Файл: Мультипроцессоры (ТЕОРЕТИЧЕСКИЕ АСПЕКТЫ МУЛЬТИ ПРОФЕССОРОВ И ИХ ИСПОЛЬЗОВАНИЯ).pdf
Добавлен: 27.06.2023
Просмотров: 157
Скачиваний: 3
СОДЕРЖАНИЕ
ГЛАВА 1 ТЕОРЕТИЧЕСКИЕ АСПЕКТЫ МУЛЬТИ ПРОФЕССОРОВ И ИХ ИСПОЛЬЗОВАНИЯ
1.1 Некоторые этапы из истории освоения массового параллелизма
1.2 Результаты измерений производительности при выполнении алгоритмов БПФ
1.3 Анализ факторов, ограничивающих рост производительности параллельных систем
ГЛАВА 2 ПРАКТИЧЕСКИЕ АСПЕКТЫ ПРИМЕНЕНИЯ МУЛЬТИПРОЦЕССОРОВ
2.1 Обзор работ по коммутационным средам
2.2 Оценка эффективности реализации вычислений
2.3 Архитектура самоопределяемых данных и принципы распределенного управления
2.3 Краткое описание математического аппарата дискретной динамики
Каждый роутер поддерживает некоторое число входящих и исходящих каналов. Внутренние каналы или порты соединяются с локальным процессором/памятью роутера. Кроме того, часто обеспечивается только одна пара внутренних каналов, некоторые системы используют большее число внутренних каналов с целью избежать коммуникационного бутылочного горлышка между локальным процессором/памятью и роутером [22]. Внешние каналы используются для коммуникации между роутерами. Сеть с непосредственным доступом определяется при соединении входящих каналов одного ядра с исходящими каналами других ядер. Два ядра, соединенных напрямую называются соседними. Каналом называют внешний канал. Часто каждое ядро имеет фиксированное число входных и выходных каналов, и каждый входной канал имеет соответствующую пару в виде выходного канала. Имеется больше число способов соединения таких каналов. Очевидно, что каждый узел сети должен быть доступен из любого другого узла сети.[21]
В отличие от непосредственно соединенных сетей, в косвенных сетях для соединения ядер применяется один или несколько переключателей. В случае если имеется несколько переключателей, они непосредственно соединяются между собой. Тогда, при передаче информации от ядра к ядру требуется проход информации через несколько переключателей. И четвертая группа – гибридные сети.
Совершенствование коммутационных сред является одним из главных направлений развития суперкомпьютеров. Основным путем развития суперкомпьютеров является увеличение числа вычислительных элементов. Текущий уровень и скорость развития вычислительных элементов превосходит уровень и темпы развития обменных сред. Рассмотрим некоторые из них:
- Толстое дерево (Fat Tree);
- Бабочка (Butterfly);
- Стрекоза (Dragonfly);
- Тор (Torus).
В больших суперкомпьютерах решающее значение для достижения максимальной производительности имеет сеть межсоединений. Маршрутизация – один из основных аспектов разработки межсоединительных сетей. Стратегия маршрутизации определяет путь каждого пакета, следующего между источником и точкой назначения. Маршрутизация является обусловленной (маршрутизация по закрепленному маршруту), если существует только один предопределенный путь для каждой пары источник - место назначения, или адаптивной, если доступно несколько путей для пакета. Алгоритмы обусловленной маршрутизации обычно обеспечивают очень низкую балансировку трафика в сети, но они гораздо проще для воплощения и обладают неблокируемыми маршрутами. Кроме того, для сетей, в которых важным является заказ сообщений между источником и назначением, обусловленная маршрутизация является простым способом гарантии доставки пакета надлежащим образом. С другой стороны, алгоритмы адаптивной маршрутизации принимают во внимание текущее состояние сети, и решение о маршрутизации пакета принимается на основе этих данных. Такая информация может включать состояние каналов или длину очереди на роутере. Адаптивная маршрутизация обычно лучше балансирует сетевой трафик, тем самым помогая сети получить более высокую пропускную способность за счет повышения стоимости маршрутизаторов.
Алгоритмы адаптивной маршрутизации часто превосходят по производительности алгоритмы с обусловленной маршрутизацией, но данное заявление не является истиной в случае топологий, основанных на толстом дереве. Применение каждого вида обменной среды определяется параметрами конкретной задачи: количество вычислительных ядер, наличие и тип коммутации между ними и т д.
