Файл: Методические указания по выполнению лабораторных работ по дисциплине (модулю) Лингвистическое и программное обеспечение автоматизированных систем.doc
ВУЗ: Не указан
Категория: Не указан
Дисциплина: Не указана
Добавлен: 11.01.2024
Просмотров: 609
Скачиваний: 3
СОДЕРЖАНИЕ
2.Общие положения (теоретические сведения)
2.1. Принцип рекурсии в правилах грамматики
2.2. Запись правил грамматик с использованием метасимволов
2.3. Запись правил грамматик в графическом виде
3. Задание на лабораторную работу
4. Ход работы (порядок выполнения работы)
2.Общие положения (теоретические сведения)
2.1. Разработка лексического анализатора
2.2. Разработка синтаксического анализатора
2.3. Пример построения простого синтаксического анализатора
2.4. Анализаторы для сложных рекурсивных грамматик
2. Общие положения (теоретические сведения)
2.5. Логическая структура XML-документа
2.8. Описание структуры XML-документов
2.9. Язык XML Sсhema Definition (XSD)
2.10. Программная обработка XML-документов
2.11. Обработка XML-данных с использованием модели DOM
2.14. Сопоставление объектной иерархии с XML-данными
2.16. Считывание XML-документа в DOM
2.17. Директивы таблицы стилей, встроенные в документ
2.18. Загрузка данных из модуля чтения
2.19. Доступ к атрибутам в модели DOM
2.20. Получение всех атрибутов в виде коллекции
2.21. Получение единичного узла атрибута
2.22. Считывание объявлений сущностей и ссылок на сущности в DOM
2.23. Сохраняемые ссылки на сущности
2.24. Разворачиваемые и не сохраняемые ссылки на сущности
2.25. Создание новых узлов в модели DOM
2.26. Создание новых атрибутов для элементов в модели DOM
2.29. Проверка имен XML-элементов и атрибутов при создании новых узлов
2.30. Создание новых ссылок на сущности
2.32. Копирование существующих узлов
2.33. Копирование существующих узлов из одного документа в другой
2.34. Копирование фрагментов документа
2.35. Удаление узлов, содержимого и значений из XML-документа
2.36. Изменение узлов, содержимого и значений в XML-документе
2.37. Проверка XML-документа в DOM
2.38. Проверка XML-документа в DOM
2.39. Обработка ошибок проверки и предупреждений
2.40. Сохранение и запись документа
2.42. Запись содержимого документа с помощью свойства OuterXml
3.Задание на лабораторную работу
4. Ход работы (порядок выполнения работы)
2. Общие положения (теоретические сведения)
3. Задание на лабораторную работу
4. Ход работы (порядок выполнения работы)
2. Общие положения (теоретические сведения)
4. Ход работы (порядок выполнения работы)
2. Общие положения (теоретические сведения)
3.5. Эскизы в документах Деталей
3.6. Взаимодействие с пользователем
3 Задание на работу (рабочее задание)
Таблица 2.6
Ограничения на использование атрибутов
| Пример'>Ключевое слово | Описание | Пример |
| #REQUIRED | Обязательный атрибут | ClientID ID #REQUIRED |
| #IMPLIED | Необязательный атрибут | Address Region #IMPLIED |
| «Значение по умолчанию» | Если атрибут отсутствует, то анализатор принимает в качестве его значения значение, заданное по умолчанию. Если атрибут имеется, то он может принимать любое значение | |
| #FIXED «Значение» | Атрибут является необязательным, но если значение указано, то оно задается по умолчанию | Клиент Тип #FIXED «ФЛ» |
В качестве примера рассмотрим XML-документ и соответствующее ему DTD-описание.
System="CRM">
ClientID ID #REQUIRED
ClientType CDATA #REQUIRED
Class CDATA #IMPLIED
System NMTOКEN #FIXED "CRM">
Для описания логического компонента, многократно используемого разными XML-документами, применяются примитивы, которые задаются путем указания типа атрибута ENTITY. Примитивы могут быть внутренними (логический компонент повторно используется в одном документе) и внешними (повторно используется логический элемент из внешнего файла).
В зависимости от содержимого примитивы можно разделить на анализируемые примитивы (ссылаются на правильно сформированное содержимое XML) и примитивы, игнорируемые анализатором (ссылаются на не-XML-данные). Поскольку XML-анализатор не способен обрабатывать данные в двоичных и других не-XML-форматах, каждому примитиву, игнорируемому анализатором, должна соответствовать нотация. Нотации применяются для того, чтобы связать формат внешних данных, используемых в XML-документе, с внешней программой-обработчиком. Анализатор отошлет не-XMLданные на обработку указанной программе.
