Файл: Информация и формы ее представления Информационные процессы и технологии.docx
ВУЗ: Не указан
Категория: Не указан
Дисциплина: Не указана
Добавлен: 07.11.2023
Просмотров: 296
Скачиваний: 1
СОДЕРЖАНИЕ
1.3. ЭВМ как средство обработки информации
1.1 Информация и формы ее представления
1.2 Информационные процессы и технологии
1.3 ЭВМ как средство обработки информации
Структура и принципы функционирования ЭВМ
Основные характеристики вычислительной техники
Перспективы развития вычислительных средств
2.4 Операционная система MS-DOS
Файловая структура логического диска
Раздел 3 Основные принципы программирования
3.1. Этапы подготовки и решения задач на ЭВМ
3.2. Алгоритмы и способы их описания
3.3. Компиляция и интерпретация программ
3.1 Этапы подготовки и решения задач на ЭВМ
3.2 Алгоритмы и способы их описания
3.3. Компиляция и интерпретация программ
Раздел 9 Объектно-ориентированное программирование
Потоковый вывод
Для начинающих программистов организация потокового вывода числовой информации на стандартное устройство вывода экран (stdout) представляется более простой:
#include
int main()
{ int i;
float f;
double d;
..........
cout << i+1 << f << f*d;
Здесь на первых порах не надо заботиться о форматах выводимых результатов. Для каждого типа данных существуют соответствующие системные соглашения. Переход в начало следующей строки здесь осуществляется путем включения в список вывода признака конца строки endl, например:
cout << i+1 << endl << f << f*d;
В таком случае значения переменных f и f*d будут выведены на новую строку.
Форматный вывод
Форматный вывод числовых результатов на стандартное устройство вывода (stdout), которым по умолчанию является экран дисплея, осуществляется с помощью функции printf. Например:
#include
int main()
{ int i;
float f;
double d;
..........
printf("%d %f %lf", i+1, f, f*d);
Ее аргументы напоминают по форме обращение к функции scanf с той лишь разницей, что список вывода составляют не адреса переменных, а арифметические выражения, значения которых предварительно будут подсчитаны, а потом выведены в соответствии с использованными форматными указателями. Выражения и имена переменных в списке перечисляются через запятую. В качестве простейших выражений могут быть константы, переменные, символы, строки.
Работа операторов вывода
Операторы вывода преобразуют значения переменных и вычисленные значения выражений, указанных в списке, из внутреннего представления во внешнее и выводят эти значения на экран.
Для вывода чисел и значений переменных на экран используют функцию printf.
Общий вид записи оператора
printf(“ список форматов”, cnиcoк имен переменных и выражений);
Например:
printf ( "Результат: %d + %d = %d \n", a, b, c );
Содержание скобок при вызове функции printf очень похоже на функцию scanf. Сначала идет символьная строка — форматы вывода, — в которой можно использовать специальные символы
%d - вывод целого числа
%f - вывод вещественного числа
%с - вывод одного символа
%s - вывод символьной строки
\n - переход в начало новой строки
все остальные символы (кроме некоторых других специальных команд) просто выводятся на экран.
В символьной строке мы сказали компьютеру, какие данные (целые, вещественные или символьные) надо вывести на экран, но не сказали откуда (из каких ячеек памяти) их брать. Поэтому через запятую после форматов вывода надо поставить список чисел или имен переменных, значения которых надо вывести, при этом можно сразу проводить вычисления.
printf ( "Результат: %d + %d = %d \n", a, 5, a+5 );
Так же, как и для функции scanf, надо следить за совпадением типов и количества переменных и форматов вывода.
Пример вывода:
Операторы
printf(“Выходные данные:\n”);
printf(“'K=%d y=%f”, 8+5, 7./10);
выводят на экран результаты в следующем виде:
Выходные данные:
К=13 у=0.7
Управление выводом данных
При стандартной форме вывода вещественные числа отображаются на экране с порядком. Мантисса выводится в нормализованном виде, т.е. с одной значащей цифрой в целой части и десятью цифрами в дробной части. На порядок отводится четыре позиции: первая позиция - под букву Е, вторая позиция - под знак порядка, третья и четвертая позиции - под цифры порядка.
Если программиста не устраивает стандартная форма вывода, то он может использовать форматированный вывод, предусмотренный в системе Турбо Си. При форматированном выводе чисел используются два формата.
-
Ширина поля, определяющая число позиций на экране, отводимых для вывода всего числа, включая целую, дробную части, знак и десятичную точку. -
Точность представления вещественного числа, определяющая число позиций в дробной части.
Вещественное число с указанием форматов всегда выводится в десятичной форме. Для целого числа используется только формат ширины поля.
В операторах вывода форматы записываются после знака % и отделяются друг от друга точкой. Например, при записи оператора
printf(“K=%3d у=%5.2f”,8+3,7./10);
результаты отображаются на экране в следующем виде:
К= 11 у = 0.70
В приведенном примере форматы 3 и 5 задают ширину поля, формат 2 - точность выводимого числа, т.е. значение выражения 7./10 выведено на экран с двумя значащими цифрами после запятой.
4.6 Структура основной программы
Простейшая программа на Си
Такая программа состоит всего из 12 символов, но заслуживает внимательного рассмотрения. Вот она:
void main()
{
}
Основная программа в Си всегда называется именем main (будьте внимательны - Си различает большие и маленькие буквы, а все стандартные операторы Си записываются маленькими буквами). Пустые скобки означают, что main не имеет аргументов, а слово void (пустой) говорит о том, что она также и не возвращает никакого значения, то есть, является процедурой.
Фигурные скобки обозначают начало и конец процедуры main - поскольку внутри них ничего нет, наша программа ничего не делает, она просто соответствует правилам языка Си, ее можно скомпилировать и получить exe-файл.
Составим теперь программу, которая делает что-нибудь полезное, например, выводит на экран слово «Привет».
 #include
#include 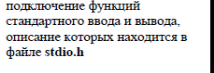
void main()
{
 printf("Привет");
printf("Привет"); }
Что новенького?
Перечислим новые элементы, использованные в этой программе:
Чтобы использовать стандартные функции, необходимо сказать транслятору, что есть функция с таким именем и перечислить тип ее аргументов - тогда он сможет определить, верно ли мы ее используем. Это значит, что надо подключить описание этой функции.
Описания стандартных функций Си находятся в так называемых заголовочных файлах с расширением *.h (в каталоге C:\BORLANDC\INCLUDE)
Для подключения заголовочных файлов используется директива (команда) препроцессора "#include", после которой в угловых скобках ставится имя файла заголовка. (Препроцессор - это специальная программа, которая обрабатывает текст вашей программы раньше транслятора. Все команды препроцессора начиняются знаком "#"). Внутри угловых скобок не должно быть пробелов. Для подключения еще каждого нового заголовочного файла надо использовать новую команду "#include".
Для вывода информации на экран используется функция printf. В простейшем случае она принимает единственный аргумент - строку в кавычках, которую надо вывести на экран.
Каждый оператор языка Си заканчивается точкой с запятой.
В программу могут быть включены комментарии - тексты,
поясняющие программу. Комментарии – обязательная принадлежность каждой программы. Описание нетривиального алгоритма, как правило, снабжается пояснениями, которые помогут разобраться в тексте программы персоналу сопровождения программных продуктов. Наконец, отключение части программы путем перевода ее в разряд комментариев – наиболее употребительный прием отладки программ. В языке Си предусматривается две разновидности комментариев – многострочные и однострочные.
Однострочный комментарий начинается вслед за парой символов "//" и продолжается до конца программной строки. Обычно с его помощью записывается комментарий к текущей строке или исключается фрагмент текущей строки из области обслуживания. Комментарии, заключенные в /* */ и записываются в любом месте программы и могут располагаться на нескольких строках.
Пример линейной программы
Составить программу вычисления площади треугольника по
формуле:
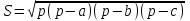
где
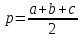 - полупериметр; а,b,с -стороны треугольника.
- полупериметр; а,b,с -стороны треугольника.Исходные данные: а = 1; b= 2; с = 0,5.
#include
#include
#include
main()
{ clrscr();
float a, b, c, p, S;
printf(“Введите исходные данные ”);
scanf(“%f%f%f”,&a, &b,&с);
p = (a + b + c) / 2;
S = sqrt(p * (p - a) * (p -b) * (p - c));
/*Вывод на экран*/
printf(“Площадь треугольника S =%5.2f”, S);
}
При выполнении оператора scanf программа останавливается и переходит в режим ожидания набора исходных данных с клавиатуры. В этот момент надо набрать на клавиатуре:
1 2 0.5 [Enter]
После нажатия клавиши [Enter] программа продолжает выполнение и выведет результат на экран в следующем виде:
Площадь треугольника S = 3.87
4.7 Разветвляющиеся вычислительные процессы
Вычислительный процесс называется разветвляющимся, если он реализуется по одному из нескольких направлений - ветвей. В программе должны быть учтены все возможные ветви вычислений. Выбор той или иной ветви осуществляется по условию, включенному в состав условного оператора. Для программной реализации условия используется логическое выражение. В сложных структурах с большим числом ветвей применяют оператор выбора.
