ВУЗ: Казахская Национальная Академия Искусств им. Т. Жургенова
Категория: Книга
Дисциплина: Не указана
Добавлен: 03.02.2019
Просмотров: 21721
Скачиваний: 19
7-56 Compression Technologies for Audio
7.3.4
Operational Details of the AC-3 Standard
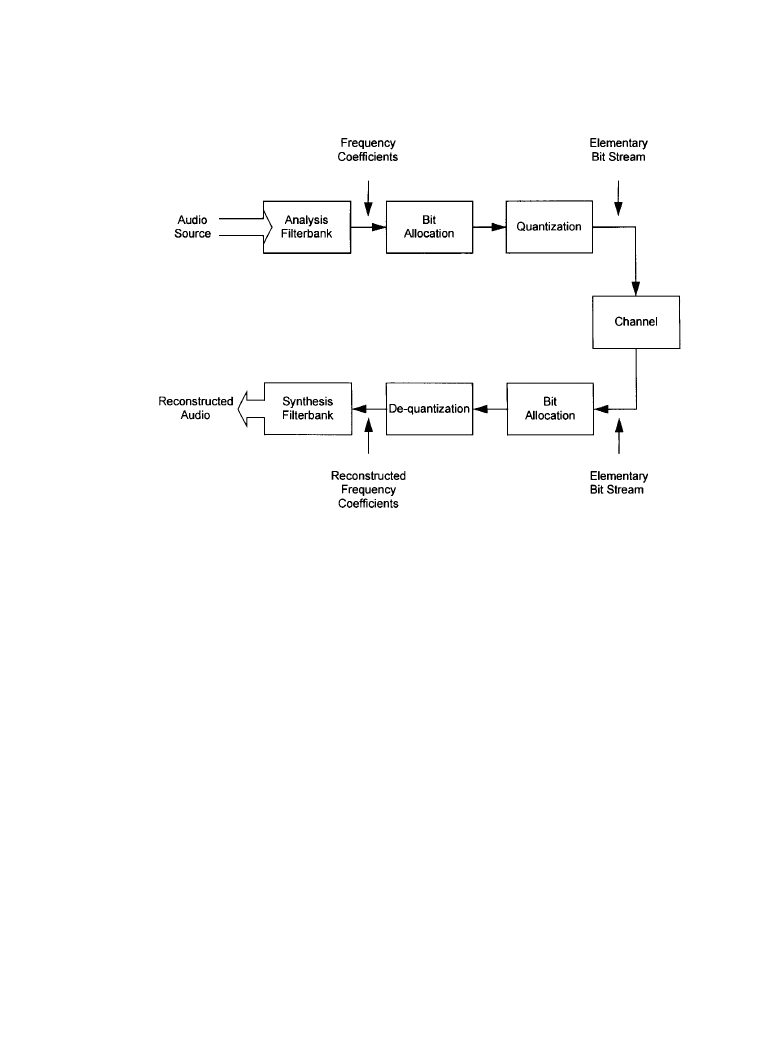
The AC-3 audio-compression system consists of three basic operations, as illustrated in Figure
7.3.6 [6]. In the first stage, the representation of the audio signal is changed from the time
domain to the frequency domain, which is a more efficient domain in which to perform psychoa-
coustically based audio compression. The resulting frequency-domain coefficients are then
encoded. The frequency-domain coefficients may be coarsely quantized because the resulting
quantizing noise will be at the same frequency as the audio signal, and relatively low S/N ratios
are acceptable because of the phenomenon of psychoacoustic masking. Based on a psychoacous-
tic model of human hearing, a bit-allocation operation determines the actual S/N acceptable for
each individual frequency coefficient. Finally, the frequency coefficients are coarsely quantized
to the necessary precision and formatted into the audio elementary stream.
The basic unit of encoded audio is the AC-3 sync frame, which represents 1536 audio sam-
ples. Each sync frame of audio is a completely independent encoded entity. The elementary bit
stream contains the information necessary to allow the audio decoder to perform the identical (to
the encoder) bit allocation. This permits the decoder to unpack and dequantize the elementary
bit-stream frequency coefficients, resulting in the reconstructed frequency coefficients. The syn-
thesis filterbank is the inverse of the analysis filterbank, and it converts the reconstructed fre-
quency coefficients back into a time-domain signal.
Figure 7.3.6
Overview of the AC-3 audio-compression system. (
From [6]. Used with permission.)
Downloaded from Digital Engineering Library @ McGraw-Hill (www.digitalengineeringlibrary.com)
Copyright © 2004 The McGraw-Hill Companies. All rights reserved.
Any use is subject to the Terms of Use as given at the website.
