ВУЗ: Не указан
Категория: Не указан
Дисциплина: Не указана
Добавлен: 29.10.2023
Просмотров: 311
Скачиваний: 6
ВНИМАНИЕ! Если данный файл нарушает Ваши авторские права, то обязательно сообщите нам.
Кластеризация – процесс как можно более близкого физического размещения на диске, логически связанных между собой и часто используемых данных.
Кластеризация внутрифайловая и межфайловая
Говорят, о внутрифайловой кластеризации, когда она осуществляется в рамках одного хранимого файла. Например, если в системе часто требуется осуществлять доступ к данным согласно порядковому номеру, то все записи следует физически размещать таким образом, чтобы первая запись была возле второй записи, вторая запись - возле третьей и т. д.
При межфайловой кластеризации ею охватываются одновременно несколько файлов. Это используют, если в системе часто требуется осуществлять доступ к записям и данным, связанным друг с другом, при этом первые стараются разместить радом со вторыми.
Внутрифайловую и межфайловую кластеризацию СУБД может осуществлять, размещая логически связанные записи на одной странице, если это возможно, или на соседних страницах.
Диспетчер дисков – программное обеспечение, контролирующее перемещение страниц между оперативной памятью и диском.
Извлечь, добавить, заменить, удалить страницу из набора страниц
Диспетчер дисков является компонентом используемой операционной системы, с помощью которого выполняются все дисковые операции ввода-вывода. Для выполнения этих операций необходимо знать значения физических адресов на диске
Что означает обеспечение целостности данных?
Ответ в 5 вопросе
При записи или обновление (INSERT, UPDATE) операции занимают разное время, если есть индекс, то время гораздо увеличится, то отсутствие индекса в таком случает ускоряет запись или обновление.
При чтении операции ускорятся если есть индекс по полю, по которому происходи выборка, если нет необходимого индекса, то придется прочесть всю таблицу.
Атрибут соответствует столбцу этой таблицы, а именно – свойствам объектов, сведения о которых хранятся в ней. В конкретных СУБД атрибуты часто называют полями.
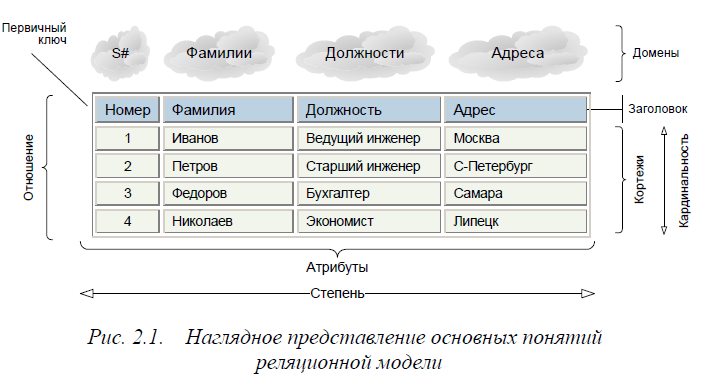
Бинарное дерево — это иерархическая структура данных, в которой каждый узел имеет одно значение (оно же является в данном случае и ключом) и ссылки на двух потомков.
Узел, находящийся на самом верхнем уровне (не являющийся чьим-либо потомком), называется корнем.
Узлы, не имеющие потомков (оба потомка которых равны NULL) называются листьями.
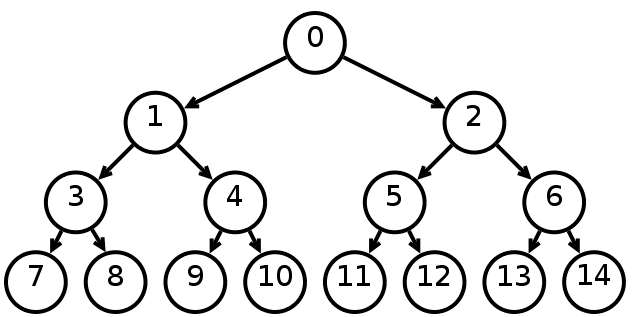
Бинарное дерево поиска — это бинарное дерево, обладающее дополнительными свойствами: значение левого потомка меньше значения родителя, а значение правого потомка больше значения родителя для каждого узла дерева. То есть, данные в бинарном дереве поиска хранятся в отсортированном виде.