Топология толстое дерево может быть использована только при относительно низком числе коммутируемых процессоров, т.к. с ростом числа этих процессоров усложняется система интерконнекта в геометрической прогрессии, необходимы сложные переключатели, которые будут обеспечивать доступ к данным из разных «ветвей» дерева. На рис. 17 представлена схема коммутации вычислительных элементов в топологии толстой дерево.

Рис. 17 Схема объединения узлов коммутаторами в топологии «толстое дерево».
Топология стрекоза была разработана для использования роутеров с большим числом разъемов и для согласования пределов корпусов / межсоединений высокомасштабных систем. Стрекоза – трехуровневая сеть, которая согласует три уровня иерархии корпусирования. Как показано на рис. 18, на низшем уровне каждый роутер соединен с Р выводами сети. Такие соединения обычно выполняются посредством объединяющей РСВ платы. На втором уровне группы роутеров объединяются локальную сеть. Эти соединения выполняются посредством электрических соединений средней длины с использованием корпусов или небольших групп корпусов. В этой работе мы рассматриваем, прежде всего, топологию стрекоза, где локальная сеть является законченным соединением (одномерная сплюснутая бабочка), где каждый роутер имеет (а-1) локальных соединений с другими роутерами в группе. Большие группы могут быть построены с использованием многомерных сплюснутых бабочек для локальной сети. На самом высоком уровне каждый роутер имеет h глобальных каналов, соединенных с другими группами с применением длинных оптических кабелей. Таким образом, порядок каждого роутера p+a+h-1, и каждая группа имеет a*h глобальных каналов. В сетях максимального размера с топологией типа стрекоза, один глобальный канал соединяется с каждой парой групп.
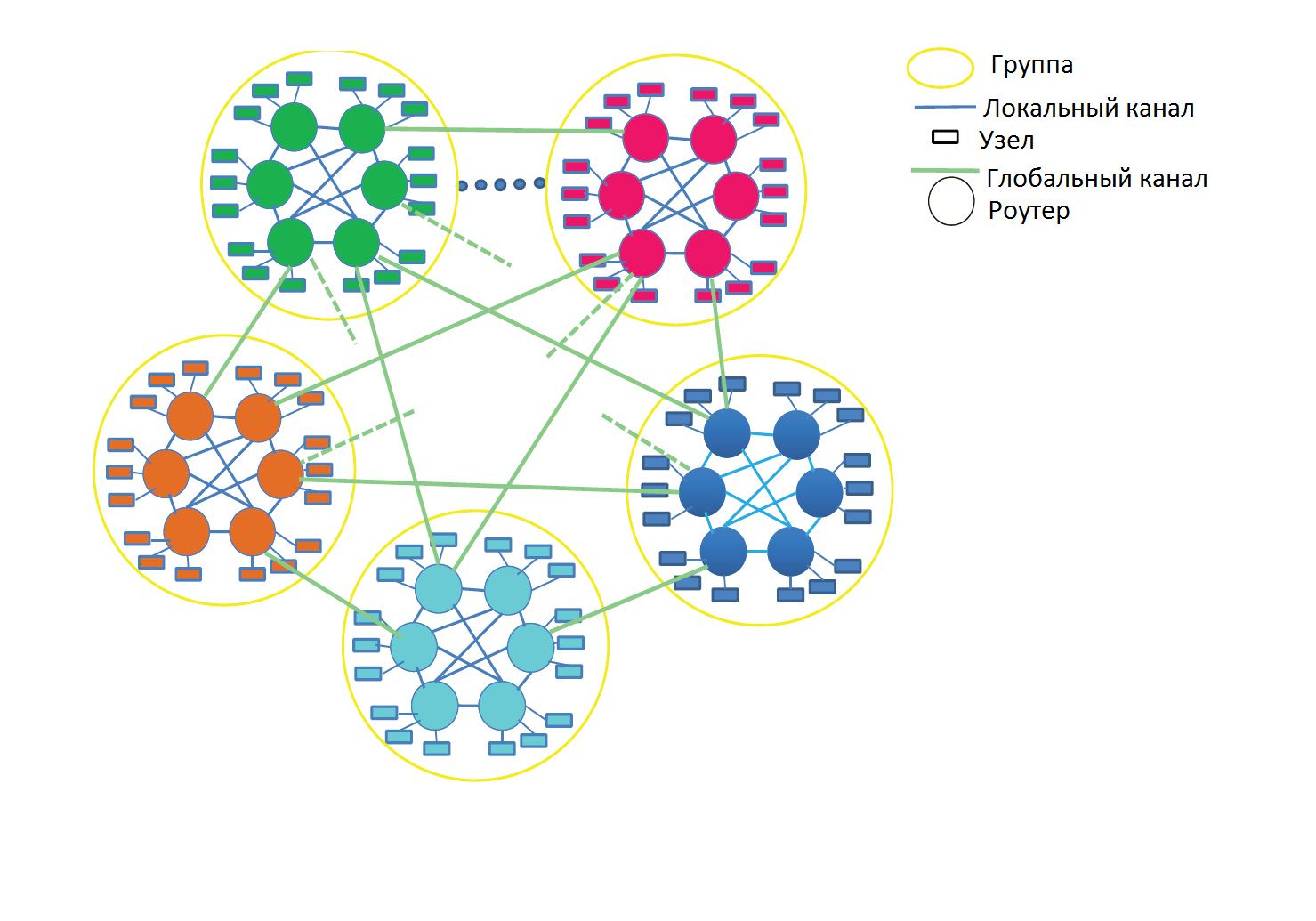
Рис. 18. – Схема объединения узлов коммутаторами в топологии «стрекоза»
Для "доброкачественного" трафика, который балансирует нагрузку на каналы сети, сеть с топологией стрекоза обладает наилучшей минимальной маршрутизацией. Минимальная маршрутизация проходит в три этапа. Сперва пакет маршрутизируется локально от исходящего вывода к глобальному каналу, следуя к группе назначения. Далее пакет передается по глобальному каналу. И в итоге пакет передается в группе назначения к заданному узлу. С минимальной маршрутизацией каждый пакет пересекает один глобальный канал и заданные локальные одномерные сети, всего - два локальных канала.
