Файл: Литература по теме Тема Информационные технологии пользователя Вопрос Информационные технологии электронного офиса.docx
ВУЗ: Не указан
Категория: Не указан
Дисциплина: Не указана
Добавлен: 25.10.2023
Просмотров: 900
Скачиваний: 8
ВНИМАНИЕ! Если данный файл нарушает Ваши авторские права, то обязательно сообщите нам.
Рис. 15. Иерархическая древовидная структура модели БД
Поиск данных в иерархической системе всегда начинается с корня. Затем производится спуск с одного уровня дерева на другой, пока не будет достигнут искомый уровень. Перемещения по системе от одной записи к другой осуществляются с помощью ссылок.
Если структура запроса совпадает со структурой иерархической БД, то такая модель обладает самым высоким быстродействием и потому чаще всего применяется в супер ЭВМ.
В противном случае, быстродействие может резко снизиться, т.к. не удобно всегда начинать поиск нужных данных с корня, а другого способа перемещения по базе в иерархических структурах нет. Достоинства и недостатки иерархической модели представлены в таблице 2.
Таблица 2.
| Достоинства | Недостатки |
| Простота описания предметной области | Сложность добавления новых и удаления существующих типов записей |
| Наглядность | Невозможность отображения отношений, отличающихся от иерархических |
| Удобство анализа структур | Громоздкость описания |
| Быстрое выполнение запросов | Информационная избыточность |
| | Поиск данных всегда начинается с корня, что иногда значительно замедляет быстродействие |
Базы данных с иерархической моделью одни из самых старых. Они стали первыми системами управления базами данных для мейнфреймов. Разрабатывались в 1950-х и 1960-х, например, Information Management System (IMS) фирмы IBM (создана в 1968 г. в рамках проекта высадки на Луну – «Аполлон»).
Сетевая модель данных.
В 1963 году С. Бахман построил первую промышленную базу данных IDS с сетевой моделью данных. В 1969 г. сформировалась группа, создавшая набор стандартов CODASYL (КОДАСИЛ) для сетевой модели данных.
Сетевая модель данных основана на представлении информации в виде орграфа, в котором в каждую вершину может входить произвольное число дуг. Вершинам графа сопоставлены типы записей, дугам – связи между ними. В сетевой модели (по крайней мере, теоретически) возможны связи всех информационных объектов со всеми.
На рис. 16, 17. представлены примеры структуры сетевой модели данных.
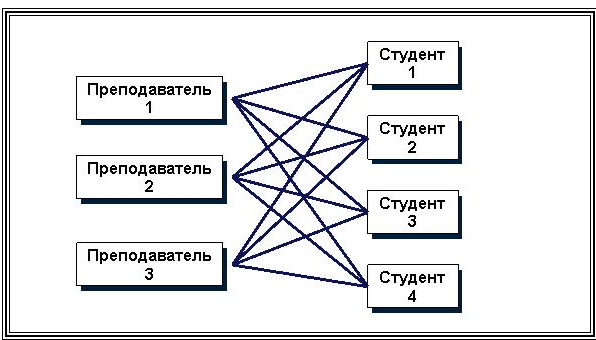
Рис. 16. Сетевая структура модели БД
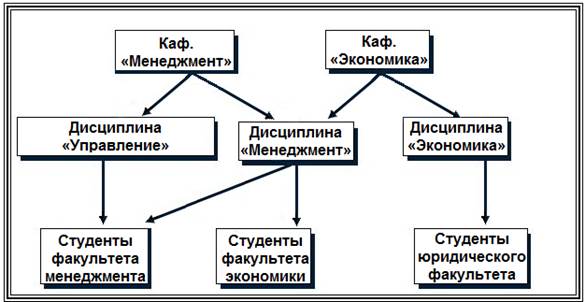
Рис. 17. Фрагмент сетевой модели данных
По сравнению с иерархическими сетевые модели обладают рядом существенных преимуществ:
возможность отображения практически всего многообразия взаимоотношений объектов предметной области;
непосредственный доступ к любой вершине сети (без указания других вершин);
малая информационная избыточность.
Вместе с тем, в сетевой модели невозможно достичь полной независимости данных, поскольку с ростом объема информации сетевая структура становится весьма сложной для описания и анализа.
Использование иерархической и сетевой моделей ускоряет доступ к информации в базе данных. Однако, поскольку каждый элемент данных должен содержать ссылки на некоторые другие элементы, требуются значительные ресурсы как дисковой, так и основной памяти ЭВМ. Недостаточность основной памяти, конечно, снижает скорость обработки данных. Кроме того, для таких моделей характерна сложность реализации системы управления базами данных.
