Файл: Литература по теме Тема Информационные технологии пользователя Вопрос Информационные технологии электронного офиса.docx
ВУЗ: Не указан
Категория: Не указан
Дисциплина: Не указана
Добавлен: 25.10.2023
Просмотров: 889
Скачиваний: 8
ВНИМАНИЕ! Если данный файл нарушает Ваши авторские права, то обязательно сообщите нам.
отображается в некоторое поисковое пространство.
При вводе в ИПС нового объекта (реферата) его дескрипторы автоматически включаются в словарь дескрипторов. Каждому дескриптору присваивается номер, называемый индексом дескриптора.
Совокупность индексов, соответствующих полному набору дескрипторов реферата, составляет его поисковый образ.
Новый поисковый образ снабжается уникальным идентификатором и включается в массив поисковых образов. Тем же идентификатором помечается новый реферат, заносимый в массив рефератов.
Поиск в дескрипторной ИПС организуется следующим образом. Пользователь выражает свои информационные потребности средствами и языком поискового пространства, формируя поисковый образ запроса(ПОЗ) к базе документов. Запрос подвергается анализу, в рамках которого выделяются дескрипторы, входящие в словарь дескрипторов. Их совокупность образует поисковое предписание, соответствующее запросу. Оно сопоставляется с поисковыми образами, в результате чего определяется их релевантность. Ответом на запрос является множество рефератов, соответствующих отобранным в процессе поиска идентификаторам.
Схематично общий принцип устройства и функционирования документальных ИПС на основе индексирования представлен на рис. 9.
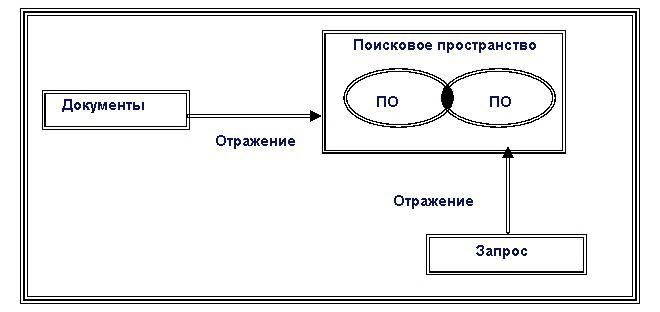
Рис. 9. Общий принцип функционирования документальных ИПС на основе индексирования
В целях ускорения поиска для каждого дескриптора в словаре дескрипторов указывается список идентификаторов рефератов, в которых он встречается. Такая информационная структура ИПС называется индексом.
Заметим, что с помощью дескрипторов можно лишь приблизительно отразить смысл документов. Таким образом, поисковая система может выдать документы, не относящие к данному поисковому запросу и не найти нужные.
Развитием поиска по дескрипторам являются информационно-поисковые системы с полнотекстовым поиском.
В системах, использующих данный вид поиска, индекс формируется на основе всех слов и словосочетаний, содержащихся в документах, за исключением служебных слов (союзов, предлогов и др.). При индексировании слова приводятся к базовой грамматической форме (именительный падеж единственного числа и др.).
В семантически-навигационных системах документы
, помещаемые в хранилище (в базу) документов, оснащаются специальными навигационными конструкциями, соответствующими смысловым связям (отсылкам) между различными документами или отдельными фрагментами одного документа. Такие конструкции реализуют некоторую семантическую (смысловую) сеть в базе документов. Способ и механизм выражения информационных потребностей в подобных системах заключаются в явной навигации пользователя по смысловым отсылкам между документами. В настоящее время такой подход реализуется в гипертекстовых ИПС.
Вопрос 4. Технология обработки запросов.
При вводе документа в систему осуществляется его индексирование и строится его представление, которое будет далее представлять этот документ в процессе функционирования системы и обработки запросов. Когда поступает пользовательский запрос, для него также строится соответствующее представление. Наконец, собственно поиск заключается в том, что каким-либо эффективным образом (не прямым перебором, а обычно с помощью рациональным образом организованного индекса) сопоставляется представление запроса с представлениями хранимых в системе документов по принятому в ней критерию близости. В некоторых случаях для этих целей вводится специальная метрика. Результаты обработки запроса представляются в виде множества найденных релевантных документов.
Хотя на практике используются различного рода представления документов и пользовательских запросов, указанные общие принципы поиска остаются неизменными.