Сети интерконнекта с топологией «Тор» хорошо подходят для систем коммуникации сетей на чипе, архитектурах связи процессор-память и в коммуникационных сетях. Сеть с топологией тор является хорошо масштабируемой – число элементов сети можно нарастить с относительной легкостью (в сравнении с топологией толстое дерево, где с увеличением числа ядер значительно увеличивается число роутеров и, вместе с тем, сложность сети).[24]
На рис. 19 представлена классическая топология тора размерностью 4х4. В узлах сети находятся переключатели, которые имеют слоты, к которым могут быть подключены такие ресурсы, как процессор, блок памяти, пользовательское оборудование или какое-либо другое периферийное устройство. Предполагается, что переключатели имеют буферные устройства для контроля трафика в сети.[25]

Рис. 19. Схема объединения узлов в сети «двумерный тор» размерностью 4х4.
Теперь же стоит привести сравнение стоимости сетей при различной реализации топологии. Сети интерконнекта встроены в иерархию корпусированных систем. На самом нижнем уровне роутеры соединяются посредством печатных плат, которые, в свою очередь, подключаются к объединительной плате. Одна или несколько таких соединительных плат устанавливаются в корпуса, которые объединяются между собой электрическими или оптическими кабелями для полного формирования системы. Основной составляющей в стоимости сети являются кабели, соединяющие стойки и передатчики, в разъемы которых подключаются такие кабели. [23]. Для снижения стоимости сети необходимо соответствие топологии с характеристиками доступных технологий интерконнекта.
Максимальная ширина полосы пропускания электрического кабеля падает с ростом длины, поскольку имеет место ослабление сигнала по причине линейного увеличения скин-эффекта и поглощения в диэлектрике с ростом длины [25]. Для типовых скоростей передачи сигналов высокой производительности (10-20 Гб/с) и технологических параметров, электрические токопроводящие дорожки ограничены длиной в 1м в печатных платах и 10м в кабелях. На больших дистанциях значительно уменьшается скорость передачи, и становится необходимым встраивание повторителей сигнала, что сказывается на стоимости сети.
Исторически высокая стоимость оптических кабелей ограничивает их применение на очень длинных расстояниях или приложений, требующих высокой производительности вне зависимости от стоимости реализации. На рис. 20 представлено сравнение стоимости активных оптических кабелей Intel Connects Cables [26] и электрических кабелей с повторителями[27].

