Добавлен: 29.10.2018
Просмотров: 48187
Скачиваний: 190
596
Глава 8. Многопроцессорные системы
Было рассмотрено, что эта команда считывает слово памяти в регистр процессора.
Одновременно она записывает 1 (или другое ненулевое значение) в слово памяти.
Конечно, для выполнения операций чтения из памяти и записи в память требуются
два цикла обращения к шине. На однопроцессорной машине команда TSL работает так,
как и ожидалось, поскольку команда процессора не может быть прервана на полпути.
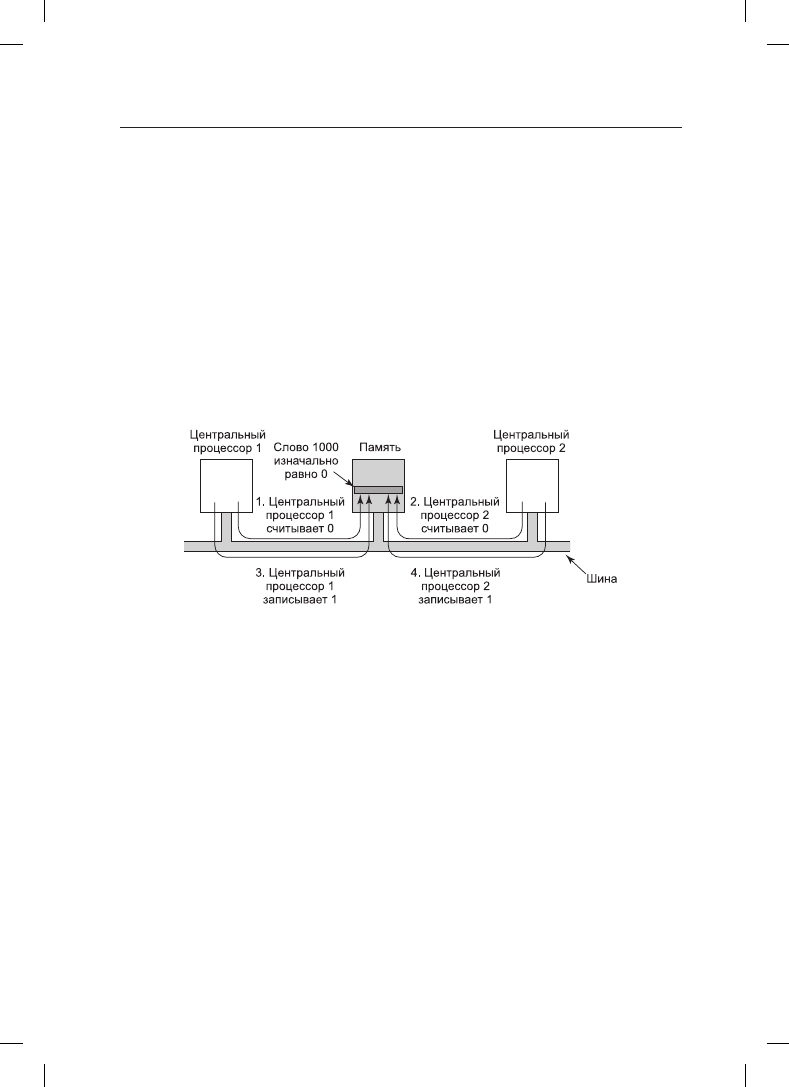
А теперь подумаем, что может произойти на мультипроцессоре. На рис. 8.10 показано
наихудшее из возможных развитие ситуации, где в качестве блокиратора используется
слово памяти по адресу 1000, имеющее начальное значение 0. На шаге 1 центральный
процессор 1 считывает слово и получает значение 0. На шаге 2, перед тем как у про-
цессора 1 появится возможность переписать значение слова на 1, на сцену выходит
центральный процессор 2 и также считывает это слово, получая значение 0. На шаге 3
центральный процессор 1 записывает в это слово значение 1. На шаге 4 центральный
процессор 2 также записывает значение 1 в это слово. Оба процессора получили
в результате работы команды TSL значение 0, поэтому теперь они оба имеют доступ
к критической области и взаимного исключения не происходит.
Рис. 8.10. Если шина не может быть заблокирована, команда TSL потерпит неудачу.
