Файл: Методические указания по выполнению лабораторных работ по дисциплине (модулю) Лингвистическое и программное обеспечение автоматизированных систем.doc
ВУЗ: Не указан
Категория: Не указан
Дисциплина: Не указана
Добавлен: 11.01.2024
Просмотров: 617
Скачиваний: 3
СОДЕРЖАНИЕ
2.Общие положения (теоретические сведения)
2.1. Принцип рекурсии в правилах грамматики
2.2. Запись правил грамматик с использованием метасимволов
2.3. Запись правил грамматик в графическом виде
3. Задание на лабораторную работу
4. Ход работы (порядок выполнения работы)
2.Общие положения (теоретические сведения)
2.1. Разработка лексического анализатора
2.2. Разработка синтаксического анализатора
2.3. Пример построения простого синтаксического анализатора
2.4. Анализаторы для сложных рекурсивных грамматик
2. Общие положения (теоретические сведения)
2.5. Логическая структура XML-документа
2.8. Описание структуры XML-документов
2.9. Язык XML Sсhema Definition (XSD)
2.10. Программная обработка XML-документов
2.11. Обработка XML-данных с использованием модели DOM
2.14. Сопоставление объектной иерархии с XML-данными
2.16. Считывание XML-документа в DOM
2.17. Директивы таблицы стилей, встроенные в документ
2.18. Загрузка данных из модуля чтения
2.19. Доступ к атрибутам в модели DOM
2.20. Получение всех атрибутов в виде коллекции
2.21. Получение единичного узла атрибута
2.22. Считывание объявлений сущностей и ссылок на сущности в DOM
2.23. Сохраняемые ссылки на сущности
2.24. Разворачиваемые и не сохраняемые ссылки на сущности
2.25. Создание новых узлов в модели DOM
2.26. Создание новых атрибутов для элементов в модели DOM
2.29. Проверка имен XML-элементов и атрибутов при создании новых узлов
2.30. Создание новых ссылок на сущности
2.32. Копирование существующих узлов
2.33. Копирование существующих узлов из одного документа в другой
2.34. Копирование фрагментов документа
2.35. Удаление узлов, содержимого и значений из XML-документа
2.36. Изменение узлов, содержимого и значений в XML-документе
2.37. Проверка XML-документа в DOM
2.38. Проверка XML-документа в DOM
2.39. Обработка ошибок проверки и предупреждений
2.40. Сохранение и запись документа
2.42. Запись содержимого документа с помощью свойства OuterXml
3.Задание на лабораторную работу
4. Ход работы (порядок выполнения работы)
2. Общие положения (теоретические сведения)
3. Задание на лабораторную работу
4. Ход работы (порядок выполнения работы)
2. Общие положения (теоретические сведения)
4. Ход работы (порядок выполнения работы)
2. Общие положения (теоретические сведения)
3.5. Эскизы в документах Деталей
3.6. Взаимодействие с пользователем
3 Задание на работу (рабочее задание)
Модель DOM чрезвычайно полезна для считывания XML-данных в память, изменения их структуры, добавления и удаления узлов, изменения данных, принадлежащих узлу (например, текста, содержащегося в документе). Однако существуют и другие классы, которые в некоторых ситуациях работают быстрее модели DOM. Классы XmlReader и XmlWriter предоставляют быстрый последовательный потоковый доступ к XML без поддержки кэширования. Если вам нужен произвольный доступ с моделью курсора и XPath, используйте класс .
2.13. Типы XML-узлов
Когда XML-документ считывается в память в виде дерева узлов, типы для узлов выбираются во время их создания. В модели XML DOM существует несколько типов узлов, определяемых консорциумом W3C. В следующей таблице перечислены типы узлов, объекты, назначаемые каждому типу узла, и дано краткое описание типов.
Таблица 2.11
Теги индикатора порядка
| ТИПЫ XML-УЗЛОВ | ||
| Тип узла модели DOM | Object | Описание |
| Document | XmlDocument | Контейнер для всех узлов в дереве. Он также называется корнем документа, что не всегда совпадает с корневым элементом. |
| DocumentFragment | XmlDocumentFragment | Временный контейнер, содержащий один или несколько узлов, не имеющих древовидной структуры. |
| DocumentType; | XmlDocumentType | Представляет узел . |
| EntityReference | XmlEntityReference | Представляет текст нераскрытой ссылки на сущность. |
| Элемент | XmlElement | Представляет узел элемента. |
| Attr | XmlAttribute | Атрибут элемента. |
| ProcessingInstruction; | XmlProcessingInstruction | Узел инструкций по обработке. |
| Добавление примечаний | XmlComment | Узел комментария. |
| Text | XmlText | Текст, принадлежащий элементу или атрибуту. |
| CDATASection. | XmlCDataSection | Представляет CDATA. |
| Объект | XmlEntity | Представляет декларации в XML-документе, полученные из встроенного DTD или из внешних DTD и сущностей параметров. |
| Notation | XmlNotation | Представляет нотацию, объявленную в DTD. |
Атрибут (attr) упомянут в числе узлов модели W3C DOM на уровне 1 в разделе "1.2. Фундаментальные интерфейсы", но не считается дочерним ни для какого узла элемента.
