Файл: Лабораторная работа 8 по дисциплине Теория информации, данные, знания Исследование методов классификации данных с помощью нейронной сети.docx
ВУЗ: Не указан
Категория: Не указан
Дисциплина: Не указана
Добавлен: 03.12.2023
Просмотров: 101
Скачиваний: 3
ВНИМАНИЕ! Если данный файл нарушает Ваши авторские права, то обязательно сообщите нам.
Лабораторная работа №8
по дисциплине «Теория информации, данные, знания»
«Исследование методов классификации данных с помощью нейронной сети»
Цель работы – исследование принципов разработки нейронной сети на примере задачи классификации данных в PyTorch.
Классификация — понятие в науке, обозначающее разновидность деления объёма понятия по определённому основанию (признаку, критерию), при котором объём родового понятия (класс, множество) делится на виды (подклассы, подмножества), а виды, в свою очередь делятся на подвиды и т.д.
Общие положения
Текст программы представлен ниже.
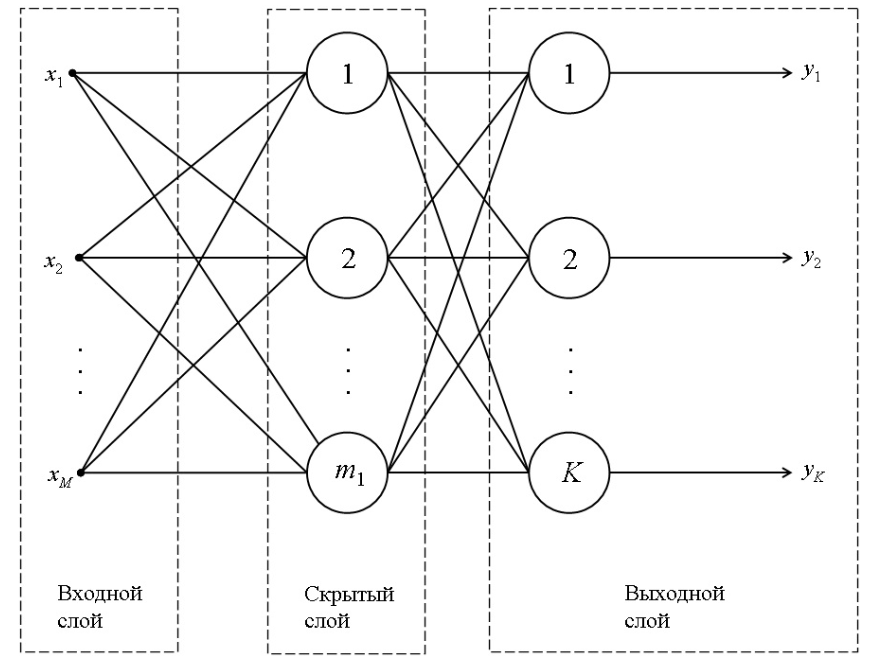
Общая структура полносвязной нейронной сети представлена на рисунке.
Для примера используем датасет классификации вин. Известный датасет имеется в библиотеке scikit.learn. Мы можем его загрузить через sklearn.datasets.load_wine(). Этот датасет будет содержать 178 различных бутылок вин, у каждой бутылки измерено 13 параметров, это вещественные числа. Конкретную бутылку можно будет классифицировать на три класса.
Если взять один и тот же код и запустить его несколько раз, то получим разные результаты. Это происходит потому, что каждый раз веса нейронной сети инициализируются заново, происходит по-разному обучение нейронной сети, и это всё зависит от того, как отработал генератор случайных чисел в нашем процессоре.