DTV Audio Encoding and Decoding

DTV Audio Encoding and Decoding 7-57
7.3.4a
Transform Filterbank
The process of converting the audio from the time domain to the frequency domain requires that
the audio be blocked into overlapping blocks of 512 samples [6]. For every 256 new audio sam-
ples, a 512-sample block is formed from the 256 new samples and the 256 previous samples.
Each audio sample is represented in two audio blocks, so the number of samples to be processed
initially is doubled. The overlapping of blocks is necessary to prevent audible blocking artifacts.
New audio blocks are formed every 5.33 ms. A group of six blocks is coded into one AC-3 sync
frame.
Window Function
Prior to being transformed into the frequency domain, the block of 512 time samples is win-
dowed [6]. The windowing operation involves a vector multiplication of the 512-point block with
a 512-point window function. The window function has a value of 1.0 in its center, tapering
down to almost zero at the ends. The shape of the window function is such that the overlap/add
processing at the decoder will result in a reconstruction free of blocking artifacts. The window
function shape also determines the shape of each individual filterbank filter.
Time-Division Aliasing Cancellation Transform
The analysis filterbank is based on the fast Fourier transform [6]. The particular transformation
employed is the oddly stacked time-domain aliasing cancellation (TDAC) transform. This par-
ticular transformation is advantageous because it allows removal of the 100 percent redundancy
that was introduced in the blocking process. The input to the TDAC transform is 512 windowed
time-domain points, and the output is 256 frequency-domain coefficients.
Transient Handling
When extreme time-domain transients exist (an impulse, such as a castanets click), there is a pos-
sibility that quantization error—incurred by coarsely quantizing the frequency coefficients of the
transient—will become audible as a result of time smearing [6]. The quantization error within a
coded audio block is reproduced throughout the block. It is possible for the portion of the quanti-
zation error that is reproduced prior to the impulse to be audible. Time smearing of quantization
noise may be reduced by altering the length of the transform that is performed. Instead of a sin-
gle 512-point transform, a pair of 256-point transforms may be performed—one on the first 256
windowed samples, and one on the last 256 windowed samples. A transient detector in the
encoder determines when to alter the transform length. The reduction in transform length pre-
vents quantization error from spreading more than a few milliseconds in time, which is adequate
to prevent audibility.
7.3.4b
Coded Audio Representation
The frequency coefficients that result from the transformation are converted to a binary floating
point notation [6]. The scaling of the transform is such that all values are smaller than 1.0. An
example value in binary notation (base 2) with 16-bit precision would be:
0.0000 0000 1010 11002
Downloaded from Digital Engineering Library @ McGraw-Hill (www.digitalengineeringlibrary.com)
Copyright © 2004 The McGraw-Hill Companies. All rights reserved.
Any use is subject to the Terms of Use as given at the website.
DTV Audio Encoding and Decoding

7-58 Compression Technologies for Audio
The number of leading zeros in the coefficient, 8 in this example, becomes the raw exponent.
The value is left-shifted by the exponent, and the value to the right of the decimal point (1010
1100) becomes the normalized mantissa to be coarsely quantized. The exponents and the
coarsely quantized mantissas are encoded into the bit stream.
Exponent Coding
A certain amount of processing is applied to the raw exponents to reduce the amount of data
required to encode them [6]. First, the raw exponents of the six blocks to be included in a single
AC-3 sync frame are examined for block-to-block differences. If the differences are small, a sin-
gle exponent set is generated that is usable by all six blocks, thus reducing the amount of data to
be encoded by a factor of 6. If the exponents undergo significant changes within the frame, expo-
nent sets are formed over blocks where the changes are not significant. Because of the frequency
response of the individual filters in the analysis filterbank, exponents for adjacent frequencies
rarely differ by more than
±2. To take advantage of this fact, exponents are encoded differentially
in frequency. The first exponent is encoded as an absolute, and the difference between the cur-
rent exponent and the following exponent then is encoded. This reduces the exponent data rate by
a factor of 2. Finally, where the spectrum is relatively flat, or an exponent set only covers 1 or 2
blocks, differential exponents may be shared across 2 or 4 frequency coefficients, for an addi-
tional savings of a factor of 2 or 4.
The final coding efficiency for AC-3 exponents is typically 0.39 bits/exponent (or 0.39 bits/
sample, because there is an exponent for each audio sample). Exponents are coded only up to the
frequency needed for the perception of full frequency response. Typically, the highest audio fre-
quency component in the signal that is audible is at a frequency lower than 20 kHz. In the case
that signal components above 15 kHz are inaudible, only the first 75 percent of the exponent val-
ues are encoded, reducing the exponent data rate to less than 0.3 bits/sample.
The exponent processing changes the exponent values from their original values. The encoder
generates a local representation of the exponents that is identical to the decoded representation
that will be used by the decoder. The decoded representation then is used to shift the original fre-
quency coefficients to generate the normalized mantissas that are subsequently quantized.