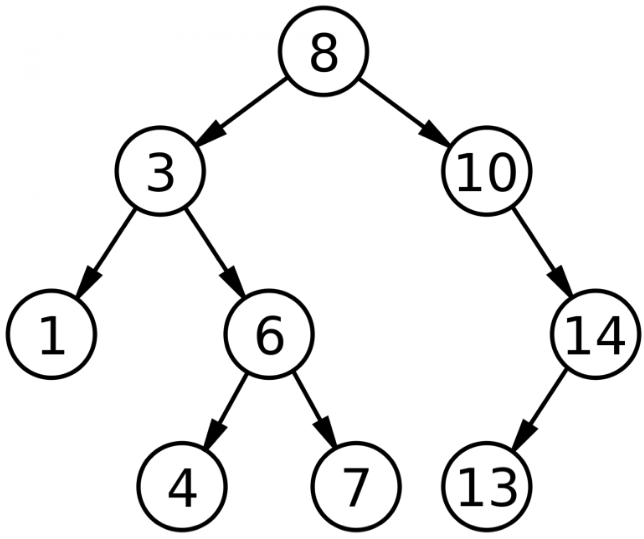
Бинарное дерево поиск используется в индексном файле, для быстрого поиска и сортировки данных. Скорость алгоритма = log2 (n), где n – количество записей в таблице
B-дерево — это особый тип бинарного дерева поиска, в котором каждый узел может содержать более одного ключа (узел хранит более одного значения) и иметь более двух дочерних элементов.
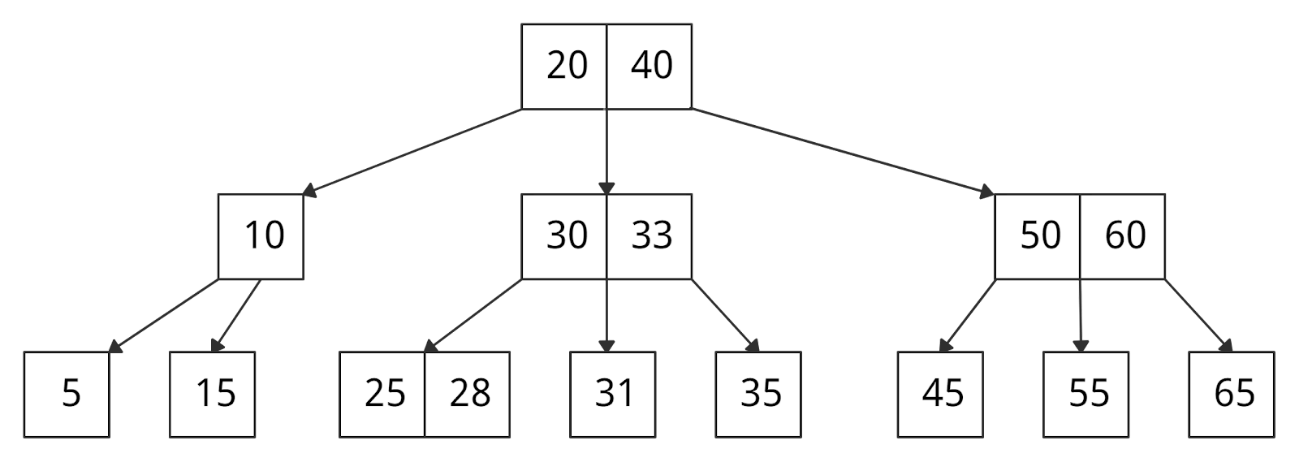
Скорость поиска данных происходит быстрее чем в бинарном. Логарифмическая функция.
