Файл: Основы сетей передачи данных Лекция #1 Эволюция вычислительных сетей. Часть 1.doc
ВУЗ: Не указан
Категория: Не указан
Дисциплина: Не указана
Добавлен: 10.01.2024
Просмотров: 532
Скачиваний: 2
ВНИМАНИЕ! Если данный файл нарушает Ваши авторские права, то обязательно сообщите нам.
К адресу сетевого интерфейса и схеме его назначения можно предъявить несколько требований:
-
адрес должен уникально идентифицировать сетевой интерфейс в сети любого масштаба; -
схема назначения адресов должна сводить к минимуму ручной труд администратора и вероятность дублирования адресов; -
желательно, чтобы адрес имел иерархическую структуру, удобную для построения больших сетей; -
адрес должен быть удобен для пользователей сети, а это значит, что он должен допускать символьное представление, например Server3 или www.cisco.com; -
адрес должен быть по возможности компактным, чтобы не перегружать память коммуникационной аппаратуры – сетевых адаптеров, маршрутизаторов и т.п.
Нетрудно заметить, что эти требования противоречивы — например, адрес, имеющий иерархическую структуру, скорее всего, будет менее компактным, чем плоский. Символьные имена удобны, но из-за переменного формата и потенциально большой длины их передача по сети не очень экономична. Так как все перечисленные требования трудно совместить в рамках какой-либо одной схемы адресации, на практике обычно используется сразу несколько схем, так что сетевой интерфейс компьютера может одновременно иметь несколько адресов-имен. Каждый адрес используется в той ситуации, когда соответствующий вид адресации наиболее удобен. А для преобразования адресов из одного вида в другой используются специальные вспомогательные протоколы, которые называют иногда протоколами разрешения адресов (address resolution).
Примером плоского числового адреса является МАС-адрес, используемый для однозначной идентификации сетевых интерфейсов в локальных сетях. Такой адрес обычно применяется только аппаратурой, поэтому его стараются сделать по возможности компактным и записывают в виде двоичного или шестнадцатеричного значения, например 0081005e24a8. Когда задаются МАС-адреса, вручную ничего делать не нужно, так как они обычно встраиваются в аппаратуру компанией-изготовителем; их называют еще аппаратными (hardware) адресами. Использование плоских адресов является жестким решением — при замене аппаратуры, например сетевого адаптера, изменяется и адрес сетевого интерфейса компьютера.
Типичными представителями иерархических числовых адресов являются сетевые IP- и IPX-адреса. В них поддерживается двухуровневая иерархия, адрес делится на старшую часть — номер сети — и младшую — номер узла. Такое разделение позволяет передавать сообщения между сетями только на основании номера сети, а номер узла используется после доставки сообщения в нужную сеть; точно так же, как название улицы используется почтальоном только после того, как письмо доставлено в нужный город. В последнее время, чтобы сделать маршрутизацию в крупных сетях более эффективной, предлагаются более сложные варианты числовой адресации, в соответствии с которыми адрес имеет три и более составляющих. Такой подход, в частности, реализован в новой версии протокола IPv6, предназначенного для работы в Internet.
Символьные адреса или имена предназначены для запоминания людьми и поэтому обычно несут смысловую нагрузку. Символьные адреса можно использовать как в небольших, так и в крупных сетях. Для работы в больших сетях символьное имя может иметь иерархическую структуру, например ftp-arch1.ucl.ac.uk. Этот адрес говорит о том, что данный компьютер поддерживает FTP-архив в сети одного из колледжей Лондонского университета (University College London — ucl), и данная сеть относится к академической ветви (ac) Internet Великобритании (United Kingdom — uk). При работе в пределах сети Лондонского университета такое длинное символьное имя явно избыточно и вместо него можно пользоваться кратким символьным именем, на роль которого хорошо подходит самая младшая составляющая полного имени, то есть ftp-arch1.
В современных сетях для адресации узлов, как правило, применяются все три приведенные выше схемы одновременно. Пользователи адресуют компьютеры символьными именами, которые автоматически заменяются в сообщениях, передаваемых по сети, на числовые номера. С помощью этих числовых номеров сообщения передаются из одной сети в другую, а после доставки сообщения в сеть назначения вместо числового номера используется аппаратный адрес компьютера. Сегодня такая схема характерна даже для небольших автономных сетей, где, казалось бы, она явно избыточна — это делается для того, чтобы при включении сети в большую сеть не нужно было менять состав операционной системы.
Проблема установления соответствия между адресами различных типов, которой занимаются протоколы разрешения адресов, может решаться как централизованными, так и распределенными средствами. В случае централизованного подхода в сети выделяется один или несколько компьютеров (серверов имен), в которых хранится таблица соответствия друг другу имен различных типов, например символьных имен и числовых номеров. Все остальные компьютеры обращаются к серверу имен, чтобы по символьному имени найти числовой номер компьютера, с которым необходимо обменяться данными.
При распределенном подходе каждый компьютер сам решает задачу установления соответствия между адресами. Например, если пользователь указал для узла назначения числовой номер, то перед началом передачи данных компьютер-отправитель посылает всем компьютерам сети широковещательное сообщение с просьбой опознать это числовое имя. Все компьютеры, получив такое сообщение, сравнивают заданный номер со своим собственным. Тот компьютер, у которого обнаружилось совпадение, посылает ответ, содержащий его аппаратный адрес, после чего становится возможной отправка сообщений по локальной сети.