4.7.1. Логические выражения
Логические выражения строятся из операндов, отношений, логических операций и круглых скобок.
Результатом вычисления логического выражения является одно из двух логических значений: TRUE(истина)(1) или FALSE(ложь)(0).
В качестве операндов используются константы, переменные и функции логического типа.
Отношения
Отношение - это простейший вид логического выражения, состоящего из двух выражений арифметического, символьного или строкового типов, соединенных знаком операции отношения.
Операция отношения - это операция сравнения двух операндов:
< - меньше
<= - меньше либо равно
>- больше
>= - больше либо равно
= = - равно
!= не равно.
Примеры записи отношений на языке Си
| Отношение | Результат |
| 5>3 | TRUE |
| cos(x)>1 | FALSE |
| х*х+у*у<1 | TRUE для всех точек, лежащих внутри круга с единичным радиусом и центром в начале координат |
| A!=’Y’ | TRUE, если значение символьной переменной А не равно символу ’Y’ |
Следует помнить, что к операндам вещественного типа не применима операция = = из-за неточного представления чисел в памяти компьютера. Поэтому для вещественных переменных а и bотношение вида а= =b надо заменить отношением abs(a-b)
Логические операции
| Математическая запись | Запись на языке Си аскаль | Название операции |
| ¬ | ! | Отрицание |
 | && | Операция «И» (логическое умножение) |
| | || | Операция «ИЛИ» (логическое сложение) |
Действия логических операций удобно задать таблицами истинности, в которых приняты следующие обозначения: a, b - логические операнды; Т - TRUE, F - FALSE.
| а | ! a |
| Т F | F Т |
| а | b | a && b |
| Т | Т | Т |
| Т | F | F |
| F | Т | F |
| F | F | F |
| а | b | a || b |
| Т | Т | Т |
| Т | F | Т |
| F | Т | Т |
| F | F | F |
Порядок выполнения операций в логических выражениях
В бесскобочных логических выражениях операции выполняют слева направо в соответствии с их приоритетом:
-
! -
&& -
|| -
Отношения.
Поскольку отношения имеют самый низкий приоритет, то их необходимо заключать в круглые скобки.
Пример. Вычислить логическое выражение:
(-3≥5)
¬(7<9) (0≤3)Запись на языке Си имеет вид:
(-3>= 5) || ! (7 <9) && (0 <= 3)
1 6 4 2 5 3
Внизу под операциями проставлен порядок выполнения действий.
1) -3>= 5=>F;2) 7 <9 => Т; 3) 0 <= 3 => Т;
4) !(T) -> F; 5) F && T=>F; 6) F || F => F.
Ответ: FALSE.
Примеры записи логических выражений
Записать на языке Си логические выражения, реализующие следующие условия:
a) переменная х принадлежит интервалу [а, b].
Ответ: (х>= a) && (x <= b)
б) переменная х не принадлежит интервалу [а, b].
Ответ: Данное условие можно записать в одном из двух вариантов:
1) (х <а) || (x> b);
2)воспользоваться операцией отрицания:
! ((x>= a) && (х <= b))
4.7.2. Условные операторы
На языке Си различают два вида условных операторов: короткий и полный.
Короткий условный оператор
Общий вид записи
if (логическое выражение) P;
где Р - любой оператор.
Работа оператора
Сначала вычисляется логическое выражение (ЛВ), и если оно имеет значение TRUE, то выполняется оператор Р, стоящий за логическим выражением. В противном случае оператор Р игнорируется.
Графическая интерпретация оператора
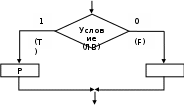
В схемах алгоритма короткому условному оператору соответствует структура ЕСЛИ—ТО.
Замечание. По определению, конструкция короткого условного оператора включает единственный оператор Р. Если в задаче по заданному условию требуется выполнить несколько операторов, то их необходимо заключить в скобки { }, образуя тем самым единый составной оператор. Тогда запись условного оператора с использованием скобок имеет следующий вид:
if (логическое выражение)
{
 Составной оператор
Составной оператор}
П
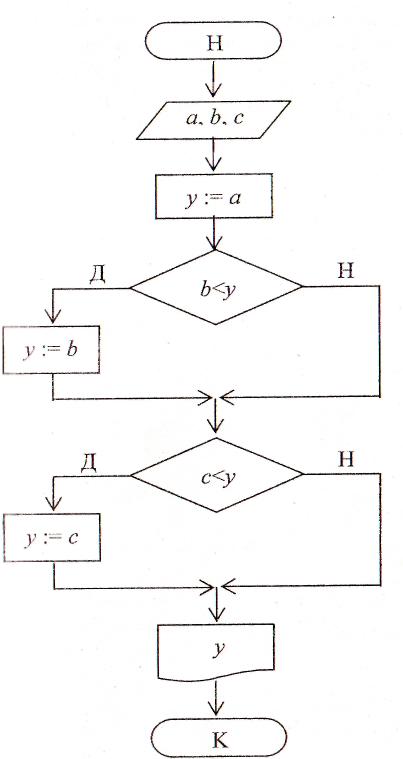 ример. Переменной у присвоить минимальное значение из трех различных чисел, т.е. у = min(a, b, с).
ример. Переменной у присвоить минимальное значение из трех различных чисел, т.е. у = min(a, b, с).Программа
#include
#include
#include
main()
{ clrscr();
float a, b, c,y;
printf(“ Вве д ите числа а, b, с”);
scanf(“%f%f%f”, &a,& b,& с);
у=а;
if (b
if (c
printf(“y =%6.2f”, y);
}
Полный условный оператор
Общий вид записи
if (логическое выражение) P1; else P2;
где Р1, Р2 - любые операторы или даже группы операторов.
Работа оператора
Вычисляется логическое выражение, и если оно имеет значение TRUE(1), то выполняется оператор Р1, стоящий после логического выражения. В противном случае (FALSE (0))оператор P1 пропускается, а выполняется оператор Р2, стоящий после служебного слова else.
Графическая интерпретацияоператора
В схемах алгоритма полному условному оператору соответствует структура ЕСЛИ-ТО-ИНАЧЕ.
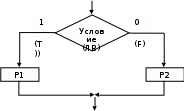
Замечание. Операторы Р1 и Р2 входят в конструкцию полного условного оператора как единственные. Если возникает необходимость выполнить в ветвях несколько операторов, то их заключают в операторные скобки { }. Вид записи условного оператора в этом случае следующий.
if (логическое выражение)
{
оператор 1;
………………
оператор n;
}
else
{
оператор 1;
………………
оператор m;
}
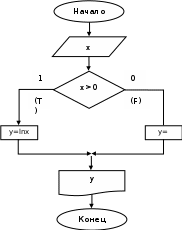
Пример 1. Вычислить значение переменной у по одной из двух ветвей:
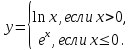
Схема алгоритма Программа
 #include
#include #include
#include
main()
{
float a, b, c,y;
printf(“ В ве д ите число x”);
scanf(“%f”,&x);
if( x>0) у = log(х)
else у = ехр(х);
printf('y =%6.2f”, у);
}
Пример 2. Вычислить корни полного квадратного уравнения
ах2 + bх + с = 0.
В программе предусмотреть проверку дискриминанта на знак. Если дискриминант окажется отрицательным, то вывести сообщение «Корни мнимые».
#include
#include
#include
main()
{
float a, b, с, d, xl, x2; // описание переменных
printf(“Введите коэффициенты уравнения ”);
scanf(“%f%f%f”,&a, &b, &с); // ввод исходных данных
d = pow(b,2)-4*a*c; //вычисление дискриминанта
if ( d<0 ) // сравнение дискриминанта с нулем
printf (“Корни мнимые”); /*вывод «корни мнимые», если d окажется < 0 */
else // иначе
{
x1=(-b+sqrt(d))/(2*a); // вычисление первого корня
x2=(-b-sqrt(d))/(2*a); // вычисление второго корня
printf(“x1=%f x2=%f”,x1,x2); // вывод корней на экран
}
}
Вложенные структуры условных операторов
Структура называется вложенной, если после служебного слова else или при истинности логического выражения вновь используются условные операторы. Число вложений может быть произвольным. При этом справедливо следующее правило: служебное слово else всегда относится к ближайшему выше слову if. Для удобства чтения вложенных структур при программировании рекомендуется избегать по возможности записи вложенного условного оператора.
Пример. Вычислить значение у по одной из трех ветвей:
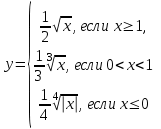
При решении данной задачи возможны два варианта программирования: 1) без вложенной структуры; 2) с вложенной структурой. Ниже рассмотрены оба варианта решения задачи.
