Файл: Лабораторная работа по дисциплине Введение в профессию Решение задачи регрессии с помощью нейронной сети.docx
ВУЗ: Не указан
Категория: Не указан
Дисциплина: Не указана
Добавлен: 05.12.2023
Просмотров: 65
Скачиваний: 2
ВНИМАНИЕ! Если данный файл нарушает Ваши авторские права, то обязательно сообщите нам.
Лабораторная работа
по дисциплине «Введение в профессию»
«Решение задачи регрессии с помощью нейронной сети»
Цель работы – исследование принципов разработки нейронной сети на примере задачи регрессии.
Регрессия – это односторонняя стохастическая зависимость, устанавливающая соответствие между случайными переменными, то есть математическое выражение, отражающее связь между зависимой переменной у и независимыми переменными х при условии, что это выражение будет иметь статистическую значимость.
Фактически, задача регрессии – это предсказание некоторого вещественного числа.
Для решения модельной задачи используем нейронную сеть c одним полносвязным скрытым слоем, представленную на рисунке.
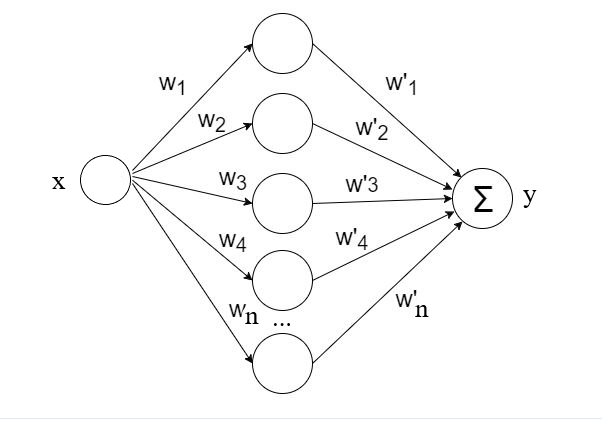
Прежде чем рассматривать процесс обучения нейронной сети, мы рассмотрим понятие размеченной обучающей выборки.
Размеченная обучающая выборка состоит из какого-то количества объектов, для которых мы знаем две вещи: во-первых, это некоторые признаки x1 … xN. Для каждого объекта мы знаем некоторый набор признаков. Кроме того, мы знаем некоторую метку объекта у1 … уN.
Мы можем на этом обучить некоторую нейронную сеть. Но, прежде чем обучать нейронную сеть, мы разделим эту выборку на три части: тренировочный датасет, валидационный датасет и тестовый датасет.
Тренировочный датасет – это то, что мы непосредственно используем для обучения нашей модели. Валидационный датасет нужен для того, чтобы подстраивать параметры обучения нашей модели (гиперпараметры). На самом деле его никогда не используют в процессе обучения, но мы подгоняем некоторые параметры, чтобы на этом датасете результаты были лучше. Тестовый датасет – это датасет, на котором мы будем проверять окончательный результат. Если у нас получится хороший результат на тестовом датасете, это означает, что наша модель обобщила информацию, которая ей была предоставлена.
Выполнение лабораторной работы можно производить в среде Google Colaboratory:
https://colab.research.google.com/notebooks/welcome.ipynb.
Если вы хотите установить PyTorch на локальном компьютере, то можно установить дистрибутив Anaconda: https://www.anaconda.com/distribution/ с Python последней версии.
Общие положения
Рассмотрим следующую учебную задачу: предсказать функцию sin (x).
Текст программы представлен ниже.
-
Импортируем torch и matplotlib, чтобы рисовать графики.
2. Нужно составить "train dataset". Возьмём точки из равномерного распределения от нуля до единицы, 100 штук, каждую точку домножим на 20, отнимем от неё 10, чтобы график примерно был по центру – это будут наши значения "x". А "y" – это будут синусы от данных точек.
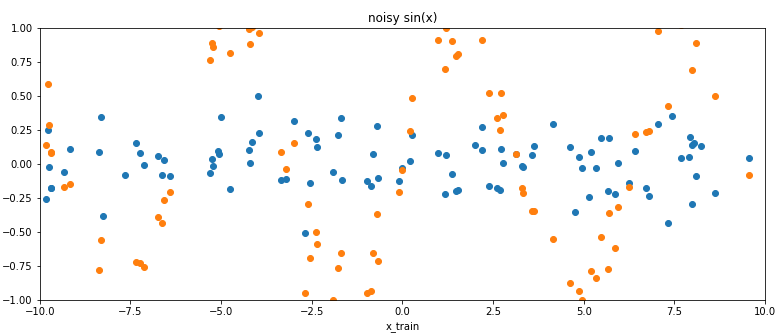
3. Добавим в обучающую выборку немного шума. Шум будет из нормального распределения. Этот шум прибавим к каждой точке предыдущего. Получится обучающая выборка.