Mantissas
The frequency coefficients produced by the analysis filterbank have a useful precision that is
dependent upon the word length of the input PCM audio samples as well as the precision of the
transform computation [6]. Typically, this precision is on the order of 16 to18 bits, but may be as
high as 24 bits. Each normalized mantissa is quantized to a precision from 0 to16 bits. Because
the goal of audio compression is to maximize the audio quality at a given bit rate, an optimum
(or near-optimum) allocation of the available bits to the individual mantissas is required.
7.3.4c
Bit Allocation
The number of bits allocated to each individual mantissa value is determined by the bit-alloca-
tion routine [6]. The identical core routine is run in both the encoder and the decoder, so that
each generates an identical bit allocation.
The core bit-allocation algorithm is considered backward adaptive, in that some of the
encoded audio information within the bit stream (fed back into the encoder) is used to compute
Downloaded from Digital Engineering Library @ McGraw-Hill (www.digitalengineeringlibrary.com)
Copyright © 2004 The McGraw-Hill Companies. All rights reserved.
Any use is subject to the Terms of Use as given at the website.
DTV Audio Encoding and Decoding

DTV Audio Encoding and Decoding 7-59
the final bit allocation. The primary input to the core allocation routine is the decoded exponent
values, which give a general picture of the signal spectrum. From this version of the signal spec-
trum, a masking curve is calculated. The calculation of the masking model is based on a model of
the human auditory system. The masking curve indicates, as a function of frequency, the level of
quantizing error that may be tolerated. Subtraction (in the log power domain) of the masking
curve from the signal spectrum yields the required S/N as a function of frequency. The required
S/N values are mapped into a set of bit-allocation pointers (BAPs) that indicate which quantizer
to apply to each mantissa.
Forward Adaptive
The AC-3 encoder may employ a more sophisticated psychoacoustic model than that used by the
decoder [6]. The core allocation routine used by both the encoder and the decoder makes use of a
number of adjustable parameters. If the encoder employs a more sophisticated psychoacoustic
model than that of the core routine, the encoder may adjust these parameters so that the core rou-
tine produces a better result. The parameters are subsequently inserted into the bit stream by the
encoder and fed forward to the decoder.
In the event that the available bit-allocation parameters do not allow the ideal allocation to be
generated, the encoder can insert explicit codes into the bit stream to alter the computed masking
curve, hence the final bit allocation. The inserted codes indicate changes to the base allocation
and are referred to as delta bit-allocation codes.
7.3.4d
Rematrixing
When the AC-3 encoder is operating in a 2-channel stereo mode, an additional processing step is
inserted to enhance interoperability with Dolby Surround 4-2-4 matrix encoded programs [6].
This extra step is referred to as rematrixing.
The signal spectrum is broken into four distinct rematrixing frequency bands. Within each
band, the energy of the left, right, sum, and difference signals are determined. If the largest signal
energy is in the left and right channels, the band is encoded normally. If the dominant signal
energy is in the sum and difference channels, then those channels are encoded instead of the left
and right channels. The decision as to whether to encode left and right or sum and difference is
made on a band-by-band basis and is signaled to the decoder in the encoded bit stream.
7.3.4e
Coupling
In the event that the number of bits required to transparently encode the audio signals exceeds
the number of bits that are available, the encoder may invoke coupling [6]. Coupling involves
combining the high-frequency content of individual channels and sending the individual channel
signal envelopes along with the combined coupling channel. The psychoacoustic basis for cou-
pling is that within narrow frequency bands, the human ear detects high-frequency localization
based on the signal envelope rather than on the detailed signal waveform.
The frequency above which coupling is invoked, and the channels that participate in the pro-
cess, are determined by the AC-3 encoder. The encoder also determines the frequency banding
structure used by the coupling process. For each coupled channel and each coupling band, the
encoder creates a sequence of coupling coordinates. The coupling coordinates for a particular
channel indicate what fraction of the common coupling channel should be reproduced out of that
Downloaded from Digital Engineering Library @ McGraw-Hill (www.digitalengineeringlibrary.com)
Copyright © 2004 The McGraw-Hill Companies. All rights reserved.
Any use is subject to the Terms of Use as given at the website.
DTV Audio Encoding and Decoding
7-60 Compression Technologies for Audio
particular channel output. The coupling coordinates represent the individual signal envelopes for
the channels. The encoder determines the frequency with which coupling coordinates are trans-
mitted. If the signal envelope is steady, the coupling coordinates do not need to be sent every
block, but can be reused by the decoder until new coordinates are sent. The encoder determines
how often to send new coordinates, and it can send them as often as each block (every 5.3 ms).