Вариант 1 (с использованием вложенной структуры)
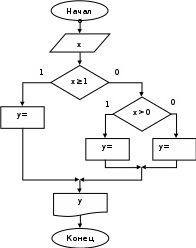
Схема алгоритма Программа
#include
#include
#include
main()
{ clrscr();
float х, у;
printf(“Введите число х”); scanf(“%f”,&x);
if (х>=1)
у = sqrt(x)/2;
else
if(x>0)
y=pow(x,1./3)/2;
else
y=pow(x,l./4)/4;
printf(“y=%6.2f”,y);
}
Вариант 2 (без использования вложенной структуры)
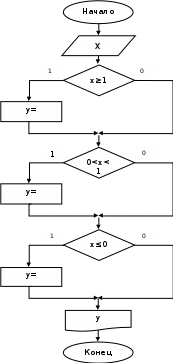
Схема алгоритма Программа
#include
#include
#include
main()
{
float х, у;
printf(“Введите число х”);
scanf(“%f”,&x);
if (х>=1) у = sqrt(x)/2;
if(x>0) y =pow(x,l/3)/2;
if(x<=0) y=pow(x,l./4)/4;
printf(“y=%6.2f”,y);
}
4.7.3. Оператор выбора
При многократном вложении условных операторов программа становится громоздкой и ее трудно понять. Считается, что число вложений не должно превышать двух-трех. При большем числе вложений рекомендуется использовать оператор выбора switch-case.
Общий вид записи оператора
switch <селектор>
{
сase константа выбора 1: оператор 1; break;
…………………………………………………
сase константа выбора n: оператор n; break;
default:
}
Селектор - это выражение целого или символьного типа.
Константы выбора - всевозможные значения селектора.
default – предусматривает обработку непредусмотренного значения селектора.
Работа оператора
По вычисленному значению селектора выбирается для исполнения case-оператор той строки, у которого содержится константа выбора, равная значению селектора. После выполнения выбранного case-оператора управление передается на конец оператора case. Следующим в программе выполняется оператор, стоящий за оператором выбора switch.
Пример 1. Написать оператор выбора для вычисления величины y по формулам:
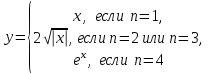
Оператор выбора имеет следующую запись:
switch (n)
{
case 1: у =х; break;
case 2: case 3: у = 2 * sqrt(abs(x)); break;
case 4: у = ехр(х); break;
default: printf(“значение для n указано не верно\n”);
}
Графическая интерпретация оператора
В схемах алгоритма оператору switch соответствует структура ВЫБОР.
Для приведенного выше примера 1 эта структура выглядит следующим образом:
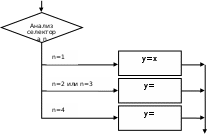
Замечание. Если в строке выбора необходимо записать несколько операторов, то их заключают в операторные скобки {...}.
Пример 2. Вычислить значение у.
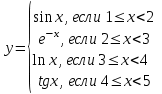
Если значение х не принадлежит рассматриваемым промежуткам, то вывести на экран соответствующее сообщение.
В задаче переменная х является вещественной и не может использоваться в качестве селектора оператора case. Введем новую переменную целого типа n, которой присваивается целая часть значения х. Тогда программа решения данной задачи с использованием оператора выбора может быть составлена следующим образом.
#include
#include
#include
main()
{ clrscr(); /* очистка экрана */
float х, у;
int n;
printf(“Введите число х ”);
scanf(“%f”,&x);
if (х<1) || (x>=5)
printf(“x не принадлежит рассматриваемой области\n”);
else
{ n = x;
switch (n)
{
case l: y =sin(x); break;
case 2: у = exp(-x); break;
case 3: y =log(x); break;
case 4: у = tan(x); break;
default: printf(“ такого решения не предусмотрено\n”); break;
}
if (n= =1)||(n= =2)||(n= =3)||(n= =4) printf(“y=%6.2f”, y);
}
}
4.8 Циклические вычислительные процессы
Циклические вычислительные процессы характеризуются наличием многократно повторяющихся участков вычислений (циклов). Переменная, изменяющаяся в цикле, называется управляющей переменной. Для программирования циклических задач используются операторы цикла с условием или с параметром.
4.8.1. Операторы цикла с условием
В языке Си имеется два вида операторов цикла с условием:
-
оператор цикла while (пока); -
оператор цикла do... while (повторять до тех пор, пока).
Оператор цикла while является наиболее универсальным, так как с его помощью можно запрограммировать практически любой циклический процесс.
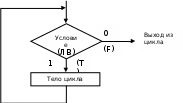
Оператор цикла while
Общий вид записи
while (логическое выражение) { <тело цикла>; }
<тело цикла> - единичный оператор или группа операторов, выполняемых в цикле.
Замечание.Если тело цикла состоит из нескольких операторов, то их обязательно заключают в операторные скобки {...}.
Работа оператора
Тело цикла выполняется, пока логическое выражение, определяющее условие выхода из цикла, имеет значение TRUE. В противном случае оператор цикла while завершает свою работу.
В состав логического выражения входит управляющая переменная, которая должна изменяться в теле цикла. Перед началом работы оператора определяется начальная установка управляющей переменной.
Графическая интерпретация оператора
В схемах алгоритма оператору цикла while соответствует структура ЦИКЛ-ПОКА.
Оператор цикла do...while
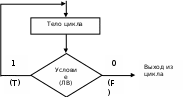
Общий вид записи
do
{
<тело цикла>;
} while (логическое выражение);
Работа оператора
Выполняется тело цикла, после чего вычисляется логическое выражение, определяющее условие выхода из цикла. Если логическое выражение примет значение FALSE, то цикл do...while завершает свою работу.
Управляющая переменная, как и в случае оператора цикла while должна включаться в состав логического выражения и изменяться в теле цикла. Перед началом работы оператора также производится начальная установка управляющей переменной.
Графическая интерпретация оператора
В схемах алгоритма оператору цикла do... while соответствует структура ЦИКЛ-ДО.
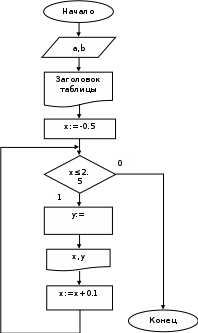
Пример 1.Алгоритм расчета значений функции с одной переменной.
Вычислить таблицу значений функции:
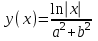
для всех х, изменяющихся в интервале [-0.5,2.5] с шагом Δх = 0.1,
а, b - заданные вещественные числа.
В данной задаче переменная х является управляющей переменной цикла.
Схема алгоритма Программа
#include
#include
#include
main()
{
clrscr(); /* очистка экрана */
float а, b, х, у;
printf”'Bвeдитe исходные данные”);
scanf(“%f%f”,&a,&b);
printf(“ x y(x)\n”);
х=-0.5;
while(х <= 2.5)
{
y= log(abs(x))/(a*a +b*b);
printf(“%8.1f %8.1f”,x,y);
x=x + 0.1;
}
}
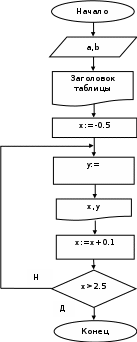
Пример 2.Решить предыдущую задачу табулирования функции с использованием оператора цикла do…while.
Схема алгоритма Программа
#include
#include
#include
void main()
{
clrscr(); /*очистка экрана */
float а, b, х, y;
printf(“Bвeдитe исходные данные “);
scanf(“%f%f”,&a,&b);
printf(“ x y(x)\n”);
х=-0.5;
do
{
y=log(abs(x))/(a*a-b*b);
printf(“%8.1f %8.1f\n”,x,y);
x= x+ 0.1;
} while( x<= 2.5);
}
Основные отличия оператора цикла whileот оператора цикла do...while
1. В операторе while тело цикла может не выполниться ни разу, если логическое выражение в начальный момент окажется ложным.
В операторе do...while логическое выражение записывается после тела цикла, поэтому тело цикла обязательно выполнится хотя бы один раз.
4.8.2. Операторы цикла с параметром
Общий вид записи
for( i = ml; i<= m2; i=i+шаг)
{ <тело цикла>;}
i - параметр, управляющий работой цикла;
ml, m2 - выражения, определяющие соответственно начальное и конечное значения параметра цикла.
Замечание.Тело цикла состоит по стандарту из одного оператора. В случае выполнения в цикле нескольких операторов надо воспользоваться обязательно операторными скобками {...}.
Работа оператора цикла for...
Тело цикла выполняется для каждого значения параметра i, начиная от ml до конечного значения m2. После каждого шага выполнения цикла значение параметра i автоматически увеличивается на шаг(шаг – это любое число).
Графическая интерпретация оператора цикла for...
В схемах алгоритма оператору цикла for..., как и в случае цикла while, соответствует структура ЦИКЛ-ПОКА.
Однако, из-за особенностей работы оператора и его широкого применения при программировании задач обработки массивов данных, для оператора for... имеется специальная структура следующего вида:
Замечание 1. Оператор цикла for...допускает применение любого шага для изменения своего параметра.
Правила использования операторов цикла с параметром
-
Параметр цикла i, а также его значения ml и m2 могут быть любого типа. -
Параметр i, а также значения ml и m2 не должны переопределяться (менять значения) в теле цикла. При завершении работы оператора параметр i становится неопределенным и переменную i можно использовать в других целях. -
Тело цикла может не выполниться ни разу, если m1>m2 для цикла for... с положительным шагом, или m1
Замечание 2.Оператор цикла while, как указывалось выше, наиболее универсальный из трех операторов цикла, используемых в языке Си. Однако конструкция оператора цикла for является наиболее простой. Поэтому рекомендуется там, где возможно, использовать оператор for.
