Файл: мирэа Российский технологический университет рту мирэа.docx
Добавлен: 01.12.2023
Просмотров: 887
Скачиваний: 20
ВНИМАНИЕ! Если данный файл нарушает Ваши авторские права, то обязательно сообщите нам.
-
1.2 Нереляционные базы данных
Нереляционная база данных (далее NoSQL БД) — это база данных, которая не использует традиционную реляционную модель хранения данных и вместо этого использует другие структуры данных для хранения данных[1]. Нереляционные базы данных являются альтернативой реляционным базам данных, которые были разработаны для работы с неструктурированными и полуструктурированными данными, такими как тексты, изображения и видео. Они предлагают более гибкие модели данных и могут быть использованы для о
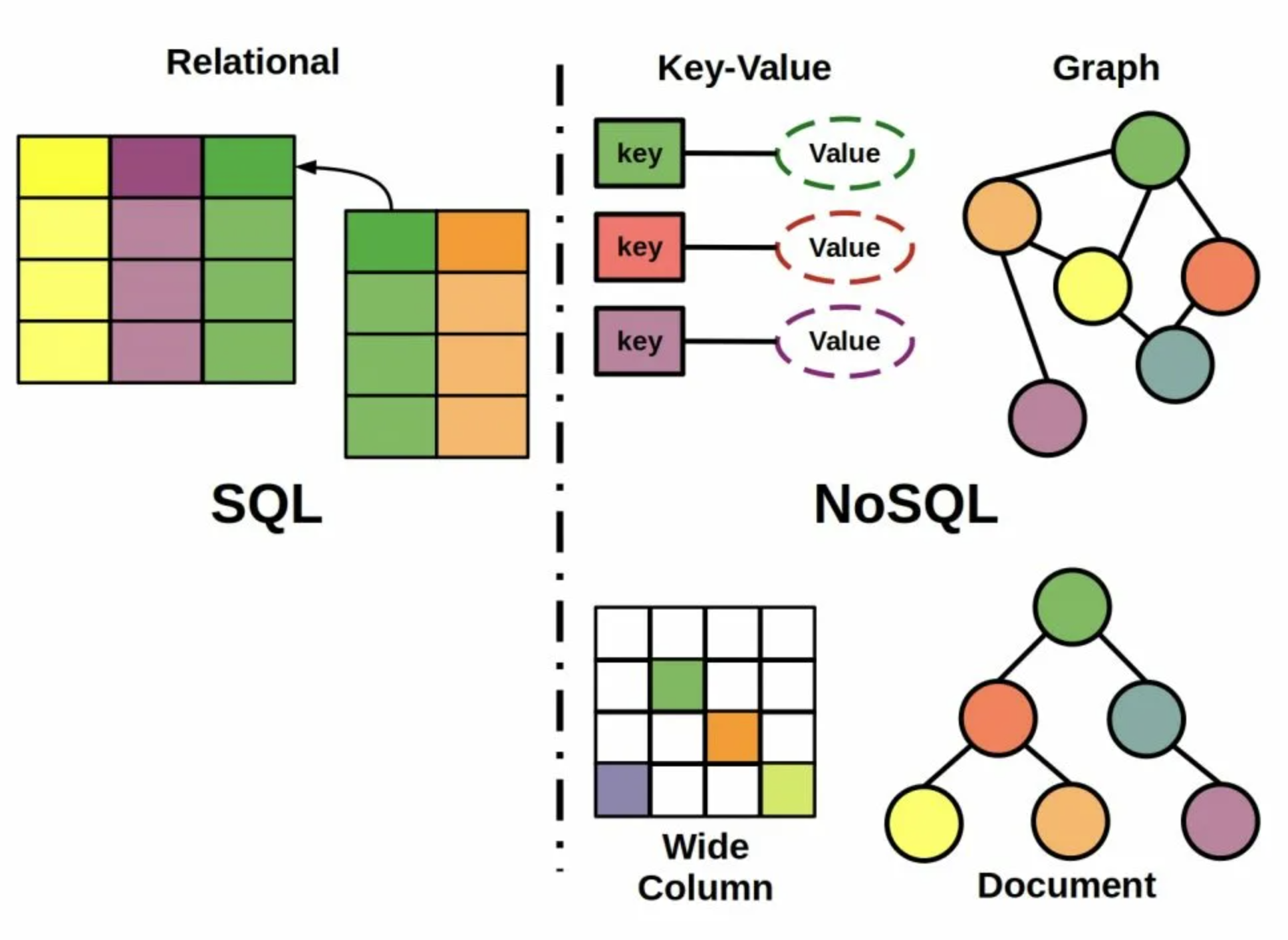 бработки больших объемов данных.