Возможно, мы хотим, чтобы эксперименты были воспроизводимы: чтобы, взяв один и тот же питоновский файл и выполнив его, мы получили бы тот же самый результат, как и раньше. Например, это нужно для того чтобы понимать: а правда ли те изменения, которые мы делаем с нейросетью, улучшают наши результаты, или это результат некоторой случайности. Зафиксируем эту случайность. Есть такое понятие как random seed, это можно интерпретировать, как номер последовательности случайных чисел, которую выдаст нам случайный генератор, если его попросить выдать нам последовательность. Случайных генераторов есть несколько: есть случайный генератор модуля random в Питоне, есть случайный генератор модуля numpy.random (библиотеки numpy), есть также случайные генераторы библиотеки PyTorch и другие.
Зафиксируем их все. Для этого возьмём random seed и поставим его в конкретное значение. Таким образом, мы всегда будем использовать нулевую последовательность при вызове случайного генератора библиотеки random (это библиотека языка python).
Также нам нужно зафиксировать сиды в numpy и в PyTorch, случайные сиды, которые отвечают за обсчёт и CPU и на GPU – они разные, соответственно нужно ещё зафиксировать случайный seed подмодуля CUDA.
Скорее всего, если вы рассчитываете на видеокарте, вы используете библиотеку cudnn, и она может выполняться в детерминистичном режиме, а может в недетерминистичном. Недетерминистичный режим гораздо быстрее, но если мы действительно, в угоду скорости, хотим детерминистичность, хотим, чтобы была воспроизводимость, то нам нужно выставить этот параметр в "True".
Выставив все эти параметры, мы можем практически гарантировать то, что у нас эксперименты будут воспроизводимы.
Теперь нужно этот датасет разбить на две части: на трейновую часть, на которой мы будем обучаться, и на тестовую, на которой мы будем считать метрики. Воспользуемся функцией train_test_split из той же библиотеки scikit_learn. Если мы передадим в функцию train_test_split первым параметром, собственно dataset (тут мы используем только первые две колонки, колонок 13, столько же, сколько у нас параметров вина, мы используем всего две для удобства последующей визуализации), вторым параметром мы передадим таргеты, то есть те классы, которые нам нужно предсказать – это будет номер класса (такая колонка).
Отведем 30 процентов на тест, и перед тем, как этот датасет делить на две части, нужно его перемешать, чтобы удостовериться, что если он был отсортирован, например, по номеру класса, то теперь эта сортировка не работает.
После этого мы все "фолды": X_train, X_test, Y_train и Y_test обернём в torch тензоры: дробные числа, мы обернём в float тензор, если числа не дробные, обернём в long тензор.
Далее реализуем класс, назовём его WineNet, это будет нейросеть для классификации. Точно так же, как нейросеть для синуса, которая была работе №1, отнаследуем класс от torch.nn.Module, в функции __init__ (в конструкторе этого класса) будет аргумент – количество скрытых нейронов n_hidden_neurons.
Реализуем здесь два скрытых слоя, нейросеть будет состоять всего из трёх слоёв, и два из них будут скрыты. Первый слой – это fully connected (полносвязный) слой, из двух входов (у нас две колонки для каждой бутылки вина), на выходе N скрытых нейронов, дальше активация: сигмоида, можно поставить любую другую, если хотите. После этого – скрытый слой, который из N нейронов, превращает их тоже в N нейронов. Снова сигмоидная активация. После этого снова fully connected слой, который выдаёт нам три нейрона, каждый нейрон будет отвечать за свой класс.
Таким образом, на выходе этих трёх нейронов будут некоторые числа, которые после этого мы передадим в софтмакс, и получим вероятности классов. Напишем функцию "forward" – она будет реализовывать граф нашей нейронной сети. Передаём двухмерный тензор с двумя колонками в первый fully connected слой, после этого в первую активацию, во второй fully connected слой, во вторую активацию, в третий fully connected слой, у которого три выхода.