4.9 Базовые алгоритмы
Для реализации циклических вычислительных процессов в большинстве случаев используются следующие базовые алгоритмы:
-
табулирование функций; -
организация счетчика; -
накопление суммы или произведения; -
поиск минимального или максимального члена последовательности.
Ниже приводятся примеры программирования задач на основе базовых алгоритмов.
Задача 1.Алгоритм организации счетчика
Дана последовательность:
cos 1, cos 3, cos 5, ..., cos 99.
Определить количество положительных членов последовательности.
Решение
Представим последовательность в общем виде:
а = cos(2n -1), где п =
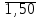 .
.Для организации счетчика в памяти компьютера выделяется ячейка, содержимое которой должно увеличиваться на 1 каждый раз, когда встречается положительный член последовательности. В программе ячейке (счетчику) соответствует переменная целого типа, например переменная L. Работа счетчика реализуется с помощью оператора присваивания L=L+1;. В начальный момент содержимое ячейки должно быть равно нулю. С этой целью предварительно осуществляется очистка ячейки оператором присваивания L=0;.
#include
#include
#include
void main()
{
clrscr(); // очистка экрана
float a;
integer n,L; // описание переменных
L=0; // очистка счетчика
for ( n = 1; n<= 50; n++) // запуск цикла
{
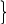
a = cos(2*n - 1);
if(a>0) L = L + 1 // тело цикла
}
printf(“L=%d”, L); // вывод значения счетчика
}
Задача 2.Алгоритм накопления суммы
Дана последовательность:
sin 2x, sin 4x, sin 6x, ..., sin l6x
x - заданное вещественное число.
Вычислить сумму членов последовательности, которые по модулю больше 0.3.
Решение
Общий член последовательности имеет вид:
а = sin(2nx), где n =
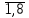 .
. Для вычисления суммы в памяти компьютера выделяется ячейка S, к содержимому которой прибавляется член последовательности а каждый раз, когда выполняется условие
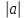 > 0.3. Накопление суммы реализуется оператором присваивания S=S+a;. В начальный момент ячейка для суммирования должна быть очищена оператором S=0;.
> 0.3. Накопление суммы реализуется оператором присваивания S=S+a;. В начальный момент ячейка для суммирования должна быть очищена оператором S=0;.#include
#include
#include
void main()
{
clrscr();
float a, x, S;
integer n;
printf(“Введите значение х= ”);
scanf(“%f”,&x);
S=0;
for( n = 1; n<= 8; n++)
{ a = sin(2*n*x);
if ( abs(a)>0.3) S = S + a;
}
printf(“S=%6.2f”, S);
}
Задача 3.Алгоритм накопления произведения
Дана последовательность:
cos 0.1, cos 0.2, cos 0.3, ..., cos 10.
Вычислить значение: Р
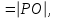 где РО - произведение отрицательных членов последовательности.
где РО - произведение отрицательных членов последовательности.Решение
Общий член последовательности имеет вид:
y = cos x, где 0.1
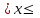 10; Δх = 0.1.
10; Δх = 0.1. Для реализации алгоритма накопления произведения выделяется ячейка памяти РО, в которой осуществляется последовательное перемножение отрицательных членов последовательности с помощью оператора присваивания РО=РО*у; . В начальный момент в ячейку должна быть занесена единица оператором РО=1;.
#include
#include
#include
void main(0
{
clrscr();
float х, у, Р, РО;
РО = 1;
for (x=0.1; x<=10; x=x+0.1)
{
у = cos(x);
if ( y<0) РО = РО*у;
}
Р = abs(PO);
printf(“P=%6.2f”,P);
}
Задача 4.Алгоритм поиска минимального члена последовательности
Дана последовательность:
ak=ektg(2k + l); к=
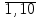 .
. Найти минимальный член последовательности.
Решение
Для реализации алгоритма выделяется ячейка памяти min, в которую сначала заносится первый член последовательности. Затем, начиная со второго, производится сравнение очередного вычисленного члена последовательности с содержимым ячейки min. Если текущий член последовательности меньше содержимого ячейки min, то oн переписывается в эту ячейку. В противном случае содержимое ячейки min сохраняет прежнее значение. При завершении сравнения всех членов последовательности в ячейке min остается минимальное значение.
Замечание 1. Алгоритм поиска максимального члена последовательности
отличается от поиска минимального члена лишь тем, что в ячейке (ей можно дать, например, имя max) запоминается больший из сравниваемых членов последовательности.
Замечание 2. В начальный момент в ячейку min можно занести не первый член последовательности, а достаточно большое число, которое превышало бы область определения сравниваемых чисел (например, min=+1E6;). Тогда при сравнении с содержимым ячейки min первый член последовательности обязательно окажется меньше и перепишется в ячейку min. При поиске максимального члена последовательности в ячейку max в начальный момент заносится, наоборот, достаточно малое число, которое должно быть меньше всех сравниваемых членов последовательности (например, mах= -1Е6;). В этом случае первый из сравниваемых членов последовательности окажется больше содержимого ячейки max и переписывается в эту ячейку.
#include
#include
#include
void main()
{
clrscr();
float a, min;
int k;
min = +1E6;
for( k=l; k<=10; k++)
{
a = exp(k)*tan(2*k + 1);
if (a
}
printf(“min=%6.2f”, min);
}
Задача 5. Табулирование функции (или кратные циклы)
Тело цикла может содержать любой оператор, в том числе и другой оператор цикла. Структура цикла, содержащая вложенный цикл, называется кратным циклом. Число вложений может быть произвольным. Если цикл содержит один вложенный цикл, то он называется двойным циклом, если содержит два вложенных цикла, то является тройным циклом, и т.д. Цикл, который содержит вложенный цикл, называется внешним. Вложенный цикл называется внутренним.
Переменная внутреннего цикла всегда меняется быстрее, чем внешнего. Это означает, что для каждого значения внешней переменной цикла меняются все значения внутренней переменной.
Внешний и внутренний циклы могут использовать любой вид операторов цикла (while, do-while, for).
Пример.Алгоритм табулирования функции с двумя переменными
Вычислить значение функции:
z(x, у) = sin x + cos y
при всех х, изменяющихся на интервале [-1, 1] с шагом Δх = 0.2,
и у, изменяющихся на интервале [0, 1] с шагом Δу = 0.1.
Данный алгоритм реализуется с использованием двойного цикла, в котором х примем за внешнюю переменную цикла, у - за внутреннюю переменную цикла.
#include
#include
#include
void main()
{
clrscr(); // очистка экрана
float х, у, z; // описание переменных
printf(“x y z(x,y)\n”); // вывод заголовка
x=-l; // начальное значение параметра цикла
while (х<=1) // запуск внешнего цикла, если х≤ 1
{
for( y=0; y<=1; y=y+0.1) //запуск внутреннего цикла
{
z=sin(x) + cos(y); // вычисление функции
printf(“%6.1f %6.1f z=%6.1f”,x, y, z); // вывод
}
x=x + 0.2; // изменение параметра х на шаг
}
}
В результате выполнения программы вид таблицы на экране будет следующим:
| x | y | z(x,y) |
| -1.0 | 0.0 | z=-1.0 |
| -1.0 | 0.1 | z=-1.1 |
| … | … | … |
| -1.0 | 1.0 | z=-0.0 |
| -0.8 | 0.0 | z=-0.8 |
| -0.8 | 1.0 | z=-0.8 |
Задача 6. Вычисление сумм последовательностей
Последовательности с заданным числом элементов
Пример 1. Найти сумму первых 20 элементов последовательности
S=1/2 – 2/4 + 3/8 – 4/16+…
Чтобы решить эту задачу, надо определить закономерность в изменении элементов. В данном случае можно заметить:
-
Каждый элемент представляет собой дробь. -
Числитель дроби при переходе к следующему элементу возрастает на единицу. -
Знаменатель дроби с каждым шагов увеличивается в 2 раза. -
Знаки перед дробями чередуются (плюс, минус и т.д.).
Любой элемент последовательности можно представить в виде
S=z*c/d
У переменной z меняется знак (эту операцию можно записать в виде z=-z), значение переменной c увеличивается на единицу (c++), а переменная d умножается на 2 (d=d*2).
Алгоритм решения задачи можно записать в виде следующих шагов:
-
Записать в переменную S значение 0. В этой ячейке будет накапливаться сумма; -
Записать в переменные z, c и d начальные значения (для первого элемента): z=1, c=1,d=2; -
Сделать 20 раз следующие две операции:
-
добавить к сумме значение очередного элемента; -
изменить значения переменных z, c и d для следующего элемента.
#include
#include

Начальные значения
void main()
{ clrscr();
float S, z, c, d;
int i;
S = 0; z = 1; c = 1; d = 2;

добавить элемент к сумме
for ( i = 1; i <= 20; i ++ )
{
S = S + z*c/d;

изменить переменные
z = - z;
c ++;
d = d * 2;
}
printf(“Сумма S = %f”, S);
}
Суммы с ограничивающим условием
Рассмотрим более сложную задачу, когда количество элементов заранее неизвестно.
Пример 2. Найти сумму всех элементов последовательности
S=1/2 – 2/4 + 3/8 – 4/16+…
которые по модулю меньше, чем 0.001.