Этими четырьмя шагами показана последовательность событий, демонстрирующая
неудачное стечение обстоятельств
Для предотвращения проблемы команда TSL должна сначала заблокировать шину,
препятствуя доступу к ней со стороны других центральных процессоров, затем осуще-
ствить обе операции доступа к памяти, после чего разблокировать шину. Как правило,
блокировка шины осуществляется путем запроса шины с использованием обычного
протокола ее запроса с последующим выставлением логической единицы на какой-
нибудь специальной линии шины, до тех пор пока не будут завершены оба цикла об-
ращения к шине. Пока на этой специальной линии шины выставлена единица, доступа
к шине не получит никакой другой центральный процессор. Эта команда может быть
реализована только на шине, у которой имеются необходимые линии и аппаратный
протокол для их использования. Все современные шины обладают такими возможно-
стями, но на более ранних шинах, не обладающих ими, правильно реализовать команду
TSL невозможно. Поэтому был изобретен протокол Петерсона для синхронизации
сугубо программным путем (Peterson, 1981).
При правильных реализации и использовании команды TSL гарантируется работо-
способное взаимное исключение. Но этот метод взаимной блокировки использует
спин-блокировку
(spin lock), потому что запрашивающий центральный процессор
просто находится в коротком цикле, с максимально возможной скоростью тестируя

8.1. Мультипроцессоры
597
блокировку. При этом совершенно напрасно тратится время запрашивающего цен-
трального процессора (или процессоров), и, кроме того, может быть также слишком
нагружена шина или память, существенно замедляя нормальное функционирование
других центральных процессоров.
На первый взгляд может показаться, что конкуренция в борьбе за шину должна быть
устранена за счет кэширования, но это не так. Теоретически, как только запрашива-
ющий центральный процессор считал слово блокировки, он должен получить его
копию в своем кэше. Пока ни один из других центральных процессоров не пытается
использовать блокировку, запрашивающий центральный процессор должен обладать
способностью выходить за пределы своего кэша. Когда центральный процессор, вла-
деющий блокировкой, делает запись в слово, чтобы снять блокировку, протокол кэша
автоматически аннулирует все копии этого слова в удаленных кэшах, требуя извлечь
заново правильное значение.
Проблема в том, что кэши работают с блоками по 32 или 64 байта. Обычно слова,
окружающие слово блокировки, нужны центральному процессору, удерживающему
блокировку. Так как команда TSL осуществляет запись (потому что она изменяет зна-
чение слова блокировки), ей нужен монопольный доступ к блоку кэша, содержащему
слово блокировки. Поэтому каждая команда TSL аннулирует блок в кэше процессора,
удерживающего блокировку, и извлекает отдельную, недоступную для других копию
для запрашивающего процессора. Как только удерживающий блокировку процессор
изменит слово, примыкающее к слову блокировки, блок кэша перемещается на его
машину. Поэтому весь блок кэша, в котором содержится слово блокировки, постоянно
совершает челночные перемещения между процессором, удерживающим блокировку,
и процессором, запрашивающим блокировку, порождая более объемный поток данных
по шине по сравнению с тем, который был бы при считывании только одного слова
блокировки.
Если бы удалось избавиться от всех записей, вызванных выполнением команды TSL
на запрашивающей стороне, то можно было бы существенно уменьшить все эти мета-
ния, связанные с кэшем. Этого можно добиться, если заставить запрашивающий цен-
тральный процессор сначала просто прочитать слово блокировки, чтобы убедиться,
что оно свободно. И только в том случае, если оно свободно, заставить его выполнить
команду TSL, чтобы осуществить захват этого слова. В результате этого небольшого
изменения большинство операций опроса теперь являются операциями чтения, а не
записи. Если удерживающий блокировку центральный процессор только считывает
переменные в одном и том же блоке кэша, то у каждого центрального процессора
может быть копия этого блока кэша в режиме общего доступа только для чтения,
что исключит все перемещения блока кэша. При окончательном снятии блокировки
ее владелец осуществляет операцию записи, требующую монопольного доступа,
поэтому все другие копии на удаленных кэшах аннулируются. При последующем
чтении запрашивающего центрального процессора блок кэша будет снова загружен.