Заметьте, здесь не используется softmax. Почему мы не прогнали выход из третьего слоя через softmax? Дело в том, что после того, как мы посчитаем выходы нейронной сети, мы хотим прогнать их через softmax и посчитать кросс-энтропию. Но в формуле кросс-энтропии есть логарифм, то есть выходы нейронной сети прогоняются через логарифм. А в формуле softmax участвуют экспоненты. Эти экспоненты и логарифмы взаимно уничтожаются, и получается, что нам не нужно вычислять экспоненты, чтобы посчитать кросс-энтропию. Мы можем её посчитать, не считая softmax. Соответственно, если мы хотим просто считать ошибку (лосс), нам softmax не нужен. Если мы хотим посчитать вероятности, то нам придётся использовать softmax.
Softmax – функция довольно долгого вычисления, поэтому мы стараемся её избегать. Для того, чтобы считать вероятности, напишем функцию inference, которая будет вызывать функцию "forward", и прогонять её через softmax.
Инициализируем нашу нейронную сеть с количеством скрытых нейронов, равным пяти. Нейросеть имеет имя wine_net. Осталось только инициировать функцию потерь –бинарную кросс-энтропию (torch.nn.CrossEntropyLoss), которая использует не выходы после софтмакса, а выходы нейронной сети, не пропущенные ещё через софтмакс.
Далее задается оптимайзер – тот метод, который будет использоваться для вычисления градиентных шагов. В оптимайзер мы передаём все параметры нейронной сети – ее веса. Это те скрытые значения, которые находятся в нейронах, которые мы хотим подбирать. Learning rate выбираем 0.001 (как правило, стандартное значение по умолчанию).
Усложним обучение нейронной сети. Ранее мы брали весь датасет, считали по нему loss-функцию, дальше делали градиентный шаг, и повторяли этот процесс многократно. Но в реальной жизни вряд ли поместится в памяти весь датасет. Обучение в реальной сети происходит по частям данных – они называются батчи (batch).
Мы должны «отрезать» некоторый кусочек данных, посчитать по нему loss, посчитать по нему градиентный шаг, сделать градиентный шаг, взять следующий кусочек, и так далее, повторять этот процесс. Соответственно, одна эпоха, то есть итерация просмотра всего датасета, бьётся на много маленьких частей.
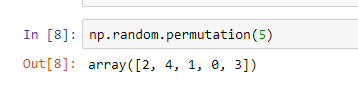
Эту разбивку осуществим следующим образом. Нам понадобится функция numpy.random.permutation. Что делает эта функция? Если мы вызовем её с аргументом "5", она даст нам numpy.array размером "5", с числами от 0 до 4 включительно, случайно перемешанными (см. пример). Если в нее подставить размер нашего трейнового датасета, получим некоторые индексы в случайном порядке.
Если от датасета взять эти индексы, то мы получим "пошафленный", перемешанный датасет. Таким образом, каждую эпоху мы будем «шаффлить» датасет, и потом резать его на части.
Пусть эти части будут размером десять элементов. Можно взять любое другое значение. Итак, каждую эпоху мы будем перемешивать датасет, у нас есть переменная "order", которая определяется каждую эпоху, задает порядок индексов, применяемый к датасету.
Итак, будем вырезать участки длиной batch_size. Каждую эпоху будем делать перемешивание датасета, определять переменную order, которая отвечает за порядок элементов. После этого будем вычислять некоторое подмножество, начиная со start_index, который будет 0, 10, 20 и так далее, до конца батча. Batch_indexes – это некоторые индексы, которые соответствуют текущему батчу.
Таким образом, каждую эпоху гарантированно проходим все значения в датасете, при этом каждая итерация обучения происходит по десяти элементам.
Каждые 100 эпох будем вычислять метрики на тестовом датасете чтобы посмотреть, обучается у нас нейросеть или нет. Таким образом, каждые 100 эпох мы делаем forward по тестовым данным, получаем тестовые prediction и вычисляем, какой выход был максимальный. На самом деле, чтобы понять, какой класс предсказывает нейросеть, не обязательно вычислять софтмакс, не обязательно вычислять вероятности. Достаточно посмотреть, какой выход был наибольший, и он же будет впоследствии выходом с максимальной вероятностью.