Эта задача имеет решение только тогда, когда элементы последовательности убывают по модулю и стремятся к нулю. Поскольку мы не знаем, сколько элементов войдет в сумму, надо использовать цикл while (или do - while). Один из вариантов решения показан ниже.
#include
#include

начальные значения
void main()
{ clrscr();

Запустить цикл, если а≥0.001
float S, z, c, d, a;
S = 0; z = 1; c = 1; d = 2;
a = 1;
while ( a >= 0.001 )

добавить элемент к сумме
{
a =abs( c / d);
S = S + z*a;

изменить переменные
z = - z;
c ++;
d = d * 2;
}
printf(“Сумма S = %f”, S);
}
Цикл закончится тогда, когда переменная a (она обозначает модуль очередного элемента последовательности) станет меньше 0.001. Чтобы программа вошла в цикл на первом шаге, в эту переменную надо записать любое значение, большее, чем 0.001.
Очевидно, что если переменная a не будет уменьшаться, то условие в заголовке цикла всегда будет истинно и программа «зациклится».
Контрольные вопросы
-
Типы данных, применяемые в языке С++. -
Запись основных стандартных функций. -
Оператор присваивания в языке С++. -
Схема простого циклического процесса. -
Операторы цикла в языке С++, особенности их использования. -
Понятие параметра цикла, тела цикла, управляющих операторов цикла. -
Вложенные циклы. -
Операторы ввода-вывода. -
Управление формой вывода в операторе printf. -
Алгоритм вычисления суммы элементов последовательности. -
Алгоритм поиска максимального (минимального) элемента последовательности. -
Алгоритм определения количества элементов последовательности. -
Понятие параметра цикла, тела цикла, управляющих операторов цикла. -
Управление формой вывода в операторе printf.
Раздел 5 Типы и структуры данных
-
Основные структуры данных
Любая программа в процессе работы обрабатывает некоторые данные. По способу представления в памяти компьютера данные можно разделить на две группы: статические и динамические. Статические данные имеют фиксированную структуру, поэтому размер выделенной для них памяти постоянен. Динамические данные изменяют свою структуру в процессе работы программы, при этом объём памяти изменяется. Основные структуры данных представлены в следующей таблице.
Таблица 1 Различные типы данных
| Статические | Простые | Перечислимые |
| Целые | ||
| Вещественные | ||
| Логические | ||
| Символьные | ||
| Структурированные | Массивы | |
| Записи | ||
| Объединения | ||
| Динамические | Списки | Стек |
| Очередь | ||
| Деревья | АВЛ-деревья | |
| Б-деревья |
Основной характеристикой данных в программировании является тип данных. Любая константа, переменная, выражение, функция всегда относятся к определенному типу. Тип характеризует множество значений, которые может принимать переменная. К простым типам языка программирования относятся целые, вещественные, логические, символьные. Целые типы в языках программирования различаются количеством байт, отведённых в памяти (диапазоном значений) и наличием знака. Вещественные типы характеризуются точностью представления числа. Перечислимые типы образуются в процессе перечисления всех возможных значений. Логический тип является частным случаем перечислимого типа с двумя возможными значениями ИСТИНА и ЛОЖЬ.
Простые типы языка С мы рассмотрели в разделе 4.
5.2 Указатели и массивы
5.2.1. Указатели
Указатель - это переменная, содержащая адрес области памяти. Указатели широко применяются в языке Си. В некоторых случаях без них просто не обойтись, а в некоторых потому, что программы с использование указателей становится короче и эффективнее.
Начнем с того, что поговорим о структуре памяти любого компьютера. Как известно, память компьютера представляет последовательность 8-битовых байтов. Каждый байт пронумерован, причем нумерация начинается с нуля. Номер байта называется адресом. Иногда говорят, что адрес указывает на определенный байт. Таким образом, указатель является просто адресом байта памяти.
Язык Си позволяет определять переменные, которые могут хранить адреса памяти. Такие переменные и называются указателями. Значение указателя сообщает о том, где размещен объект, но ничего не говорит о значении самого объекта.

Присваивая указателю то или иное допустимое значение, можно обеспечить доступ к желаемым данным через этот указатель.
Для описания переменной типа указатель используется символ *.
Формат описания:
Тип *имя;
Указатель всегда указывает на переменную того типа, для которого он был объявлен.
Напимер:
int *x;
char *y;
Пример следует понимать, что x – это указатель на ячейку, в которой хранится целое значение, а y – указатель на однобайтовую ячейку, предназначенную для хранения символа.
Двумя наиболее важными операциями, связанными с указателями, являются операция обращения по адресу * и определение адреса &.
Операция обращения по адресу предназначена для записи или считывания значения, размещенного по адресу, содержащемуся в переменной-указателе.
Например:
int *x;
. . .
*x=5;
Операция определения адреса & возвращает адрес памяти своего операнда. Операндом должна быть переменная.
Напимер:
int *x;
int a=5;
x=&a;
Кроме того, над указателями можно выполнять арифметические операции сложения и вычитания.
Если у – указатель на целое, то унарная операция y++ увеличивает значение адреса, хранящегося в переменной-указателе на число равное размеру ячейки целого типа, т.е. на 2 байта; теперь оно является адресом следующей ячейки целого типа. Соответственно, оператор y-- означает, что адрес уменьшается на 2 байта.
Указатели и целые числа можно складывать. Конструкция у + n (у - указатель, n - целое число) задает адрес n-гo объекта, на который указывает у. Это справедливо для любых объектов (int, char, float и др.); транслятор будет масштабировать приращение адреса в соответствии с типом, указанным в определении объекта.
Любой адрес можно проверить на равенство (= =) или неравенство (!=), больше (>) или меньше (<) с любым другим адресом.
Рассмотрим следующий фрагмент программы:
#include
main()
{
int *x, *w;
int y;
*x=16;
y=-15;
w=&y;
. . .
}
Этот текст можно понимать так:
Выделить память под три переменные x, w, y, где x и w –переменные типа указатель. Оператор *x=16; означает, что в ячейку, адрес которой записан в х, помещается значение 16. Затем переменной у присваивается значение -15. После чего в указатель w записывается адрес переменной y. Синтаксически текст записан правильно. Проблема заключается в том, что указатель х не инициализирован. Описание int *x; приводит к тому, что компилятор резервирует память, необходимую для хранения адреса целой ячейки, но адрес в этой ячейки может быть любой, в том числе и адрес, где хранится полезная информация, например, операционная система. Запись в такую ячейку может привести к сбою в работе компьютера. Поэтому при работе с указателями их надо правильно инициализировать. Существует 4 способа правильного задания начального значения для указателя:
1) Описать указатель глобально, т.е. вне любой функции. При этом указатель будет инициализирован безопасным нулевым адресом. Кроме того любому указателю можно присвоить безопасный нулевой адрес, например:
int *x;
char *y=0;
x=NULL;
Гарантируется, что этот адрес не совпадет ни с одним адресом, уже использованным в системе.
2) Присвоить указателю адрес переменной. Например: w=&y;
3) Присвоить указателю значение другого указателя, к этому моменту правильно инициализированного. Например: x=w;
4) Использовать функции выделения динамической памяти malloc() и calloc(). При использовании этих функция необходимо подключать библиотеку
x=(int*)malloc(sizeof(int));
Приведенный пример означает, что функция выделит область памяти, размер которой определит функция sizeof(). Если вы знаете размер ячейки заданного типа, то можно написать проще: x=(int*)malloc(2);
По окончанию работы программы, память, выделенную функцией malloc() рекомендуется освободить функцией free(x);
И так, вернемся к приведенному ранее фрагменту программы:
#include
main()
{
int *x, *w;
int y;
x=(int*)malloc(sizeof(int));
*x=16;
y=-15;
w=&y;
. . .
}
Теперь никаких конфликтных ситуаций при работе с указателями не возникнет.
5.2.2. Понятие массива
Массив представляет собой упорядоченное множества однотипных элементов. В языке Си массив описывается переменной сложной структуры. При описании массива необходимо указать:
-
способ объединения элементов в структуру (одномерный, двухмерный и т.д. массивы); -
число элементов;
• тип элементов.
Общий вид описания массива
<тип элементов> имя [число элементов];
Доступ к каждому элементу массива осуществляется с помощью индексов. Индексы задают порядковый номер элемента, к которому осуществляется доступ. В языке Си первый элемент массива имеет индекс ноль. Число индексов определяет структуру массива: если используется один индекс, то такой массив называется одномерным, если два индекса - двухмерным, и т.д. В общем случае размерность массива может быть произвольной.
5.2.3. Одномерные массивы
В математике одномерному массиву соответствует n-мерный вектор, например:
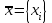 ; i = 1, n,
; i = 1, n,где х, - компонента (координата) вектора;
i- номер компоненты;
п - число компонент.
Описание одномерного массива
На языке Си описание одномерного массива задается следующим образом:
<тип элементов> <имя массива>[размер];
Компилятор отводит под массив память размером (sizeof(тип)*размер) байтов.