Обратите внимание на то, что при борьбе двух и более процессоров за одну и ту же
блокировку может случиться, что все они одновременно увидят, что она свободна,
и все одновременно выполнят команду TSL для ее захвата. Только один из них до-
бьется успеха, и состязательных условий между ними не будет, потому что реальный
захват осуществляется командой TSL, а она имеет атомарный характер. Обнаружение
свободной блокировки и попытка ее немедленного захвата не гарантируют получения
этой блокировки. Выиграть может какой-нибудь другой центральный процессор, но
598
Глава 8. Многопроцессорные системы
для правильной работы алгоритма не имеет значения, кто именно получит блокиров-
ку. Успешное чтение является всего лишь подсказкой о том, что есть благоприятная
возможность предпринять попытку захвата блокировки, но это еще не гарантия того,
что этот захват увенчается успехом.
Другой способ уменьшения потока передаваемых по шине данных заключается в при-
менении широко известного алгоритма двоичной экспоненциальной задержки (binary
exponential backoff), используемого в сетях Ethernet (Anderson, 1990). Вместо посто-
янного опроса, как на рис. 2.17, между опросами может быть вставлен цикл задержки.
Сначала задержка составляет одну команду. Если блокировка еще не освободилась,
задержка удваивается и составляет две команды, затем четыре и так далее до дости-
жения некоторого максимума. Низкий максимум приводит к быстрому отклику при
освобождении блокировки, но заставляет тратить впустую циклы обращения к шине на
челночные передачи данных кэша. Высокий максимум сокращает челночные передачи
данных кэша за счет замедленной реакции на освобождение блокировки. Двоичная
экспоненциальная задержка может использоваться совместно с простым чтением,
предваряющим выполнение команды TSL, или без него.
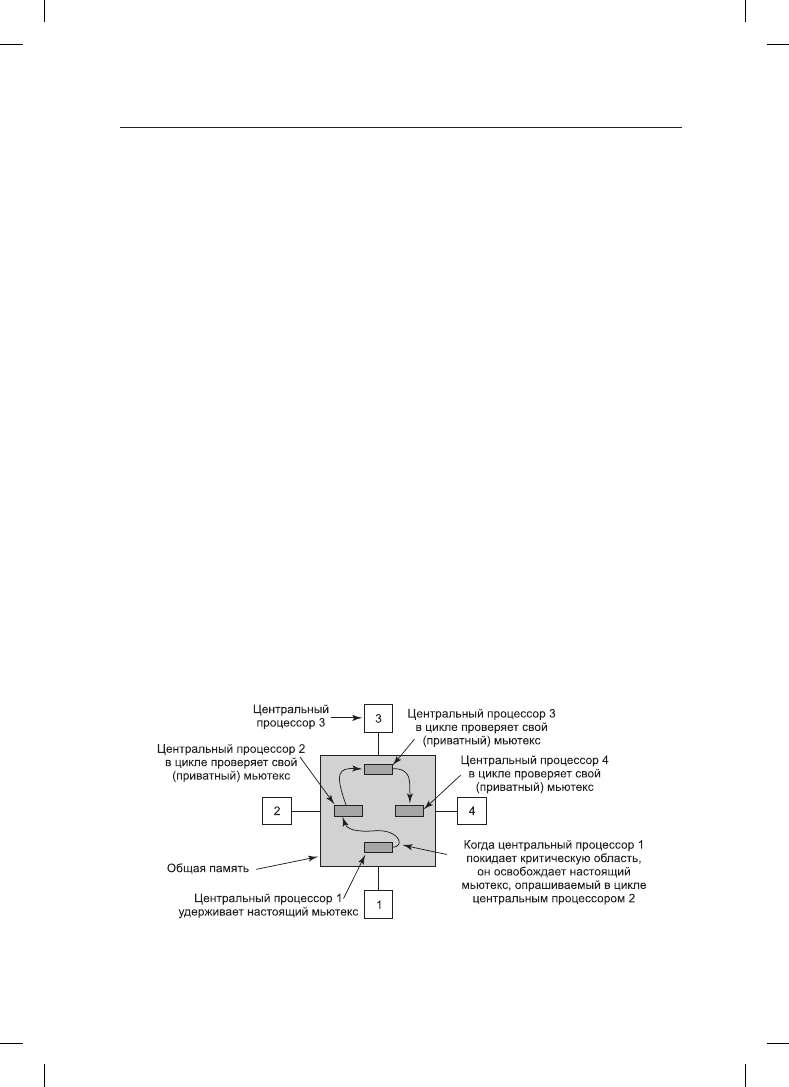
Более интересная идея заключается в том, чтобы предоставить для проверки каждому
центральному процессору, желающему захватить мьютекс, собственную переменную
блокировки (рис. 8.11) (Mellor-Crummey and Scott, 1991). Во избежание конфлик-
тов она должна быть помещена в блок кэша, не используемый ни для чего другого.