бработки больших объемов данных.Рисунок 1.2 — Сравнение структуры реляционных и нереляционных СУБД
Нереляционные базы данных бывают :
-
Документоориентированные базы данных.
В таких базах данных данные хранятся в документах, которые могут быть в формате JSON, XML, BSON и других. Примерами документоориентированных баз данных являются MongoDB, Couchbase и Amazon DocumentDB.
-
Колоночные базы данных.
В таких базах данных данные хранятся в таблицах, где каждый столбец соответствует отдельному атрибуту, а каждая строка - отдельной записи. Примерами колоночных баз данных являются Apache Cassandra и HBase.
-
Ключ-значение базы данных.
В таких базах данных данные хранятся в виде пар ключ-значение, где ключ - уникальный идентификатор, а значение - произвольные данные. Примерами ключ-значение баз данных являются Redis и Riak.
-
Графовые базы данных.
В таких базах данных данные хранятся в виде вершин и ребер графа, что позволяет эффективно хранить и обрабатывать связанные данные. Примерами графовых баз данных являются Neo4j и Amazon Neptune.
При использовании нереляционных баз данных для распознавания лиц, разработчики могут использовать документную модель данных для хранения изображений лиц в формате JSON или BSON. В документной модели данные хранятся в виде документов, которые могут содержать различные поля и структуры данных, включая изображения лиц. Это позволяет легко хранить и обрабатывать изображения лиц в нереляционных базах данных.
Плюсы нереляционных баз данных:
-
Масштабируемость.
Большинство систем NoSQL легко масштабируются горизонтально, что позволяет обрабатывать большие объемы данных.
-
Гибкость.
NoSQL базы данных не требуют строгой схемы данных, что позволяет быстро изменять структуру данных.
-
Высокая производительность.
NoSQL базы данных обычно показывают лучшие результаты в работе с большими объемами данных.
-
Надежность.
Некоторые системы NoSQL обеспечивают высокую отказоустойчивость и достижимость данных.
Однако, NoSQL БД также имеют свои ограничения. Они не всегда подходят для хранения структурированных данных, и могут не обеспечивать транзакционную целостность данных. Кроме того, при использовании нереляционных баз данных для распознавания лиц может возникнуть проблема с точностью распознавания, так как нереляционные базы данных не всегда могут обеспечивать точный поиск и сопоставление данных[4].
Также, при использовании нереляционных баз данных для распознавания лиц следует учитывать некоторые ограничения и недостатки. Например, некоторые типы нереляционных баз данных могут иметь ограничения по производительности при обработке определенных типов данных, включая фотоизображения.
-
1.3 Распределенные базы данных
Распределенная база данных (от англ. distributed database) — это база данных, которая физически распределяется на две или более компьютерные системы[1]. Иначе говоря, распределенные базы данных представляют собой системы хранения и управления данными, в которых данные разбиваются на несколько частей и хранятся на нескольких физических устройствах, которые могут находиться в разных местах. Каждое устройство хранит только часть данных, что позволяет обеспечивать более высокую доступность и производительность, а также более надежную защиту данных.
