ВУЗ: Не указан
Категория: Не указан
Дисциплина: Не указана
Добавлен: 31.03.2024
Просмотров: 460
Скачиваний: 1
СОДЕРЖАНИЕ
1. Составляющие информационной технологии
2. Инструментарий информационной технологии
3. Виды современных информационных технологий
4. Проблемы и перспективы использования информационных технологий
Текстовый редакторMicrosoft Word 2003
Лабораторные задания поMicrosoftWord Ввод и форматировние текста
Признак деления - вид задач и процессов обработки информации
Признак деления — проблемы, стоящие на пути информатизации общества
Глава 1. Планирование эксперимента
Особенности планирования эксперимента
Выбор оптимальных условий эксперимента
Глава 3. Оптимальная структура моделей
Глава 1. Аппроксимация функций
Табличный процессор Microsoft Excel 2003
Лабораторные задания поMicrosoftExcel Оформление таблиц
Рисунок 45. Кумулята для интервального ряда распределения
Режим «Гистограмма» служит для вычисления частот попадания данных в указанные границы интервального вариационного ряда распределения.
Команда Сервис/Анализ данных/Гистограмма отображает диалоговое окно (рис. 45), в котором задаются параметры, указанные в таблице 10.
|
Параметр |
Описание |
|
Входной интервал |
Ссылка на ячейки, содержащие анализируемые данные |
|
Интервал карманов |
Необязательный параметр. Набор граничных значений, определяющих интервалы. Эти значения должны быть введены в возрастающем порядке. Вычисляется число попаданий в сформированные интервалы, причем границы интервалов являются строгими нижними и нестрогими верхними: а<хb. Если диапазон карманов не задан, то набор интервалов будет создан автоматически. |
|
Метки |
Задается если первая строка (столбец) во входном диапазоне содержит заголовки. |
|
Выходной интервал |
Поле, в которое необходимо ввести ссылку на левую верхнюю ячейку выходного диапазона. |
|
Новый рабочий лист |
Вставка результата анализа на новый рабочий лист начиная с ячейки А1. Можно задать имя открываемого рабочего листа, указав его в соседней области. |
|
Новая рабочая книга |
Результат анализа выводится в новой рабочей книге на первом листе начиная с ячейки А1. |
|
Парето |
Устанавливает данные в порядке убывания частоты. |
|
Интервальный процент |
Выполняет расчет в процентах накопленных частот и включает в гистограмму графика кумуляты. |
|
Вывод графика |
Автоматически создает встроенную диаграмму на листе содержащем выходной диапазон. |