Алгоритм работает за счет того, что центральный процессор, не сумевший получить
блокировку, получает переменную блокировки и присоединяется к концу списка цен-
тральных процессоров, ожидающих освобождения блокировки. Когда центральный
процессор, удерживающий блокировку, покидает критическую область, он освобож-
дает ту частную переменную блокировки, которую первый по списку центральный
процессор тестирует в своем собственном кэше. Затем в критическую область входит
этот центральный процессор. Завершив свою работу, он освобождает переменную
блокировку, используемую его последователем, и т. д. При всей сложности этого про-
токола (связанной с тем, что нужно не допустить одновременного присоединения двух
центральных процессоров к концу списка) он работает эффективно и без зависаний.
Подробности можно узнать из упомянутой ранее статьи.
Рис. 8.11. Использование нескольких переменных блокировки, чтобы избежать
челночной передачи данных кэша

8.1. Мультипроцессоры
599
Что лучше, ожидание в цикле или переключение?
До сих пор мы допускали, что центральный процессор, которому требуется заблоки-
рованный мьютекс, просто ждет, пока тот не освободится, постоянно или периодиче-
ски опрашивая его состояние или присоединяясь к списку ожидающих процессоров.
Иногда другого выбора, кроме простого ожидания, для запрашивающего блокировку
центрального процессора просто нет. Предположим, к примеру, что какой-либо цен-
тральный процессор простаивает и ему нужен доступ к общему списку готовых к ра-
боте процессов, чтобы выбрать оттуда процесс и запустить его. Если список готовых
к работе процессов заблокирован, центральный процессор не может просто решить
приостановить то, чем он занимается, и запустить другой процесс, потому что для это-
го требуется прочитать список процессов, готовых к работе. Центральный процессор
вынужден ждать, пока этот список не освободится.
Но в других случаях центральному процессору есть из чего выбирать. Например, если
какому-нибудь потоку на центральном процессоре потребуется доступ к буферному
кэшу файловой системы, который в данный момент заблокирован, центральный про-
цессор может решить не ждать, а переключиться на другой поток. Вопрос о том, ждать
или переключаться на другой поток, являлся предметом многочисленных исследова-
ний, некоторые из них будут рассмотрены в дальнейшем. Обратите внимание на то, что
на однопроцессорной системе этот вопрос не возникает, потому что опрос в цикле не
имеет смысла, если нет другого центрального процессора, освобождающего блокировку.
Если поток пытается получить блокировку и ему это не удается, он всегда блокируется,
чтобы дать возможность для работы и освобождения блокировки ее владельцу.
Если предположить, что можно применить как циклический опрос, так и переключение
на другой поток, то все «за» и «против» будут следующими. На циклический опрос впу-
стую тратится время центрального процессора. Постоянное тестирование переменной
блокировки не является продуктивной работой. Но и на переключение также тратит-
ся впустую время центрального процессора, поскольку нужно сохранить состояние
текущего потока, получить блокировку списка готовых к работе процессов, выбрать
поток, загрузить его состояние и запустить этот поток. Кроме того, кэш центрального
процессора будет заполнен ненужными блоками, поэтому с запуском нового потока
на заполнение кэша отсутствующими в нем блоками будет затрачено много ресурсов.
Также вероятны возникновения ошибок TLB. В конечном итоге должно произойти
обратное переключение на исходный поток, опять же связанное с отсутствием в кэше
нужных блоков. Время на осуществление этих двух переключений контекста плюс
время, необходимое на обновление кэша, тратится впустую.