В следующей таблице представлены дополнительные типы узлов, которые не определены консорциумом W3C, но доступны для использования в модели объектов Microsoft .NET Framework в виде перечислений XmlNodeType. Таким образом, для этих типов узлов отсутствует соответствующий столбец типа узла в модели DOM.
Таблица 2.12
Типы узлов XML
| | |
| Тип узла | Описание |
| XmlDeclaration | Представляет узел декларации . |
| XmlSignificantWhitespace | Представляет значимые пробелы, то есть пробелы в смешанном содержимом. |
| XmlWhitespace | Представляет пробелы в содержимом элемента. |
| EndElement | Возвращается, когда модуль XmlReader достигает конца элемента. Пример XML-кода: Для получения дополнительной информации см. XmlNodeType. |
| EndEntity | Возвращается, когда модуль XmlReader достигает конца замещения сущности в результате вызова метода ResolveEntity. Для получения дополнительной информации см. XmlNodeType. |
Пример кода, считывающего XML и использующего конструкцию case с типами узлов для вывода сведений об узле и его содержимом, см. в статье NodeType.
2.14. Сопоставление объектной иерархии с XML-данными
Когда XML-документ находится в памяти, его концептуальным представлением является дерево. В распоряжении программиста имеется объектная иерархия для доступа к узлам этого дерева. Следующий пример показывает, как XML-содержимое становится узлами.
При считывании XML в модель DOM, его фрагменты преобразуются в узлы, и эти узлы сохраняют дополнительные метаданные о себе, в частности, тип узла и значения. Тип узла - это его объект и характеристики, определяющие выполняемые действия и свойства, которые можно установить и получить.
Если имеется следующий простой XML:
Ввод
Входные данные представлены в памяти следующим деревом узлов с назначенным свойством типа узлов:
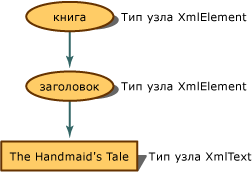
Представление дерева узлов book и title
Элемент book становится объектом XmlElementtitle, следующий элемент также становится объектом XmlElement, а элемент content становится объектом XmlText. Методы и свойства объекта XmlElement отличаются от методов и свойств, доступных для объекта XmlText. Поэтому очень важно знать, какой тип узла получает XML, так как тип узла определяет действия, которые можно выполнить.
В следующих примерах выполняется считывание XML-данных и запись другого текста, в зависимости от типа узла. Использование следующего XML-файла items.xml для получения входных данных.
Ввод
]>
Следующий пример кода считывает файл items.xml и отображает сведения о типах узлов.
C#
using System;
using System.IO;
using System.Xml;
public class Sample
{
private const String filename = "items.xml";
public static void Main()
{
XmlTextReader reader = null;
try
{
// Load the reader with the data file and ignore
// all white space nodes.
reader = new XmlTextReader(filename);
reader.WhitespaceHandling = WhitespaceHandling.None;
// Parse the file and display each of the nodes.
while (reader.Read())
{
switch (reader.NodeType)
{
case XmlNodeType.Element:
Console.Write("<{0}>", reader.Name);
break;
case XmlNodeType.Text:
Console.Write(reader.Value);
break;
case XmlNodeType.CDATA:
Console.Write("", reader.Value);
break;
case XmlNodeType.ProcessingInstruction:
Console.Write("{0} {1}?>", reader.Name, reader.Value);
break;
case XmlNodeType.Comment:
Console.Write("", reader.Value);
break;
case XmlNodeType.XmlDeclaration:
Console.Write("");
break;
case XmlNodeType.Document:
break;
case XmlNodeType.DocumentType:
Console.Write(", reader.Name, reader.Value);
break;
case XmlNodeType.EntityReference:
Console.Write(reader.Name);
break;
case XmlNodeType.EndElement:
Console.Write("{0}>", reader.Name);
break;
}
}
}
finally
{
if (reader != null)
reader.Close();
}
}
} // End class
Вывод примера содержит сопоставление данных типам узлов.