Таблица 10. Параметры режима «Гистограмма»
На рис. 45 приведен пример построения гистограммы и кумуляты, для задачи, в которой представлен общий объем товарооборота по районам Ярославский области.
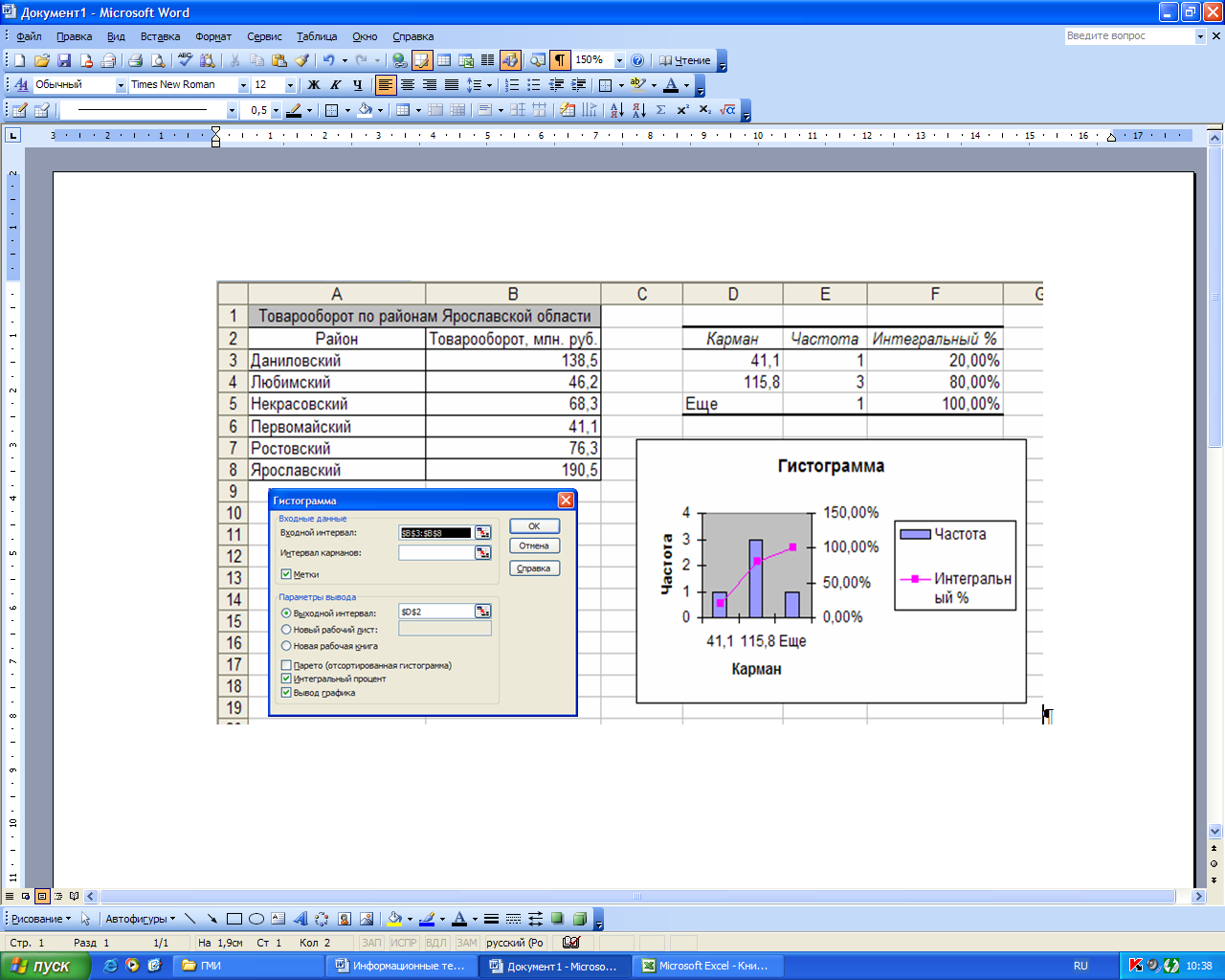
Рисунок 46. Пример построения гистограммы и кумуляты
Выборка
Исследование массовых статистических явлений в зависимости от полноты охвата изучаемого объекта бывает сплошным и несплошным (выборочным). Под выборочным наблюдением понимается метод исследования, при котором обобщающие показатели изучаемой совокупности устанавливаются по некоторой ее части на основе положений случайного отбора. Выборка должна быть представительной (репрезентативной), чтобы по ней можно было судить о генеральной совокупности. Выборочный метод позволяет значительно сократить время на контроль и получение основных статистических характеристик, но может привести и к появлению ошибок, уменьшающих получение истинных характеристик генеральной совокупности. Данное обстоятельство важно учитывать при формировании малых выборок. Достаточно сложной проблемой является определение оптимального объема выборки. В математической статистике доказывается, что необходимая численность собственно-случайной повторной выборки определяется выражением:
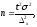
где ∆х – предельная ошибка выборки;
2 – дисперсия генеральной совокупности;
t – коэффициент доверия.
Режим «Выборка» служит для формирования выборки из генеральной совокупности на основе механизма повторного собственно-случайного отбора, а также из периодических данных.
Команда Сервис/Анализ данных/Выборка отображает диалоговое окно, в котором задаются параметры, указанные в таблице 11.
|
Параметр |
Описание |
|
Входной интервал |
См. описание в режиме «Гистограмма» таб. 10 |
|
Метки |
|
|
Выходной интервал |
|
|
Новый рабочий лист |
|
|
Новая рабочая книга |
|
|
Периодический метод выборки |
Указывается размер периодического интервала, по которому формируется выборка. Значение из генеральной совокупности, номер которого совпадает с номером, заданным в поле Период, и каждое последующее с номером, кратным периоду, будет занесено в выходной столбец |
|
Случайный метод |
Указывается число размещаемых в выходном столбце случайных значений. |
Таблица 11. Параметры режима «Выборка»
На рис. 46 приведен пример использования режима «Выборка», для организации лотереи. Требуется отобрать три победителя.