XML-документ, использующий нотации, играет роль унифицирующего документа, объединяющего разнородные данные.
Форматы описания логических компонентов XML приведены в табл. 2.7.
Таблица 2.7
Форматы описания логических компонентов XML
| Тип логического компонента | Формат описания (пример) |
| Внутренний примитив | Пример Строка DTD В DTD используется примитив Система, имеющий значение 1С:Предприятие. Строка XML <Клиент ИсточникДанных="&Система;"> В XML-документе атрибуту Источник данных тега Клиент будет присвоено значение 1С:Предприятие |
| Внешний примитив, обрабатываемый анализатором | Имя_примитива SYSTEM "SYS_ID"> или ENTITY Имя_примитива PUBLIC "PUBL_ID" "SYS_ID">, где " SYS_ID" — ссылка на реально существующий внешний файл (URL); "PUBL_ID" — идентификатор ресурса (URI), не обязательно реально существующий. Пример Строка DTD В DTD используется внешний примитив Описание, который определяет внешний файл C:/Discription.xml, содержащий описание клиента. Строка XML <Клиент>&Описание;Клиент> В тег Клиент будет вставлено содержимое файла C:/Discription.xml |
| Внешний примитив, игнорируемый анализатором | Имя_примитива SYSTEM "SYSTEM_ID" NDATA Имя нотации>, где " SYSTEM_ID" — ссылка на реально существующий внешний файл (URL); Имя_нотации — имя нотации, содержащей информацию о программе-обработчике не-XML-данных. Для описания нотации используется следующий формат: , где Т ип_данных — имя формата данных; SYSTEM_ID — внешняя программа-обработчик. Пример Фрагмент DTD image ENTITY #REQUIRED> Фрагмент XML < Book image="support" /> В XML-документ будут вставлены соответствующие графические файлы |
2.9. Язык XML Sсhema Definition (XSD)
Язык XML Schema Definition (XSD) основан на XML и обладает более широкими возможностями описания структуры документа, чем DTD. Он поддерживает типизацию данных, пространства имен, регулярные выражения.
XML Schema содержит описание элементов и атрибутов XMLдокумента, правила наследования элементов, включая порядок и количество потомков, тип содержимого элементов, типы данных элементов и атрибутов, значения элементов и атрибутов и дополнительные ограничения на значения. Кроме того, использование XML Schema обеспечивает трансформацию XML-документа в иерархию объектов определенных типов, доступ к которым может быть осуществлен программным способом с помощью интерфейса (функциональность PSV1).
Основным преимуществом языка XML Schema является поддержка строго типизированных данных. При обмене данными между различными приложениями и базами данных задача согласования типов данных всегда остается актуальной, поскольку в разных системах определения типов данных могут отличаться. К таким отличиям относятся: максимальное и минимальное возможные значения, наибольшая длина, поддержка дробных чисел, внутренняя кодировка и внешний формат (например, для даты и времени). Таким образом, несмотря на возможное совпадение названий типов данных, их реализация в различных продуктах может отличаться. Применение типов данных в схемах позволяет проводить необходимую верификацию данных документа при обмене или совместном использовании данных несколькими системами.
Данные пособие не является подробным руководством по языку XML Schema, поэтому здесь мы ограничимся только базовыми сведениями о языке XSD, которые необходимы для понимания последующего материала.
XML Schema всегда создается в отдельном файле, имеющем расширение xsd. Файл XML связывается с соответствующей схемой с помощью атрибута schemaLocation пространства имен схемы. Для того чтобы использовать атрибут schemaLocation, необходимо определить пространство имен схемы. Все эти определения указываются в корневом элементе документа XML.
<КорневойЭлемент
xmlns:xs="http://www.w3.org/2001/XMLSchema-instance"
xs:schemaLocation="Схема.xsd">
Рассмотрим основные элементы структуры XML Schema.