Тезаурусы –специальные словари, которые играют важную роль в анализе и формировании формализованного представления текстовых документов. Это словари основных понятий языка, обозначаемых отдельными словами или словосочетаниями, с определенными семантическими отношениями между ними.
В настоящее время существует два способа создания тезаурусов: вручную и автоматически.
Тезаурус, созданный вручную, может быть универсальным, независимым от конкретной коллекции документов. Он может быть общеязыковым (например, тезаурус русского языка) или ориентированным на какую-либо предметную область. Лексика тезауруса может включать множество слов и/или фраз. В нем могут поддерживаться различные типы семантических связей между лексическими единицами: синонимы, антонимы, связи типа: «целое-часть», «род-вид», «используется для», «работает в» и т.д. Набор связей может быть зависимым или независимым от конкретной предметной области.
К сожалению, разработка тезауруса вручную является весьма дорогостоящим, кропотливым и трудоемким делом, требующим значительных временных затрат. Поэтому на практике часто используют автоматическое создание тезаурусов. Методы решения этой задачи начали исследоваться еще в 60-х гг. XX в.
Создание тезаурусов в автоматическом режимеосуществляется обычно на основе заданных коллекций текстовых документов. Поэтому такие тезаурусы предназначены для работы именно с этими коллекциями.
Для создания тезауруса используется статистическая обработка текстов документов, входящих в данные коллекции. Автоматически построенный тезаурус поддерживает обычно простейший вид связей между лексическими термами, который может быть выявлен статистически, – ассоциативные связи, характеризующие совместное вхождение сочетания этих термов в текст документа.
В системах, использующих тезаурус, можно, например, при поиске по ключевым словам расширять запрос, включая в него синонимы первоначально заданных пользователем ключевых слов и обеспечивая тем самым более полный поиск. Тезаурусы также часто используются для индексирования документов в ручном или автоматическом режиме.
Вопрос 5. Поисковый аппарат.
Существуют различные подходы к построению систем полнотекстового поиска. Это связано, главным образом, с разнообразием информационных потребностей пользователей, которое приводит к необходимости применения различных способов формулировки запросов, а также с различием возможных способов представления содержания текстовых документов в поисковых системах.
Определение модели поиска.
В литературе, посвященной текстовому поиску, одним из ключевых понятий, характеризующих технологию поиска в той или иной конкретной системе, является модельпоиска.
Под моделью поиска понимается сочетание:
способа представления документов;
способа представления поисковых запросов;
вида критерия релевантности документов.
Разнообразие функциональных возможностей различных систем текстового поиска связано именно с различием реализованных в них моделей поиска.
Простейшие модели поиска– это модели, в которых документ представляется в виде набора ассоциированных с ним внешних атрибутов. К числу таких моделей принадлежит модель дескрипторного поиска, а также модель поиска, основанная на «Дублинском ядре».
Модель дескрипторного поиска описана в предыдущих разделах.
Модель поиска, основанная на «Дублинском ядре», основана на хранении метаданных о документе.
Метаданные (англ. metadata) – это информация о документе, понимаемая ЭВМ, т.е. обладающая свойством внутренней интерпретируемости.
Экземпляр метаданных для информационного ресурса выступает в качестве описания данного информационного ресурса. По назначению выделяют четыре основных вида метаданных:
1) описательные – библиографические описания информационных ресурсов и описания их семантики в виде рефератов и аннотаций;
2) структурные – формат, объем и структура информационного ресурса;
3) административные – правообладатели, права на доступ и коррекцию информационного ресурса, сведения о пользователях, платежах и др.;
4) идентифицирующие – служат для однозначного представления описываемых объектов для внешнего мира и приложений.
Наиболее распространенной системой метаданных является «Дублинское ядро». «Дублинское ядро» включает два уровня:
1. Простое «Дублинское ядро».
2. «Дублинское ядро» с квалификаторами.
Состав элементов простого «Дублинского ядра» определен в стандарте ISO 15836:2003.[2] Первый уровень содержит 15 элементов данных, образующих три группы:
1) содержание (англ. Content);
2) интеллектуальная собственность (англ. Intellectual Property);
3) характеристики данного экземпляра информационного ресурса (англ. Instantiation).
На втором уровне к 15 элементам добавлены два дополнительных элемента:
1) целевая аудитория – категория пользователей (англ. Audience);
2) правообладатель (англ. Rights).