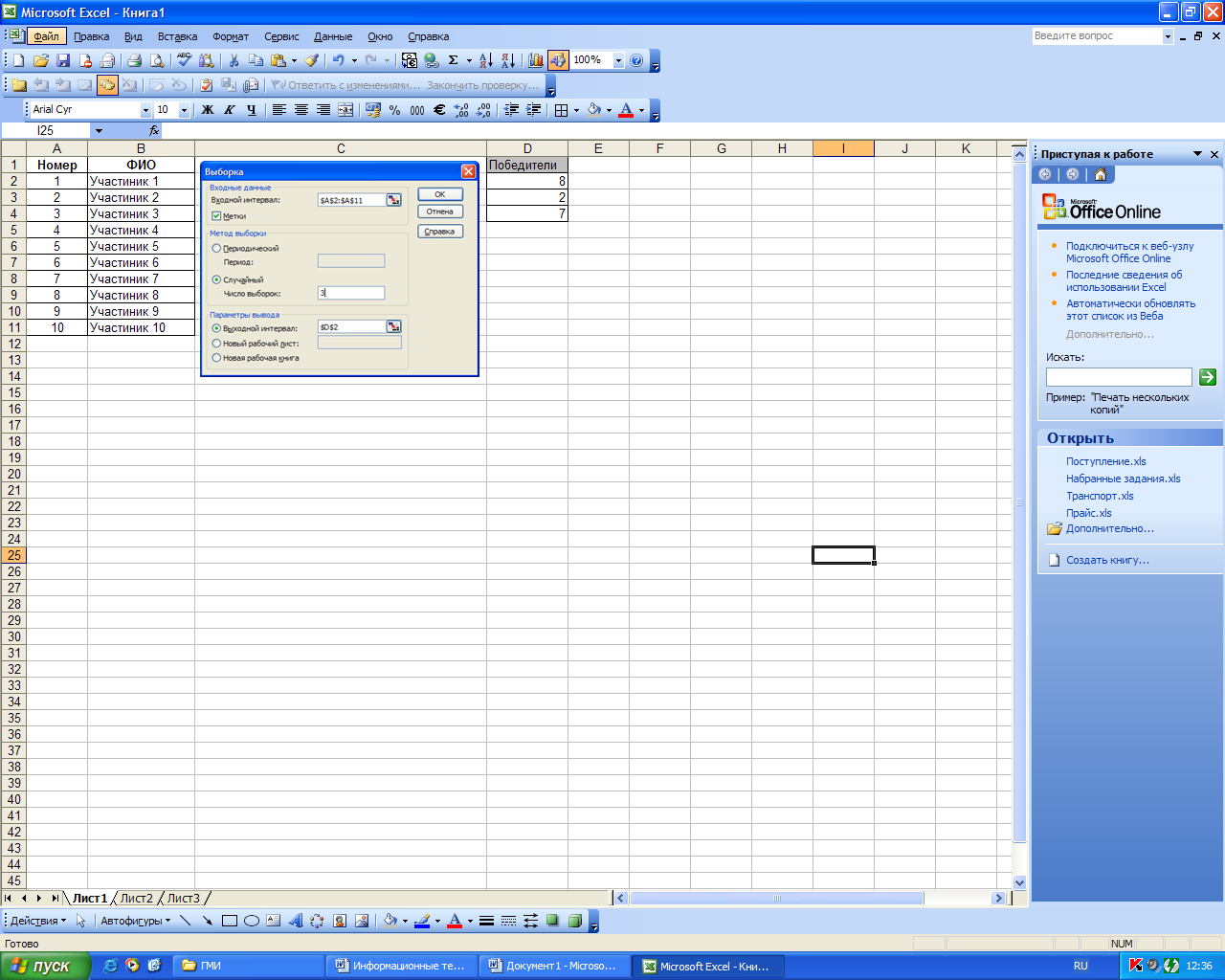
Рисунок 47. Пример использования режима «Выборка»
Генерация случайных чисел
Случайной называется переменная величина, принимающая в зависимости от случая те или иные значения с определенными вероятностями. Чтобы дать полное математическое описание случайной величины, нужно указать множество ее значений и соответствующие случайной величине распределение вероятностей на этом множестве. Для дискретной случайной величины используется статистический ряд распределения, для непрерывной случайной величины используется функция распределения. Функцией распределения случайной величины Х называется функция F(x), задающая вероятность того, что случайная величина Х принимает значение, меньшее х, т.е. F(x)=P(X<x).