В реляционных базах данных кортеж — это элемент отношения (запись (строка) в таблице).
Для N-арного отношения кортеж представляет собой упорядоченный набор из N значений, по одному значению для каждого атрибута отношения.
Отношением называется вся таблица (файл)
Многоуровневый индекс — это индекс, состоящий из нескольких индексных файлов, при этом только индекс первого уровня ссылается на реальные данные (обычно это плотный индекс), а индексы более высоких уровней ссылаются на предыдущие уровни (эти индексы обязательно неплотные).
В плотных для каждого значения ключа имеется отдельная запись индекса, указывающая место размещения конкретной записи.
Неплотные (разреженные) индексы строятся в предположении, что на каждой странице памяти хранятся записи, отсортированные по значениям индексируемого атрибута. Тогда для каждой страницы в индексе задаётся диапазон значений ключей хранимых в ней записей, и поиск записи осуществляется среди записей на указанной странице.
Структура многоуровневого индекса за счет увеличения объема данных позволяет сократить время поиска записей, т.к. данные уже разбиты на фрагменты, которые бы получались, например, в результате бинарного поиска.
Многоуровневый индекс вводится при наличии в файле данных большого числа записей, обычно при условии, что бинарный поиск в одноуровневом плотном индексе проводится за значительное число шагов. Поиск данных в многоуровневом индексе начинается с самого верхнего уровня и продолжается пока не будет достигнута запись данных, поиск ссылки на следующий уровень на текущем уровне проводится методом двоичного поиска в определенном диапазоне.
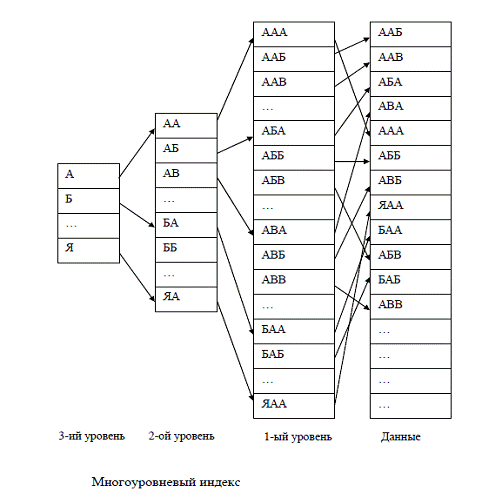
Аналогом является многоуровневый индекс.
Инвертированный список в общем случае — это двухуровневая индексная структура.
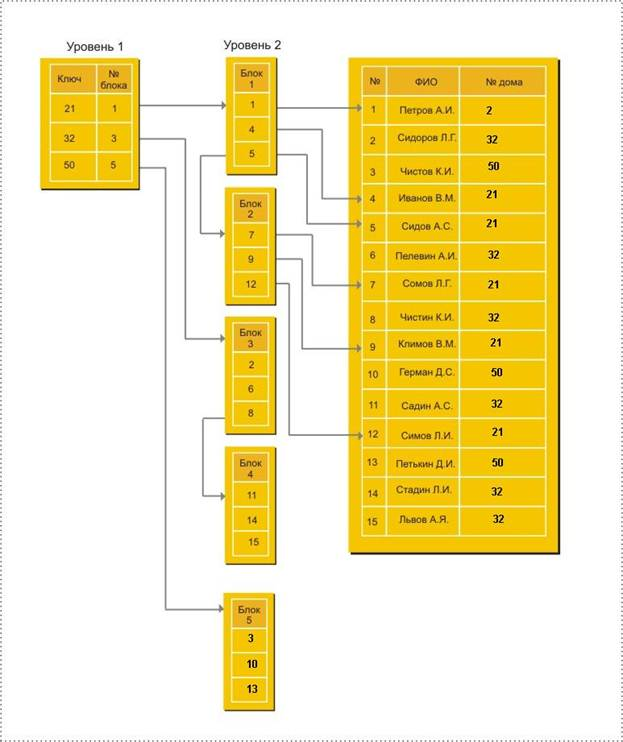
Здесь на первом уровне находится файл или часть файла, в которой упорядоченно расположены значения вторичных ключей. Каждая запись с вторичным ключом имеет ссылку на номер первого блока в цепочке блоков, содержащих номера записей с данным значением вторичного ключа.
