Файл: В подобной ситуации я считаю актуальным создание программы для обучения основам синтаксиса и семантики языка.doc
ВУЗ: Не указан
Категория: Не указан
Дисциплина: Не указана
Добавлен: 08.11.2023
Просмотров: 72
Скачиваний: 1
ВНИМАНИЕ! Если данный файл нарушает Ваши авторские права, то обязательно сообщите нам.
Введение
Знание языка управления базами данных SQL является неотъемлемой частью обучения основам реляционных баз данных и современных информационных систем. Несмотря на большое кол-во справочной литературы, у многих учащихся возникают проблемы с его усвоением. Основной причиной этого является отсутствие специализированного программного обеспечения, предназначенного непосредственно для обучения основам синтаксиса и семантики языка. В большинстве случаев практические работы проходят в программах интерфейс и функционал которых направлен не на обучение.
После написания программы и появления «живых» данных выясняется, что реакция программы на тестовые наборы, порой сильно отличается от работы с реальными данными. Программисты обычно мало внимания уделяют формированию тестовых наборов данных, что является серьезной ошибкой. Ставка делается на то, что используются современные «крутые» СУБД, которые сами себя настраивают. К сожалению, это не совсем так, и работе с базой данных следует уделять пристальное внимание. В идеале, за обработку бизнес логики должны отвечать специалисты. Но и рядовым программистам полезно иметь навыки и знания по архитектуре СУБД и написанию SQL- запросов.
Практика показывает, что, анализируя и перестраивая SQL -операторы можно снизить время их выполнения в десятки, а иногда и в сотни раз. После разработки нескольких проектов, у программистов вырабатываются навыки написания более «быстрых» запросов. Но все равно полезно выполнять периодический анализ затрат ресурсов сервера при работе вашего творения. И хотя по большому счету анализ использования ресурсов сервера это работа администратора базы данных, иметь навыки по оптимизации программ никому не помешает. Тем более что это не так сложно, как кажется на первый взгляд.
В подобной ситуации я считаю актуальным создание программы для обучения основам синтаксиса и семантики языка.
Целью данного дипломного проекта является проектирование и разработка анализатора SQL-операторов, который можно использовать в учебных целях. Разрабатываемая программа должна анализировать запрос и указывать на его ошибки. Предметом для дипломного проектирования является инструментальное средство для обучения основам синтаксиса и семантики языка.
В соответствии с целью, в проекте должны решаться следующие задачи:
-
Анализ проблемы синтаксического анализа; -
Анализ предметной области; -
Разработка и описание архитектуры системы; -
Разработка базы данных и ее описание; -
Описание работы системы; -
Тестирование системы и оценка его результатов; -
Оценка стоимости разработки системы и ее экономической эффективности; -
Разработка условий безопасного труда.
-
Общая часть
1.1 Анализ проблемы синтаксического анализа языка SQL
1.1 Язык SQL
Язык SQL (Structured Query Language - структурированный язык запросов) представляет собой стандартный высокоуровневый язык описания данных и манипулирования ими в системах управления базами данных (СУБД), построенных на основе реляционной модели данных. [2]
Язык SQL был разработан фирмой IBM в конце 70-х годов. Первый международный стандарт языка был принят международной стандартизирующей организацией ISO в 1989 г., а новый (более полный) - в 1992 г. . В настоящее время все производители реляционных СУБД поддерживают с различной степенью соответствия стандарт SQL92.
Единственной структурой представления данных (как прикладных, так и системных) в реляционной базе данных (БД) является двумерная таблица. Любая таблица может рассматриваться как одна из форм представления теоретико-множественного понятия отношение (relation), отсюда название модели данных - «реляционная». В реляционной модели данных таблица обладает следующими основными свойствами:
-
идентифицируется уникальным именем; -
имеет конечное (как правило, постоянное) ненулевое количество столбцов; -
имеет конечное (возможно, нулевое) число строк; -
столбцы таблицы идентифицируются своими уникальными именами и номерами;
-
содержимое всех ячеек столбца принадлежит одному типу данных (т.е. столбцы однородны), содержимым ячейки столбца не может быть таблица;
-
строки таблицы не имеют какой-либо упорядоченности и идентифицируются только своим содержимым (т.е. понятие «номер строки» не определено); -
в общем случае ячейки таблицы могут оставаться «пустыми» (т.е. не содержать какого-либо значения), такое их состояние обозначается как NULL.