В статистике широко используются различные виды теоретических распределений – нормальное распределение, биноминальное, дискретное, распределение Пуассона и т.д.
Режим «Генерация случайных чисел» служит для формирования массива случайных чисел, распределенных по одному из теоретических распределений. В зависимости от выбранного теоретического распределения меняются параметры диалогового окна «Генерация случайных чисел». Общими параметрами являются параметры, указанные в таблице 12.
|
Параметр |
Описание |
|
Число переменных |
Число столбцов значений, которые необходимо разместить в выходном диапазоне. Если число не задано, заполняются все столбцы выходного диапазона |
|
Число случайных чисел |
Число случайных значений, которое необходимо ввести в каждом столбце выходного диапазона. Если число не введено, все строки выходного диапазона будут заполнены. |
|
Распределение |
Указывается тип распределения из раскрывающегося списка. |
|
Случайное рассеивание |
Вводиться начальное число для генерации определенной последовательности случайных чисел. |
|
Выходной интервал/ Новый рабочий лист/ Новая рабочая книга |
См. описание в режиме «Гистограмма» таб. 10 |
Таблица 12. Параметры режима «Генерация случайных чисел»
На рис. 47 приведен пример использования режима «Генерация случайных чисел», если требуется смоделировать 10 подбрасываний двух игральных костей. Предварительно следует сформировать таблицу значений и вероятностей, а затем задать соответствующие параметры в диалоговом окне. Заметим, что для дискретного распределения сумма вероятностей должна быть равна 1.
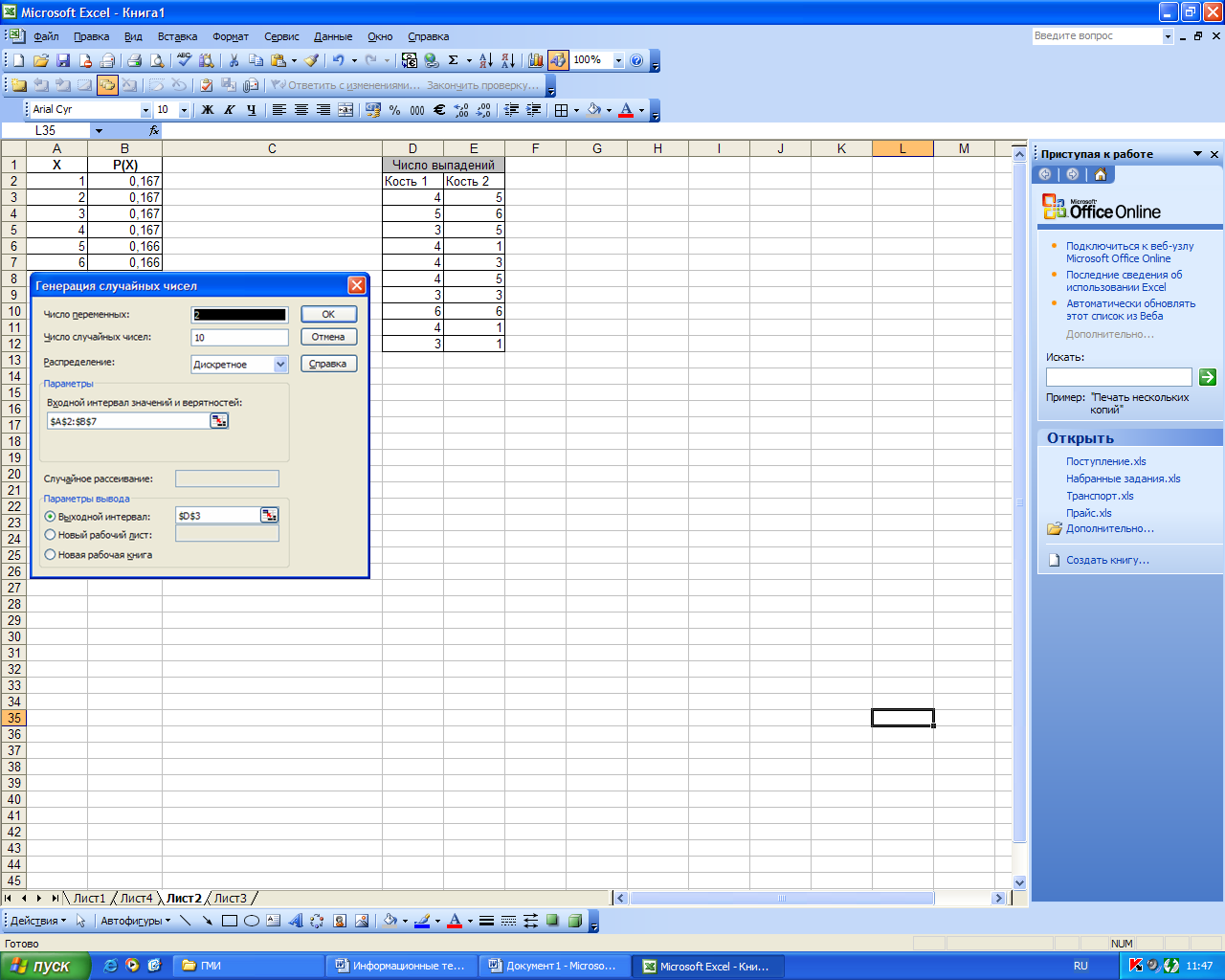
Рисунок 48. Пример использования режима «Генерация случайных чисел»
Двухвыборочный t-тест с одинаковыми и различными дисперсиями