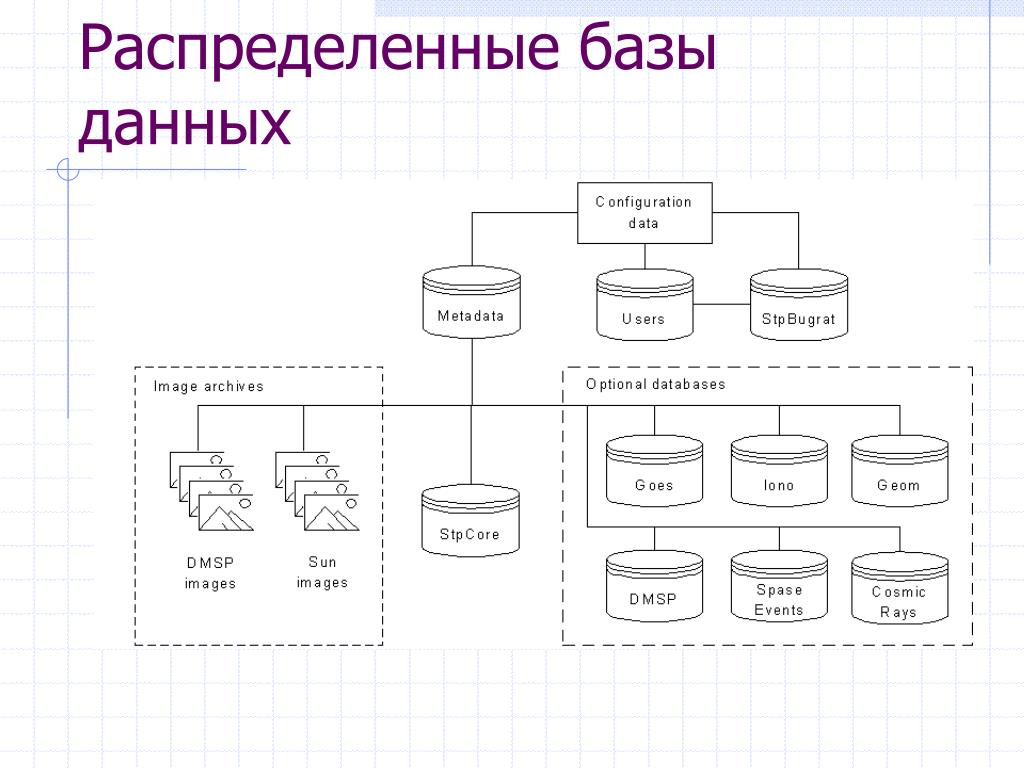
Рисунок 1.3 — Распределенные базы данных
Распределенные базы данных могут быть полезны для распознавания лиц, так как они могут обеспечивать более быстрый доступ к большим объемам данных, которые могут возникать при обработке фотоизображений. Кроме того, распределенные базы данных могут быть легко масштабированы по мере необходимости, что позволяет расширять систему при необходимости увеличения ее производительности. Они могут обеспечивать более быстрый доступ к большим объемам данных, высокую доступность и надежность системы. Кроме того, они могут быть легко масштабируемы по мере необходимости. Тем не менее, использование распределенных баз данных также требует дополнительных усилий на управление данными и обеспечение согласованности, что может увеличить сложность проекта и его стоимость.
Однако, использование распределенных баз данных также имеет свои ограничения и недостатки. Например, управление распределенными данными может быть сложным, и требует разработки специальных алгоритмов, которые позволяют обеспечивать целостность и согласованность данных. Кроме того, распределенные базы данных могут иметь более высокую стоимость, чем локальные базы данных, так как они требуют больших ресурсов на хранение и обработку данных.
Выбор между локальными и распределенными базами данных зависит от конкретных требований проекта и доступности ресурсов. Распределенные базы данных могут быть полезны для распознавания лиц, если данные распределены на нескольких устройствах и требуется быстрый доступ к большим объемам данных. Кроме того, распределенные базы данных могут быть полезны для обеспечения высокой доступности и надежности системы.
2. Методы распознавания лиц
Распознавание лиц - это задача компьютерного зрения, которая заключается в идентификации и классификации лиц на изображениях или в реальном времени с помощью алгоритмов машинного обучения [3][5].
Технология распознавания лиц может быть использована для различных целей, таких как:
-
Безопасность: распознавание лиц может быть использовано для идентификации людей на местах работы, в аэропортах, на стадионах и других общественных местах для обеспечения безопасности и предотвращения преступлений. -
Аутентификация: распознавание лиц может быть использовано для аутентификации пользователей в системах безопасности, банковских приложениях и других приложениях, где требуется высокий уровень безопасности. -
Управление ресурсами: распознавание лиц может быть использовано для управления ресурсами, такими как доступ к зданиям, мероприятиям и т.д.
-
2.1 Метод на основе геометрических признаков.
Метод на основе геометрических признаков — это один из методов распознавания лиц, который использует геометрические признаки лица, такие как расстояние между глазами, длина носа и т. д., для идентификации личности[5].
Основная идея метода заключается в том, что каждый человек имеет уникальные геометрические черты в лице, и эти черты могут быть использованы для идентификации личности. В этом методе выделяются точки на лице, называемые ключевыми точками (landmarks), которые затем используются для извлечения геометрических признаков.