Рис. 20 Сравнение стоимости электрических кабелей с повторителями и активных оптических кабелей в зависимости от длины кабеля.
Из рисунка видно, что оптические кабели имеют более высокую первоначальную стоимость, но более низкую стоимость за единицу длины. Основываясь на представленных данных, точка пересечения лежит на длине кабеля порядка 10 метров. Для расстояний ниже 10м целесообразно использование электрических кабелей, для расстояния выше 10 м – оптических.
Топология уплощенная бабочка сокращает стоимость сети путем неиспользования промежуточных роутеров и каналов. В результате, стоимость топологии плоская бабочка сокращается примерно на 50% в сравнении с топологией Клос [28] при сбалансированном трафике. Топология стрекоза расширяет топологию плоская бабочка путем увеличения эффективности разъемов роутера для дальнейшего сокращения стоимости и увеличения масштабируемости сети.
Для сетей с топологией стрекоза и плоская бабочка и количеством разъемов до 1000 все роутеры соединены и топологии являются идентичными по количеству роутеров и стоимости. Для полностью соединенных топологий нет выигрыша в стоимости при попытке использования виртуального роутера, т.к. это будет только повышать стоимость сети. Для больших сетей, стрекоза более масштабируема не только потому, что в таких сетях большее эффективное основание роутера, , но и размер группы в два раза больше размера для плоской бабочки, что ведет к более низкой стоимости. Для сетей с числом выводов <4000 стрекоза показывает снижение стоимости порядка 10% по причине снижения средней длины кабеля при тех же размерах в плоской бабочке. Для сетей с >4000 выводов стрекоза обеспечивает 20% снижение стоимости по сравнению с плоской бабочкой по причине более коротких глобальных кабелей.
Стоимость интерконнекта для 3D тора, как показано на рисунке, значительно превосходит стоимость для прочих топологий, поскольку требуется большое число кабелей для обеспечения высокого диаметра сети. Для сетей с 1000 ядер, стрекоза примерно на 62 % дешевле. Сокращение стоимости сети при топологии стрекоза так же трансформируется в сокращение потребляемой мощности как показано в [27].
2.2 Оценка эффективности реализации вычислений
Расположение точки насыщения роста производительности определяется соотношением временных затрат на полезную работу и на издержки разных видов. Естественным образом возникает вопрос – почему в рассмотренных примерах динамика роста производительности параллельных систем ограничивается столь низкими значениями коэффициентов ускорения и степени параллелизма. Это 3-х кратное ускорение при 6 процессорных элементах в примере с моделированием редукционно-потоковой архитектуры и 6-х кратное ускорение при 12 узлах обработки во втором примере? Если определяющим фактором являются соотношения временных затрат на полезную работу и на издержки необходимо провести оценку существующих форм организации вычислений с целью определения источников издержек и возможности их радикального сокращения. Необходимо учитывать, что при распараллеливании процессов издержки, свойственные одному процессорному элементу размножаются кратно показателю параллелизма. Кроме того, порождаются дополнительные издержки обслуживания параллелизма, которые прибавляются к общему грузу издержек и таким образом суммарные издержки растут опережающим темпом. В современных условиях, когда произошло введение критерия эффективности кристалла по показателю числа операций на единицу затрат энергии учет издержек и определение их соотношения к полезной работе кристалла становится критическим показателем, от которого зависит возможность реализации массового параллелизма.
Рассмотрим основные положения классической архитектуры с точки зрения оценки издержек и эффективности организации процессов. Стоит напомнить, что все промышленно выпускаемые в настоящее время вычислительные средства построены по классической архитектуре. Неклассические архитектуры существуют как проекты или модели и не переходят в стадию промышленной реализации. Сущность архитектурной идеи наиболее полно воплощается в знаковой системе, средствами которой осуществляется программирование машины и управление внутренними процессами.
В архитектуре классической машины фон Неймана управление вычислительными процессами осуществляет простейшая знаковая система, называемая линейный императивный язык. Элементами императивного языка являются команды, которые в совокупности образуют функционально полный набор базисных функций. Функциональная полнота базисного набора команд позволяет декларировать тезис алгоритмической универсальности машины - средствами системы команд можно запрограммировать любой алгоритм. Программа представляет собой линейную последовательность команд.