Режим «Двухвыборочный t-тест с одинаковыми (различными) дисперсиями» служит для проверки гипотез о различии между средними (математическими ожиданиями) двух нормальных распределений соответственно с неизвестными, но равными дисперсиями (2х=2у) и с неизвестными дисперсиями, равенство которых не предполагается.
Команда Сервис/Анализ данных/Двухвыборочный t-тест с одинаковыми дисперсиями (Двухвыборочный t-тест с различными дисперсиями) отображает диалоговое окно, в котором задаются параметры, указанные в таблице 13.
|
Параметр |
Описание |
|
Интервал переменной 1 |
Вводиться ссылка на ячейки, содержащие результаты наблюдений величины Х. Диапазон должен состоять из одного столбца (строки) |
|
Интервал переменной 2 |
Вводиться ссылка на ячейки, содержащие результаты наблюдений величины Y. Диапазон должен состоять из одного столбца (строки) |
|
Гипотетическая средняя разность |
Число, равное предполагаемой разности средних (мат. ожиданий) изучаемых генеральных совокупностей. Значение 0 указывает, что проверяется гипотеза H0: ax=ay |
|
Альфа |
Вводиться уровень значимости , равный вероятности возникновения ошибки первого рода. |
|
Метки |
См. описание в режиме «Гистограмма» таб. 10 |
|
Выходной интервал |
|
|
Новый рабочий лист |
|
|
Новая рабочая книга |
Таблица 13. Параметры режима «Двухвыборочный t-тест с одинаковыми (различными) дисперсиями»
На рис. 48 приведен пример использования режима «Двухвыборочный t-тест с одинаковыми (различными) дисперсиями». Известны данные о расходе сырья при производстве продукции по старой и новой технологиям. Требуется проверить гипотезу H0: ax=ay , предположив, что =0,05,соответствующие генеральные совокупности имеют нормальное распределения:
с одинаковыми дисперсиями;
с различными дисперсиями.