Непосредственно при описании можно задать начальные значения массива:
int dat[4]={5,8,-2,11};
float kom[]={3.5,6,-1.1};
Указатели могут обеспечить простой способ ссылок на массив. Имя массива фактически является константой-указателем, ссылающимся на начальный адрес данных (адрес первого элемента массива). Начальный адрес массива определяет компилятор в момент описания массива, и такой адрес не может быть переопределен. Первый элемент массива имеет индекс ноль.
Например:
int Ar[5];
printf (“адрес Ar=%x\n”,Ar);
printf (“адрес Ar=%x\n”,&Ar[0]);
В приведенном фрагменте обе функции printf выводят начальный адрес массива Ar, т.к. выражения Ar и &Ar[0] эквивалентны.
Индексные переменные
Выбор отдельного элемента из массива осуществляется с помощью индексной переменной, которая задается следующим образом:
x[i] - индексная переменная (элемент массива).
Здесь x - имя массива;
i - индекс (номер элемента массива).
В качестве индекса используются:
-
целые константы, например х[2]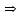 х2;
х2; -
целые переменные, например х[к] хk; -
индексные выражения, например х[2*n+1] x2n+1.
Замечание.В языке Си индексы начинаются с нуля. Индексными выражениями являются арифметические выражения целого типа.
Индексная переменная, как и простая; может стоять в левой части оператора присваивания, например:
х[3]=2.5;
Ввод-вывод одномерных массивов
Ввод-вывод массивов осуществляется поэлементно с помощью операторов scanf и printf соответственно и оператора цикла for..., в котором в качестве параметра используется индекс.
Пример 1. Организовать ввод с клавиатуры массива:
A = (1.2, 5,-6.8, 14).
Необходимо задать описание массива и индекса.
void main()
{ float A [4] ;
int i;
В программе ввод массива рекомендуется организовать в виде диалога, поместив перед оператором ввода оператор вывода (printf), в котором дается поясняющее сообщение, например:
printf(“Введите массив А\n”);
for( i = 0; i<4; i++)
scanf(“%f”,&A[i]);
В момент работы оператора scanf на клавиатуре через один или несколько пробелов набираются элементы массива (ввод в строке экрана) и нажимается клавиша [Enter]:
1.2 5 -6.8 14 [Enter]
Замечание.Элементы массива можно вводить в «столбик», если после ввода каждого элемента нажимать клавишу [Enter].
Пример 2. Организовать вывод массива А на экран таким образом, чтобы все элементы располагались на одной строке экрана.
В программе надо записать следующие операторы:
for ( i = 0; i<4; i++)
printf(%5.2f “,A[i]);
printf(“\n”);
Вид выводимого массива на экране:
1.2 5.0 -6.8 14.0
Оператор printf(“\n”); без списка служит для перевода курсора к началу следующей строки.
Обработка одномерных массивов
При решении задач обработки массивов используют базовые алгоритмы реализации циклических вычислительных процессов: организация счетчика, накопление сумм и произведений, поиск минимального и максимального элементов массива.
Задача 1. Организация счетчика
Дан целочисленный массив: В = {bi};i=
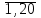 . Определить количество элементов массива, которые делятся на 3 без остатка.
. Определить количество элементов массива, которые делятся на 3 без остатка.#include
#include
void main()
{
clrscr();
int В [20] ; /* описание массива B*/
int i, L;
printf(“Введите массив В\n”);
for( i =0; i<20; i++)
scanf(“%d”, &B[i]); /* ввод данных в массив с клавиатуры*/
L=0;
for( i =0; i<20; i++)
if (B[i] % 3= = 0) /*проверка элемента на кратность 3*/
L ++;
printf(“Кол-во=%d\n”, L);
}
Задача 2.Накопление суммы и произведения
Дано целое число п и массив вещественных чисел:
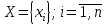 . Вычислить среднее арифметическое и среднее геометрическое чисел массива, используя формулы:
. Вычислить среднее арифметическое и среднее геометрическое чисел массива, используя формулы: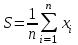 ;
; 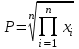 .
.#include
#include
void main()
{
clrscr();
float X [100];
int n, i;
float S=0, P=1;
printf(“Введите размер массива n= “);
scanf(“%d”,&n);
prinf(“Введите массив X\n”);
for( i = 0; i
scanf(“%f”,&X[i]);
for( i=0; i
{
S = S + X[i]; /* вычисление суммы элементов массива Х */
P =P*X[i]; /* вычисление произведения элементов Х */
}
S = S/n; /* вычисление среднего значения Х */
P=exp(l/n*log(P)); /* вычисление среднего геометрического Х */
printf(“S=%6.2f\n”, S);
printf(“P=%10.2f\n”,P);
}
Задача 3. Поиск минимального и максимального элементов массива
Дан вещественный массив: T = {ti}; i=
 . Поменять местами минимальный и максимальный элементы массива и вывести массив после обмена.
. Поменять местами минимальный и максимальный элементы массива и вывести массив после обмена.Решение
В этой задаче для осуществления обмена надо знать не только значения минимального и максимального элементов массива, но и их местоположение. Поэтому во время поиска минимального и максимального элементов необходимо фиксировать их индексы.
Введем обозначения:
min - минимальный элемент;
imin - индекс минимального элемента;
max - максимальный элемент;
imax - индекс максимального элемента.
#include
#include
#include
void main()
{
clrscr();
float Т [10] ; /* описание массива Т */
int i, imin, imax;
float min, max;
printf(“Введите массив Т\n”);
for( i = 0;i<10;i++)
scanf(“%f”,&T[i]);
min =+1E6;
max =-1E6;
for( i = 0; i<10; i++)
{
if (T[i]
{
min = T[i];
imin=i; /* сохранение номера текущего min */
}
If( T[i]>max)
{
max = T[i];
imax = i; /* сохранение номера текущего max */
}
}
T[imin]=max;
T[imax]= min;
for( i= 0; i<10; i++)
printf(“%6.2f “,T[i]);
printf(“\n”);
}
5.2.4. Двухмерные массивы
Двухмерные массивы в математике представляются матрицей:
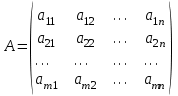
или сокращенно можно записать: А =
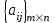 , где т - число
, где т - числострок; n - число столбцов; i,j- индексы (номера) текущих строки и столбца, на пересечении которых находится элемент aij.
Описание двухмерного массива
Описание матрицы задается структурным типом вида:
<тип элементов><имя> [m][ n] ;
где m – количество строк;
n –количество столбцов матрицы.
|По описанию матрицы во внутренней памяти компьютера выделяется область из т
 п последовательных ячеек, в которые при работе программы записываются значения элементов матрицы. Например, по описанию:
п последовательных ячеек, в которые при работе программы записываются значения элементов матрицы. Например, по описанию: float A [3][5];
В памяти компьютера для элементов матрицы выделяется область, состоящая из 3
5=15 последовательных ячеек вещественного типа. Из описания видно, что матрица состоит из трех строк и пяти столбцов.Обращение к отдельным элементам матрицы осуществляется с помощью переменной с двумя индексами, причем индексы, как и для одномерного массива начинаются с нуля. Например:
А[i][j]
aij;А[2][3]
a23;А[2*n][k+1]
a2n,k+1.Ввод-вывод двухмерного массива
Для поэлементного ввода и вывода матрицы используется двойной цикл for.... Если задать индекс i как параметр внешнего цикла, а индекс j как параметр внутреннего цикла, то ввод-вывод матрицы осуществляется построчно.
Пример 1.Организовать ввод целочисленной матрицы М по строкам.
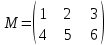
Описание матрицы вместе с текущими индексами имеет вид:
void main()
{
int М [2][3] ;
int i, j;
Ввод в программе реализуется в форме диалога, т.е. сопровождается поясняющим сообщением:
printf(“Введите матрицу М\n”);
for( i = 0; i<2; i++)
for( j = 0; j< 3; j++)
scanf(“%f”,&m[i][ j]);
На клавиатуре желательно для наглядности восприятия набирать элементы матрицы по строкам, отделяя числа друг от друга одним или несколькими пробелами:
1 2 3 [Enter]
4 5 6 [Enter]
Пример 2.Организовать вывод матрицы М на экран.
Вывод матрицы необходимо реализовать в удобном для чтения виде, т.е. чтобы на одной строке экрана располагалась одна строка матрицы. С этой целью в тело внешнего цикла, помимо внутреннего, включается оператор printf, который переводит курсор к началу следующей строки экрана после вывода текущей строки матрицы.
for ( i = 0; i<2; i++)
{
for ( j = 0; j< 3; j++)
printf(“%3d “,m[i][j]);
printf(“\n”);
}
Вывод матрицы на экран будет следующим:
1 2 3
4 5 6
Обработка матриц
Базовыми алгоритмами обработки матриц являются те же алгоритмы, которые используются при обработке одномерных массивов. Однако реализацию этих алгоритмов можно условно рассматривать для двух типов задач.
-
Алгоритмы реализуются при просмотре всех элементов матрицы (просмотр может быть с условием). Начальная установка алгоритма выполняется перед двойным циклом. В этом случае запись операторов цикла для параметров i и j осуществляется последовательно друг за другом и имеет вид:
<начальная установка>
for (i = 0; i
for (j = 0; j< n; j++)
<тело цикла>;
-
Алгоритмы реализуются внутри каждой строки или каждого столбца матрицы. В этом случае начальная установка алгоритма выполняется между операторами цикла, записанными для параметров i и j. Например, если алгоритм реализуется для каждой строки, то запись в программе имеет следующий вид:
for ( i = 0; i< m ; i++)
{
<начальная установка>
for ( j = 0; j< n; j++)
<тело цикла>;
}
Нижерассмотрены примеры программирования задач каждого типа.