Существует несколько различных подходов к выделению ключевых точек. Некоторые методы используют заранее заданные точки, такие как углы глаз, носа и рта, в то время как другие методы используют алгоритмы для автоматического выделения ключевых точек. После выделения ключевых точек метод на основе геометрических признаков применяет алгоритмы для извлечения признаков, которые затем используются для идентификации личности. Например, признаки могут быть основаны на расстояниях между ключевыми точками, углах между линиями, соединяющими ключевые точки, и т. д.
Преимущества метода на основе геометрических признаков:
-
Не требует большого объема данных для обучения, так как геометрические признаки являются универсальными и применимы для большинства людей -
Не зависит от освещения или других факторов, таких как растительность на лице, которые могут затруднить распознавание с помощью других методов -
Может быть применен в реальном времени на мобильных устройствах и других устройствах с ограниченными вычислительными мощностями благодаря своей скорости.
Недостатками метода на основе геометрических признаков являются:
-
Требует выделения и подготовки изображения лица для правильного извлечения признаков.
Это может быть сложно, если изображение содержит шум или находится в условиях с недостаточным освещением. Более того, метод требует того, чтобы лицо было заранее зарегистрировано в базе данных, что не всегда возможно или желательно.
-
Подвержен ошибкам при распознавании лиц, особенно если лица на изображениях сильно отличаются по своей форме и размеру.
Например, если анализируемые изображения были сделаны в разных условиях освещения, позы или пространственном положении.
-
Не учитывает информацию о текстуре и цвете лица
-
2.2 Метод главных компонент
Метод главных компонент (PCA) - это один из наиболее распространенных подходов к распознаванию лиц. Этот метод использует линейную алгебру для сжатия изображений лиц в пространство меньшей размерности, что позволяет увеличить скорость распознавания и уменьшить количество данных, необходимых для хранения[6].
Принцип работы метода главных компонент заключается в том, что он осуществляет проекцию исходных данных на новое пространство меньшей размерности, при этом максимально сохраняется дисперсия исходных данных. Это достигается путем нахождения главных компонент – новых признаков, которые наиболее точно описывают распределение исходных данных.
Для применения метода главных компонент к задаче распознавания лиц необходимо выполнить следующие шаги:
-
Подготовить обучающую выборку, состоящую из изображений лиц. -
Нормализовать каждое изображение, чтобы оно имело одинаковый размер и было расположено в одном и том же положении. -
Применить метод главных компонент к обучающей выборке, чтобы найти главные компоненты, описывающие распределение изображений лиц. -
С использованием полученных главных компонент построить новые признаки, которые будут использоваться для распознавания лиц. -
Обучить классификатор на основе новых признаков. -
Проверить работу классификатора на тестовой выборке.
Одним из главных преимуществ метода главных компонент является возможность работать с большим количеством изображений за счёт уменьшения объёма данных. Также, метод позволяет учитывать различные условия освещения и искажения, такие как изменение масштаба и повороты изображений, что делает его более универсальным.
Основной недостаток заключается в том, что при использовании метода для больших наборов изображений, требуется большой объем вычислительных ресурсов и времени для обработки данных. Метод может быть неработоспособным в случае, если изображения содержат большое количество шума или изображения с низким разрешением.
Заключение
Выбор конкретного типа базы данных и метода распознавания зависит от многих факторов: от количества данных, качества данных, структуры данных, предметной области, условий обработки и вычислительной мощности.
Реляционные базы данных наиболее удобны для хранения структурированных данных, таких как идентификаторы и атрибуты лиц, а нереляционные базы данных могут обеспечивать более высокую скорость доступа и обработки данных, особенно в случае с большим объемом неструктурированных данных, таких как изображения. Распределенные базы данных могут предоставлять увеличенную масштабируемость и отказоустойчивость.
Методы на основе геометрических признаков позволяют быстро и эффективно идентифицировать лица, но могут столкнуться с проблемами, такими как низкая точность в случае с изменением освещения и угла обзора. Метод главных компонент является одним из наиболее эффективных алгоритмов для распознавания лиц, обеспечивая высокую точность при использовании относительно небольшого объема данных, но при этом требует много вычислительных ресурсов и большее время на обработку.