На содержимое таблиц допустимо накладывать ограничения в виде:
-
требования уникальности содержимого каждой ячейки какого-либо столбца и/или совокупности ячеек в строке, относящихся к нескольким столбцам; -
запрета для какого-либо столбца (столбцов) иметь «пустые» (NULL) ячейки.
Ограничение в виде требования уникальности тесно связано с понятием ключа таблицы. Ключом таблицы называется столбец или комбинация столбцов, содержимое ячеек которого(ых) используется для прямого доступа («быстрого» определения местоположения) к строкам таблицы. Различают ключи первичный (он может быть только единственным для каждой таблицы) и вторичные. Первичный ключ уникален и однозначно идентифицирует строку таблицы. Столбец строки, определенный в качестве первичного ключа, не может содержать «пустое» (NULL) значение в какой-либо своей ячейке. Вторичный ключ определяет местоположение, в общем случае, не одной строки таблицы, а нескольких «подобных» (в любом случае ускоряя доступ к ним, хотя не в такой степени как ключ первичный).
Ключи используются внутренними механизмами СУБД для оптимизации затрат на доступ к строкам таблиц (путем, например, их физического упорядочения по значениям ключей или построения двоичного дерева поиска).
Основными операциями над таблицами являются следующие.
-
Проекция - построение новой таблицы из исходной путем включения в нее избранных столбцов исходной таблицы. -
Ограничение - построение новой таблицы из исходной путем включения в нее тех строк исходной таблицы, которые отвечают некоторому критерию в виде логического условия (ограничения). -
Объединение - построение новой таблицы из 2-ух или более исходных путем включения в нее всех строк исходных таблиц (при условии, конечно, что они подобны). -
Декартово произведение - построение новой таблицы из 2-ух или более исходных путем включения в нее строк, образованных всеми возможными вариантами конкатенации (слияния) строк исходных таблиц. Количество строк новой таблицы определяется как произведение количеств строк всех исходных таблиц.
Перечисленные выше 4 операции создают базис, на основе которого может быть построено большинство (но не все) практически полезных запросов на извлечение информации из реляционной БД.
Кроме перечисленных выше в языке SQL реализованы операции модификации содержимого строк таблицы и пополнения таблицы новыми строками (что теоретически может рассматриваться как операция объединения), а также операции управления таблицами. Рассмотренные выше операции над таблицами реляционной БД обладая функциональной полнотой, будучи реализованы на практике в своем «чистом» каноническом виде, как правило, крайне неэкономичны (в первую очередь это относится к комбинации операций
ограничения и декартового произведения). Разработчики реальных реляционных СУБД прибегают ко всевозможным приемам и «ухищрениям» для минимизации вычислительных затрат (в первую очередь, машинного времени) при выполнении этих операций. Общим способом, нашедшим отражение в языке SQL, повышения эффективности выполнения запросов в реляционных СУБД являются использование ключей индексов.
Индексом называется скрытая от пользователя вспомогательная управляющая структура, обеспечивающая прямой (или «квази»-прямой) метод доступа к строкам таблицы, позволяющий исключить последовательный просмотр всех строк таблицы для обнаружения отвечающих некоторому критерию поиска. Индексы неявным образом (скрытно от пользователя) автоматически создаются для всех ключей таблицы.
В настоящее время наибольшее распространение получили реляционные SQL СУБД двух групп:
-
мощные крупные коммерческие СУБД, ориентированные на хранение огромных объемов информации (от гигабайт); -
мобильные компактные свободно распространяемые (в том числе и в исходных кодах) СУБД, использование которых оправдано и для БД объемом всего лишь в десятки килобайт.
