Файл: В подобной ситуации я считаю актуальным создание программы для обучения основам синтаксиса и семантики языка.doc
ВУЗ: Не указан
Категория: Не указан
Дисциплина: Не указана
Добавлен: 08.11.2023
Просмотров: 75
Скачиваний: 1
ВНИМАНИЕ! Если данный файл нарушает Ваши авторские права, то обязательно сообщите нам.
1.1.1 Синтаксический анализ языка SQL
Неотъемлемой частью большинства сложных ИТ-систем являются реляционные базы данных (РБД) и алгоритмы доступа к данным на основе языка структурированных запросов SQL.
В то же время традиционное обучение языку SQL, впрочем, как и многим другим сложным темам в условиях массового производства, как правило, не дает требуемого качества подготовки каждого студента.
Причина тому - сложность индивидуального и адаптивного подхода к каждому студенту, обусловленная, в том числе, магическим числом Миллера, демонстрирующим ограниченность кратковременной памяти человека.
По мнению многих исследователей, выход следует искать в создании и внедрении компьютерных обучающих программ, обладающих практически неограниченной памятью и развитыми интеллектуальными способностями.
Основной проблемой предложенных подходов является их недостаточная гибкость при появлении новых требований. Вследствие этого возникает задача создания нового подхода к ИКО SQL, который объединял бы в себе достоинства уже существующих подходов, и, насколько это возможно, устранял их недостатки.
Цель синтаксического анализа -автоматическое построение функционального дерева фразы, т.е. нахождение взаимозависимостей между разно уровневыми элементами предложения. Существует достаточно много различных способов синтаксического анализа естественно-языковых текстов, которые можно проанализировать с различных точек зрения. Общая структура классификации способов синтаксического анализа приведена в таблице 1
Таблица 1 - Классификация способов синтаксического анализа
| № п/п | Основание классификации | Группа методов |
| 1 | Тип цели | Одноцелевые Многоцелевые |
| 2 | Синтаксическая структура | Построение графа зависимостей Построение дерева непосредственных составляющих |
| 3 | Формальные теории описания естественного языка | Формально-грамматические методы Вероятностно-статистические методы |
С точки зрения цели синтаксического анализа можно выделить два основных подхода: одноцелевой и многоцелевой. При первом подходе для фразы требуется построить одно синтаксическое представление
, этот подход характерен для первых алгоритмов синтаксического анализа, когда считалось, что синтаксических средств достаточно для того, чтобы обеспечить правильный анализ фразы, хотя бы для большинства фраз. При втором подходе для фразы требуется получить все те синтаксические представления, которые удовлетворяют определенным соглашениям (все «правильно построенные» представления). Вопрос о том, какое из этих представлений является не только правильно построенным, но и правильным, т.е. соответствующим смыслу анализируемой фразы, в рамках синтаксического анализа не решается.
Одним из основных компонентов лингвистической базы знаний, осуществляющей автоматический синтаксический анализ, является описательная модель синтаксической структуры предложения. Такая модель в значительной степени передает концепцию разработчиков относительно синтаксического уровня анализа: какая именно информация об элементах предложения и их взаимосвязях должна выявляться в процессе анализа, присутствовать в его результатах и какие формы представления ей адекватны. Наиболее общим для разработчиков синтаксических анализаторов является взгляд, что синтаксическое строение предложения можно представить некоторым частично упорядоченным множеством бинарных связей между элементами. Виды и свойства элементов, связей и отношения порядка варьируют в разных моделях.
Представления о бинарных синтаксических связях используются в двух известных моделях синтаксической структуры: графах зависимостей и графах непосредственных составляющих. В настоящее время эти две формы представления синтаксической структуры остаются основными. Они используются в чистом виде или - очень часто - в смешанных формах, сочетающих в себе свойства обоих графов.