Основным преимуществом использования индексирования является значительное ускорение процесса выборки, сортировки.
Основным недостатком замедления процесса обновления данных так как при каждом добавлении новой записи в индексированный файл потребуется также добавить новые индекс в индексный файл.
Индекс – это объект базы данных, обеспечивающий быстрый доступ к строкам таблицы на основе значений одного или нескольких столбцов, а также служит для сортировки данных.
Индексный файл — это файл в котором хранится информация об индексе.
Нормализация – это метод проектирования базы данных, который позволяет привести базу данных к минимальной избыточности.
Избыточность данных создает предпосылки для появления различных аномалий, снижает производительность, и делает управление данными не гибким и не очень удобным.
Избыточность данных – это когда одни и те же данные хранятся в базе в нескольких местах, именно это и приводит к аномалиям.
Поэтому нормализация нужна для
Устранения аномалий
Аномалия обновления – обновлять придется все возможные данные, где присутствуют данные, которые мы хотели обновить, снижается производительности БД, иначе если не обновить все записи то будут артефакты чтения и записи (противоречивость данных)
Аномалия удаления – помимо удаления необходимой информации, удаляется и избыточная (происходит потеря данных).
Повышения производительности
Повышения удобства управления данными
Избыточность устраняется, как правило, за счёт декомпозиции отношений (таблиц), т.е. разбиения одной таблицы на несколько.
Процесс нормализации – это последовательный процесс приведения базы данных к эталонному виду, т.е. переход от одной нормальной формы к следующей.
Нормальная форма базы данных – это набор правил и критериев, которым должна отвечать база данных.
Первая нормальная форма (1NF), Вторая нормальная форма (2NF), Третья нормальная форма (3NF), Нормальная форма Бойса-Кодда (BCNF), Четвертая нормальная форма (4NF), Пятая нормальная форма (5NF)
Данные в таблицах удовлетворяют следующим принципам:
– Каждое значение, содержащееся на пересечении строки и колонки, должно быть атомарным (т. е. не расчленяемым на несколько значений).
– Значения данных в одной и той же колонке должны принадлежать к одному типу, доступному для исполнения в данной СУБД.
– Каждая запись в таблице уникальна, т. е. в таблице не существует двух записей с полностью совпадающим набором значений ее полей.
– Каждое поле имеет уникальное имя.
– Последовательность полей в таблице несущественна
2 вопрос
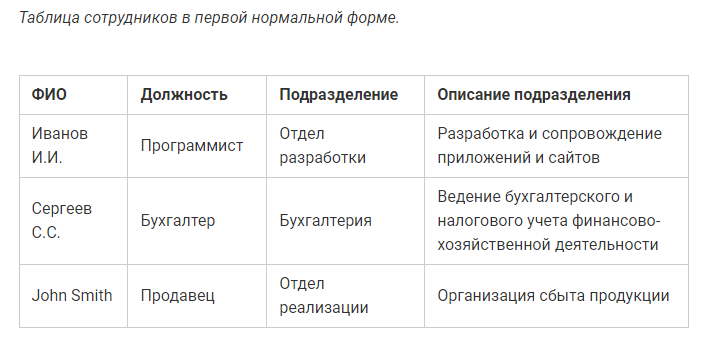
Первая нормальная форма: таблица базы данных – это представление сущности вашей системы, которую вы создаете. Каждая запись в базе данных представляет один экземпляр сущности.