Кроме того, для повышения детальности и выразительности описаний на этом уровне вводятся и используются квалификаторы, уточняющие семантику элементов данных и способы представления их значений. Так, например, даты рекомендуется представлять в формате ISO 8601:2004.
Все элементы «Дублинского ядра» являются необязательными и могут повторяться. Порядок их следования в описании информационного ресурса значения не имеет.
Модели, основанные на классификаторах, представляют собой одну из разновидностей простейших моделей, в которых документ выглядит в виде совокупности ассоциированных с ним атрибутов.
В модели, основанной на классификаторах, документы представляются идентификаторами классов в иерархической структуре классификатора, к которым относится данный документ. Представление запроса в простейшем случае – также идентификатор какого-либо класса из заданного классификатора. Критерием релевантности документа является условие, что класс документа совпадает с классом в представлении запроса или является его подклассом.
В более сложном случае в модели поиска, основанной на классификаторах, допускается указание в запросе нескольких классов классификатора. При этом релевантными считаются документы, принадлежащие какому-либо из указанных в запросе классов. Такая модель поиска близка к рассматриваемой далее булевской модели.
Булевские модели – модель поиска,особенность которой заключается в том, что пользователь может формулировать запрос в виде булевского выражения с использованием операторов И, ИЛИ, НЕТ. Термы такого выражения могут быть различными в разных вариациях модели поиска. Это может быть, например, условие вхождения данного слова или словосочетания (с точностью до грамматических форм) в текст документа в булевской модели, ориентированной на контекстный поиск. В булевской модели, ориентированной на поиск по классификаторам, термами выражения могут быть условия принадлежности документа данному классу классификатора. В булевской модели поиска с использованием Дублинского ядра термом может быть равенство, описывающее тот факт, что некоторый элемент метаданных имя рассматриваемого документа имеет заданное в запросе значение. Критерием релевантности данного документа запросу в булевских моделях поиска является истинность булевского выражения, заданного в запросе.
Векторные модели – это более продвинутые модели поиска, различные вариации которых в настоящее время широко применяются на практике. Вероятно, самыми распространенными из них являются векторные модели поиска, называемые иногда также векторными пространствами.
В векторных моделях предполагается, что документы и запросы представляются векторами. В простейшем случае координаты вектора соответствуют термам текста – словам или словосочетаниям, принадлежащим словарю системы, который представляет общеязыковую лексику или лексику предметной области. Каждому терму из такого словаря сопоставляется свое измерение в векторном пространстве. Размерность векторов, представляющих документы и пользовательские запросы, в точности равна количеству измерений в этом пространстве.
Координате вектора присваивается некоторое ненулевое значение в том и только в том случае, когда соответствующий ей терм принадлежит данному документу или запросу. Поскольку размер словаря может быть очень большим, а документы или тексты запросов состоят из существенно меньшего количества содержащихся в нем термов, такие векторы оказываются очень разреженными
При вводе в ИПС нового объекта (реферата) его дескрипторы автоматически включаются в словарь дескрипторов. Каждому дескриптору присваивается номер, называемый индексом дескриптора.
Совокупность индексов, соответствующих полному набору дескрипторов реферата, составляет его поисковый образ.
Новый поисковый образ снабжается уникальным идентификатором и включается в массив поисковых образов. Тем же идентификатором помечается новый реферат, заносимый в массив рефератов.
Поиск в дескрипторной ИПС организуется следующим образом. Пользователь выражает свои информационные потребности средствами и языком поискового пространства, формируя поисковый образ запроса(ПОЗ) к базе документов. Запрос подвергается анализу, в рамках которого выделяются дескрипторы, входящие в словарь дескрипторов. Их совокупность образует поисковое предписание, соответствующее запросу. Оно сопоставляется с поисковыми образами, в результате чего определяется их релевантность. Ответом на запрос является множество рефератов, соответствующих отобранным в процессе поиска идентификаторам.
Схематично общий принцип устройства и функционирования документальных ИПС на основе индексирования представлен на рис. 9.
Рис. 9. Общий принцип функционирования документальных ИПС на основе индексирования
В целях ускорения поиска для каждого дескриптора в словаре дескрипторов указывается список идентификаторов рефератов, в которых он встречается. Такая информационная структура ИПС называется индексом.
Заметим, что с помощью дескрипторов можно лишь приблизительно отразить смысл документов. Таким образом, поисковая система может выдать документы, не относящие к данному поисковому запросу и не найти нужные.
Развитием поиска по дескрипторам являются информационно-поисковые системы с полнотекстовым поиском.