Реализация алгоритмов задач первого типа
Задача 1.Дана матрица вещественных чисел А = {аij}4х6.
Вычислить значение Z = Р1/|Р2|, где Р1 и Р2 – произведения положительных и отрицательных элементов матрицы соответственно.
#include
#include
#include
void main()
{
clrscr();
float A [4][6] ; /* описание матрицы А
int i,j;
float P1,P2,Z;
printf(“Введите матрицу А\n”);
for ( i = 0; i<4; i++)
for ( j = 0;j<6; j++)
scanf(“%f”,A[i][j]);
Pl=l; /* установка начальных значений
P2=1; произведений
for ( i = 0; i<4; i++)
for ( j =0; j< 6 ;j++)
{
if (A[i][j]>0) P1= P1*A[i][j]; /* произведение + */
if ( A[i][j]<0) Р2 = P2*A[i][j]; /* произведение - */
}
Z=Pl/abs(P2);
printf(“Z=%10.2f ”,Z);
}
Задача 2.В квадратной целочисленной матрице В= {bij}5х5 вычислить модуль разности между числом нулевых элементов, стоящих ниже главной диагонали, и числом нулевых элементов, стоящих выше главной диагонали.
Введем обозначения:
L1 – счетчик нулевых элементов ниже главной диагонали;
L2 – счетчик нулевых элементов выше главной диагонали;
L = |L1 -L2|.
#include
#include
#include
void main()
{
clrscr();
int B [5][5] ; /* описание матрицы B */
int i, j, LI, L2, L;
printf(“Введите матрицу В\n”);
for ( i = 0; i< 5; i++)

for (j = 0;j<5; j++)
scanf(“%d”,B[i][j]);
L1 = 0; /* инициализация счетчиков L1 и L2 */
L2 = 0;
for ( i = 0; i< 5; i++)
for (j = 0; j< 5; j++)
if (B[i][j]==0 ) /* поиск элементов, равных нулю */
{
if ( i>j) Ll=L1+1; /* выше главной диагонали */
if ( i
}
L = abs(Ll - L2);
printf(“L=%d”, L);
}
Реализация алгоритмов задач второго типа
Задача 1.В матрице X ={хij}3х6вещественных чисел первый элемент каждой строки поменять местами с минимальным элементом этой строки. Вывести матрицу Xпосле обмена.
#include
#include
#include
void main()
{
clrscr();
float X[3][6 ]; // описание матрицы X
int i,j,jmin;
float min;
printf(“введите матрицу X\n”);
for(i=0; i<3; i++) /* ввод значений матрицы */
for (j= 0; j<6; j++)
scanf(“%f ”,X[i][j]);
for(i=0; i<3; i++)
{
min=+lE6;
for (j=0; j<6; j++)
if (X[i][j]
{
min=X[i][j];
jmin=j;
}
X[i][jmin]=X[i][0]; // перестановка первого элемента //матрицы с наименьшим
X[i,0]=min;
}
for(i=0; i<3; i++)
{
for (j=0; j<6; j++) printf(“%8.2f”,X[i][j]);
printf(“\n”);
}
getch();
}
Задача 2.Дана матрица вещественных чисел С = {сij}8х4. Вычислить среднее арифметическое каждого столбца. Результат оформить в виде одномерного массива S = {sj};j=
 .
.#include
#include
main()
{ float С[8][4];
float S[4];
int i, j;
printf(“Введите матрицу С:\n”);
for(i=0; i<8; i++)
for (j= 0; j<4; j++)
scanf(“%f ”,C[i][j]);
for (j= 0; j<4; j++)
{
S[j]=0;
for(i=0; i<8; i++)
S[j]= S[j] + C[i][j];
S[j]=S[j]/8;
}
for (j= 0; j<4; j++) printf(“%8.2f”,S[j]);
printf(“\n”);
getch();
}
В приведенной выше программе для вычисления каждого элемента S[j] организован двойной цикл, в котором индекс j является внешним параметром цикла, а индекс i - внутренним.
Приведем вариант программы без использования одномерного массива S.
#include
#include
main()
{ float С[8][4];
float S;
int i, j;
printf(“Введите матрицу С:\n”);
for(i=0; i<8; i++)
for (j= 0; j<4; j++)
scanf(“%f ”,C[i][j]);
for (j= 0; j<4; j++)
{
S=0;
for(i=0; i<8; i++) S:= S + C[i][j];
S = S/8;
printf(“Среднее арифметическое %d -го
столбца =%8.2f\n”,j, S);
}
}
5.3 Текстовые данные
В языке СИ текстовая информация может быть представлена двумя типами данных: символьным и строковым.
5.3.1. Символьный тип данных
Значением данных символьного типа является любой символ
из набора всех символов компьютера. Каждому символу соответствует порядковый номер (код) в диапазоне 0..255. Для кодировки символов первой половины диапазона (0..127) используется код ASCII (американский стандартный код для обмена информацией).
Вторая половина символов с кодами 128..255 может быть различной.
При написании программ символьные данные могут быть
представлены либо константами, либо переменными.
Символьная константа представляет собой одиночный
символ, заключенный в апострофы, например:
‘Y’ ‘!’ ‘_’ ‘Д’
Символьная переменная объявляется с помощью ключевого слова char, например:
char cr;
Во внутренней памяти компьютера каждый символ занимаем 1 байт.
Ввод-вывод символьных данных
Для ввода символьных данных используются функции: scanf() – форматированный ввод, getchar() – специальная функция для ввода символа. Для форматного ввода и вывода символьных констант используется спецификатор (формат) %с. Необходимо помнить, что нажатие любой небуквенной клавиши при вводе ([пробел], [Enter] и др.) будет значимым и восприниматься как символ.
Пример 1. Организовать ввод символьных переменных:
a='i';b='j';c='k'
main()
{ char a,b,c;
printf(“Введите исходные данные”);
scanf(“%c%c%c”,&a,&b,&sc);
. . .
}
При вводе символы набираются без апострофов:
ijk [Enter]
Символ клавиши [Enter] выходит за пределы списка ввода, поэтому он игнорируется.
При использовании для ввода символьной информации с помощью функции getchar() надо помнить, что функция переводит программу в ожидание нажатого символа, но при нажатии символа на клавиатуре он не выводится на экран. Например, при выполнении следующего фрагмента программы
printf(“Введите исходные данные”);
a=getch();b=getch();c=getch();
переменные будут введены, но на экране их значения не отразятся.
Для вывода символьных данных используются функции printf() и putchar().
Пример 2. Организовать вывод указанных выше переменных на экран в одну строку. Запись операторов вывода будет следующей:
printf(“%c%c%c\n”,a,b,c);
Нa экране будет отображено:
ijk
Если использовать для вывода функцию putchar():
putchar(a); putchar(b); putchar(c);
на экране будет отображен тот же результат.
Обработка символьных данных
Поскольку символы в языке СИ упорядочены, к ним можно применять операции отношения (>, >=, <, <=, =, <>). Это дает возможность записывать логические выражения с символьными данными в условных операторах. Например, оператор
If (ch=='!' ) ch ='.';
заменяет в символьной переменной ch восклицательный знак точкой.
Символьные данные могут использоваться и в операторах цикла for. Так, при выполнении операторов:
for (ch= 'a';ch>='d';ch++)printf(“%с ”,ch);
в строку экрана выводится последовательность:
a b с d
Если значение символьной переменной вывести, используя спецификатор для целых чисел %d, на экране отобразится код символа. Например:
for (ch= 'a';ch>='d';ch++)printf(“%d ”,ch);
на экран будет выведено:
97 98 99 100
Над символьными данными можно выполнять арифметические операции сложению и вычитания. Так, например, операция ch++; из предыдущего примера увеличивает код символа, хранящегося в переменной ch на 1. Или, выполняя операцию ch='a'-'A'; будет получена разница кода большой и маленькой буквы латинского алфавита. Так, например, если в символьной переменной ch1 хранится маленькая буква алфавита, то, выполнив действия:
char ch,ch1,ch2;
ch='a'-'A';
ch1='k';
ch2=ch1-сh;
printf(“%c-%d %c-%d\n”,ch1,ch1,ch2,ch2);
в переменную ch2 запишется та же буква, только большая, а на экран
k-107 K-75
5.3.2. Строковый тип данных
Значением данных строкового типа (строка) является любая последовательность символов из набора символов компьютера. Причем компьютеру все равно, какие данные записаны – для него это набор байтов.
Строковая константа - это строка, заключенная в кавычки, например:
“Язык программирования”
Строковая переменная или строка представляет собой массив символов, поэтому и объявляется она именно так:
сhar st[30];
В квадратных скобках указывается максимальное число символов в строке st.
Под значение строковой переменной в памяти компьютера отводится (МАХ) байт, пронумерованных от 0 до МАХ-1, где МАХ - заданный максимальный размер строки.