Корневым элементом всегда является элемент
Таблица 2.8 Описание атрибутов элемента
| Атрибут | Обязательный | Описание |
| elementFormDefault | Нет | Принимает значения «qualified» и «unqualified» (по умолчанию). Значение «qualified» указывет на то, что элементы документа должны уточняться префиксом пространства имен |
| attributeFormDefault | Нет | Принимает значения «qualified» и «unqualified» (по умолчанию). Значение «qualified» указывет на то, что атрибуты элементов документа должны уточняться префиксом пространства имен |
| xmlns: xs | Да | Всегда принимает значение xmlns: xs="http://www.w3.org/2001/XMLSchema" Указывает на пространство имен языка XMLSchema для элементов и типов данных схемы. При наличии префикса (в данном примере — xs) все элементы и типы данных схемы должны уточняться этим префиксом (xs: schema). Если префикс отсутствует, то атрибут xmlns указывает для схемы пространство имен по умолчанию. Элемент |
| targetNamespace | Нет | Пространство имен для элементов XML-документа, определенных данной схемой |
| version | Нет | Версия схемы |
| xml: lang | Нет | Язык для всех комментариев схемы |
Корневой элемент
-
— используется для определения элементов XML-документа; — используется для определения атрибутов XML-документа; — необходим для определения группы элементов, предназначенной для повторного использования в рамках схемы по ссылке на имя группы; — используется для определения атрибутов группы элементов; — позволяет включать в XML-документ документацию; — позволяет использовать компоненты указанной внешней схемы в основной схеме (обеспечивает модульность схем); — добавляет все компоненты указанной внешней схемы в основную схему (обеспечивает модульность схем);
< notation> — содержит определение нотации, описывающей формат не-XML-данных в XML-документе;— переопределяет компоненты внешней схемы, имеющей то же пространство имен, что и основная схема; — объявляет простой тип содержимого элемента. Элементы с простым типом данных могут содержать только символьные данные и не могут включать атрибуты и дочерние элементы; — объявляет сложный тип содержимого элемента, который может включать атрибуты и другие элементы.
XML Schema поддерживает три основные категории типов данных:
-
предопределенные примитивные типы — фундаментальные типы данных, на которые можно ссылаться и применять их к элементам и атрибутам. Примерами примитивных типов данных являются
String, Float, Double, Time, Date, Decimal, AnyURI;
-
предопределенные производные типы — встроенные типы, полученные на основании примитивных типов. Примерами производных типов данных являются Integer, Long, Byte, Short, nonPositiveInteger, nonNegativeInteger, ID и др.; -
нестандартные типы — определяемые пользователем типы данных, которые создаются на основании примитивных или производных типов путем введения дополнительных ограничений. Поддержка нестандартных типов данных исключительно полезна для верификации данных с учетом бизнес-логики.
Для описания элементов и атрибутов, имеющих предопределенные (примитивные и производные) типы данных, в XML Schema используются следующие синтаксические конструкции:
Дополнительно для элементов и атрибутов можно указать атрибуты fixed или default для задания фиксированных значений элементов/атрибутов или значений по умолчанию.
Если необходимо описать нестандартный тип данных для элемента или атрибута, то это следует делать с помощью тега
-
объединения (union) простых типов; -
использования списка (list) простых типов.
Новые нестандартные простые типы данных получают путем: сужения (restriction) встроенного или ранее определенного
Описание нестандартного типа данных
Пример использования нового простого типа данных, полученного путем сужения предопределенного типа (на базовый тип String накладываются ограничения на максимально и минимально допустимую длину строки):
Пример использования нового простого типа данных, полученног о путем объединения базовых типов (элемент или атрибут могут при- нимать неотрицательные или неположительные целые значения):
Пример использования списка простых типов (атрибут shoeSizes объявляется в качестве списка, содержащего десятичные значения 10.5, 9, 8 и 11):
Язык XML Schema использует различные типы ограничений на данные (см. табл. 2.6):
-
ограничения длины (количество символов); -
границы значений (наибольшее и наименьшее значения как диапазон или порог); -
ограничения количества цифр десятичного числа (общее количество цифр или количество цифр после запятой); -
список допустимых значений; -
шаблоны; -
обработка символов пробела.
Примеры использования различных ограничений приведены в табл. 2.9.
Таблица 2.9
Примеры использования ограничений
| Тип ограничения | Теги, задающие ограничения |
| Ограничения длины | |
| | |
| Границы значений | (в примере допустимы целые значения в диапазоне от 5 до 10, включая 5 и 10): (в примере допустимы целые значения в диапазоне от 5 до 10, исключая 5 и 10): |
| Ограничения количества и типа цифр | |
| Список допустимых значений | |
| Шаблоны | — регулярное выражение, используемое для ограничения внешнего вида или формы значений данных: |
| Обработка символов пробела | Используется в трех вариантах:
|
Элементы, имеющие простой тип или предопределенные стандартные типы, могут содержать только данные (не могут содержать атрибутов и дочерних элементов).