Например, в таблице клиентов каждая запись представляет одного клиента.
Требования:
Таблица не должна иметь дублирующих строк (кортежей).
Первая форма не предусматривает обязательное наличие первичного ключа.
Каждое поле содержит только одно значение, то есть атомарные данные (не делимая информация).
Данные типизированы
Таблица не имеет поля, которые хранят в себе информацию одинаковую по смыслу
Вторая нормальная форма связана с избыточностью данных.
Требования:
Поля в таблице должны зависть от всех полей первичного ключа, если есть поля, которые зависят от части полей первичного ключа, то они должны вынесены в отдельную таблицу, то есть провести декомпозицию таблицы на несколько таблиц. Это требование должно выполняться только если первичный ключ составной.
Наличие первичного ключа.
Пример
У каждого сотрудника есть свой уникальный табельный номер, поэтому его можно выбрать ключом
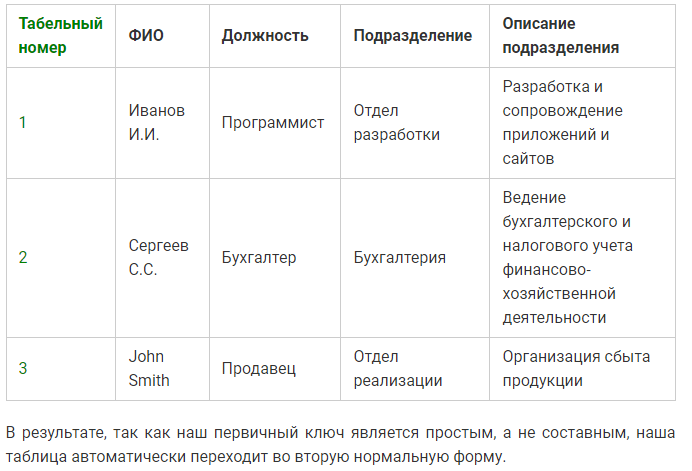
Пример если составной ключ
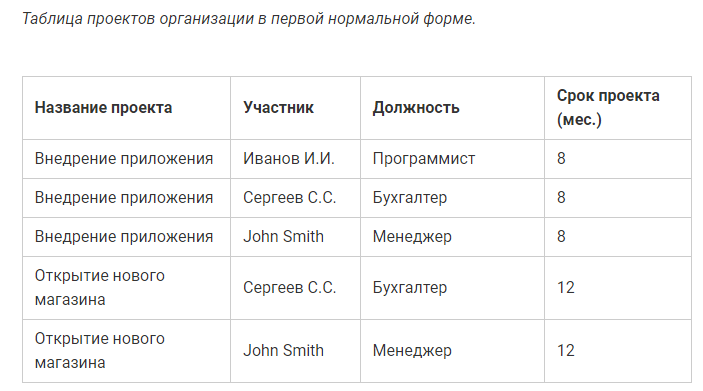
Ключ будет состоять из двух полей: названия проекта и участник
Кластеризация внутрифайловая и межфайловая
Говорят, о внутрифайловой кластеризации, когда она осуществляется в рамках одного хранимого файла. Например, если в системе часто требуется осуществлять доступ к данным согласно порядковому номеру, то все записи следует физически размещать таким образом, чтобы первая запись была возле второй записи, вторая запись - возле третьей и т. д.
При межфайловой кластеризации ею охватываются одновременно несколько файлов. Это используют, если в системе часто требуется осуществлять доступ к записям и данным, связанным друг с другом, при этом первые стараются разместить радом со вторыми.
Внутрифайловую и межфайловую кластеризацию СУБД может осуществлять, размещая логически связанные записи на одной странице, если это возможно, или на соседних страницах.
-
Какую функцию при работе СУБД выполняет диспетчер дисков?
Диспетчер дисков – программное обеспечение, контролирующее перемещение страниц между оперативной памятью и диском.