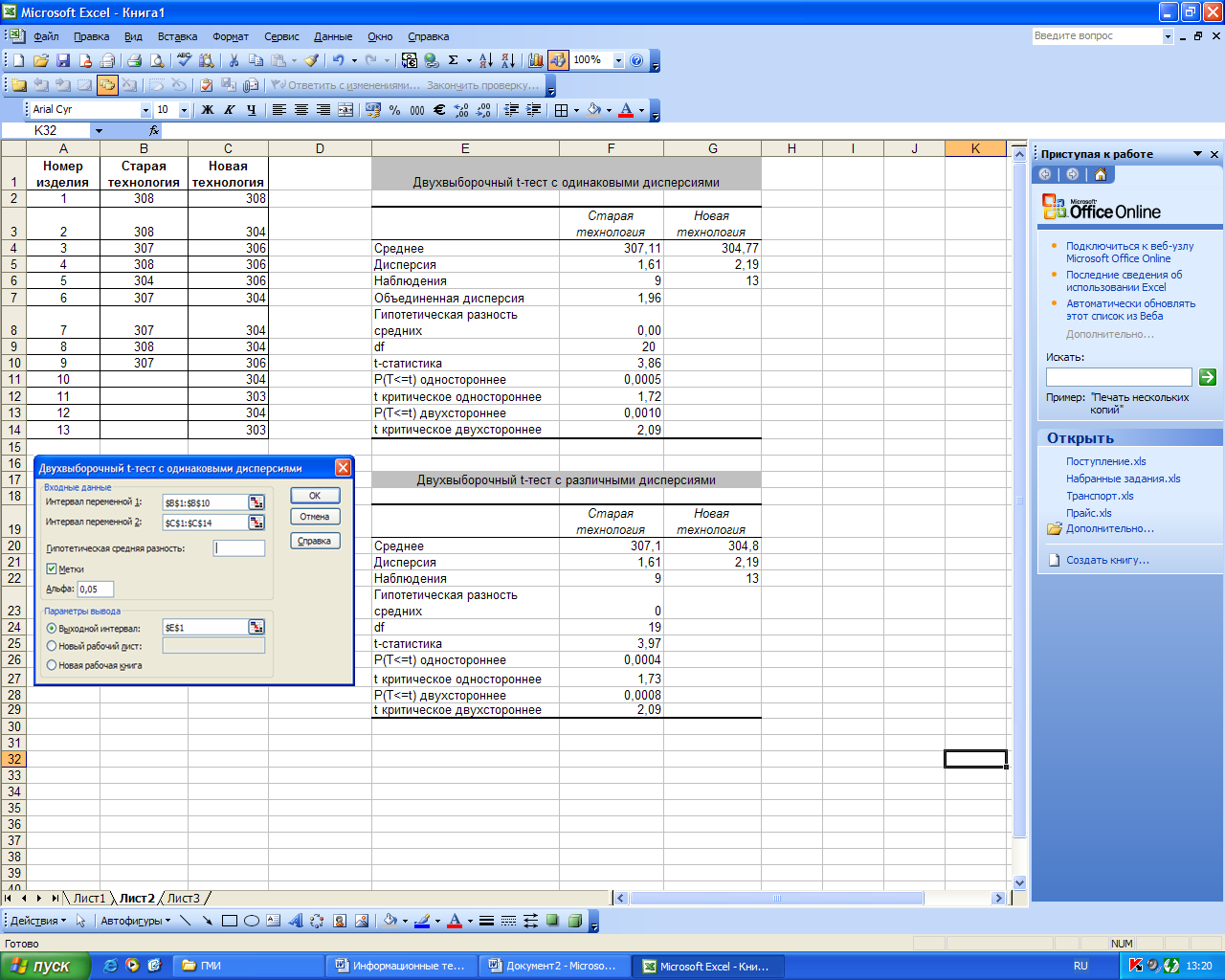
Рисунок 49. Пример использования режима «Двухвыборочный t-тест с одинаковыми (различными) дисперсиями»
Дисперсионный анализ
Дисперсионный анализ – это статистический метод анализа результатов наблюдений, зависящих от различных одновременно действующих факторов и оценка их влияния. В зависимости от количества факторов, включенных в анализ, различают классификацию по одному фактору (однофакторный анализ), по двум признакам (двухфакторный анализ) и многофакторную классификацию, изучением которой занимается многофакторный анализ.
Задачи однофакторного дисперсионного анализа являются самыми простыми, но часто встречаются на практике. Методы дисперсионного анализа основываются на следующем: пусть а1, а2, …, аm – математическое ожидание результатов признака соответственно при уровне А(1), А(2), …, А(m) (i=1,2, , m). Если при изменении уровня фактора групповые математические ожидания не изменяются, т.е. а1= а2 =…= аm, то считают, что результативный признак не зависит от фактора А, в противном случае такая зависимость имеется. Поскольку числовые значения математических ожиданий неизвестны, возникает задача проверки гипотезы H0: а1=а2=…=аm, при выполнении условий:
наблюдения независимы и проводятся в одинаковых условиях;
результативный признак имеет нормальное распределение с постоянной для различных уровней генеральной дисперсией 2.
Для проверки гипотезы о равенстве дисперсий трех (и более) нормальных распределений применяется критерий Бартлетта.