Реляционная модель данных.
Реляционная модель (от англ. relation – отношение) была разработана в начале 70-х годов XX в. Коддом. Простота и гибкость этой модели привлекли к ней внимание разработчиков, и уже в 80-х годах XX в. она получила широкое распространение. Таким образом, реляционные СУБД оказались промышленным стандартом.
В основе реляционной модели данных лежат не графические, а табличные методы и средства представления данных и манипулирования ими (рис. 18).
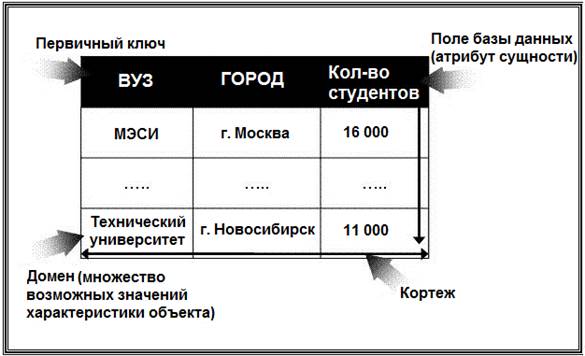
Рис. 18. Фрагмент реляционной модели данных
Реляционная модель опирается на систему понятий реляционной алгебры, важнейшими из которых являются таблица, строка, столбец, отношение и первичный ключ. Следовательно, все операции сводятся к манипуляциям с таблицами. Строка такой таблицы называется кортежем, столбец – атрибутом. Каждый атрибут может принимать некоторое подмножество значений из определенной области –
домена.
Таблица отражает объект реального мира – сущность, а каждая ее строка (запись) отражает один конкретный экземпляр объекта – экземпляр сущности. Каждый столбец таблицы имеет уникальное для данной таблицы имя. Располагаются столбцы в соответствии с порядком следования их имен, принятом при создании таблицы.
Реляционные системы исключили необходимость сложной навигации, поскольку данные представлены в них не в виде одного файла, а независимыми наборами, и для отбора данных используются операции реляционной алгебры: прикладной теории множеств.
В каждой таблице реляционной модели должен быть столбец (или совокупность столбцов), значение которого однозначно идентифицирует каждую ее строку. Этот столбец (или совокупность столбцов) и называется первичным ключом таблицы (рис. 19).
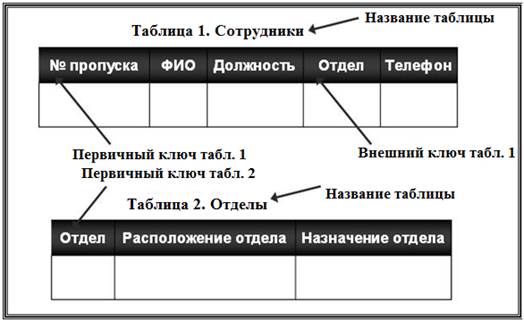
Рис. 19. Организация ссылки от одной таблицы к другой
Если таблица удовлетворяет требованию уникальности первичного ключа, она называется отношением. В реляционной модели все таблицы должны быть преобразованы в отношения. Отношения реляционной модели связаны между собой. Связи поддерживаются внешними ключами. Внешний ключ – это столбец (совокупность столбцов), значение которого однозначно характеризует значения первичного ключа другого отношения (таблицы).
Говорят, что отношение, в котором определен внешний ключ, ссылается на соответствующее отношение, в котором та же совокупность столбцов является первичным ключом. Схема реляционной таблицы (отношения) представляет собой совокупность имен полей, образующих ее запись:
НАЗВАНИЕ ТАБЛИЦЫ (Поле 1, Поле 2, ..., Поле n).
Например, для таблиц, показанных на рис. 19, имеем следующие схемы:
СОТРУДНИК (Номер пропуска, ФИО, Должность, Название отдела, Телефон).
ОТДЕЛ (Название отдела, Расположение отдела, Назначение отдела).
Подавляющее большинство СУБД, ориентированных на персональные ЭВМ, являются системами, построенными на основе реляционной модели данных, так называемыми «реляционными» СУБД.
Доминирование реляционной модели в современных СУБД определяется наличием:
развитой теории (реляционной алгебры);
аппарата сведения других моделей данных к реляционной модели;
специальных средств ускоренного доступа к информации;
стандартизированного высокоуровневого языка запросов к БД, позволяющего манипулировать ими без знания конкретной физической организации БД во внешней памяти.