Извлечь, добавить, заменить, удалить страницу из набора страниц
Диспетчер дисков является компонентом используемой операционной системы, с помощью которого выполняются все дисковые операции ввода-вывода. Для выполнения этих операций необходимо знать значения физических адресов на диске
- 1 2 3 4 5
Что означает обеспечение целостности данных?
Ответ в 5 вопросе
-
Какое из действий занимает в среднем наибольшее время при операциях чтения/записи на диск?
При записи или обновление (INSERT, UPDATE) операции занимают разное время, если есть индекс, то время гораздо увеличится, то отсутствие индекса в таком случает ускоряет запись или обновление.
При чтении операции ускорятся если есть индекс по полю, по которому происходи выборка, если нет необходимого индекса, то придется прочесть всю таблицу.
-
Что является синонимом термина "атрибут" в реляционных системах?
Атрибут соответствует столбцу этой таблицы, а именно – свойствам объектов, сведения о которых хранятся в ней. В конкретных СУБД атрибуты часто называют полями.
-
Что такое Б-дерево?
Бинарное дерево — это иерархическая структура данных, в которой каждый узел имеет одно значение (оно же является в данном случае и ключом) и ссылки на двух потомков.
Узел, находящийся на самом верхнем уровне (не являющийся чьим-либо потомком), называется корнем.
Узлы, не имеющие потомков (оба потомка которых равны NULL) называются листьями.
Бинарное дерево поиска — это бинарное дерево, обладающее дополнительными свойствами: значение левого потомка меньше значения родителя, а значение правого потомка больше значения родителя для каждого узла дерева. То есть, данные в бинарном дереве поиска хранятся в отсортированном виде.
Бинарное дерево поиск используется в индексном файле, для быстрого поиска и сортировки данных. Скорость алгоритма = log2 (n), где n – количество записей в таблице
B-дерево — это особый тип бинарного дерева поиска, в котором каждый узел может содержать более одного ключа (узел хранит более одного значения) и иметь более двух дочерних элементов.
Скорость поиска данных происходит быстрее чем в бинарном. Логарифмическая функция.
-
Что является синонимом термина "кортеж" в реляционных системах?
В реляционных базах данных кортеж — это элемент отношения (запись (строка) в таблице).
Для N-арного отношения кортеж представляет собой упорядоченный набор из N значений, по одному значению для каждого атрибута отношения.
-
Что является синонимом термина "отношение" в реляционных системах?
Отношением называется вся таблица (файл)
-
Что справедливо для многоуровневого индекса?
Многоуровневый индекс — это индекс, состоящий из нескольких индексных файлов, при этом только индекс первого уровня ссылается на реальные данные (обычно это плотный индекс), а индексы более высоких уровней ссылаются на предыдущие уровни (эти индексы обязательно неплотные).
В плотных для каждого значения ключа имеется отдельная запись индекса, указывающая место размещения конкретной записи.
Неплотные (разреженные) индексы строятся в предположении, что на каждой странице памяти хранятся записи, отсортированные по значениям индексируемого атрибута. Тогда для каждой страницы в индексе задаётся диапазон значений ключей хранимых в ней записей, и поиск записи осуществляется среди записей на указанной странице.
Структура многоуровневого индекса за счет увеличения объема данных позволяет сократить время поиска записей, т.к. данные уже разбиты на фрагменты, которые бы получались, например, в результате бинарного поиска.
Многоуровневый индекс вводится при наличии в файле данных большого числа записей, обычно при условии, что бинарный поиск в одноуровневом плотном индексе проводится за значительное число шагов. Поиск данных в многоуровневом индексе начинается с самого верхнего уровня и продолжается пока не будет достигнута запись данных, поиск ссылки на следующий уровень на текущем уровне проводится методом двоичного поиска в определенном диапазоне.
-
Что является аналогом "инвертированного списка"?
Аналогом является многоуровневый индекс.
Инвертированный список в общем случае — это двухуровневая индексная структура.