4. Когда мы будем передавать в нейросеть данные, нам хочется, чтобы они были правильной размерности. Ведь, по сути, признаком объекта может быть не одно число, как здесь (координата "x", по которой мы хотим предсказать координату "y"), а может быть сразу несколько чисел. Соответственно, для общности, нам нужно наш вектор x (который сейчас строчка), превратить в столбец, у которого в каждой строчке будет одно число x. Это делает метод unsqueeze(). Если вы в PyTorch видите нижнее подчёркивание в названии метода, это значит, что этот метод трансформирует тот объект, к которому он применяется, то есть после выполнения этой ячейки у нас x_train и y_train изменились, и теперь это столбцы.
5. Кроме train dataset нам нужен будет отдельный validation dataset, мы делим наш dataset на тренировочные данные, и те, на которых мы будем тестировать или валидироваться. Сеть обучается на тренировочных данных и, соответственно, валидируется на тех данных которые она не видела.
Мы знаем, что тот закон природы, который сгенерировал наши данные – это функция синуса. Поэтому мы возьмём в валидационный датасет просто функцию синуса, не будем добавлять к ней никакого шума. Конечно это не очень жизненно, потому что у вас никогда такого не будет, что ваши данные будут не зашумлены, там всегда будет некоторый шум. Но в данном примере мы возьмём как валидацию обычный синус.
Создадим две переменные "x_validation" и "y_validation". Посмотрим, как выглядит график этой функции. Это обычный синус на точках, которые распределены равномерно от минус десяти до десяти. Мы будем их передавать в нейронную сеть, соответственно, они должны быть правильной размерности – это должен быть двумерный тензор, где каждая строчка соответствует одному элементу, одной точке. Делаем x_validation unsqueeze(1) и y_validation unsqueeze(1).
6. Теперь можно создать нейронную сеть. Чтобы создать нейронную сеть, нужно создать класс, назовём его SineNet, предполагая, что это будет нейросеть, которая решает задачу восстановления синуса. Её мы должны отнаследовать от класса torch.nn.Module. Такое наследование внесет в наш объект дополнительные функции, которые мы будем использовать. Кроме того, нужно проинициализировать те слои, которые будут использоваться в сети, с помощью функции "__init__", она на вход может принимать что угодно, любые параметры, которые нам будет интересно передать в эту сеть в момент конструирования. Например, интересно передать количество скрытых нейронов, которые будут храниться в каждом слое, то есть мы предполагаем, что все слои будут одинакового размера. Там будет n_hidden neurons.
Теперь инициируем родительский объект. Создадим слои: первый слой, который будет называться fc1, это "fully connected" слой, полносвязный слой. В PyTorch "fully connected" слой называется "linear". Мы передаём количество входных нейронов и количество выходных нейронов. Входных нейронов будет ровно один. То есть это просто вход в нейрон. Это одно число "x", координата нашей точки, по которой мы будем что-то предсказывать. Выходных нейронов будет ровно "n_hidden_neurons
".
7. После этого нужна функция активации. Кстати, попробуйте убрать функцию активации, узнайте, что получится. В качестве функции активации берем сигмоиду. В принципе, нам бы подошла любая функция активации. Но сигмоида – самая простая. Кроме того, мы добавим ещё один полносвязный слой, но у него будет всего один нейрон. Этот нейрон будет выходным - нашим ответом на вопрос о регрессии. Так как у нас задача регрессии, нас интересует ответ, который является одним числом, следовательно, на выходе нашей сети должен быть один нейрон. В итоге, наша нейросеть будет выглядеть, как два слоя, в одном из них будет несколько нейронов, а во втором будет один.
Теперь нам нужно написать функцию forward, описывающую как наши слои последовательно применяются. Сначала мы применяем слой "fc1" на "x". То, что получилось мы передаём в функцию активации, то что вышло из функций активации мы передаём в "fc2". В принципе, функция forward повторяет инициализацию.