Описание структур в форме классического графа зависимостей хорошо соответствует русской грамматической традиции: оно основывается на понятии бинарного словосочетания в предложении с выделенными главными и зависимыми элементами. Элементы изображаются узлами графа, подчинение одного узла другому - направленными дугами, вследствие чего граф зависимостей является ориентированным графом. Обычно ровно один узел графа в подавляющем большинстве моделей, соответствующий сказуемому, не имеет подчиняющего узла и называется вершиной. Иногда двумя вершинами представляют подлежащее и сказуемое.
Отношение подчинения задает частичный порядок на множестве узлов. Если одному
узлу подчиняется сразу несколько узлов, то среди последних порядок не определен: граф зависимостей не передает информацию об относительной степени близости подчиненного слова к главному.
Как правило, отношение подчинения подразделяется на ряд типов, и дуги графа помечаются индексами синтаксических отношений. К числу редких исключений, когда синтаксическое отношение в графе зависимостей не дифференцируется, относятся системы группы Г.Г. Белоногова.
Иногда граф зависимостей одновременно с отношением подчинения задает и отношение линейного порядка следования узлов. Такой граф называется
расположенным. В большинстве случаев отношение подчинения и отношение линейного порядка слов в предложении связаны законом проективности, который при данном способе изображения формулируется так: никакая дуга, исходящая из некоторого узла, не пересекает других дуг или перпендикуляров, опущенных из более верхних узлов.
Особая сложность связана с представлением в древесной структуре явлений однородности. Изображение всех связей однородных членов между собой, с подчиняющими и подчиненными элементами приводит к возникновению замкнутых контуров в графах зависимостей. Чтобы избежать этого, часто используют представление, при котором сочинительная связь включается в граф зависимостей наравне с другими синтаксическими отношениями (СинО), а подчинительные связи, общие для группы однородных членов, изображаются лишь для одного члена группы.
1.1.3 Постановка задачи
Целью дипломного проекта является разработка анализатора запросов на SQL в учебных целях.
Поскольку для языка SQL характерна избыточность форм представления запросов, то для любой задачи может существует более одного рационального SQL-запроса. Отсюда можно сделать предположение о том, что необходимо проверять соответствие SQL-запроса некоторому набору эталонов, выявленных для данной задачи.
В случае совпадения с одним из эталонных решений система идентифицирует ответ как известный системе. Каждый эталон, хранимый в системе, характеризуется набором параметров, определяющих его качество (и, следовательно, знания и умения обучаемого). Такими параметрами, к примеру, могут пространственно-временные затраты
, количество символов в запросе (обуславливает удобство чтения и понимания запроса другим человеком).
В случае, когда система не идентифицирует ответ как известный, она может попробовать выполнить его на реальной БД на нескольких наборах данных. Поскольку выборка некоторого множества кортежей является основным заданием проекта SQL-запроса (в рамках данной работы рассматриваются только запросы выборки), то все правильные ответы к данному заданию должны выбирать одни и те же множества данных на любом начальном множестве данных. Отсюда с большой долей вероятности можно сделать вывод, что если запрос не известен системе, но на разных начальных наборах данных дает на выходе одно и то же множество кортежей, что и эталонный (правильный по умолчанию), то этот запрос можно классифицировать как верный ответ.
Таким образом, можно выделить следующие классы SQL-запросов:
-
Наилучшее решение, известное системе; -
Приемлемое решение, но существует лучше; -
Решение, неизвестное системе:
-
Неправильное; -
Похожее на правильное.