Выходныеданные
]
<--Fourteen chars in this element.-->
Рассматривая входные данные построчно и используя выход, сформированный кодом, можно использовать следующую таблицу для анализа того, какой узел сформировал конкретные строки результата, и понять, какие XML-данные стали соответствующими типами узлов.
Таблица 2.13
| | ||
| Входные данные | Вывод | Проверка типа узла |
| | | XmlNodeType.XmlDeclaration |
| | | XmlNodeType.Comment |
| ]> | ] | XmlNodeType.DocumentType |
| | | XmlNodeType.Element |
| | | XmlNodeType.Element |
| Проверка с помощью сущности: &number; | Проверка с помощью сущности: 123 | XmlNodeType.Text |
| | | XmlNodeType.EndElement |
| | | XmNodeType.Element |
| test with a child element | test with a child element | XmlNodeType.Text |
| | | XmlNodeType.Element |
| stuff | stuff | XmlNodeType.Text |
| | | XmlNodeType.EndElement |
| | | XmlNodeType.Element |
| test with a CDATA section | test with a CDATA section | XmlTest.Text |
| ]]> | ]]> | XmlTest.CDATA |
| def | def | XmlNodeType.Text |
| | | XmlNodeType.EndElement |
| | | XmlNodeType.Element |
| Проверка с помощью сущности char: A | Проверка с помощью сущности char: А | XmlNodeType.Text |
| | | XmlNodeType.EndElement |
| | <--Fourteen chars in this element.--> | XmlNodeType.Comment |
| | | XmlNodeType.Element |
| 1234567890ABCD | 1234567890ABCD | XmlNodeType.Text |
| | | XmlNodeType.EndElement |
| | | XmlNodeType.EndElement |
Необходимо знать, какой тип узла назначен, так как от типа узла зависят допустимые типы действий и типы свойств, которые можно установить и получить.
2.15. Создание XML-документа
XML-документ можно создать двумя способами. Один из них заключается в создании объекта XmlDocument без параметров. Второй включает создание объекта XmlDocument, которому нужно в качестве параметра передать XmlNameTable. В следующем примере показано создание пустого объекта XmlDocument без параметров.
C#
XmlDocument doc = new XmlDocument();
После создания документа в него можно с помощью метода Load загрузить данные из строки, потока, URL-адреса, текстового модуля чтения или класса, производного от XmlReader. Есть еще один метод загрузки: LoadXML, который считывает XML из строки.
Существует класс с именем XmlNameTable. Он является таблицей атомарных объектов строки. Эта таблица предоставляет средству синтаксического анализа XML эффективный способ использовать один и тот же строковый объект для всех повторяющихся имен элементов и атрибутов в XML-документе. Класс XmlNameTable автоматически создается при создании документа, как показано выше, и заполняется именами элементов и атрибутов при загрузке этого документа. Если у вас уже есть документ с таблицей имен и эти имена можно применить в другом документе, создайте новый документ с помощью метода Load, передав ему в качестве параметра таблицу XmlNameTable. Когда документ создается с помощью этого метода, он использует существующую таблицу XmlNameTable со всеми атрибутами и элементами, ранее загруженными в нее из другого документа. Это можно использовать для эффективного сравнения имен элементов и атрибутов.
2.16. Считывание XML-документа в DOM
XML-данные считываются в память из разных форматов. Они могут быть считаны из строки, URL-адреса, модуля чтения текста или класса, производного от класса XmlReader.
Метод Load загружает документ в память и имеет перегруженные методы для получения данных из разных форматов. Существует также метод LoadXml, который считывает XML-данные из строки.
Разные методы Load влияют на то, какие узлы создаются при загрузке модели DOM. В следующей таблице приведены различия между некоторыми методами Load, а также ссылки на разделы, описывающие их.
Таблица 2.14
| | |
| Субъект | Раздел |
| Создание узлов пробелов | Объект, используемый для загрузки модели DOM, влияет на узлы пробелов и значащих пробелов, формируемые в модели DOM.. |
| Загрузка XML-данных, начиная с определенного узла, или загрузка всего XML-документа | С помощью метода XmlDocument.Load данные в модель DOM можно загружать с определенного узла. |
| Проверка XML-данных по мере загрузки | Можно проводить проверку XML-данных, загружаемых в модель DOM, по мере их загрузки. Делается это с помощью проверяющего объекта XmlReader. |