Создадим такую сеть. Количество скрытых нейронов – 50, чтобы точно хватило. У нас теперь есть "SineNet" – объект, который можно обучать предсказанию.
8. Давайте не будем ничего обучать, а сразу предскажем. А вдруг уже сразу заработает? Напишем некоторую функцию "predict", внутри она будет очень простая – там будет вызов метода "forward". И если вы передадите туда некоторую переменную x, на выходе у вас будет некоторый prediction (одно искомое число). Далее есть некоторый код, который рисует этот prediction. Давайте посмотрим, что происходит. Представлено два графика, синим обозначен groud truth, (то, что мы бы хотели на валидации увидеть), x – это то, что мы передаём в сеть, а y – это то что мы бы хотели, чтобы сеть вернула, а красными точками обозначено то, что сеть нам предсказала.
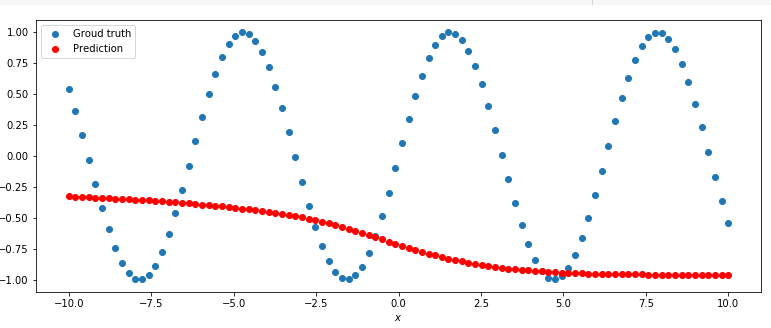
Нетрудно догадаться, что, так как у нас сеть была инициирована случайными числами (когда вы задаёте слои, они инициализируются некоторыми случайными числами), то на выходе у нас получилась некоторая случайная кривая (она может быть разная в зависимости от запуска).
9. Давайте обучим эту нейросеть. Чтобы обучить нейросеть, нам нужно несколько вещей дополнительно. Во-первых, нам нужен некоторый оптимизатор – некоторый объект, который будет совершать для нас шаги градиентного спуска. Используем
torch.optim.adam. Вы можете попробовать что-то другое. Метод ADAM – adaptive moment estimation – оптимизационный алгоритм. Он сочетает в себе идею накопления движения и идею более слабого обновления весов для типичных признаков (наиболее известен SGD – обычный градиентный спуск, но в данной задаче он работает не очень хорошо, собственно, поэтому используем другие градиентные спуски).
Очень важно, что на вход Adam передаются те параметры, которые мы хотим модифицировать – параметры, которые мы хотим обучать в нейронной сети. Можно было подумать, что это "x", но это не так, потому что "x" – это наши точки, мы не можем на них никак повлиять. Зато мы можем повлиять на веса нейронной сети – те веса, которые хранятся в нейронах (они находятся в sine_net.parameters). Это одна из тех причин, почему нейросеть мы наследовали, а не создавали как класс с нуля. Соответственно, если мы передадим в Adam такой объект, то ADAM поймёт, что здесь лежат все те переменные, которые он может модифицировать вследствие градиентного спуска. Также необходимо передать "learning rate" – шаг градиентного спуска. Здесь взято значение 0.01, можно также попробовать другие значения.
10. Создадим такой оптимизатор. Также нам нужна функция потерь – та функция, которая говорит, насколько неправильно мы предсказали, насколько мы ошиблись. Это та функция, по которой будет происходить вычисление градиента, и которая будет участвовать в градиентном спуске – функция loss function. В данной работе используется MSE (mean squared error).
11. Начнем тренировку. Если мы возьмём весь наш датасет, прогоним его через нейросеть, получим некоторые предсказания. После этого, на этих предсказаниях посчитаем функцию потерь, которую мы задали. После этого у функции потерь посчитаем производную и сделаем градиентный шаг. Это будет называться эпохой. Таким образом, мы посмотрели на все наши данные и сделали градиентный шаг.
Возможно нам потребуется много эпох. Тут взято две тысячи, чтобы точно хватало. Что мы делаем внутри одной итерации, внутри одной эпохи? Сначала мы обнуляем градиенты. Можно было обнулять градиенты в конце, но, чтобы не забыть, лучше сразу делать это вначале.