Наиболее известными СУБД первой группы являются:
-
Sybase SQLServer фирмы Sybase, Inc.; -
Oracle фирмы Oracle Corporation; -
Ingres фирмы Computer Associates International; -
Informix фирмы Informix Corporation.
К наиболее популярным СУБД второй группы относятся:
-
PostgreSQL организации PostgreSQL; -
microSQL фирмы Hughes Technologies Pty. Ltd.; -
mySQL фирмы T.C.X DataKonsult AB.
Все перечисленные выше СУБД построены по принципу «клиент-сервер», как это показано на рисунке 1.
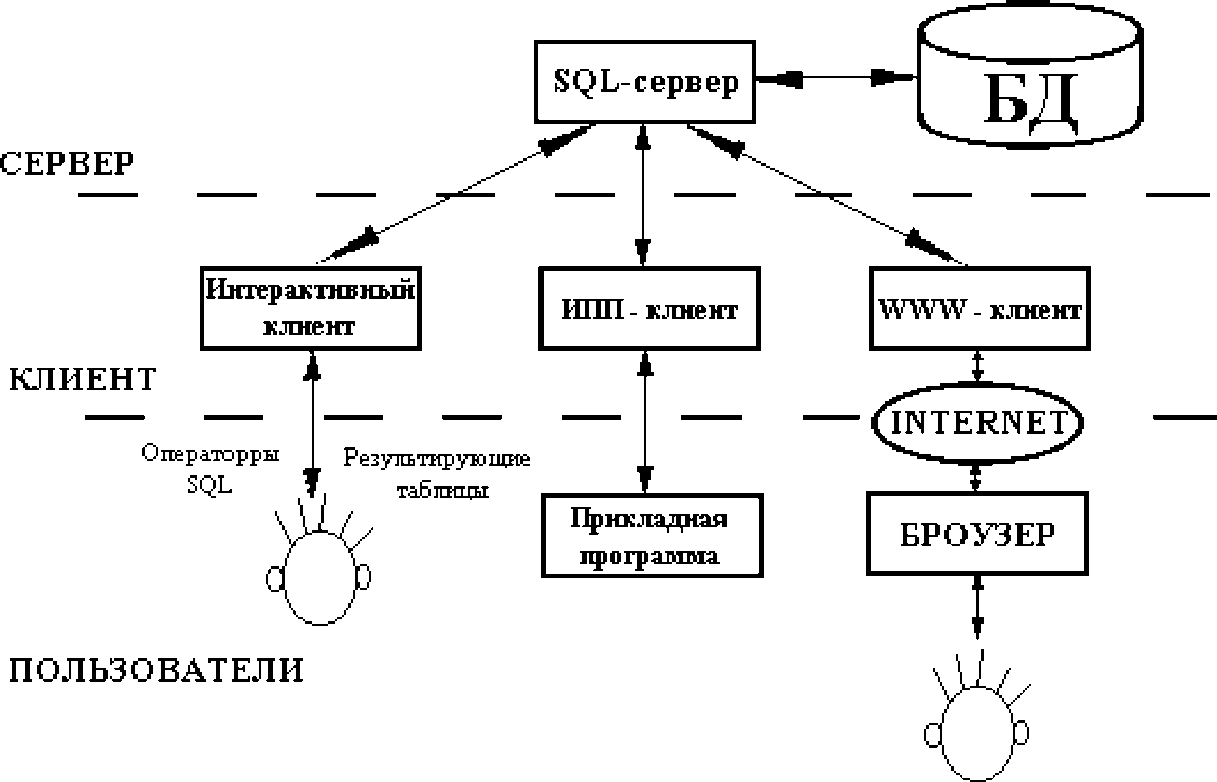
Рисунок 1 - Архитектура клиент-сервер
SQL-сервер реализует собственно хранение данных и манипулирование ими. Он принимает запросы на языке SQL от своих клиентов, выполняет их и возвращает результаты (чаще всего в виде вновь построенных таблиц) клиентам. Для общения с клиентами используется специальный протокол (как правило, реализованный в виде протокола прикладного уровня стека сетевых протоколов TCP/IP).