Однако строка отличается от массива тем, что она заканчивается символом с кодом 0 - признаком окончания строки. По местоположению этого специального символа определяется фактическая длина строки.
Начальное значение строки можно задать при объявлении в двойных кавычках после знака равенства:
char s[80] = "Язык программирования Си";
Символы в кавычках будут записаны в начало массива s, а затем - признак окончания строки '\0'.
При описании строки можно также написать так:
char s[] = "Язык программирования Си";
В этом случае компилятор подсчитает символы в кавычках, выделит памяти на 1 байт больше и занесет в эту область саму строку и завершающий ноль.
Ввод-вывод строковых данных
При вводе строк, как и символов, используется функция scanf(). При этом для форматного ввода и вывода строк используется спецификатор %s. Однако нажатие клавиши [Enter] или клавиши [пробел] не является значимым символом. При вводе строки с помощью функции scanf() нажатие одной из этих клавиш формирует символ конца строки. Таким образом надо помнить, что функция scanf() позволяет записать в строку только одно слово.
Пример.Организовать ввод ФИО студента.
char fam[20];
printf("Введите фамилию и инициалы студента");
scanf("%s",fam);
На клавиатуре строка набирается без кавычек, например:
Андреева СВ. [Enter]
Одновременно с вводом строки в байт с индексом восемь запишется символ с кодом 0. Инициалы студента с эту строку записаны не будут.
Для ввода текста содержащего пробелы можно использовать специальную функцию gets(). При вводе строки с помощью этой функции только нажатие клавиши [Enter] сформирует символ конца строки.
Так, например, в предыдущей задаче:
char fam[20];
printf(“Введите фамилию и инициалы студента”);
gets(fam);
использование функции gets() позволит записать в строку fam не только фамилию, но и инициалы.
Вывод строк осуществляется с помощью функции printf() и специальной функции puts(). Например, оператор
printf(“| %20s|”,fam);
выведет на экран в правую часть поля из 20 позиций строку fam:
| Андреева С.В.|
Специальная функция puts() позволяет вывести содержимое строки и переводит курсор на следующую строку. Например:
putchar(‘|’); puts(fam);putchar(‘|’);
приведет к получению следующего результата:
|Андреева С.В.
|
Последний символ будет выводиться в следующей строке экрана.
Обработка строковых данных
К любому символу строки можно обратиться как к элементу одномерного массива, например, запись st[i] определяет i символ в строке st. Поэтому при решении некоторых задач обработку строковых данных можно проводить посимвольно, организуя циклы для просмотра строки.
Например: Дано предложение. Определите количество слов в нем.
Решение:
Слова в предложении разделяются пробелами. Подсчитав количество пробелов, можно определить количество слов, учитываю, что между словами введен только один пробел.
#include
#include
#include
main()
{ char slova[120];
int i, n, k=1;
printf(“Введите предложение\n”);
gets(slova);
n= strlen(slova); // функция strlen() возвращает длину строки
for(i=0;i
if(slovo[i]==‘ ’)k++;
printf("k=%d\n",k);
}
Стандартные функции и процедуры
Большинство действий над строками реализуется с помощью стандартных функций. Библиотека языка Си содержит большое количество таких функций, прототипы которых определяются в заголовочном файле string.h. Рассмотрим некоторые из них.
Сравнение строк:
strcmp(str1,str2) – сравнивает две строки str1 и str2 и возвращает 0, если они одинаковы; результат отрицателен, если str1
strncmp(str1, str2, kol) – сравниваются части строк str1 и str2 из kol символов. Результат равен 0, если они одинаковы.
Сравнение двух строк выполняется последовательно слева неправо с учетом кодировки символов. Например, сравнивая стоки st1 и st2
char st1[10]=”Пример”;
char st2[10]=”ПPимер”;
int a;
if (strcmp(st1,st2)>0)
a=1;
else
a=2;
переменной а будет присвоено значение 1, так как код символа 'р' больше кода символа 'Р'.
Сцепление строк
strcat(str1,str2) - сцепление строк в порядке их перечисления.
strncat(str1,str2,kol) – приписывает kol символов строки str2 к строке str1.
Функция служит для объединения двух строк в одну. Например, в результате выполнения операторов:
char fam[] = “Андреева С.В.”;
char pr[7]= “ “; //7 пробелов
strcat(fam ,pr);
printf(“|%20s|”, fam);
на экран выведется строка:
|Андреева С.В. |
Заметим, что строка вывода занимает поле в 20 позиций, а переменная fam располагается в левой части поля.
Определение длины строки
strlen(str) – определяет длину строки str.
Пример.Определить длину строки
charfam[] = “Андреева С.В”;
printf(“%d”,strlen(fam));
функция strlen() вернёт значение равное 13 (символов).
Копирование строк
strcpy(str1,str2) – копирует строку str2 в строку str1.
Strncpy(str1, str2, kol) – копирует kol символов строки str2 в строку str1.
Пример.Скопировать фамилию сотрудника в переменную fam и вывести на экран.
int main()
{ char fam[15];
char *str = " Андреева СВ.";
strcpy(fam, str);
printf("|%s|\n", fam);
return 0; }
В результате выполнения данных операторов на экран будет выведена строка: |Андреева СВ.|
Поиск символа в стоке
P=strchr(st, ch) - функция поиска адреса символа ch в заданной строке st. Результатом выполнения поиска является адрес P найденного символа в строке st, иначе возвращается нулевой адрес. Чтобы вычислить порядковый номер символа ch в строке, можно из адреса P вычесть адрес начала строки.
Пример.В заданной фамилии определить порядковый номер символа ‘n’.
main()
{ char fam[] = "Ivanov";
char faml[20];
char a='n'; char *p;
p=strchr(fam,a);
if(p)
printf("|%s|%d", fam,p-fam);
else
printf("нет такого символа в фамилии!\n");
}
Пример программирования текстовой задачи
Исходный текст является предложением, заканчивающимся точкой. Слова в предложении отделяются друг от друга одним пробелом. Определить самое длинное слово в предложении.
#include
#include
#include
main()
{ char slovo[12],x[120];
int i,m=0,n,k=0;
gets(x);
for(i=1;i
if(x[i]!=' ')k++;
else{ if (k>m){ m=k;n=i;}
k=0;}
k=0;
for(i=n-m;i
slovo[k++]=x[i];
slovo[k]=0;
printf("%s \n%s\n",slovo,x);
printf("%d %d\n",strlen(slovo),strlen(x));
}
Контрольные вопросы
-
Какие ограничения накладываются на индексы элементов массивов? -
Способы описания массивов на языке С++. Понятия размерности массивов, описание размерности массивов. -
Задание типов элементов массива. Могут ли элементы массива иметь разный тип? -
Как располагаются элементы массива в памяти? -
Чем отличаются алгоритмы поиска максимального и минимального элемента массива. -
Что является общим во всех алгоритмах формирования и обработки массивов? -
Чем отличаются алгоритмы расчета суммы и подсчета числа элементов массива. -
Как располагаются элементы двухмерного массива в памяти? -
Чем отличаются алгоритмы поиска максимального и минимального элемента массива, расчета суммы и подсчета числа положительных (отрицательных) элементов массива для массива в целом и для каждой его строки (столбца)? -
Особенности организации ввода – вывода двухмерных массивов на языке С++. -
Описание символьных данных и строк на языке С++. -
Встроенные функции языка С++, используемые для обработки строк. -
Кодирование символьной информации в ПЗВМ.
Раздал 6 Структуры данных
6.1 Понятие структуры
6.2 Обработка структур
6.1 Понятие структуры
Очень часто при обработке информации приходится работать с блоками данных, в которых присутствуют данные разных типов. Например, информация о книге в каталоге библиотеки включает в себя автора, название книги, год издания, количество страниц и т.п.
Для хранения этой информации в памяти не подходит обычный массив, так как в массиве все элементы должны быть одного типа. Конечно, можно использовать несколько массивов разных типов, но это не совсем удобно.
В современных языках программирования существует особый тип данных, который может включать в себя несколько элементов более простых (причем разных!) типов.
Структура - это тип данных, который может включать в себя несколько полей – элементов разных типов (в том числе и другие структуры).
В общем случае при работе со структурами следует выделить четыре момента:
- объявление и определение типа структуры,
- объявление структурной переменной,
- инициализация структурной переменной,
- использование структурной переменной.
Данные типа структура, как и массивы, относятся к сложным структурам данных. Структура состоит из фиксированного числа элементов, называемых полями. Однако, в отличие от массива, поля могут быть различного типа. Например, структурой можно считать строку экзаменационной ведомости:
Андреева С.В. 4 5 5
Данная структура состоит из четырех полей: одно поле - строка (ФИО студента) и три числовых поля (оценки студента по предметам).
Поскольку структура - это новый тип данных, его надо предварительно объявить в начале программы. Определение типа структуры делается так:
struct Имя
{
<тип> <имя 1-го поля>;
<тип> <имя 2-го поля>;
…………
<тип> <имя последнего поля>;
};
Например, задание типа записи строки экзаменационной ведомости выглядит следующим образом:
struct student
{
char fam[20];
int mathematics, informatics, history;