Распределенный подход хорош тем, что не предполагает выделения специального компьютера, на котором к тому же часто приходится вручную вводить таблицу соответствия адресов. Недостатком распределенного подхода является необходимость широковещательных сообщений — такие сообщения перегружают сеть, так как они требуют обязательной обработки всеми узлами, а не только узлом назначения. Поэтому распределенный подход используется только в небольших локальных сетях. В крупных сетях распространение широковещательных сообщений по всем ее сегментам становится практически нереальным, поэтому для них характерен централизованный подход. Наиболее известной службой централизованного разрешения адресов является система доменных имен (Domain Name System, DNS) сети Internet.
Адреса могут использоваться для идентификации:
-
отдельных интерфейсов; -
их групп (групповые адреса); -
сразу всех сетевых интерфейсов сети (широковещательные адреса).
Адреса могут быть:
-
числовыми и символьными; -
аппаратными и сетевыми; -
плоскими и иерахическими.
Для преобразования адресов из одного вида в другой используются протоколы разрешения адресов (address resolution).
До сих пор мы говорили об адресах сетевых интерфейсов, которые указывают на порты узлов сети (компьютеров и коммуникационных устройств), однако конечной целью пересылаемых по сети данных, являются не компьютеры или маршрутизаторы, а выполняемые на этих устройствах программы — процессы. Поэтому в адресе назначения наряду с информацией, идентифицирующей порт устройства, должен указываться адрес процесса, которому предназначены посылаемые данные. После того, как эти данные достигнут указанного в адресе назначения сетевого интерфейса, программное обеспечение компьютера должно их направить соответствующему процессу. Понятно, что адрес процесса не обязательно должен задавать его однозначно в пределах всей сети, достаточно обеспечить его уникальность в пределах компьютера. Примером адресов процессов могут служить номера портов TCP и UDP, используемые в стеке TCP/IP.
Еще одной важнейшей задачей построения сетей является создание эффективного механизма коммутации. В следующей лекции мы рассмотрим это фундаментальное понятие с самых общих позиций.
Лекция #5: Коммутация и мультиплексирование
Коммутация рассматривается с самых общих позиций, для чего вводятся понятия информационных потоков, коммутатора, ставится задача маршрутизации. Определяются процедуры мультиплексирования и демультиплексирования, подчеркивается их отличие от процедур разделения среды передачи данных.
Обобщенная задача коммутации
Если топология сети не полносвязная, то обмен данными между произвольной парой конечных узлов (абонентов) должен идти в общем случае через транзитные узлы.
Например, в сети на рис. 5.1 узлы 2 и 4, непосредственно друг с другом не связанные, вынуждены передавать данные через транзитные узлы, в качестве которых могут использоваться, например, узлы 1 и 5. Узел 1 должен выполнить передачу данных с интерфейса A на интерфейс B, а узел 5 — с интерфейса F на B.
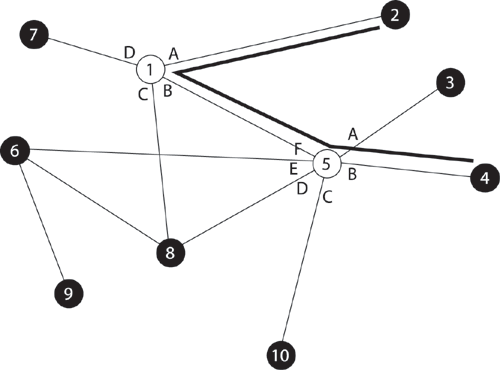
Рис. 5.1. Коммутация абонентов через сеть транзитных узлов.
Последовательность транзитных узлов (сетевых интерфейсов) на пути от отправителя к получателю называется маршрутом.
В самом общем виде задача коммутации — задача соединения конечных узлов через сеть транзитных узлов — может быть представлена в виде нескольких взаимосвязанных частных задач:
-
Определение информационных потоков, для которых требуется прокладывать пути. -
Определение маршрутов для потоков. -
Сообщение о найденных маршрутах узлам сети. -
Продвижение – распознавание потоков и локальная коммутация на каждом транзитном узле. -
Мультиплексирование и демультиплексирование потоков.
Определение информационных потоков
Понятно, что через один транзитный узел может проходить несколько маршрутов, например через узел 5 проходят данные, направляемые узлом 4 каждому из остальных узлов, а также все данные, поступающие в узлы 3 и 10. Транзитный узел должен уметь распознавать поступающие на него потоки данных, чтобы обеспечивать их передачу именно на те свои интерфейсы, которые ведут к нужному узлу.
Информационным потоком (data flow, data stream) называют последовательность данных, объединенных набором общих признаков, который выделяет эти данные из общего сетевого трафика.
Данные могут быть представлены в виде последовательности байтов или объединены в более крупные единицы данных — пакеты, кадры, ячейки. Например, все данные, поступающие от одного компьютера, можно определить как единый поток, а можно представить как совокупность нескольких подпотоков, каждый из которых в качестве дополнительного признака имеет адрес назначения. Каждый из этих подпотоков, в свою очередь, можно