программирование специализированных системных задач, как правило, ведется если не на языке высокого уровня, то на ассемблере, следовательно, применяется соответствующий компилятор. Компиляторы обычно несколько проще в реализации, чем интерпретаторы. По эффективности они также превосходят их — очевидно, что откомпилированный код будет исполняться всегда быстрее, чем происходит интерпретация аналогичной исходной программы. Кроме того, не каждый язык программирования допускает построение простого интерпретатора. Однако, интерпретаторы имеют одно существенное преимущество — откомпилированный код всегда привязан к архитектуре вычислительной системы, на которую он ориентирован, а исходная программа — только к семантике языка программирования, которая гораздо легче поддается стандартизации. Первыми компиляторами были компиляторы с мнемокодов. Их потомки — современные компиляторы с языков ассемблера — существую практически для всех известных вычислительных систем. Они предельно жестко ориентированы на архитектуру. Затем появились компиляторы с таких языков, как fortran, algol-68,. Они были ориентированы на большие эвм с пакетной обработкой задач. Из вышеперечисленных языков, только fortran продолжает использоваться по сей день, поскольку имеет огромное количество библиотек различного назначения. На рынке программных систем доминируют компиляторы языков с и c++. Первый из них родился вместе с операционными системами типа unix, а затем перешел под ос других типов. Второй удачно воплотил в себе пример реализации идей объектно-ориентированного программирования на хорошо зарекомендовавшей себя практической базе. Изначально интерпретаторам не предавали существенного значения, поскольку почти по всем параметрам они уступают компиляторам. Тем не менее сейчас ситуация несколько изменилась, поскольку вопрос о переносимости программ и их аппаратно-платформенной независимости приобретает все большую актуальность с развитием сети интернет. Самый известный сейчас пример — это язык java (сам по себе он сочетает компиляцию и интерпретацию), а также связанный с ним javascript. Кроме того, язык html, на котором зиждется протокол http — это тоже интерпретируемый язык.
Этапы трансляции. Общая схема работы транслятора
Процесс компиляции состоит из двух основных этапов — синтеза и анализа. На этапе анализа выполняется распознавание текста исходной программы, создание и заполнение таблиц идентификаторов. Результатом его работы служит внутреннее представление программы, понятное компилятору. На этапе синтеза на основании внутреннего представления программы и информации, содержащейся в таблице идентификаторов, порождается текст результирующей программы. Результатом этого этапа является объектный код. Кроме того, в составе компилятора присутствует часть, ответственная за анализ и исправление ошибок, которая при наличии ошибки в тексте исходной программы должна максимально полно информировать пользователя о типе ошибки и месте ее возникновения. В лучшем случае компилятор может предложить пользователю вариант исправления ошибки. Эти этапы, в свою очередь, состоят из более мелких этапов, называемых фазами компиляции. Компилятор в целом с точки зрения теории формальных языков выполняет две основные функции. Во-первых, он является распознавателем для языка исходной программы. Т.е он должен получить на вход цепочку символов входного языка, проверить ее принадлежность языку и, более того, выявить правила, по которым эта цепочка была построена. Генератором цепочек входного языка выступает пользователь — автор входной программы. Во-вторых, компилятор является генератором для языка результирующей программы. Он должен построить на выходе цепочку выходного языка по определенным правилам, предполагаемым языком машинных команд или языком ассемблера. Лексический анализ (сканер) — это часть компилятора, которая читает литеры программы на исходном языке и строит из них слова (лексемы) исходного языка. На вход лексического анализатора поступает текст исходной программы, а выходная информация передается для дальнейшей обработки компилятором на этапе синтаксического разбора. Синтаксический разбор — это основная часть компилятора на этапе анализа. Она выполняет выделение синтаксических конструкций в тексте исходной программы, обработанном лексическим анализатором. На этой же фазе компиляции проверяется синтаксическая правильность программы. Синтаксический разбор играет главную роль — роль распознавателя текста входного языка программирования. Семантический анализ — это часть компилятора, проверяющая правильность текста исходной программы с точки зрения семантики входного языка. Кроме непосредственно проверки, семантический анализ должен выполнять преобразования текста, требуемые семантикой входного языка. Подготовка к генерации кода — это фаза, на которой компилятором выполняются предварительные действия, непосредственно связанные с синтезом текста результирующей программы, но еще не ведущие к порождению текста на выходном языке. Генерация кода — это фаза, непосредственно связанная с порождением команд, составляющих предложения выходного языка и в целом текст результирующей программы. Это основная фаза на этапе синтеза результирующей программы. Кроме непосредственного порождения текста результирующей программы, генерация обычно включает в себя также оптимизацию — процесс, связанный с обработкой уже порожденного текста. Таблицы идентификаторов (иногда - «таблицы символов») — это специальным образом организованные наборы данных, служащие для хранения информации об элементах исходной программы, которые затем используются для порождения текста результирующей программы. Таблица идентификаторов в конкретной реализации компилятора может быть одна, а несколько. Элементами исходной программы, информацию о которых нужно хранить в процессе компиляции, являются переменные, константы, функции и т. П. — конкретный состав набора элементов зависит от используемого входного языка программирования. В более общем виде: на фазе лексического анализа лексемы выделяются из текста входной программы постольку, поскольку они необходимы для следующей фазы синтаксического разбора. Синтаксический разбор и генерация кода могут выполняться одновременно. Таким т.о, эти три фазы компиляции могут работать комбинированно, а вместе с ними может выполняться и подготовка к генерации кода.
Понятие прохода. Многопроходные и однопроходные компиляторы
Процесс компиляции программ состоит из нескольких фаз. В реальных компиляторах состав этих фаз может несколько отличаться— некоторые из них могут быть разбиты на составляющие, другие, напротив, объединены в одну фазу. Реальные компиляторы, как правило, выполняют трансляцию текста исходной программы за несколько проходов.
Проход — это процесс последовательного чтения компилятором данных из внешней памяти, их обработки и помещения результата работы во внешнюю память. Чаще всего один проход включает в себя выполнение одной или нескольких фаз компиляции. Результатом промежуточных проходов является внутреннее представление исходной программы, результатом последнего прохода — результирующая объектная программа.
В качестве внешней памяти могут выступать любые носители информации — оперативная память компьютера, накопители на магнитных дисках, магнитных лентах и т. П. Современные компиляторы, как правило, стремятся максимально использовать для хранения данных оперативную память компьютера, и только при недостатке объема доступной памяти используются накопители на жестких магнитных дисках.
При выполнении каждого прохода компилятору доступна информация, полученная в результате всех предыдущих проходов. Он стремится использовать в первую очередь только информацию, полученную на проходе, непосредственно предшествовавшем текущему, но в принципе может обращаться и к данным от более ранних проходов вплоть до исходного текста программы. Информация, получаемая компилятором при выполнении проходов, недоступна пользователю. Она либо хранится в оп, которая освобождается компилятором после завершения процесса трансляции, либо оформляется в виде временных файлов на диске, которые также уничтожаются после завершения работы компилятора. Поэтому человек, работающий с компилятором, может даже не знать, сколько проходов выполняет компилятор — он всегда видит только текст исходной программы и результирующую объектную программу. Но количество выполняемых проходов — это важная техническая характеристика компилятора, солидные фирмы — разработчики компиляторов обычно указывают ее в описании своего продукта.
При сокращении количества проходов, выполняемых компиляторами, скорость его работы увеличивается, при сокращении необходимой ему памяти. Однопроходный компилятор, получающий на вход исходную программу и сразу же порождающий результирующую объектную программу, — это идеальный вариант.