Графическая модель классификации ответов представлена на рис. 2
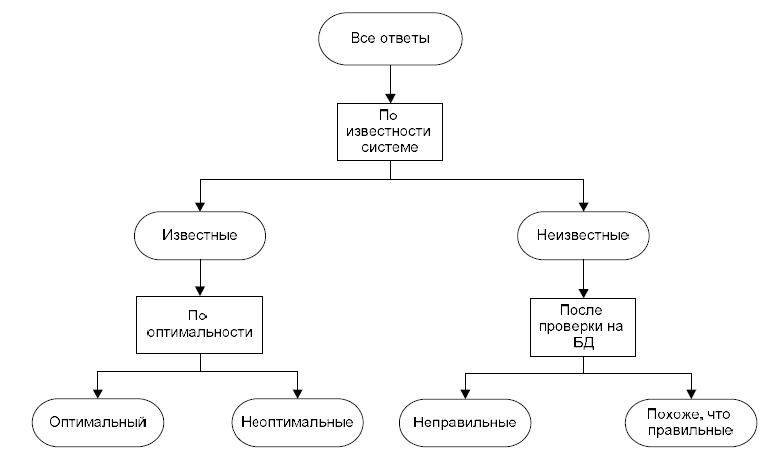
Рисунок 2- Графическая модель классификации ответов
Каждое задание, которое предоставляется студенту, характеризуется двумя типами параметров: скрытыми и открытыми. К скрытым параметрам можно отнести те параметры, которые студенту необходимо отразить в написанном SQL-запросе, например, имена таблиц, полей, значения полей, условия и т.д.; эти параметры необходимы системе для генерации эталонных решений конкретного задания и не должны показываться студенту. Открытыми параметрами являются условие задания, схема таблиц и их связей в БД; они показываются студенту и на их основе он решает поставленную задачу.
После генерации нового задания (его скрытых и открытых параметров) студенту на рабочую форму программы выводится текст (условие) задания, схема БД и поле для ввода собственного SQL-запроса. После нажатия кнопки подтверждения ответа система считывает SQL-запрос из текстового поля, и далее приступает к его анализу в соответствии со следующим сценарием:
1. Происходит лексический анализ SQL-запроса (разбиение непрерывной строки на лексемы, и их классификация как терминалов и не терминалов);
2. Выполняется синтаксический анализ SQL-запроса в соответствии с описанным набором правил грамматики данного языка;
3. Дерево синтаксического разбора запроса сравнивается с деревьями заранее сгенерированного набора эталонов. При этом каждый эталон описывается набором параметров, характеризующих его качество по ряду аспектов: пространственно-временные затраты, удобство восприятия другими пользователями (читабельность) и т.д. (набор параметров можно расширить в условиях изменившихся требований); При этом:
3.1. В случае, если SQL-запрос совпадает с эталоном, который характеризуется оптимальными параметрами качества, студенту выводится сообщение об абсолютно верном решении;
3.2. Если SQL-запрос совпадает с одним из эталонов, который характеризуется не наилучшими показателями, студенту выводится предупреждение о правильном, но не оптимальном ответе, и предлагается подумать еще;
3.3. Если SQL-запрос в большой степени совпадает с одним из эталонов, но не является правильным, то студент информируется о месте допущенной ошибки, и ему предлагается решить данную задачу еще раз и исправить ошибку;
3.4. Если SQL-запрос студента не соответствует ни одному из эталонов, система переходит к следующему пункту;
4. Запрос выполняется на реальной БД на разных наборах данных, и полученное множество кортежей сравнивается с множеством кортежей, полученных при выполнении эталонного запроса, характеризующегося наилучшими показателями качества.
Сравнение множеств может производиться путем расчета хеш-функций обеих множеств, и сравнения их значений;
4.1. В случае совпадения выбранных множеств студенту выводится сообщение о правильном ответе. Поскольку SQL-запрос верен, но не известен программе, то далее в системе регистрируется новый эталонный запрос для данного задания;
4.2. В случае, когда показатели качества SQL-запроса выше, чем в наилучшем эталонном запросе, известном системе, этот новый запрос регистрируется как новый наилучший эталон. Студенту в таком случае могут быть начислены дополнительные баллы;
4.3. В случае несовпадения множеств ответ студенту считается неверным. Ему предлагается другое задание на такую же тему;
5. В случае правильного ответа студенту начисляются баллы за это задание, и система переходит к новому заданию на другую тему.
Представленный метод позволяет проводить анализ SQL-запроса по многим критериям.