Объектно-ориентированная модель.
Объектно-ориентированная модель баз данных начала разрабатываться в связи с появлением объектно-ориентированных языков программирования в 90-е годы XX в. Это одна из самых перспективных и прогрессивных моделей баз данных, существующих в настоящее время. В этой модели база данных, интерфейс пользователя и алгоритм приложения построены с использованием объектно-ориентированного подхода.
Объектно-ориентированная СУБД должна поддерживать объекты с нелинейной структурой (сложные объекты, в том числе с иерархией объектов), что достигается инкапсуляцией и наследованием. Такого рода базы хранят методы классов, а иногда и постоянные объекты классов, что позволяет осуществлять беспрепятственную интеграцию между данными и их обработкой в приложениях. Легко поддерживается расширяемость, вычислительная полнота, языки запроса.
В 1991 г. была сформирована группа Object Database Management Group (ODMG), целью которой было – построить стандарты для объектно-ориентированной базы данных (ООБД). В 1993 г. был предложен стандарт ODMG-3 для ООБД, который включает:
1) объектную модель Object Data Model (ODM);
2) язык определения объектов Object Definition Language (ODL);
3) объектный язык запроса Object Query Language (OQL);
4) интерфейсы языков программирования (С++ и др.).
Суть ООБД определяется объектно-ориентированным подходом, который включает объектно-ориентированное проектирование и объектно-ориентированное программирование.
Чтобы построить ООБД, нужно, чтобы все структурные элементы реализации были спроектированы с использованием объектно-ориентированного подхода. Для этого необходимо:
провести инкапсуляцию данных, т.е. выделить классы и объекты;
определить возможные виды структуры реализуемых таблиц;
создать наследование классов данных;
обеспечить полиморфизм.
Базовым языком ООБД чаще всего является С++. Для работы с такими ООБД разрабатывается новый вариант языка программирования SQL, получивший название SQL3, содержащий внутри себя в качестве частного случая SQL2.
В настоящее время насчитывается несколько сотен объектно-ориентированных СУБД. Наиболее широкое применение объектно-ориентированные базы данных нашли в таких областях, как системы автоматизированного конструирования/производства (CAD/CAM), системы автоматизированной разработки программного обеспечения (CASE), системы управления составными документами.
Так, например, компания Enterprise Integration Tecnologies предлагает продукт MKS (Manufacturing Knowledge System – система знаний о производстве). В рамках этого продукта возможно интегрировать разработку технологических процессов, разработку оборудования, управление предприятием, проектирование производственных помещений, диагностику, мониторинг, моделирование и планирование.
В России получила широкое распространение СУБД Cashe фирмы InterSystems, апробированная и хорошо проявившая себя в банках. В данной СУБД предусмотрен объектный доступ (объектно-ориентированная модель) и SQL-доступ (реляционная модель с использованием языка SQL2). Хранение данных осуществляется с помощью многомерной модели данных, позволяющей уменьшить объем потребной памяти при одновременном увеличении скорости доступа к данным.
В последнее время объектно-ориентированные СУБД все чаще применяют как составную часть другого приложения. Например, компания Computervision, производящая программное обеспечение CAD, интегрировало в свой продукт СУБД ObjectStory. Американские фирмы Aotorol Technology, Step Tools, Dec используют ООСУБД ObjectStory для работы со слабо структурированными данными в стандарте обмена данными STEP (Standard of Exchange of Product model data).
Вопрос 6. Программные средства реализации фактографических ИС.
Подавляющее большинство фактографических информационных систем, ориентированных на персональные ЭВМ, построены на основе реляционной модели данных, так называемых «реляционных» СУБД. Группа реляционных СУБД представлена на рынке программных продуктов очень широко. Например, системы dBase, Paradox, FoxPro, Access.
dBase – семейство широко распространённых систем управления базами данных, а также язык программирования, используемый в них. В настоящее время используется версия dBase IV.
Хранение данных в dBase основано на принципе «одна таблица – один файл» (эти файлы обычно имеют расширение *.dbf). МЕМО-поля и BLOB-поля (доступные в поздних версиях dBase) хранятся в отдельных файлах (обычно с расширением *.dbt). Индексы для таблиц также хранятся в отдельных файлах. При этом в ранних версиях этой СУБД требовалась специальная операция реиндексирования для приведения индексов в соответствие с текущим состоянием таблицы.