Здесь на первом уровне находится файл или часть файла, в которой упорядоченно расположены значения вторичных ключей. Каждая запись с вторичным ключом имеет ссылку на номер первого блока в цепочке блоков, содержащих номера записей с данным значением вторичного ключа.
-
Что справедливо при индексировании файла базы данных?
Основным преимуществом использования индексирования является значительное ускорение процесса выборки, сортировки.
Основным недостатком замедления процесса обновления данных так как при каждом добавлении новой записи в индексированный файл потребуется также добавить новые индекс в индексный файл.
Индекс – это объект базы данных, обеспечивающий быстрый доступ к строкам таблицы на основе значений одного или нескольких столбцов, а также служит для сортировки данных.
Индексный файл — это файл в котором хранится информация об индексе.
-
Нормализация данных в БД
Нормализация – это метод проектирования базы данных, который позволяет привести базу данных к минимальной избыточности.
Избыточность данных создает предпосылки для появления различных аномалий, снижает производительность, и делает управление данными не гибким и не очень удобным.
Избыточность данных – это когда одни и те же данные хранятся в базе в нескольких местах, именно это и приводит к аномалиям.
Поэтому нормализация нужна для
Устранения аномалий
Аномалия обновления – обновлять придется все возможные данные, где присутствуют данные, которые мы хотели обновить, снижается производительности БД, иначе если не обновить все записи то будут артефакты чтения и записи (противоречивость данных)
Аномалия удаления – помимо удаления необходимой информации, удаляется и избыточная (происходит потеря данных).
Повышения производительности
Повышения удобства управления данными
Избыточность устраняется, как правило, за счёт декомпозиции отношений (таблиц), т.е. разбиения одной таблицы на несколько.
Процесс нормализации – это последовательный процесс приведения базы данных к эталонному виду, т.е. переход от одной нормальной формы к следующей.
Нормальная форма базы данных – это набор правил и критериев, которым должна отвечать база данных.
Первая нормальная форма (1NF), Вторая нормальная форма (2NF), Третья нормальная форма (3NF), Нормальная форма Бойса-Кодда (BCNF), Четвертая нормальная форма (4NF), Пятая нормальная форма (5NF)
Данные в таблицах удовлетворяют следующим принципам:
– Каждое значение, содержащееся на пересечении строки и колонки, должно быть атомарным (т. е. не расчленяемым на несколько значений).
– Значения данных в одной и той же колонке должны принадлежать к одному типу, доступному для исполнения в данной СУБД.
– Каждая запись в таблице уникальна, т. е. в таблице не существует двух записей с полностью совпадающим набором значений ее полей.
– Каждое поле имеет уникальное имя.
– Последовательность полей в таблице несущественна
2 вопрос
-
1НФ
Первая нормальная форма: таблица базы данных – это представление сущности вашей системы, которую вы создаете. Каждая запись в базе данных представляет один экземпляр сущности.
Например, в таблице клиентов каждая запись представляет одного клиента.
Требования:
Таблица не должна иметь дублирующих строк (кортежей).
Первая форма не предусматривает обязательное наличие первичного ключа.
Каждое поле содержит только одно значение, то есть атомарные данные (не делимая информация).
Данные типизированы
Таблица не имеет поля, которые хранят в себе информацию одинаковую по смыслу
-
2НФ
Вторая нормальная форма связана с избыточностью данных.
Требования:
Поля в таблице должны зависть от всех полей первичного ключа, если есть поля, которые зависят от части полей первичного ключа, то они должны вынесены в отдельную таблицу, то есть провести декомпозицию таблицы на несколько таблиц. Это требование должно выполняться только если первичный ключ составной.
Наличие первичного ключа.
Пример
У каждого сотрудника есть свой уникальный табельный номер, поэтому его можно выбрать ключом
Пример если составной ключ
Ключ будет состоять из двух полей: названия проекта и участник