7.3.4f
Bit Stream Elements and Syntax
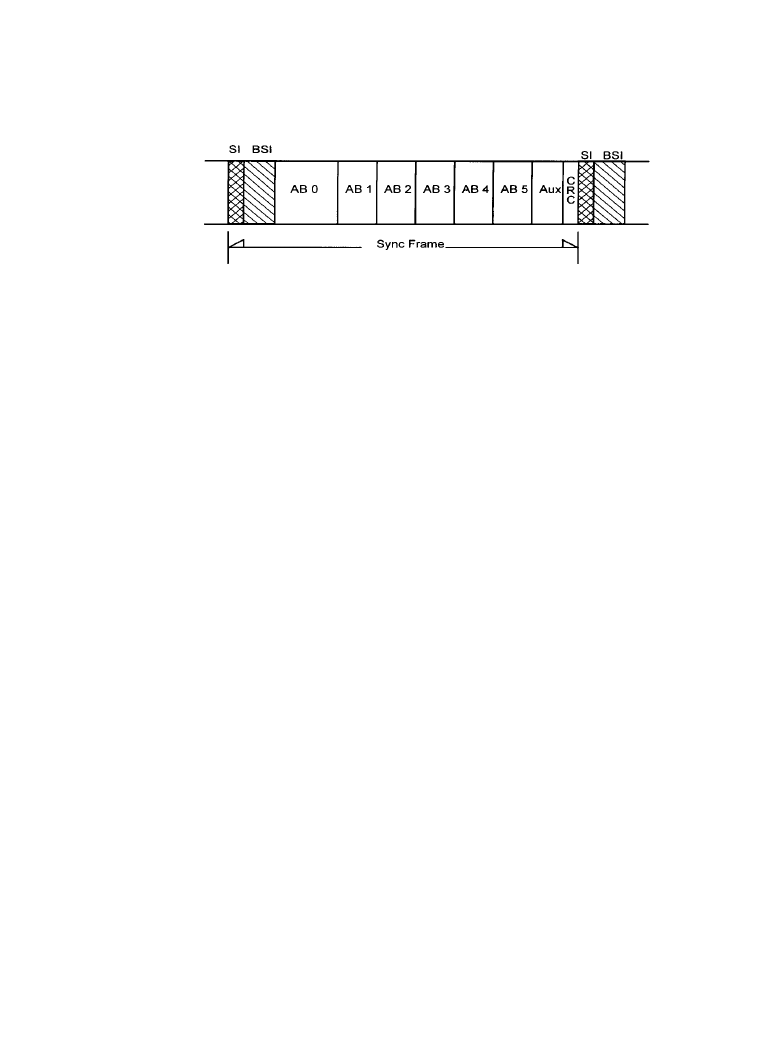
An AC-3 serial-coded audio bit stream is made up of a sequence of synchronization frames, as
illustrated in Figure 7.3.7 [6]. Each synchronization frame contains six coded audio blocks, each
of which represent 256 new audio samples. A synchronization information (SI) header at the
beginning of each frame contains information needed to acquire and maintain synchronization.
A bit-stream information (BSI) header follows each SI, containing parameters describing the
coded audio service. The coded audio blocks may be followed by an auxiliary data (Aux) field.
At the end of each frame is an error-check field that includes a CRC word for error detection. An
additional CRC word, the use of which is optional, is located in the SI header.
A number of bit-stream elements have values that may be transmitted, but whose meaning has
been reserved. If a decoder receives a bit stream that contains reserved values, the decoder may
or may not be able to decode and produce audio.
Splicing and Insertion
The ideal place to splice encoded audio bit streams is at the boundary of a sync frame [6]. If a bit
stream splice is performed at the boundary of the sync frame, the audio decoding will proceed
without interruption. If a bit stream splice is performed randomly, there will be an audio inter-
ruption. The frame that is incomplete will not pass the decoder’s error-detection test, and this
will cause the decoder to mute. The decoder will not find sync in its proper place in the next
frame, and it will enter a sync search mode. After the sync code of the new bit stream is found,
synchronization will be achieved, and audio reproduction will resume. This type of outage will
be on the order of two frames, or about 64 ms. Because of the windowing process of the filter-
bank, when the audio goes to mute, there will be a gentle fadedown over a period of 2.6 ms.
When the audio is recovered, it will fade up over a period of 2.6 ms. Except for the approxi-
mately 64 ms of time during which the audio is muted, the effect of a random splice of an AC-3
elementary stream is relatively benign.
Figure 7.3.7
The AC-3 synchronization frame. (
From [6]. Used with permission.)
Downloaded from Digital Engineering Library @ McGraw-Hill (www.digitalengineeringlibrary.com)
Copyright © 2004 The McGraw-Hill Companies. All rights reserved.
Any use is subject to the Terms of Use as given at the website.
DTV Audio Encoding and Decoding