Любой простой тип данных может содержать произвольный набор ограничений, который определяется бизнес-логикой приложения, работающего с данными.
Если простому типу данных присвоено имя, то ссылка на новый нестандартный тип данных может быть использована многократно в пределах данной схемы (аналогично ссылке на предопределенные типы данных).
В данном примере определен нестандартный тип данных с именем «Код», базирующийся на типе «string»: он использован как тип данных для элементов «Код1» и «Код2».
Для описания элементов XML-документа, содержащих дочерние элементы и атрибуты, в схеме используется сложный тип данных, который задается с помощью тега
Описание сложного типа данных
При описании сложного типа указываются порядок вхождения дочерних элементов (с помощью специальных тегов — индикаторов порядка, см. табл. 2.9), а также степень кардинальности повторяющихся элементов (с использованием атрибутов minOccurs и maxOccurs).
Атрибут minOccurs определяет минимальную степень кардинальности, то есть наименьшее возможное количество повторений дочернего элемента. Значение minOccurs, равное нулю, указывает на необязательность (опциональность) элемента.
Атрибут maxOccurs определяет максимальную степень кардинальности, или наибольшее количество повторений элемента. Максимальная и минимальная степени кардинальности задаются определенными значениями. Для maxOccurs может быть указано значение unbounded (элемент встречается любое количество раз).
В данном примере описан сложный тип данных для элемента «Книга», содержащего дочерние элементы «Название», «Автор», «Код», «Цена». Тег
Таблица 2.10
Теги индикатора порядка
| Тег индикатора порядка | Описание |
| sequence | Дочерние элементы должны встречаться в указанном порядке. Степень кардинальности определяет, может ли дочерний элемент повторяться |
| all | Все дочерние элементы должны присутствовать в XML-документе. Дочерние элементы могут появляться в любом порядке, но должны встречаться только один раз. Нельзя задать значение степени кардинальности maxOccurs и minOccurs, отличное от единицы |
| choice | Из всех указанных дочерних элементов должен встречаться только один |
Индикатор порядка choice указывает, что элемент этого типа «Цена» может содержать либо элемент «Рубли», либо элемент «Доллары», но не оба.
2.10. Программная обработка XML-документов
Приложения, работающие с XML-документами, получают доступ к их содержимому и структуре путем использования специального программного компонента — XML-процессора (XML-анализатора). Следует отметить, что приложения работают не непосредственно с XML-документом, а с его информационным пространством XML Infoset, получаемым в результате разбора XML-документа XML-процессом. Таким образом, XML-процессор предназначен для анализа XML-документа, извлечения данных и передачи их на обработку в прикладную программу. XML-процессоры поддерживают механизм XML Namespace (спецификация W3C XML Namespaces 1.0) и обеспечивают проверку структурной и синтаксической корректности XML-документов.
XML-процессоры
Обрабатывая XML-документ, XML-процессоры представляют его структуру в виде упорядоченной модели данных, доступ к которой осуществляется с помощью стандартных интерфейсов прикладного программирования. Существуют два основных типа XML-процессоров — объектные (DOM) и потоковые (SAX).
Объектный анализатор строит в собственном пространстве памяти иерархическую модель разбираемого документа (Document Object Model, DOM), доступ к элементам которой прикладная программа получает с помощью DOM-интерфейсов. Основным преимуществом объектного анализатора является то, что он сразу предоставляет прикладной программе всю структуру XML-документа, позволяя ее анализировать в произвольном порядке.
Потоковый процессор является событийно управляемым и анализирует документ последовательно в режиме реального времени, что позволяет существенно экономить ресурсы памяти. Для доступа к элементам структуры документа прикладная программа в этом случае использует SAX (Simple API for XML).
2.11. Обработка XML-данных с использованием модели DOM
Модель DOM рассматривает XML-данные как стандартный набор объектов и используется для обработки XML-данных в памяти. Пространство имен System.Xml обеспечивает программное представление XML-документов, фрагментов, узлов и наборов узлов. Оно основывается на рекомендациях базовой модели DOM уровня 1 и модели DOM уровня 2 консорциума W3C.