Необходимо посчитать argmax у выходов нейронной сети, это будет номер нейрона, затем сравнить его с тем номером класса, который находится в Y_test. После этого можно посчитать, какова доля этого совпадения, когда нейрон с максимальным выходом совпал с реально правильным классом. Следует посчитать среднее значение, но среднее значение нельзя посчитать у целочисленного тензора, который получается в результате этого сравнения, поэтому сначала надо преобразовать его к дробному тензору и вызвать метод mean().
Запустим обучение и посмотрим, что получится. Проходит по 100 эпох, получаем некоторое новое значение accuracy. Обычно оно растёт, правда иногда осциллирует в некоторых значениях и дальше увеличивается. Не обязательно ждать, пока обучение закончится, можно в любой момент его остановить вручную, если видно, что нейросеть уже сошлась и значения не изменяются.
Сделаем kernel interrupt и остановимся на accuracy где-то 0.85. Попробуем визуализировать результат. На графике точками обозначен трейновый датасет, то есть те точки, на которых обучалась нейронная сеть, а заполненными областями – то, как нейросеть классифицировала точки в соответствующих значениях. Видно, что нейросеть довольно неплохо справляется с тем, чтобы отделять точки разных классов.
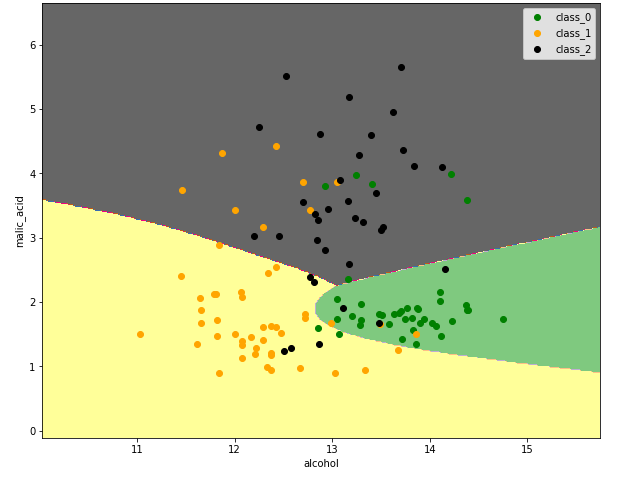
Если изменить архитектуру нейронной сети, можно попытаться улучшить результаты классификации. Например, можно изменить число нейронов в скрытых слоях, само количество скрытых слоёв, метод градиентного спуска, Learning rate, функции активации.
Например, изменим количество скрытых слоёв на один. Закомментируем слой.
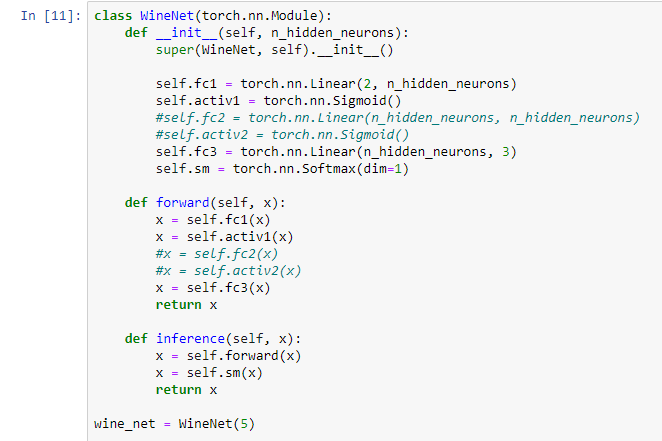
Увидим, что обучение пошло быстрее, потому что у нас меньше вычислений, меньше слоёв, и довольно быстро нейронная сеть выходит на те же значения.