Если известно, что мьютексы обычно удерживаются, скажем, в течение 50 мкс, а пере-
ключение с одного потока на другой занимает 1 мс и еще 1 мс требуется на обратное
переключение, то лучше просто вести циклический опрос, ожидая освобождения мью-
текса. Но если в среднем мьютекс удерживается в течение 10 мс, то стоит потратиться
на два переключения контекста. Проблема в том, что продолжительность пребывания
процессов в критических областях может варьироваться в широких пределах, поэтому
возникает вопрос: какой из двух подходов лучше?
Можно остановиться на циклическом опросе, а можно и на переключении. Но есть еще
и третий вариант: в каждом случае, связанном с блокируемым взаимным исключением,
принимать отдельное решение. К тому моменту, когда следует принять решение, еще
неизвестно, что лучше — циклический опрос или переключение, но есть возможность

600
Глава 8. Многопроцессорные системы
отследить всю работу каждой конкретной системы и проанализировать ее чуть позже
в автономном режиме. Затем в ретроспективе можно будет сказать, какое решение
было лучшим и сколько времени было потрачено впустую в лучшем случае. Этот ре-
троспективный алгоритм станет отправной точкой для оценки подходящих алгоритмов.
Эта проблема была изучена исследователями (Ousterhout, 1982). В большинстве работ
использовалась модель, в которой поток, не сумевший захватить мьютекс, некоторое
время выполнял циклический опрос. По истечении заданного времени он переклю-
чался. В некоторых случаях заданное время было фиксированным, как правило, это
были известные потери на переключение на другой поток с последующим обратным
переключением. В других случаях время задавалось динамически в зависимости от
предшествующих наблюдений за востребованным мьютексом.
Лучших результатов удавалось достичь, когда система отслеживала время нескольких
последних циклических ожиданий и предполагала, что каждое конкретное ожидание
будет по времени аналогично предыдущим. Например, опять предполагая, что на пере-
ключение контекста уйдет 1 мс, поток будет проводить циклический опрос не более
2 мс, но понаблюдает, сколько времени действительно уйдет на циклический опрос.
Если он не сможет получить блокировку и увидит, что в ходе предыдущих трех за-
пусков на ожидание в среднем уходило 200 мкс, значит, перед тем как переключиться,
ему следует провести в состоянии циклического опроса 2 мс. Но если он видит, что при
каждой предыдущей попытке он провел в состоянии циклического опроса все 2 мс, он
должен переключиться немедленно и вообще не проводить циклический опрос.
Некоторые современные процессоры, включая x86, предлагают специальные ин-
струкции, повышающие эффективность ожидания в понятиях энергосбережения.
Например, инструкции MONITOR/MWAIT в процессоре x86 позволяют программе
блокироваться до тех пор, пока какой-нибудь другой процесс не изменит данные в за-
ранее определенной области памяти. В частности, инструкция MONITOR определяет
диапазон адресов, который должен отслеживаться на предмет записи. Затем инструк-
ция MWAIT блокирует поток до тех пор, пока кто-нибудь не произведет запись в эту
область. Фактически поток продолжает работать, но без напрасной траты множества
вычислительных циклов.
8.1.4. Планирование работы мультипроцессора
Перед тем как перейти к рассмотрению вопросов планирования работы мультипро-
цессоров, нужно четко определить, что именно подвергается планированию. В былые
времена, когда все процессы были однопоточными, ответ был один: следовало плани-
ровать процессы, поскольку больше планировать было нечего. Но все современные
операционные системы поддерживают многопоточные процессы, что значительно
усложняет планирование.
Играет роль и то, с какими потоками мы имеем дело: с потоками в пространстве ядра
или с потоками в пользовательском пространстве. Если потоки образуются с помощью
библиотеки, находящейся в пользовательском пространстве, и ядро о них ничего не
знает, то планирование осуществляется, как и всегда, на основе процессов. Если ядро
даже ничего не знает о существовании потоков, то вряд ли оно сможет заниматься их
планированием.
А вот с потоками в пространстве ядра все обстоит по-другому. Здесь ядро знает обо всех
потоках и может выбирать из тех потоков, которые принадлежат процессу. В этих