Класс XmlDocument представляет XML-документ. Он включает элементы для получения и создания всех других XML-объектов. С помощью класса XmlDocument и связанных с ним классов можно конструировать XML-документы, загружать и обращаться к данным, изменять данные и сохранять изменения
Класс XML DOM является представлением XML-документа в памяти. Модель DOM позволяет читать, обрабатывать и изменять XML-документ программным образом. Класс XmlReader также читает XML, но предоставляет только последовательный доступ для чтения без поддержки кэширования. Это значит, что XmlReader не позволит изменять значения атрибутов или содержимое элемента, а также вставлять и удалять узлы. Изменение - основная функция модели DOM. Это стандартизованный, структурированный способ представления XML-данных в памяти, хотя на самом деле данные XML хранятся в файлах и пересылаются из других объектов в строковом виде. Далее приведен пример XML-данных.
2.12. Входные данные
Далее показано, какая структура будет создана в памяти, когда эти XML-данные считываются в модель структуры DOM.
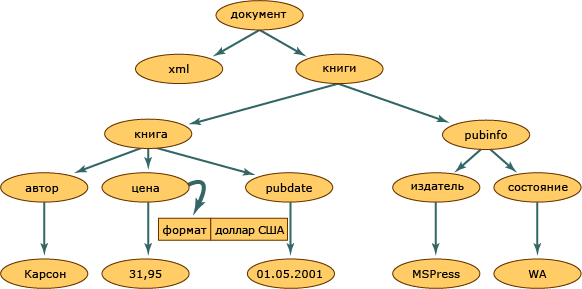 Структура XML-документа
Структура XML-документаКаждый круг на этой иллюстрации представляет собой узел в структуре XML-документа, называемый объектом XmlNode. Объект XmlNode является базовым объектом дерева DOM. Класс XmlDocument, расширяющий класс XmlNode, поддерживает методы для операций над документом в целом (например, для загрузки его в память или сохранения XML в файл). Кроме того, XmlDocument предоставляет возможности для просмотра узлов всего XML-документа и выполнения операций над ними. И XmlNode, и XmlDocument обладают улучшенной производительностью, расширенной функциональностью и содержат методы и свойства, которые позволяют следующее.
-
Получать доступ к DOM-специфичным узлам, например к узлам элементов, узлам ссылок на сущности и т. п., и изменять эти узлы. -
Получать целые узлы помимо содержащейся в них информации, например текста в узле элемента.
Объекты Node обладают набором методов и свойств, а также хорошо определенных базовых характеристик. Вот некоторые из этих характеристик:
-
У каждого узла есть один родительский узел, то есть узел, находящийся непосредственно над данным. Единственный узел, не имеющий родителя - корневой узел документа, так как это узел верхнего уровня, содержащий сам документ и его фрагменты. -
У большинства узлов может быть несколько дочерних узлов, то есть узлов, расположенных непосредственно под ними. Далее следует список типов узлов, которые могут иметь дочерние узлы:-
Document -
DocumentFragment -
EntityReference -
Элемент -
Attribute (XElement Dynamic Property) (Attribute (динамическое свойство XElement))
-
Узлы XmlDeclaration, Notation, Entity, CDATASection, Text, Comment, ProcessingInstruction и DocumentType не могут иметь дочерних узлов.
-
Узлы, находящиеся на одном уровне наследования, например узлы book и pubinfo на нашей схеме, называются одноуровневыми.
Одна из характеристик модели DOM - способ обработки атрибутов. Атрибуты не являются узлами, состоящими в родительских, дочерних и одноуровневых связях. Атрибуты считаются собственностью узла элемента и представляют собой пару «имя-значение». Например, если XML-данные представляют собой конструкцию format="dollar, связанную с элементом price, слово format является именем атрибута, а значением атрибута format является dollar. Чтобы получить атрибут format="dollar" узла price, воспользуйтесь методом GetAttribute, когда курсор расположен в узле элемента price.
По мере считывания XML-документа в память создаются узлы. Узлы бывают разных типов. Правила и синтаксис XML-элемента отличаются от правил и синтаксиса инструкции по обработке. Поэтому по мере считывания разнообразных данных каждому узлу присваивается тип. Тип узла определяет его характеристики и функциональность.
Корпорация Майкрософт расширила API-интерфейсы, доступные в DOM уровней 1 и 2 W3C, чтобы облегчить работу с XML-документами. Дополнительные классы, методы и свойства полностью совместимы со стандартами W3C и добавляют дополнительную функциональность по сравнению с возможностями W3C XML DOM. Новые классы позволяют получить доступ к реляционным данным