В системах, использующих данный вид поиска, индекс формируется на основе всех слов и словосочетаний, содержащихся в документах, за исключением служебных слов (союзов, предлогов и др.). При индексировании слова приводятся к базовой грамматической форме (именительный падеж единственного числа и др.).
В семантически-навигационных системах документы
, помещаемые в хранилище (в базу) документов, оснащаются специальными навигационными конструкциями, соответствующими смысловым связям (отсылкам) между различными документами или отдельными фрагментами одного документа. Такие конструкции реализуют некоторую семантическую (смысловую) сеть в базе документов. Способ и механизм выражения информационных потребностей в подобных системах заключаются в явной навигации пользователя по смысловым отсылкам между документами. В настоящее время такой подход реализуется в гипертекстовых ИПС.
Вопрос 4. Технология обработки запросов.
При вводе документа в систему осуществляется его индексирование и строится его представление, которое будет далее представлять этот документ в процессе функционирования системы и обработки запросов. Когда поступает пользовательский запрос, для него также строится соответствующее представление. Наконец, собственно поиск заключается в том, что каким-либо эффективным образом (не прямым перебором, а обычно с помощью рациональным образом организованного индекса) сопоставляется представление запроса с представлениями хранимых в системе документов по принятому в ней критерию близости. В некоторых случаях для этих целей вводится специальная метрика. Результаты обработки запроса представляются в виде множества найденных релевантных документов.
Хотя на практике используются различного рода представления документов и пользовательских запросов, указанные общие принципы поиска остаются неизменными.
Тезаурусы –специальные словари, которые играют важную роль в анализе и формировании формализованного представления текстовых документов. Это словари основных понятий языка, обозначаемых отдельными словами или словосочетаниями, с определенными семантическими отношениями между ними.
В настоящее время существует два способа создания тезаурусов: вручную и автоматически.
Тезаурус, созданный вручную, может быть универсальным, независимым от конкретной коллекции документов. Он может быть общеязыковым (например, тезаурус русского языка) или ориентированным на какую-либо предметную область. Лексика тезауруса может включать множество слов и/или фраз. В нем могут поддерживаться различные типы семантических связей между лексическими единицами: синонимы, антонимы, связи типа: «целое-часть», «род-вид», «используется для», «работает в» и т.д. Набор связей может быть зависимым или независимым от конкретной предметной области.
К сожалению, разработка тезауруса вручную является весьма дорогостоящим, кропотливым и трудоемким делом, требующим значительных временных затрат. Поэтому на практике часто используют автоматическое создание тезаурусов. Методы решения этой задачи начали исследоваться еще в 60-х гг. XX в.
Создание тезаурусов в автоматическом режимеосуществляется обычно на основе заданных коллекций текстовых документов. Поэтому такие тезаурусы предназначены для работы именно с этими коллекциями.
Для создания тезауруса используется статистическая обработка текстов документов, входящих в данные коллекции. Автоматически построенный тезаурус поддерживает обычно простейший вид связей между лексическими термами, который может быть выявлен статистически, – ассоциативные связи, характеризующие совместное вхождение сочетания этих термов в текст документа.
В системах, использующих тезаурус, можно, например, при поиске по ключевым словам расширять запрос, включая в него синонимы первоначально заданных пользователем ключевых слов и обеспечивая тем самым более полный поиск. Тезаурусы также часто используются для индексирования документов в ручном или автоматическом режиме.
Вопрос 5. Поисковый аппарат.
Существуют различные подходы к построению систем полнотекстового поиска. Это связано, главным образом, с разнообразием информационных потребностей пользователей, которое приводит к необходимости применения различных способов формулировки запросов, а также с различием возможных способов представления содержания текстовых документов в поисковых системах.
Определение модели поиска.
В литературе, посвященной текстовому поиску, одним из ключевых понятий, характеризующих технологию поиска в той или иной конкретной системе, является модельпоиска.
Под моделью поиска понимается сочетание:
способа представления документов;
способа представления поисковых запросов;
вида критерия релевантности документов.
Разнообразие функциональных возможностей различных систем текстового поиска связано именно с различием реализованных в них моделей поиска.
Простейшие модели поиска– это модели, в которых документ представляется в виде набора ассоциированных с ним внешних атрибутов. К числу таких моделей принадлежит модель дескрипторного поиска, а также модель поиска, основанная на «Дублинском ядре».