Клиентскую часть СУБД составляют клиенты трех основных типов.
-
Интерактивные клиенты, обеспечивающие пользователю-человеку возможность общения с SQL-сервером непосредственно с помощью языка SQL. -
ИПП-клиенты, обеспечивающие интерфейс прикладного программирования (ИПП) прикладным программам, использующим средства SQL-сервера. Такой ИПП может быть средством общения прикладной программы с SQL-сервером на языке SQL или набором стандартных функций доступа к реляционной SQL БД без формирования символьных строк запросов (например, стандартный интерфейс ODBC). -
WWW-клиенты, встраиваемые в World Wide Web-сервера и обеспечивающие доступ к информационным возможностям SQL-сервера пользователям сети Internet по протоколу HTTP (протоколу передачи гипертекстовых документов).
«Программа» на языке SQL представляет собой простую линейную последовательность операторов языка SQL. Язык SQL в своем «чистом» виде операторов управления порядком выполнения запросов к БД (типа циклов, ветвлений, переходов) не имеет. Операторы языка SQL строятся с применением:
-
зарезервированных ключевых слов; -
идентификаторов (имен) таблиц и столбцов таблиц; -
логических, арифметических и строковых выражений, используемых для формирования критериев поиска информации в БД и для вычисления значений ячеек результирующих таблиц; -
идентификаторов (имен) операций и функций, используемых в выражениях.
Все ключевые слова, имена функций и, как правило, имена таблиц и столбцов представляются 7-мибитными символами кодировки ASCII (иначе говоря - латинскими буквами).
В языке SQL не делается различия между прописными (большими) и строчными (маленькими) буквами, т.е., например, строки «SELECT», «Select», «select» представляют собой одно и то же ключевое слово.
Для конструирования имен таблиц и их столбцов допустимо использовать буквы, цифры и знак «_» (подчеркивание), но первым символом имени обязательно должна быть буква. Запрещено использование ключевых слов и имен функций в качестве идентификаторов таблиц и имен столбцов. Полный список ключевых слов и имен функций (а он весьма обширен) можно найти в документации на конкретную СУБД. Оператор начинается с ключевого слова-глагола (например, «CREATE» - создать, «UPDATE» - обновить, «SELECT» - выбрать и т.п.) и заканчивается знаком «;» (точка с запятой). Оператор записывается в свободном формате и может занимать несколько строк. Допустимыми разделителями лексических единиц в операторе являются:
-
один или несколько пробелов, -
один или несколько символов табуляции, -
один или несколько символов «новая строка».
При описании операторов языка SQL в учебном пособии используются следующие соглашения.
-
Прописными (большими) буквами (напрмер, SELECT, FROM, WHERE) набраны зарезервированные слова. -
Курсивом (например, имятабл, сложн __условие) набраны переменные (нетерминальные символы), подлежащие замене в реальном операторе конструкцией из терминальных символов (идентификаторов, знаков операций, имен функций и т.п.). -
В квадратные скобки («[...]») заключается необязательная часть оператора, которую можно опустить при создании реального оператора (сами квадратные скобки в текст оператора не включаются). -
Вертикальная черта («|») означает возможность выбора («или») из двух или нескольких вариантов синтаксической конструкции (сама вертикальная черта в текст оператора не включается). Подчеркнутый вариант (например, в «[ ALL | DISTINCT }») является умолчательным. -
Последовательность символов «, ...» обозначает возможность повторения произвольное количество раз (в том числе и нулевое) предшествующей запятой конструкции. Символ «,» включается в реальный оператор в качестве разделителя перед каждым повторением конструкции.