Модель дескрипторного поиска описана в предыдущих разделах.
Модель поиска, основанная на «Дублинском ядре», основана на хранении метаданных о документе.
Метаданные (англ. metadata) – это информация о документе, понимаемая ЭВМ, т.е. обладающая свойством внутренней интерпретируемости.
Экземпляр метаданных для информационного ресурса выступает в качестве описания данного информационного ресурса. По назначению выделяют четыре основных вида метаданных:
1) описательные – библиографические описания информационных ресурсов и описания их семантики в виде рефератов и аннотаций;
2) структурные – формат, объем и структура информационного ресурса;
3) административные – правообладатели, права на доступ и коррекцию информационного ресурса, сведения о пользователях, платежах и др.;
4) идентифицирующие – служат для однозначного представления описываемых объектов для внешнего мира и приложений.
Наиболее распространенной системой метаданных является «Дублинское ядро». «Дублинское ядро» включает два уровня:
1. Простое «Дублинское ядро».
2. «Дублинское ядро» с квалификаторами.
Состав элементов простого «Дублинского ядра» определен в стандарте ISO 15836:2003.[2] Первый уровень содержит 15 элементов данных, образующих три группы:
1) содержание (англ. Content);
2) интеллектуальная собственность (англ. Intellectual Property);
3) характеристики данного экземпляра информационного ресурса (англ. Instantiation).
На втором уровне к 15 элементам добавлены два дополнительных элемента:
1) целевая аудитория – категория пользователей (англ. Audience);
2) правообладатель (англ. Rights).
Кроме того, для повышения детальности и выразительности описаний на этом уровне вводятся и используются квалификаторы, уточняющие семантику элементов данных и способы представления их значений. Так, например, даты рекомендуется представлять в формате ISO 8601:2004.
Все элементы «Дублинского ядра» являются необязательными и могут повторяться. Порядок их следования в описании информационного ресурса значения не имеет.
Модели, основанные на классификаторах, представляют собой одну из разновидностей простейших моделей, в которых документ выглядит в виде совокупности ассоциированных с ним атрибутов.
В модели, основанной на классификаторах, документы представляются идентификаторами классов в иерархической структуре классификатора, к которым относится данный документ. Представление запроса в простейшем случае – также идентификатор какого-либо класса из заданного классификатора. Критерием релевантности документа является условие, что класс документа совпадает с классом в представлении запроса или является его подклассом.
В более сложном случае в модели поиска, основанной на классификаторах, допускается указание в запросе нескольких классов классификатора. При этом релевантными считаются документы, принадлежащие какому-либо из указанных в запросе классов. Такая модель поиска близка к рассматриваемой далее булевской модели.
Булевские модели – модель поиска,особенность которой заключается в том, что пользователь может формулировать запрос в виде булевского выражения с использованием операторов И, ИЛИ, НЕТ. Термы такого выражения могут быть различными в разных вариациях модели поиска. Это может быть, например, условие вхождения данного слова или словосочетания (с точностью до грамматических форм) в текст документа в булевской модели, ориентированной на контекстный поиск. В булевской модели, ориентированной на поиск по классификаторам, термами выражения могут быть условия принадлежности документа данному классу классификатора. В булевской модели поиска с использованием Дублинского ядра термом может быть равенство, описывающее тот факт, что некоторый элемент метаданных имя рассматриваемого документа имеет заданное в запросе значение. Критерием релевантности данного документа запросу в булевских моделях поиска является истинность булевского выражения, заданного в запросе.
Векторные модели – это более продвинутые модели поиска, различные вариации которых в настоящее время широко применяются на практике. Вероятно, самыми распространенными из них являются векторные модели поиска, называемые иногда также векторными пространствами.
В векторных моделях предполагается, что документы и запросы представляются векторами. В простейшем случае координаты вектора соответствуют термам текста – словам или словосочетаниям, принадлежащим словарю системы, который представляет общеязыковую лексику или лексику предметной области. Каждому терму из такого словаря сопоставляется свое измерение в векторном пространстве. Размерность векторов, представляющих документы и пользовательские запросы, в точности равна количеству измерений в этом пространстве.
Координате вектора присваивается некоторое ненулевое значение в том и только в том случае, когда соответствующий ей терм принадлежит данному документу или запросу. Поскольку размер словаря может быть очень большим, а документы или тексты запросов состоят из существенно меньшего количества содержащихся в нем термов, такие векторы оказываются очень разреженными